Структуры данных и алгоритмы в Python
В этой статье мы кратко рассмотрим встроенные структуры данных: списки, кортежи, словари и т.д., а также некоторые пользовательские структуры данных: связанные списки, деревья и графы. Более подробно затронем алгоритмы обхода, поиска и сортировки.
Чтиво длинное, так что если вы точно знаете, что вам нужно, вот содержание:
Список
Списки в Python — это упорядоченные коллекции данных, в качестве элементов в них могут выступать объекты любых других типов.
Для списков очень «затратной» с точки зрения расходования памяти операцией является вставка элемента в начало или его удаление с первой позиции, так как все элементы должны быть сдвинуты. Вставка и удаление в конец списка также могут быть «затратными» в случае, если переполняется предварительно выделенная память.
Доступ к элементам списка можно получить по индексу. В Python начальный индекс списка (и любого другого составного объекта) всегда равен 0, а конечный (если в нём N элементов) — N-1.
Кортеж
Кортежи в Python похожи на списки, но они неизменяемы, т.е. элементы в них нельзя изменить после создания. Как и список, кортеж может содержать элементы различных типов.
В Python кортежи создаются путем перечисления значений через запятую с использованием круглых скобок или без них.
Примечание: Чтобы создать кортеж из одного элемента, обязательно нужно поставить запятую после него. Например, (8,) создаст кортеж, содержащий 8 в качестве единственного элемента.
Множество
В Python это изменяемый набор из уникальных элементов. Множества используются в основном для нахождения общих элементов и устранения дубликатов. Для всех действий используется хэширование — популярная техника, позволяющая выполнять вставку, удаление и обход в среднем за O(1).
Если несколько значений присутствуют в одной и той же позиции индекса, то значение добавляется к этой позиции индекса, формируя связанный список.
Frozen set
Это неизменяемые объекты (как и кортежи), состоящие из уникальных элементов (как и множества). В то время как элементы множества могут быть изменены после его создания, элементы frozen sets — нет.
Строка
Строки в Python — это неизменяемый массив байтов, представляющих собой набор символов в Unicode. В Python нет символьного типа данных, отдельный символ — это тоже строка, состоящая из одного элемента.
Словарь
Словарь — это неупорядоченная коллекция данных, хранящихся в формате пары ключ:значение. Он похож на хэш-таблицы в любом другом языке со сложностью равной O(1). Индексация словаря Python осуществляется с помощью ключей. Это может быть любой хэшируемый тип данных: строки, числа, кортежи и т.д. Мы можем создать словарь с помощью фигурных скобок ({}) или dictionary comprehension.
Матрица
Матрица — это двумерный массив, в котором каждый элемент имеет строго одинаковый размер. Для создания матрицы мы будем использовать библиотеку NumPy.
import numpy as np a = np.array([[1,2,3,4],[4,55,1,2], [8,3,20,19],[11,2,22,21]]) m = np.reshape(a,(4, 4)) print(m) >>>OUTPUT [[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21]] # Доступ к элементам print(a[1]) print(a[2][0]) # [ 4 55 1 2] # 8 # Добавление элемента m = np.append(m,[[1, 15,13,11]],0) print(m) >>>OUTPUT [[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]] # Удаление элемента m = np.delete(m,[1],0) print(m) # Удаление элемента: [[ 1 2 3 4] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]]
Байт-массив
Байт-массив в Python — это изменяемая последовательность целых чисел в диапазоне 0 <= x < 256.
# Создание массива
a = bytearray((12, 8, 25, 2))
print(a)
# bytearray(b'\x0c\x08\x19\x02')
# Доступ к элементам
print("\nДоступ к элементам:", a[1])
# 8
# Изменение элемента
a[1] = 3
print("\nПосле изменения:")
print(a)
# После изменения:
# bytearray(b'\x0c\x03\x19\x02')
# Добавление элемента
a.append(30)
print("\nПосле добавления:")
print(a)
# После добавления:
# bytearray(b'\x0c\x03\x19\x02\x1e')Связанный список
Связанный список — это линейная структура данных, в которой элементы не хранятся в смежных областях памяти. Элементы в таком списке связаны между собой с помощью указателей, как показано на рисунке ниже:
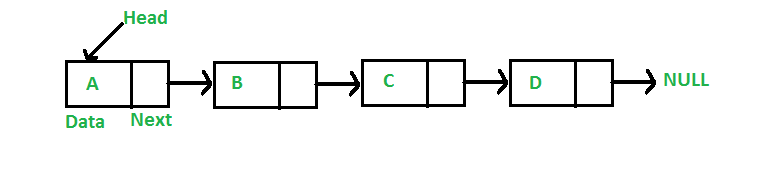
Связанный список представлен как указатель на первый узел, который называется Head. Если связанный список пуст, то значение в Head равно NULL. Каждый узел в списке состоит как минимум из двух частей: данных и указателя (или ссылки) на следующий узел.
# Класс узла class Node: # Инициализация объекта узел def __init__(self, data): self.data = data # присваиваем данные self.next = None # инициализируем # далее - null # Класс связанного списка class LinkedList: # Инициализация связанного списка # объект - список def __init__(self): self.head = None
Создадим простой связный список с тремя узлами:
# Исполнение начинается отсюда
if __name__=='__main__':
# начнём с пустого списка
llist = LinkedList()
llist.head = Node(1)
second = Node(2)
third = Node(3)
'''
Создали три узла.
Их имена: head, second и third
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | None | | 2 | None | | 3 | None |
+----+------+ +----+------+ +----+------+
'''
llist.head.next = second # связываем первый узел со вторым
'''
Первый узел ссылается на второй.
Теперь они связаны.
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | o-------->| 2 | null | | 3 | null |
+----+------+ +----+------+ +----+------+
'''
second.next = third # связываем второй узел с третьим
'''
Второй узел ссылается на третий.
Теперь они связаны.
llist.head second third
| | |
| | |
+----+------+ +----+------+ +----+------+
| 1 | o-------->| 2 | o-------->| 3 | null |
+----+------+ +----+------+ +----+------+
'''Обход связанного списка
В предыдущем скрипте мы создали простой связный список с тремя узлами. Давайте обойдем его и выведем данные каждого узла. Для обхода напишем метод print_list(), который выводит в консоль любой данный ей список.
class Node: def __init__(self, data): self.data = data self.next = None class LinkedList: def __init__(self): self.head = None # печатает содержимое связанного списка def print_list(self): temp = self.head while temp: print(temp.data) temp = temp.next if __name__=='__main__': llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) llist.head.next = second second.next = third llist.print_list() >>>OUTPUT # 1 # 2 # 3
Стек (Stack)
Стек — это линейная структура данных, которая хранит элементы по принципу «последний вошел/первый вышел» (LIFO) или «первый вошел/последний вышел» (FILO). В стеке новый элемент добавляется и удаляется только с одного конца. Операции вставки и удаления часто называют push и pop.
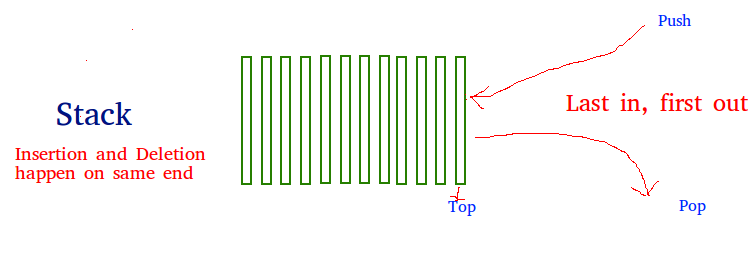
- empty() — возвращает, пуст ли стек, сложность: O(1)
- size() — возвращает размер стека, сложность: O(1)
- top() — возвращает ссылку на самый верхний элемент стека, сложность: O(1)
- push(a) — вставляет элемент 'a' на вершину стека, сложность: O(1)
- pop() — удаляет самый верхний элемент стека, сложность: O(N)
stack = []
# добавление элементов
stack.append('g')
stack.append('f')
stack.append('g')
print('Начальный стек')
print(stack)
# Начальный стек
# ['g', 'f', 'g']
# удаление элементов
print('\nУдаление элементов:')
print(stack.pop())
print(stack.pop())
print(stack.pop())
# Удаление элементов:
# g
# f
# g
print('\nФинальный стек:')
print(stack)
# Финальный стек:
# []Очередь (Queue)
Как и стек, очередь представляет собой линейную структуру данных, которая хранит элементы по принципу «первым пришел — первым ушел» (FIFO). В очереди первым удаляется последний добавленный элемент.
