Способы кодирования категориальных данных

В сфере data science подготовка данных является обязательным этапом работы перед построением моделей. Один из них — кодирование категориальных данных, т.к. значимая часть информации в реальной жизни относится именно к категориальным строковым значениям, а подавляющее большинство моделей умеют работать исключительно с числовыми значениями. Кодирование — это и есть процесс преобразования категориальных данных в числовой формат.
Что такое категориальные данные?
Раз уж вся эта статья про категориальные данные, то давайте подробнее обсудим, что это такое. Если совсем кратно, то это данные с ограниченным числом уникальных значений или категорий.
Также к категориальным данным можно относиться как к значениям, которые делят все имеющиеся объекты изучения на группы. Например, список людей с их группой крови: I, II, III, IV. В таком списке каждая группа крови является категориальным значением.
Категориальные данные могут быть двух видов: порядковыми и номинальными.
Номинальные категории. Такие значения не могут быть проранжированы, и нет логической возможности их порядкового сравнения между собой. Например, это могут быть названия различных отделов в компании: производственный отдел, отдел кадров, бухгалтерия и так далее.

Выше представлено несколько примеров номинальных данных.
Порядковые категории. Такие значения могут быть упорядочены, и их можно сравниваться друг с другом. Например, показатель уровня сахара у пациентов, который можно представить как высокий, низкий и средний.
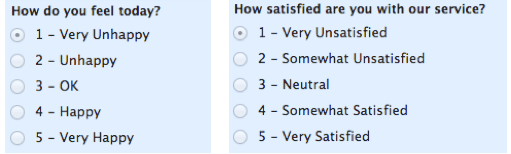
Выше представлены несколько примеров порядковых данных.
Label Encoding и Ordinal Encoding
Эти способы кодирования используется, когда категории являются порядковыми. Каждое уникальное значение преобразуется в целочисленное, таким образом, все значения просто преобразовываются в числовой ряд по возрастанию.
В Python это можно сделать так:
import category_encoders as ce
import pandas as pd
df = pd.DataFrame({'height': ['tall', 'medium', 'short', 'tall',
'medium', 'short', 'tall', 'medium', 'short']})
# создание класса OrdinalEncoder
encoder = ce.OrdinalEncoder(cols = ['height'],
return_df = True,
mapping = [
{'col':'height',
'mapping':{'None':0,'tall':1,'medium':2,
'short':3}}
])
# Исходные данные
display(df)
df['transformed'] = encoder.fit_transform(df)
# Результат
display(df)
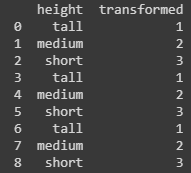
Если Ordinal Encoding используется для кодирования признаков в данных, то Label Encoding применяется для кодирования целевой переменной (хоть и работает аналогично).
One-Hot Encoding
При One-Hot Encoding каждая категория преобразовывается в отдельный столбец/массив. Количество новых столбцов будет равно количеству значений категориальной величины. У конкретного объекта будет стоять 1 в том столбце, который соответствует присущей ему категории и нули во всех остальных. Этот тип кодирования используется, когда данные являются номинальными. Вновь созданные бинарные признаки обычно называют фиктивными (dummy).
Один из способ сделать это в Python представлен ниже:
df=pd.DataFrame({'name':[
'rahul','ashok','ankit','aditya','yash','vipin','amit'
]})
encoder = ce.OneHotEncoder(cols='name',
handle_unknown='return_nan',
return_df=True,
use_cat_names=True)
# вывод исходным данных
display(df)
# преобразование данных
df_encoded = encoder.fit_transform(df)
display(df_encoded)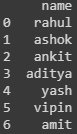

