Как изменить значение по условию в датафрейме Pandas

Значения в столбце датафрейма могут быть изменены на основе условного выражения. В этой статье мы рассмотрим несколько способов создания столбцов по условию в Pandas.
Загрузка датафрейма для примера
import pandas as pd
data = {'Stock': ['AAPL', 'IBM', 'MSFT', 'WMT'],
'Price': [144.8, 141.61, 304.21, 139.5],
'PE': [25, 21, 39, 16],
'TradingExchange': ['NASDAQ', 'NYSE', 'NASDAQ', 'NYSE']}
df = pd.DataFrame(data)
print(df)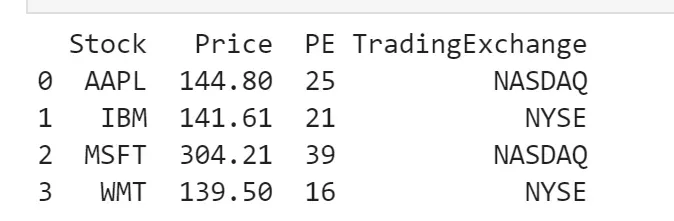
Способ 1: использование атрибута loc
Атрибут loc в Pandas позволяет создать логическую маску, основанную на условии. Он может либо просто выбирать строки и столбцы, либо фильтровать датафреймы по условию.
example_df.loc[example_df['column_1'] condition, 'column_2'] = value
column_1— столбец для проверки по условию;column_2— столбец для создания или изменения, может совпадать сcolumn_1;condition— условное выражение;value— новое присваиваемое значение.
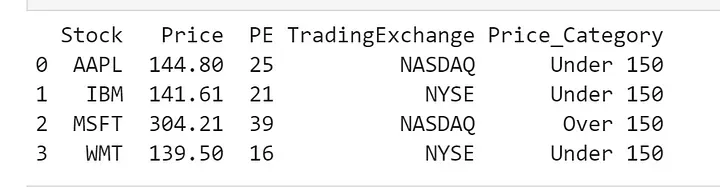
Давайте присвоим строку "Under 150" любой акции с ценой ниже 150$, а строку "Over 150" — любой акции с большей ценой, чем 150$.
df['Price_Category'] = 'Over 150' df.loc[df['Price'] < 150, 'Price_Category'] = 'Under 150'
- Мы создали новый столбец "Price_Category" и присвоили значение "Over 150" каждой записи в датафрейме.
- Затем мы использовали атрибут
locдля создания логической маски в столбце "Price", чтобы отфильтровать строки с ценой ниже 150$. Когда значение столбца "Price" удовлетворяет условию, значение "Price_Category" для текущей записи меняется на новое — "Under 150".

Способ 2: функция where из numpy
Синтаксис у этого способа такой:
import numpy as np example_df['column_1'] = np.where(condition, new_value, 'column_2')
Аналогично создаём столбец "Price_Category" и присваиваем записям значения "Over 150" или "Under 150".
df['Price_Category'] = 'Over 150' df['Price_Category'] = np.where(df['Price'] < 150, 'Under 150', df['Price_Category'])
Но что делать, если у нас несколько условий? Мы могли бы использовать .loc несколько раз, но это усложнить восприятие кода.
Способ 3: функция select из numpy
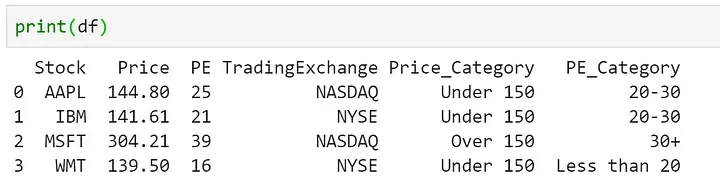
А теперь попробуем выделить несколько категорий на основе соотношения цены и дохода (PE или price earning ratio):
Для выполнения поставленной задачи мы можем создать список условий.
PE_Conditions = [
(df['PE'] < 20),
(df['PE'] >= 20) & (df['PE'] < 30),
(df['PE'] >= 30)]
PE_Categories = ['Less than 20', '20-30', '30+']
df['PE_Category'] = np.select(PE_Conditions, PE_Categories)
print(df)И получим следующий результат:
Заключение
В этой статье мы изучили три способа создания столбцов на основе условий в Pandas. Дополнительную информацию об операциях Pandas можно найти в официальной документации:
👉🏻Подписывайтесь на PythonTalk в Telegram 👈🏻
Источник: Medium