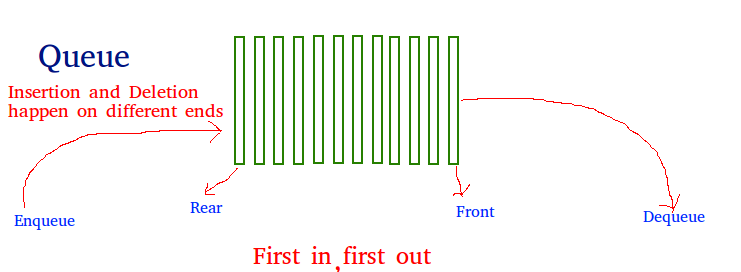
С очередью связаны следующие операции:
Enqueue: добавляет элемент в очередь. Если очередь переполнена, то говорят о состоянии переполнения, сложность: O(1)
Dequeue: удаляет элемент из очереди. Элементы выгружаются в том же порядке, в котором они были вставлены. Если очередь пуста, то считается, что это условие переполнения, сложность: O(1)
Front: получает первый элемент из очереди, сложность: O(1)
Rear: получает последний элемент из очереди, cложность: O(1)
# создаём очередь
queue = []
# добавляем в неё элементы
queue.append('g')
queue.append('f')
queue.append('g')
print("Исходная очередь")
print(queue)
# Исходная очередь
# ['g', 'f', 'g']
# убираем элементы из очереди
print("\nУдалённые элементы")
print(queue.pop(0))
print(queue.pop(0))
print(queue.pop(0))
# Удалённые элементы
# g
# f
# g
print("\nОчередь после удаления элементов")
print(queue)
# Очередь после удаления элементов
# []Очередь с приоритетом
Это абстрактные структуры данных, в которых каждое значение в очереди имеет определённый приоритет. Например, в авиакомпаниях багаж с названием «Бизнес» или «Первый класс» прибывает раньше остальных. Очередь с приоритетом — это расширение обычной очереди со следующими свойствами:
- элемент с высоким приоритетом выгружается раньше элемента с низким приоритетом.
- если два элемента имеют одинаковый приоритет, они обслуживаются в соответствии с их порядком в очереди.
# простая реализация очереди с приоритетом class PriorityQueue(object): def __init__(self): self.queue = [] def __str__(self): return ' '.join([str(i) for i in self.queue]) # проверяет, пуста ли очередь def isEmpty(self): return len(self.queue) == 0 # добавляет элемент в очередь def insert(self, data): self.queue.append(data) # удаляет элемент по приоритету def delete(self): try: max = 0 for i in range(len(self.queue)): if self.queue[i] > self.queue[max]: max = i item = self.queue[max] del self.queue[max] return item except IndexError: print() exit() if __name__ == '__main__': myQueue = PriorityQueue() myQueue.insert(12) myQueue.insert(1) myQueue.insert(14) myQueue.insert(7) print(myQueue) while not myQueue.isEmpty(): print(myQueue.delete()) >>>OUTPUT # 12 1 14 7 # 14 # 12 # 7 # 1
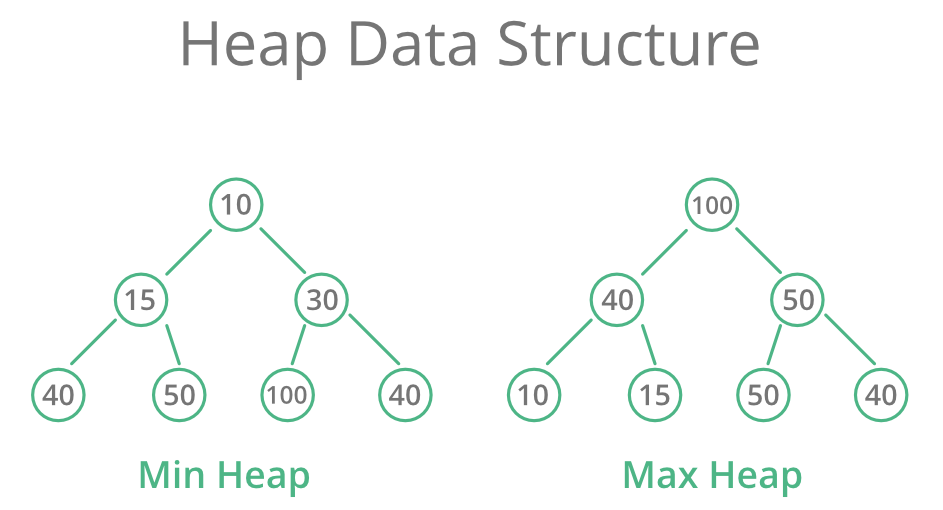
Куча (Heap)
Модуль heapq в Python позволяет создать структуру данных под элегантным названием «куча» или Heap, которая, как правило, представляет собой очередь с приоритетом. Свойство этой структуры данных заключается в том, что она всегда выдает наименьший элемент (min heap).
При добавлении или удалении элемента структура данных сохраняется. heap[0] также каждый раз возвращает наименьший элемент.
Временная сложность — O (log n).
В целом, кучи могут быть двух типов:
Max-Heap: ключ, находящийся в корневом узле, должен быть наибольшим среди ключей, находящихся во всех его дочерних узлах. Это же свойство должно быть рекурсивно истинным для всех поддеревьев этого дерева.
Min-Heap: ключ, находящийся в корневом узле, должен быть наименьшим среди ключей, присутствующих во всех его дочерних узлах. Это же свойство должно быть рекурсивно истинным для всех поддеревьев этого дерева.
# импортируем библиотеку
import heapq
# создаём список
li = [5, 7, 9, 1, 3]
# превращаем список в кучу
heapq.heapify(li)
# выводим кучу
print("Куча: ",end="")
print(list(li))
# Куча: [1, 3, 9, 7, 5]
# добавляем элемент
heapq.heappush(li,4)
# выводим результат
print("Изменённая куча: ",end="")
print(list(li))
# Изменённая куча: [1, 3, 4, 7, 5, 9]
# получаем наименьший элемент
print("Наименьший элемент - ",end="")
print(heapq.heappop(li))
# Наименьший элемент - 1Бинарное дерево (Binary tree)
Дерево — это иерархическая структура данных, которая выглядит так, как показано ниже.
дерево
----
j <-- корень
/ \
f k
/ \ \
a h z <-- листьяСамый верхний узел дерева называется корнем, а самые нижние узлы или узлы, не имеющие детей, называются листовыми узлами. Узлы, которые находятся непосредственно под узлом, называются его детьми, а узлы, которые находятся непосредственно над узлом, называются его родителем.