Выше мы как раз видим новые созданные столбцы для каждой категории.
Effect Encoding
При таком способе кодирования категориям присваиваются значения -1, 0, 1 (а не только 0 и 1, как при OHE).
Наглядно разницу видно в примере:
data = pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai',
'Bangalore','Delhi','Hyderabad']})
encoder = ce.sum_coding.SumEncoder(cols='City', verbose=False)
# выводим исходные данные
data
# делаем преобразование
df = encoder.fit_transform(data)
display(df)
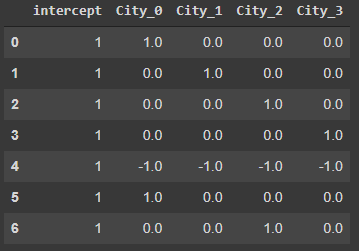
Мы видим, что кодировщик присвоил значение -1 для всех фиктивных столбцов у Bangalore.
Hash Encoding
Так же, как и One-Hot Encoding, такой способ преобразует каждую категорию в отдельный столбец с 0/1 в нём. Отличие заключается в том, что при Hash Encoding мы можем самостоятельно указать количество этих новых столбцов. Такой способ преобразования всегда используется для данных произвольной размерности в объект со строго фиксированной размерностью.
data = pd.DataFrame({'Month':['January','April','March','April',
'Februay','June','July','June','September']})
# создаем объект хэш-кодировщика
encoder = ce.HashingEncoder(cols='Month', n_components=6)
# преобразуем данные
encoder.fit_transform(data)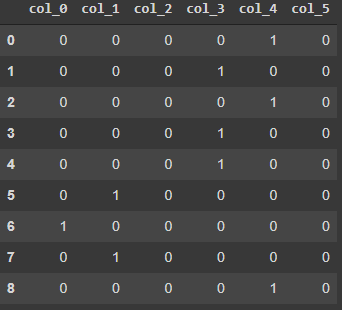
Хеширование — это такой способ преобразования, который отличается от прочих тем, что после него данные не могут быть преобразованы обратно. При этом мы можем указывать выходную размерность меньше, чем требуется, чтобы уменьшить размерность результата. Это может быть полезно, когда итоговая размерность данных чрезмерно большая, а мы ее хотим сократить (с частичной потерей информации).
Binary Encoding
При Hash encoding мы можем потерять информацию с целью уменьшить размерность, а при One-Hot Encoding итоговая размерность может быть непозволительно большой. А Binary Encoding позволяет решить обе этих проблемы.
В целом такое кодирование — это комбинация Hash Encoding и One-Hot Encoding.
encoder = ce.BinaryEncoder(cols=['Month'], return_df=True) data = encoder.fit_transform(data) display(data)
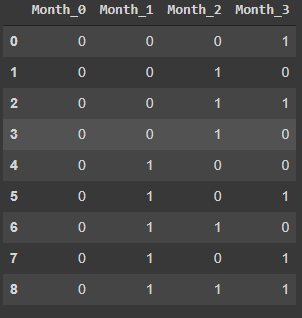
Мы видим, что новых столбцов меньше, но при этом все значения преобразованных признаков отличаются друг от друга, то есть мы не теряем информацию. Такой способ очень полезен, когда категориальных признаков и их значений очень много.
Base-N Encoding
В позиционной системе счисления основание — это количество уникальных цифр, включая ноль, используемых для представления чисел. В Base-N кодировании, если база равна двум, кодировщик преобразует категории в числовую форму, используя их соответствующую двоичную форму, что по факту будет аналогично one-hot-кодированию. Но если мы изменим базу (количество категорий признака) на 10, то категории будут преобразованы в числа от 0 до 9. Выглядит это так:
# инициализация кодировщика
encoder = ce.BaseNEncoder(cols=['Month'],
return_df=True,
base=5)
# преобразование данных
data_encoded = encoder.fit_transform(data)
display(data_encoded)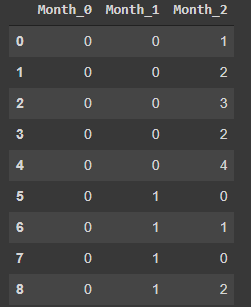
Мы явно указали базу 5, поэтому в итоге получили 3 новых столбца (а не 9, как получили бы в one-hot) со значениями от 0 до 9. Это такой компромиссный вариант между one-hot и ordinal-кодированием.
Если базу не указывать, то по умолчанию она будет равна двум, и мы получим результат, аналогичный one-hot-кодированию.
Target Encoding
Target encoding — это метод преобразования категориального значения в среднее значение целевой переменной. Этот тип кодирования представляет собой тип байесовского метода кодирования, в котором целевые переменные используются для кодирования категориального значения.
Target encoder вычисляет среднее значение целевой переменной для каждой категории и именно их использует для преобразования. Давайте посмотрим, как это работает:
df = pd.DataFrame(
{'name': [ 'rahul','ashok','ankit','rahul','ashok','ankit' ],
'marks' : [10,20,30,60,70,80,]}
)
display(df)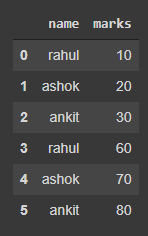
# инициализируем кодировщик encoder = ce.TargetEncoder(cols='name') # преобразуем данные encoder.fit_transform(df['name'], df['marks'])
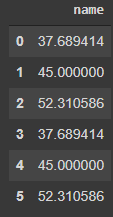
И видим, что имена студентов меняются на их средние оценки. Такой способ очень хорошо подходит, когда категориальных признаков и их значений много. Но это может привести к переобучению любой модели, т.к. мы используем значение целевой переменной для формирования признаков, что будет создавать сильную корреляцию между ними. Поэтому использовать его надо с осторожностью.
Заключение
Как мы увидели, существует много способов кодирования категориальных данных. Разные способы могут привести к разным результатам нашей модели, а выбрать нужно какой-то один, поэтому выбирать стоит правильно :)
Источник: Analytics India Magazine