Бинарное дерево — это дерево, элементы которого могут иметь два дочерних элемента. Поскольку каждый элемент бинарного дерева может иметь только 2 дочерних элемента, мы обычно называем их просто левый и правый. Узел бинарного дерева содержит следующие части:
Давайте создадим дерево с четырьмя узлами. Предположим, что структура дерева выглядит следующим образом:
дерево
----
1 <-- корень
/ \
2 3
/
4# класс как узел бинарного дерева class Node: def __init__(self,key): self.left = None self.right = None self.val = key # создаём узел root = Node(1) ''' вот что должно получиться: 1 / \ None None''' root.left = Node(2); root.right = Node(3); ''' 1 / \ 2 3 / \ / \ None None None None''' root.left.left = Node(4); ''' 1 / \ 2 3 / \ / \ 4 None None None / \ None None'''
Обход бинарного дерева
Деревья можно обходить различными способами. Ниже перечислены наиболее часто используемые. Рассмотрим следующее дерево:
дерево
----
1 <-- корень
/ \
2 3
/ \
4 5- Центрированный (левое поддерево, корень, правое поддерево) : 4 2 5 1 3
- Прямой (корень, левое поддерево, правое поддерево) : 1 2 4 5 3
- Обратный (левое поддерево, правое поддерево, корень) : 4 5 2 3 1
- Пройти по левому поддереву, т.е. вызвать
Inorder(left-subtree). - Зайти в корень.
- Пройти по правому поддереву, т.е. вызвать
Inorder(right-subtree).
- Зайти в корень.
- Обратиться к левому поддереву, т.е. вызвать
Preorder(left-subtree). - Пройти по правому поддереву, т.е. вызвать
Preorder(right-subtree).
- Обратиться к левому поддереву, т.е. вызвать
Postorder(left-subtree). - Пройти по правому поддереву, т.е. вызвать
Postorder(right-subtree). - Зайти в корень.
# узел бинарного дерева
class Node:
def __init__(self, key):
self.left = None
self.right = None
self.val = key
# ф-ия для обхода дерева по
# центрированному алгоритму
def print_inorder(root):
if root:
# рекурсивно возвращаемся к левому поддереву
print_inorder(root.left)
# выводим данные узла
print(root.val),
# рекурсивно возвращаемся к правому поддереву
print_inorder(root.right)
# ф-ия для обхода дерева по
# обратному алгоритму
def print_postorder(root):
if root:
# рекурсивно возвращаемся к левому поддереву
print_postorder(root.left)
# рекурсивно возвращаемся к правому поддереву
print_postorder(root.right)
# выводим данные узла
print(root.val),
# ф-ия для обхода дерева по
# прямому алгоритму
def print_preorder(root):
if root:
# сначала выводим данные
print(root.val),
# рекурсивно возвращаемся к левому поддереву
print_preorder(root.left)
# рекурсивно возвращаемся к правому поддереву
print_preorder(root.right)
# запускаем шайтан-код
root = Node(1)
root.left = Node(2)
root.right = Node(3)
root.left.left = Node(4)
root.left.right = Node(5)
print("Обход по прямому алгоритму:")
print_preorder(root)
# Обход по прямому алгоритму:
# 1
# 2
# 4
# 5
# 3
print("\nОбход по центрированному алгоритму:")
print_inorder(root)
# Обход по центрированному алгоритму:
# 4
# 2
# 5
# 1
# 3
print("\nОбход по обратному алгоритму:")
print_postorder(root)
# Обход по обратному алгоритму:
# 4
# 5
# 2
# 3
# 1Для приведённого выше дерева порядок следования уровней следующий: 1 2 3 4 5.
Сначала посещается сам узел, а затем его дочерние узлы помещаются в очередь. Ниже приведён алгоритм для этого:
- Создать пустую очередь q
temp_node = root/*начать с корня*/- Запустить цикл while пока temp_node is not None
# обход дерева в ширину с помощью очереди
# задаём структуру узла
class Node:
def __init__(self ,key):
self.data = key
self.left = None
self.right = None
# итеративный метод вывода
# высоты дерева
def print_level_order(root):
if root is None:
return
# создаём пустую очередь
queue = []
# добавляем узел
queue.append(root)
while(len(queue) > 0):
# выводим первый элемент в очереди
# и убираем его
print (queue[0].data)
node = queue.pop(0)
# добавляем в очередь левое поддерево
if node.left is not None:
queue.append(node.left)
# добавляем в очередь правое поддерево
if node.right is not None:
queue.append(node.right)
# запускаем шайтан-код
root = Node(1)
root.left = Node(2)
root.right = Node(3)
root.left.left = Node(4)
root.left.right = Node(5)
print("Обходим дерево по ширине:")
print_level_order(root)
>>>OUTPUT
# Обходим дерево по ширине:
# 1
# 2
# 3
# 4
# 5Бинарное дерево поиска (Binary Search Tree)
Это основанная на узлах двоичная древовидная структура данных, обладающая следующими свойствами:
- Левое поддерево узла содержит только узлы с ключами, меньшими, чем ключ узла.
- Правое поддерево узла содержит только узлы с ключами, большими, чем ключ узла.
- Каждое левое и правое поддерево также должно быть двоичным деревом поиска.

Такие свойства дерева обеспечивают упорядочивание ключей, поэтому операции поиска, нахождение минимума и максимума могут быть выполнены быстро. Если порядка нет, то для поиска заданного ключа может потребоваться сравнение каждого ключа.
Поиск элемента
- Начинаем с корня.
- Сравниваем искомый элемент с корнем. Если он меньше корня, то выполняем перебор слева, если больше, то справа.
- Если искомый элемент найден, возвращаем True, иначе — False.
# ф-ия поиска ключа def search(root,key): # Базовый случай: узел пуст или ключ в узле if root is None or root.val == key: return root # Ключ больше того, что в узле if root.val < key: return search(root.right,key) # Ключ меньше того, что в узле return search(root.left,key)
Вставка ключа
- Начинаем с корня.
- Сравниваем вставляемый элемент с корнем, если он меньше, чем корень, то выполняем перебор слева, иначе — выполняем перебор элементов справа.
- Достигнув конца, вставляем этот узел слева (если он меньше текущего), иначе — справа.
# задаём структуру узла class Node: def __init__(self, key): self.left = None self.right = None self.val = key # ф-ия вставки нового узла с # заданным ключом def insert(root, key): if root is None: return Node(key) else: if root.val == key: return root elif root.val < key: root.right = insert(root.right, key) else: root.left = insert(root.left, key) return root # ф-ия для центрированного обхода дерева def inorder(root): if root: inorder(root.left) print(root.val) inorder(root.right) # запускаем шайтан-код # чтобы создать такое дерево: # 50 # / \ # 30 70 # / \ / \ #20 40 60 80 r = Node(50) r = insert(r, 30) r = insert(r, 20) r = insert(r, 40) r = insert(r, 70) r = insert(r, 60) r = insert(r, 80) inorder(r) >>>OUTPUT # 20 # 30 # 40 # 50 # 60 # 70 # 80
Графы (Graphs)
Граф — это нелинейная структура данных, состоящая из узлов и рёбер. Узлы иногда также называют вершинами, а рёбра — линиями или дугами, которые соединяют любые две вершины графа. Более формально граф можно определить как структуру, состоящую из конечного набора вершин (или узлов) и набора рёбер, которые соединяют пару вершин.
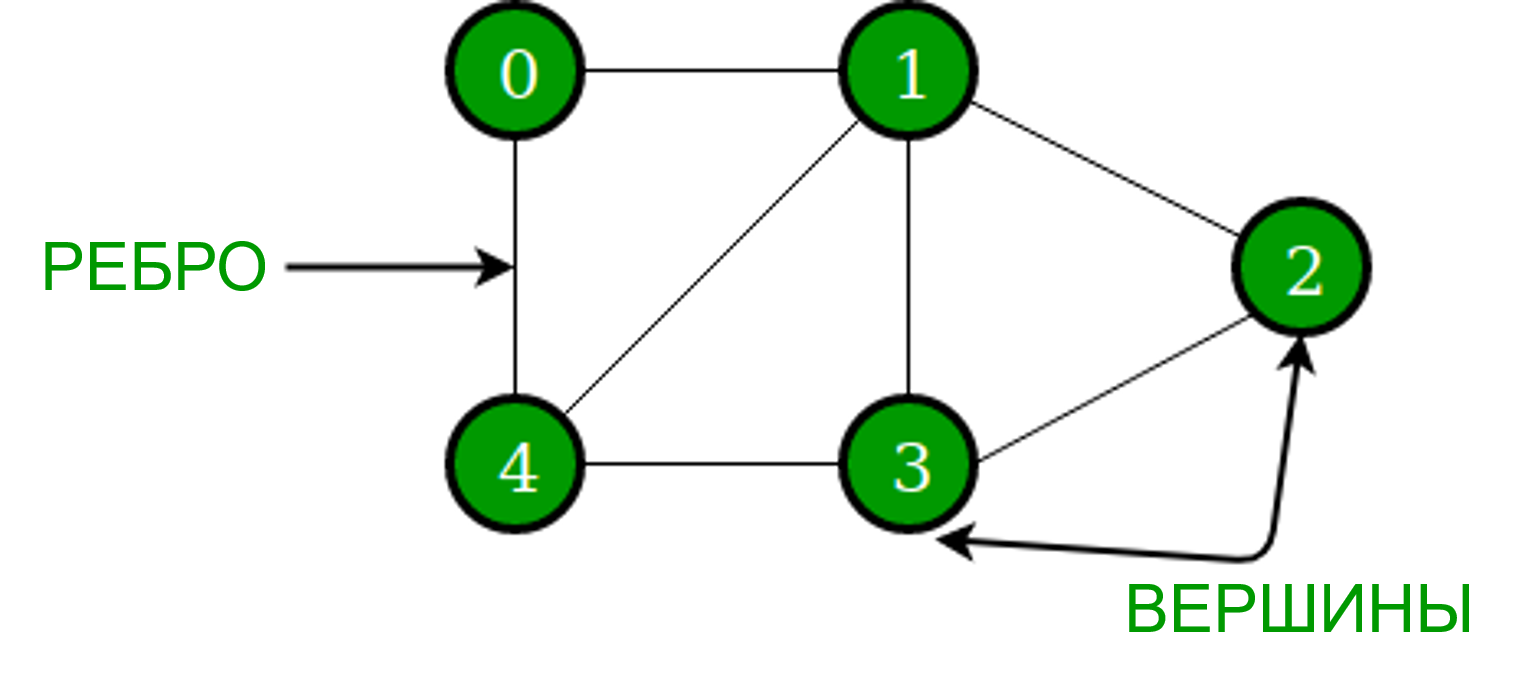
В приведенном выше графе множество вершин V = {0,1,2,3,4} и множество ребер E = {01, 12, 23, 34, 04, 14, 13}. Наиболее часто используемыми представлениями графа являются следующие два типа:
Матрица смежности — это двумерный массив размером V на V, где V — количество вершин в графе. Пусть двумерный массив будет adj[][], слот adj[i][j] = 1 означает, что существует ребро из вершины i в вершину j. Матрица смежности для неориентированного графа всегда симметрична; она также используется для представления взвешенных графов. Если adj[i][j] = w, то существует ребро из вершины i в вершину j с весом w.
# Простое представление графа с помощью матрицы смежности
class Graph:
def __init__(self,numvertex):
self.adj_matrix = [[-1]*numvertex for x in range(numvertex)]
self.numvertex = numvertex
self.vertices = {}
self.verticeslist =[0]*numvertex
def set_vertex(self,vtx,id):
if 0<=vtx<=self.numvertex:
self.vertices[id] = vtx
self.verticeslist[vtx] = id
def set_edge(self,frm,to,cost=0):
frm = self.vertices[frm]
to = self.vertices[to]
self.adj_matrix[frm][to] = cost
# для направленного графа не добавлять это:
self.adj_matrix[to][frm] = cost
def get_vertex(self):
return self.verticeslist
def get_edges(self):
edges = []
for i in range (self.numvertex):
for j in range (self.numvertex):
if (self.adj_matrix[i][j] != -1):
edges.append((self.verticeslist[i],
self.verticeslist[j],
self.adj_matrix[i][j]))
return edges
def get_matrix(self):
return self.adj_matrix
G = Graph(6)
G.set_vertex(0,'a')
G.set_vertex(1,'b')
G.set_vertex(2,'c')
G.set_vertex(3,'d')
G.set_vertex(4,'e')
G.set_vertex(5,'f')
G.set_edge('a','e',10)
G.set_edge('a','c',20)
G.set_edge('c','b',30)
G.set_edge('b','e',40)
G.set_edge('e','d',50)
G.set_edge('f','e',60)
print("Вершины графа:")
print(G.get_vertex())
# Вершины графа:
# ['a', 'b', 'c', 'd', 'e', 'f']
print("Рёбра графа:")
print(G.get_edges())
>>>OUTPUT
# Матрица смежности:
[('a', 'c', 20), ('a', 'e', 10), ('b', 'c', 30),
('b', 'e', 40), ('c', 'a', 20), ('c', 'b', 30),
('d', 'e', 50), ('e', 'a', 10), ('e', 'b', 40),
('e', 'd', 50), ('e', 'f', 60), ('f', 'e', 60)]
print("Матрица смежности:")
print(G.get_matrix())
>>>OUTPUT
# Матрица смежности:
[[-1, -1, 20, -1, 10, -1], [-1, -1, 30, -1, 40, -1],
[20, 30, -1, -1, -1, -1], [-1, -1, -1, -1, 50, -1],
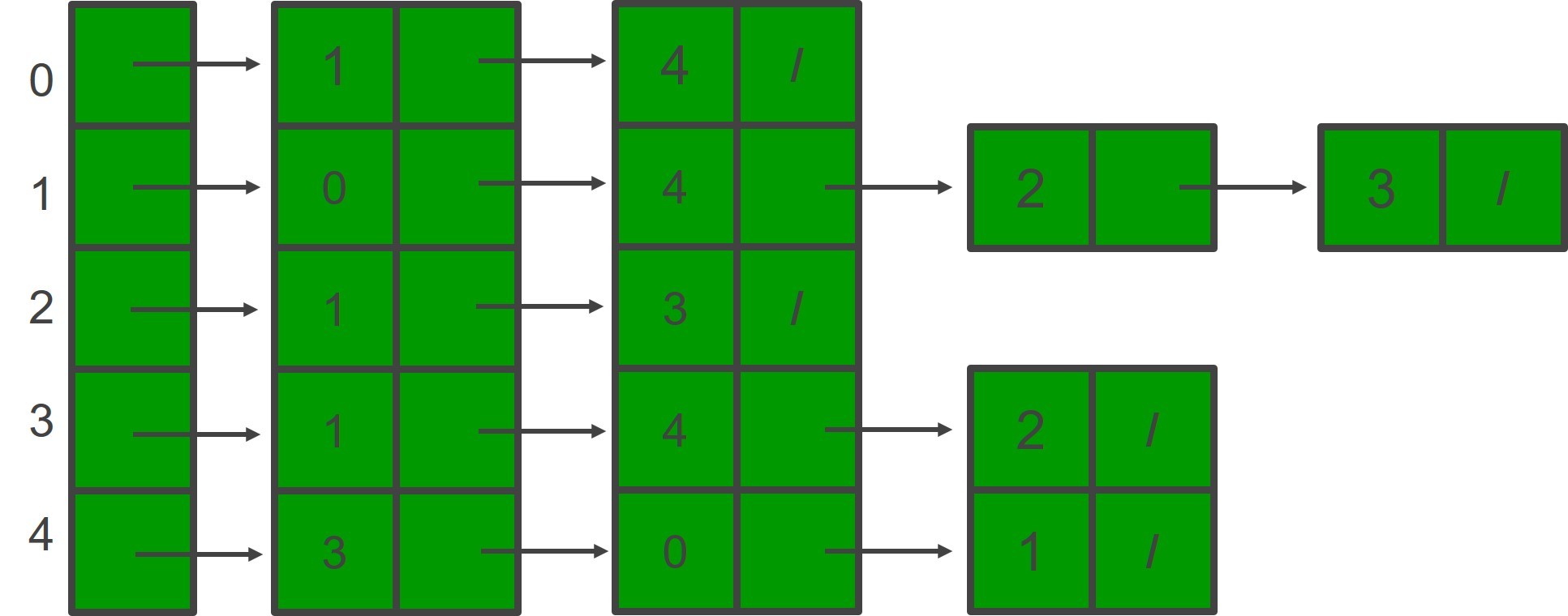
[10, 40, -1, 50, -1, 60], [-1, -1, -1, -1, 60, -1]]Для его создания используется массив списков. Размер массива равен количеству вершин. Пусть массив представляет собой array[]. Запись array[i] представляет собой список вершин, смежных с вершиной i. Веса рёбер могут быть представлены в виде списков пар. Вот представление в виде списка смежности для графа выше.
# Класс для представления списка смежности узла
class AdjNode:
def __init__(self, data):
self.vertex = data
self.next = None
# Класс для представления графа.
# Граф - это список списков смежности.
# Размер массива равен кол-ву вершин "V".
class Graph:
def __init__(self, vertices):
self.V = vertices
self.graph = [None] * self.V
# Функция для добавления ребра в неориентированный граф
def add_edge(self, src, dest):
# Добавление узла к исходному узлу
node = AdjNode(dest)
node.next = self.graph[src]
self.graph[src] = node
# Добавление узла источника к узлу назначения
# так как это неориентированный граф
node = AdjNode(src)
node.next = self.graph[dest]
self.graph[dest] = node
# Функция для вывода графа
def print_graph(self):
for i in range(self.V):
print("Список смежности вершин {}\n начало".format(i), end="")
temp = self.graph[i]
while temp:
print(" -> {}".format(temp.vertex), end="")
temp = temp.next
print(" \n")
if __name__ == "__main__":
V = 5
graph = Graph(V)
graph.add_edge(0, 1)
graph.add_edge(0, 4)
graph.add_edge(1, 2)
graph.add_edge(1, 3)
graph.add_edge(1, 4)
graph.add_edge(2, 3)
graph.add_edge(3, 4)
graph.print_graph()
# Список смежности вершины 0
# начало -> 4 -> 1
# Список смежности вершины 1
# начало -> 4 -> 3 -> 2 -> 0
# Список смежности вершины 2
# начало -> 3 -> 1
# Список смежности вершины 3
# начало -> 4 -> 2 -> 1
# Список смежности вершины 4
# начало -> 3 -> 1 -> 0 Обходы графа
Обход в ширину (Breadth-First Search или BFS)
Обход в ширину для графа похож на аналогичный алгоритм для дерева. Единственная загвоздка в том, что в отличие от деревьев, графы могут содержать циклы, поэтому мы можем прийти к одному и тому же узлу снова. Чтобы избежать обработки узла более одного раза, мы используем массив из булевых значений «посещён/не посещён». Для простоты предполагается, что все вершины достижимы из начальной вершины.
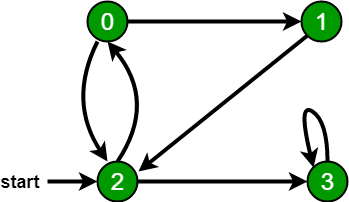
Например, в следующем графе мы начинаем обход с вершины 2. Когда мы приходим к вершине 0, мы ищем все смежные с ней вершины. 2 также является смежной вершиной 0. Если мы не пометим посещённые вершины, то 2 будет обработана снова, и процесс зациклится. BFS следующего графа — 2, 0, 3, 1.
from collections import defaultdict
# Этот класс представляет направленный граф,
# построенный с помощью списка смежности
class Graph:
# конструктор
def __init__(self):
# словарь для хранения графа
self.graph = defaultdict(list)
# ф-ия для добавления ребра к графу
def add_edge(self,u,v):
self.graph[u].append(v)
# ф-ия для печати результата обхода графа
def BFS(self, s):
# Пометить все вершины как не посещённые
visited = [False] * (max(self.graph) + 1)
# Создание очереди для BFS
queue = []
# Пометить исходный узел как посещённый
# и поставить его в очередь
queue.append(s)
visited[s] = True
while queue:
# Удалить вершину из
# очереди и вывести её
s = queue.pop(0)
print (s, end = " ")
# Получить все смежные вершины отложенной вершины s.
# Если смежная вершина не была посещена, то пометить
# её посещённой и поставить в очередь
for i in self.graph[s]:
if visited[i] == False:
queue.append(i)
visited[i] = True
# магия
g = Graph()
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
print("Обход в ширину (начиная с вершины 2)")
g.BFS(2)
# Обход в ширину (начиная с вершины 2)
# 2 0 3 1 Временная сложность — O (V+E), где V — количество вершин в графе, а E — количество рёбер.
Обход в глубину (Depth First Search или DFS)
- Создайте рекурсивную функцию, которая принимает индекс узла и список
visited. - Пометить текущий узел как посещённый и вывести его на печать.
- Пройти по всем соседним и не помеченным узлам и вызвать рекурсивную функцию с индексом соседнего узла.
from collections import defaultdict
# Этот класс представляет направленный граф,
# построенный с помощью списка смежности
class Graph:
# конструктор
def __init__(self):
# словарь для хранения графа
self.graph = defaultdict(list)
# ф-ия для добавления ребра к графу
def add_edge(self, u, v):
self.graph[u].append(v)
# ф-ия для ф-ии DFS
def DFSUtil(self, v, visited):
# помечаем узел как посещённый
# и выводим его
visited.add(v)
print(v, end=' ')
# Повторить для всех вершин,
# смежных с данной вершиной
for neighbour in self.graph[v]:
if neighbour not in visited:
self.DFSUtil(neighbour, visited)
# ф-ия для обхода графа в глубину.
# в ней используется рекурсивная ф-ия DFSUtil()
def DFS(self, v):
# создаём множество, где хранятся все
# посещённые вершины
visited = set()
# вызов рекурсивной спромогательной ф-ии
# для вывода результата обхода графа в глубину
self.DFSUtil(v, visited)
# создаём граф
# как на диаграмме выше
g = Graph()
g.add_edge(0, 1)
g.add_edge(0, 2)
g.add_edge(1, 2)
g.add_edge(2, 0)
g.add_edge(2, 3)
g.add_edge(3, 3)
print("Обход графа в глубину (начиная с вершины 2)")
g.DFS(2)
# Обход графа в глубину (начиная с вершины 2)
# 2 0 1 3 Рекурсия
Процесс, в котором функция прямо или косвенно вызывает саму себя, называется рекурсией, а соответствующая функция — рекурсивной. Некоторые проблемы можно решить довольно легко, если использовать рекурсивные алгоритмы. Примерами таких задач являются Ханойские башни (TOH), обходы деревьев и т.д.
Что такое базовое условие в рекурсии?
В рекурсивной программе дается решение базового случая, а решение большей задачи разбивается на меньшие.
def fact(n):
# базовый случай
if (n < = 1)
return 1
else
return n*fact(n-1)В приведённом выше примере определён базовый случай для n < = 1, и случай с большим числом может быть решён путём преобразования числа в меньшее, пока не будет достигнут базовый случай.
Как выделяется память для различных вызовов функций при рекурсии?
Когда мы вызываем функцию из main(), для неё на стеке выделяется память. Рекурсивная функция вызывает сама себя, память для вызываемой функции выделяется поверх памяти, выделенной для вызывающей функции, и для каждого вызова функции создается своя копия локальных переменных. Когда достигается базовый вариант, функция возвращает своё значение функции, которой она была вызвана, память деаллоцируется, и процесс продолжается.
Давайте рассмотрим работу рекурсии на примере простой функции.
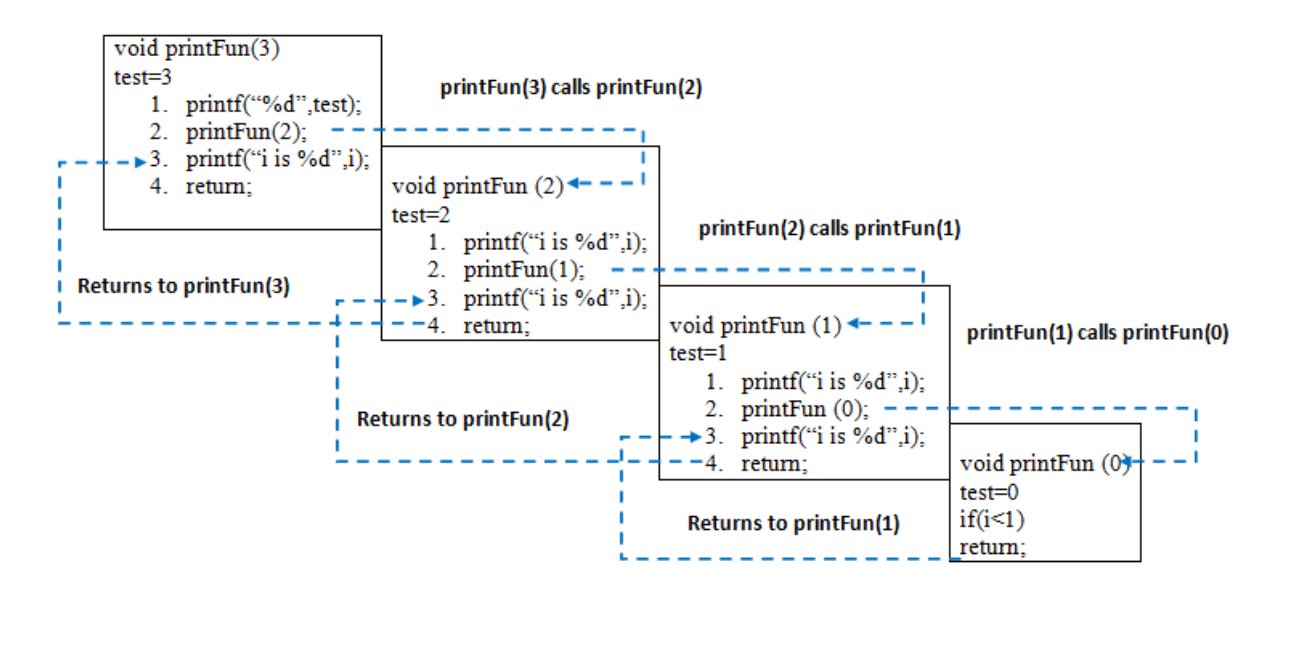
def printFun(test): if (test < 1): return else: print(test, end=" ") printFun(test-1) print(test, end=" ") return test = 3 printFun(test) # 3 2 1 1 2 3
Стек памяти показан на следующей диаграмме.
Динамическое программирование
Динамическое программирование — это, в основном, оптимизация обычной рекурсии. Везде, где мы видим рекурсивное решение, которое имеет повторяющиеся вызовы для одних и тех же входов, можем его оптимизировать с помощью динамического программирования. Идея заключается в том, чтобы хранить результаты подзадач, а не вычислять их заново, когда они понадобятся позже. Эта простая оптимизация уменьшает временные сложности от экспоненциальных до полиномиальных.
Например, если мы напишем простое рекурсивное решение для чисел Фибоначчи, то получим экспоненциальную временную сложность, а если мы оптимизируем его, сохранив решения подзадач, то временная сложность уменьшится до линейной.
# экспоненциальная временная сложность:
def fib1(n):
if n <= 1:
return n
else:
return fib1(n-1) + fib1(n-2)
# линейная временная сложность:
def fib2(n):
if n <= 1:
return n
f = [0, 1]
for i in range(2, n+1):
f.append(f[i-1] + f[i-2])
return f[-1]return f[-1]Табуляция в сравнении с мемоизацией
Существует два различных способа хранения значений, чтобы их можно было использовать повторно. Здесь будут рассмотрены два способа решения задачи динамического программирования (DP):
Давайте опишем состояние для нашей задачи как dp[x] с dp[0] в качестве базового состояния и dp[n] в качестве состояния назначения. Итак, нам нужно найти значение состояния назначения, т.е. dp[n].
Если мы начинаем переход из базового состояния, т.е. dp[0], и, следуя соотношению перехода состояний, достигаем состояния назначения dp[n], мы называем это подходом «снизу вверх», поскольку совершенно ясно, что мы начали переход из нижнего базового состояния и достигли самого верхнего желаемого состояния.
Итак, почему мы называем это методом табуляции?
Чтобы узнать это, давайте сначала напишем код для вычисления факториала числа с использованием подхода «снизу вверх». Сначала определяем состояние. В данном случае мы определяем состояние как dp[x], где dp[x] — это нахождение факториала числа x.
Теперь совершенно очевидно, что dp[x+1] = dp[x] * (x+1):
# находим факториал с помощью табуляции dp = [0]*MAXN # базовый случай dp[0] = 1; for i in range(n+1): dp[i] = dp[i-1] * i
Снова опишем это как переход состояний. Если нам нужно найти значение для некоторого состояния, скажем dp[n], и вместо того, чтобы начинать с базового состояния, т.е. dp[0], мы запрашиваем ответ из состояний, которые могут достичь целевого состояния dp[n], следуя отношению перехода состояний, то это нисходящий пример динамического программирования.
Здесь мы начинаем путь с самого верхнего состояния назначения и вычисляем его ответ, подсчитывая значения состояний, которые могут достичь состояния назначения, пока не достигнем самого нижнего базового состояния.
# находим факториал с помощью меморизации
dp[0]*MAXN
def solve(x):
if (x==0)
return 1
if (dp[x]!=-1)
return dp[x]
return (dp[x] = x * solve(x-1))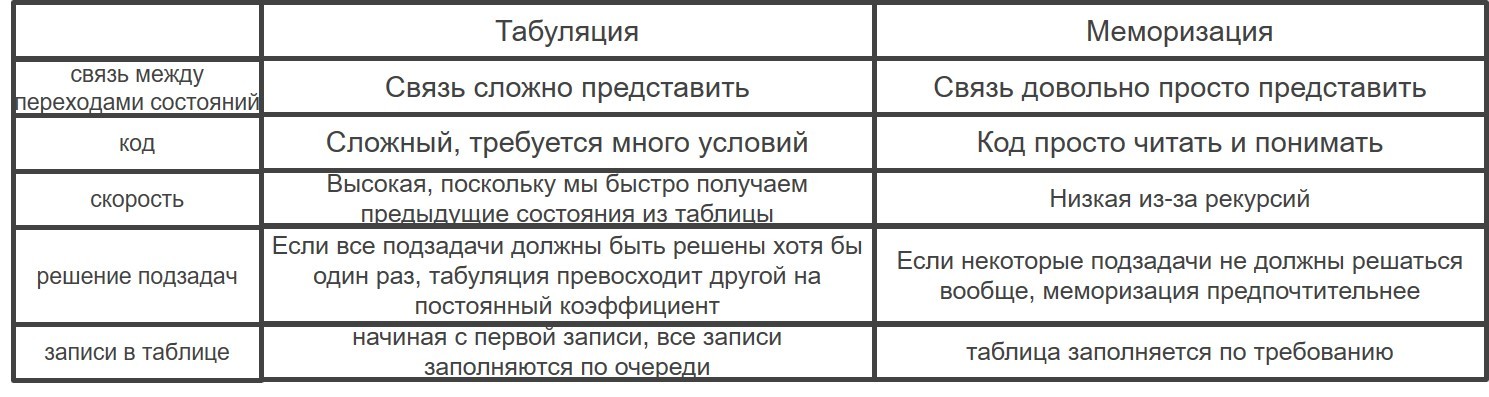
Алгоритмы поиска
Линейный поиск
- Начиная с самого левого элемента массива по очереди сравнить
xс каждым элементом. - Если
xсовпадает с элементом, возвращается индекс. - Если
xне совпадает ни с одним из элементов, верните -1.

def search(arr, n, x):
for i in range(0, n):
if (arr[i] == x):
return i
return -1
arr = [2, 3, 4, 10, 40]
x = 10
n = len(arr)
result = search(arr, n, x)
if(result == -1):
print("Элемента нет в списке")
else:
print("Элемент найден по индексу", result)
# Элемент найден по индексу 3Бинарный поиск
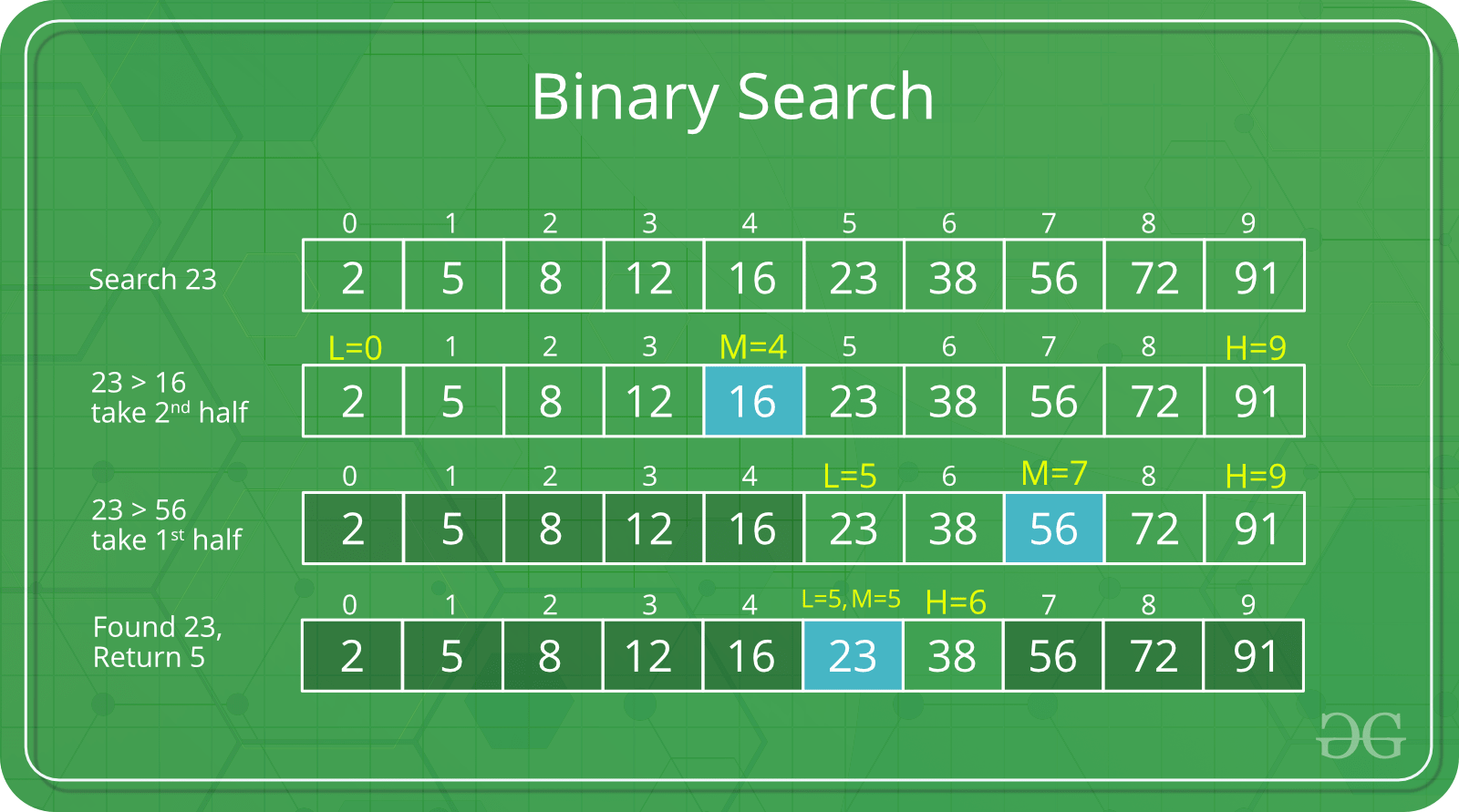
Выполните поиск в отсортированном массиве, многократно деля интервал поиска пополам. Начните с интервала, охватывающего весь массив. Если значение ключа поиска меньше, чем элемент в середине интервала, сузьте интервал до нижней половины. В противном случае сузьте его до верхней половины. Повторяйте проверку до тех пор, пока значение не будет найдено или интервал не окажется пустым.
def binary_search(arr, l, r, x):
# базовый случай
if r >= l:
mid = l + (r - l) // 2
# если элемент ровно посередине
if arr[mid] == x:
return mid
# если элемент меньше середины,
# искать его слева
elif arr[mid] > x:
return binary_search(arr, l, mid-1, x)
# иначе - справа
else:
return binary_search(arr, mid + 1, r, x)
else:
# элемент не найден в списке
return -1
arr = [ 2, 3, 4, 10, 40 ]
x = 10
result = binary_search(arr, 0, len(arr)-1, x)
if result != -1:
print("Элемент найден по индексу", result)
else:
print("Элемента нет в списке")
# Элемент найден по индексу 3Временная сложность — O(log(n)).
Алгоритмы сортировки
Сортировка по выбору
Этот алгоритм сортирует массив, многократно находя минимальный элемент (в порядке возрастания) из неотсортированной части и помещая его в начало. На каждой итерации выбирается минимальный элемент (в порядке возрастания) из неотсортированного подмассива и перемещается в отсортированный подмассив.
import sys
A = [64, 25, 12, 22, 11]
# перебор всех элементов массива
for i in range(len(A)):
# нахождение минимального элемента
# в несортированном списке
min_idx = i
for j in range(i+1, len(A)):
if A[min_idx] > A[j]:
min_idx = j
# замена элемента с минимальным значением
# на первый элемент
A[i], A[min_idx] = A[min_idx], A[i]
print("Отсортированный список:")
for i in range(len(A)):
print(f"{A[i]}")
# Отсортированный список:
# 11
# 12
# 22
# 25
# 64Временная сложность — O (n**2), так как имеется два вложенных цикла.
Вспомогательное пространство: O(1)
Пузырьковая сортировка
Это простейший алгоритм сортировки, который работает путем многократной перемены мест соседних элементов, если они расположены в неправильном порядке.
def bubble_sort(arr):
n = len(arr)
# перебор всех элементов списка
for i in range(n):
# последние i элементов на месте
for j in range(0, n-i-1):
# обход элементов от 0 до n-i-1
# поменять местами, если найденный элемент
# больше следующего
if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j]
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("Отсортированный список:")
for i in range(len(arr)):
print(f"{arr[i]}")
# Отсортированный список:
# 11
# 12
# 22
# 25
# 34
# 64
# 90Временная сложность — O(n**2).
Сортировка вставкой
Чтобы отсортировать массив размера n по возрастанию, используйте сортировку вставкой:
- Переберите список от
arr[1]доarr[n]. - Сравните текущий элемент с его предыдущим.
- Если ключевой элемент меньше своего предшественника, сравните его с предыдущими элементами. Переместите больший элемент на одну позицию вверх, чтобы освободить место для поменявшегося элемента.

def insertion_sort(arr):
# перебор от 1 до len(arr)
for i in range(1, len(arr)):
key = arr[i]
# Переместить элементы arr[0..i-1],
# которые больше ключа,
# на одну позицию вперед от их текущей позиции
j = i-1
while j >= 0 and key < arr[j] :
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
arr = [12, 11, 13, 5, 6]
insertion_sort(arr)
for i in range(len(arr)):
print(f"{arr[i]}")
# 5
# 6
# 11
# 12
# 13Временная сложность — O (n**2).
Сортировка слиянием
Этот алгоритм делит входной массив на две половины, вызывает себя для двух половин, а затем объединяет две отсортированные половины. Для слияния двух половин используется функция merge(). Merge(arr, l, m, r) — это ключевой процесс, который предполагает, что arr[l..m] и arr[m+1..r] отсортированы, и объединяет два отсортированных подмассива в один.
MergeSort(arr[], l, r)
Если r > l
1. Найдите среднюю точку, чтобы разделить массив на две половины:
середина m = l+ (r-l)/2
2. Вызовите mergeSort для первой половины:
вызов mergeSort(arr, l, m)
3. Вызовите mergeSort для второй половины:
вызов mergeSort(arr, m+1, r).
4. Объедините две половины, отсортированные на шаге 2 и 3:
вызов merge(arr, l, m, r)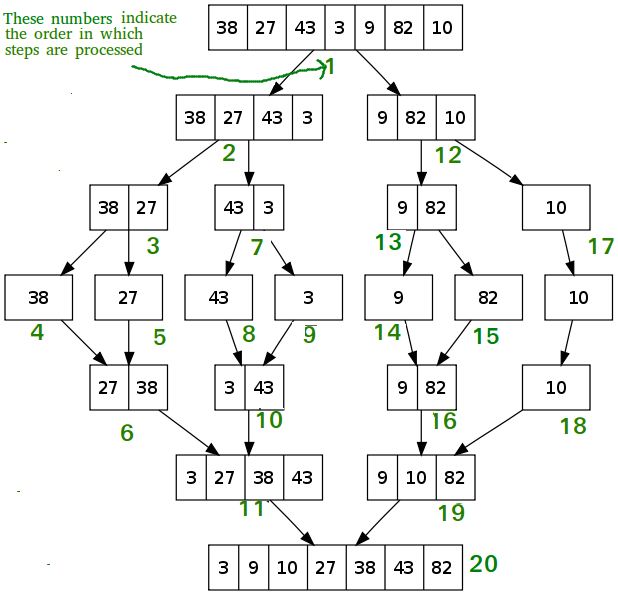
def merge_sort(arr):
if len(arr) > 1:
# находим середину списка
mid = len(arr)//2
# делим список
L = arr[:mid]
# на две половины
R = arr[mid:]
# сортируем первую
merge_sort(L)
# сортируем вторую
merge_sort(R)
i = j = k = 0
# копируем данные во временные списки L[] и R[]
while i < len(L) and j < len(R):
if L[i] < R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
# проверяем, что ничего не потеряли
while i < len(L):
arr[k] = L[i]
i += 1
k += 1
while j < len(R):
arr[k] = R[j]
j += 1
k += 1
def print_list(arr):
for i in range(len(arr)):
print(arr[i], end=" ")
print()
if __name__ == '__main__':
arr = [12, 11, 13, 5, 6, 7]
print("Изначальный список:", end="\n")
print_list(arr)
merge_sort(arr)
print("Отсортированный список: ", end="\n")
print_list(arr)
# Изначальный список:
# 12 11 13 5 6 7
# Отсортированный список:
# 5 6 7 11 12 13 Временная сложность — O (n (logn)).
Алгоритм быстрой сортировки
Он выбирает элемент за основу и разбивает заданный массив вокруг него. Существует много различных версий этого алгоритма, которые выбирают основу разными способами:
- Всегда выбирать последний элемент в качестве основы (реализовано ниже).
- Выбирать случайный элемент в качестве основы.
- Выбрать медиану в качестве основы.
Ключевым процессом в алгоритме является partition(). Его задача состоит в том, чтобы, учитывая массив и элемент x из массива в качестве основы, поместить x на его правильную позицию в отсортированном массиве и поместить все меньшие элементы перед x, а все большие элементы — после x. Всё это должно быть выполнено за линейное время.
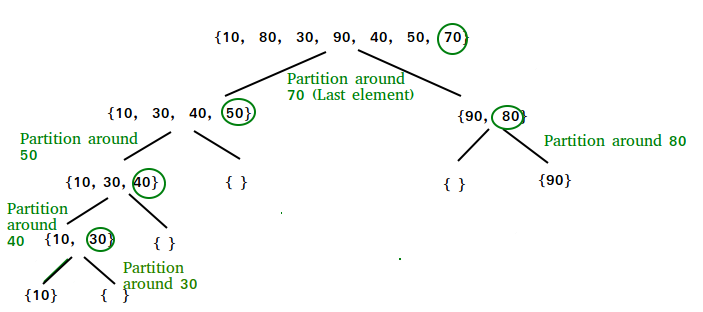
Алгоритм разбивки
Разбиение может быть выполнено разными способами, следующий псевдокод использует метод, логика которого проста: мы начинаем с самого левого элемента и отслеживаем индекс меньших (или равных) элементов как i. При обходе, если мы находим меньший элемент, мы меняем текущий элемент на arr[i]. В противном случае мы игнорируем текущий элемент.
/* low --> начальный индекс, high --> конечный индекс */
quickSort(arr[], low, high)
{
if (low < high)
{
/* pi - индекс разбиения, arr[pi] теперь
в нужном месте */
pi = partition(arr, low, high);
quickSort(arr, low, pi - 1); // Перед pi
quickSort(arr, pi + 1, high); // После pi
}
}# ф-ия сортировки
# start и end - первый и последний
# элементы списка
def partition(start, end, array):
# определяем индекс основы
pivot_index = start
pivot = array[pivot_index]
while start < end:
# увеличиваем start пока не найдём
# элемент больше, чем основа
while start < len(array) and array[start] <= pivot:
start += 1
# уменьшаем end пока не найдём
# элемент меньше основы
while array[end] > pivot:
end -= 1
if(start < end):
array[start], array[end] = array[end], array[start]
# Поменяйте местами элементы
# Это помещает основу на её правильное отсортированное место
array[end], array[pivot_index] = array[pivot_index], array[end]
# возвращает основу-разделитель
return end
# ф-ия быстрой сортировки
def quick_sort(start, end, array):
if (start < end):
p = partition(start, end, array)
# сортировка элементов
# до разделения и после
quick_sort(start, p - 1, array)
quick_sort(p + 1, end, array)
array = [ 10, 7, 8, 9, 1, 5 ]
quick_sort(0, len(array) - 1, array)
print(f'Отсортированный список: {array}')
# Отсортированный список: [1, 5, 7, 8, 9, 10]Временная сложность — O (n (logn)).
ShellSort
Является разновидностью сортировки вставкой. При сортировке вставкой мы перемещаем элементы только на одну позицию вперёд. Когда элемент должен быть перемещён далеко вперед, требуется много перемещений. Идея ShellSort заключается в том, чтобы позволить обмен дальними элементами. Мы делаем массив h-сортированным для большого значения h и продолжаем уменьшать значение h, пока оно не станет равным 1. Массив считается h-сортированным, если все подсписки каждого h-го элемента отсортированы.
def shell_sort(arr):
gap = len(arr) // 2 определяем промежутокap
while gap > 0:
i = 0
j = gap
# проверяем массив слева направо
# до последнего возможного индекса j
while j < len(arr):
if arr[i] >arr[j]:
arr[i],arr[j] = arr[j],arr[i]
i += 1
j += 1
# теперь смотрим назад от i-го индекса влево
# меняем местами значения, которые не
# находятся в правильном порядке
k = i
while k - gap > -1:
if arr[k - gap] > arr[k]:
arr[k-gap],arr[k] = arr[k],arr[k-gap]
k -= 1
gap //= 2
arr2 = [12, 34, 54, 2, 3]
print("Начальный список:",arr2)
# Начальный список: [12, 34, 54, 2, 3]
shell_sort(arr2)
print("Сортированный список:",arr2)
# Сортированный список: [2, 3, 12, 34, 54]Временная сложность — O(n**2).
Источник: Geeks for Geeks
Перевод: Екатерина Прохорова