Линейная регрессия и её регуляризация в Scikit-learn

В этой статье мы рассмотрим модели линейной регрессии, доступные в scikit-learn. Обсудим, что такое регуляризация, на примерах Ridge, Lasso и Elastic Net, а также покажем, как эти методы можно реализовать на Python.
Создание модели линейной регрессии относится к задачам обучения с учителем, цель которых — предсказать значение непрерывной зависимой переменной (y) на основе набора признаков (X).
Одним из ключевых допущений любой модели линейной регрессии является предположение, что зависимая переменная (y) в некоторой степени линейно зависит от независимых переменных (Xi). Это означает, что мы можем оценить значение y, используя математическое выражение:

где bi — это коэффициенты, которые должны быть подобраны моделью.
Функция потерь, которую мы стремимся минимизировать, представляет собой сумму квадратов ошибок (также называемых остатками). Такой подход обычно называют методом наименьших квадратов (МНК). Другими словами, нам нужны те оптимальные значения bi, которые минимизируют следующую функцию:

где игрек с "крышечкой" — это значения, прогнозируемые моделью.
Хотя МНК и хорошо работает во многих случаях, у него есть свои недостатки, когда данные имеют значимые выбросы или когда независимые переменные (Xi) сильно коррелируют друг с другом.
Это может оказать значительное влияние на общее качество прогноза. В таких случаях будет оправдано применение регуляризации.
Двумя наиболее популярными методами регуляризации являются ridge- регрессия и lasso-регрессия, которые мы обсудим в данном материале.
Давайте начнем с основ, то есть импортируем необходимые библиотеки и загрузим данные.
Импорт библиотек и загрузка данных
Нам понадобятся pandas, numpy и matplotlib, а также сам scikit-learn:
import numpy as np import pandas as pd import matplotlib.pylab as plt import sklearn
Scikit-learn включает в себя несколько стандартных наборов данных, одним из которых являются данные о диабете. В нём содержится информацию о 442 пациентах. Для каждого из них указаны десять исходных характеристик: возраст, пол, индекс массы тела, среднее кровяное давление, а также шесть измерений сыворотки крови (s1, s2, s3, s4, s5 и s6). Также имеется интересующая нас целевая переменная — количественная оценка прогрессирования заболевания (y) через год после первоначального обследования
Полученная модель может быть использована для двух важных задач:
- во-первых, определение важных особенностей (из десяти упомянутых выше), которые способствуют прогрессированию заболевания.
- во-вторых, для прогнозирования развития заболевания у новых пациентов.
Каждый из признаков был центрирован по среднему значению и масштабирован на стандартное отклонение, умноженное на количество образцов (n_samples). Таким образом, сумма квадратов значений каждого столбца составляет 1.
Давайте сохраним данные в переменные X и y. Параметр as_frame=True указывает, что данные должны быть загружены в виде датафрейма pandas, а параметр return_X_y=True указывает, что данные должны быть разделены на признаки (X) и целевую переменную (y).
В результате переменная X содержит DataFrame с признаками, а переменная y содержит Series с целевой переменной.
from sklearn import datasets X, y = datasets.load_diabetes(as_frame=True, return_X_y=True) display(X) display(y)


И вот мы можем перейти к построению и сравнению различных регрессионных моделей. Однако перед этим нам необходимо выбрать подходящую методологию для их оценки и сравнения.
Метрика оценки качества моделей
Scikit-learn предлагает множество метрик, которые могут помочь нам оценить качество модели. Для нашей задачи мы будем использовать neg_mean_squared_error.
В библиотеке все реализовано так, что всегда более высокое значение метрики лучше, чем более низкое. Но метрики, которые измеряют расстояние между реальным значением и прогнозом должны быть минимизированы для улучшения модели, например, поэтому mean_squared_error, доступен в виде neg_mean_squared_error. Например, модель с значением neg_mean_squared_error равным -100 будет лучше, чем модель с значением -150. То есть к таким метрикам просто добавляется минус.
Можно ознакомиться со всеми доступными в библиотеке метриками, выполнив следующую команду:
sklearn.metrics.SCORERS
Простая линейная регрессия
Простейшая форма линейной регрессии — это когда у нас есть только один признак для прогноза целевой переменной. Известно, что хороший ИМТ (индекс массы тела) способствует снижению вероятности развития диабета.
Мы можем количественно оценить это соотношение, используя простую модель линейной регрессии. Для начала сделаем выборку только из одного столбца (bmi):
bmi = X[['bmi']]
# Импорт класса LinearRegression из модуля linear_model пакета scikit-learn from sklearn.linear_model import LinearRegression # Создание экземпляра класса LinearRegression simple_lr = LinearRegression() # Обучение модели simple_lr.fit(bmi, y) # Прогнозирование целевой переменной и сохранение результата в predicted_y predicted_y = simple_lr.predict(bmi)
Наконец, давайте визуализируем линию регрессии для нашей модели, чтобы получить наглядное представление результата:
# Построение линии регрессии на точечной диаграмме
plt.figure(figsize=(10, 6))
plt.scatter(bmi, y)
plt.plot(bmi, predicted_y, c = 'r')
plt.title('Scatter plot and a Simple Linear Regression Model')
plt.ylabel("y")
plt.xlabel("bmi")
plt.show()
На представленном выше графике синие точки обозначают фактические значения (X, y). Визуально можно заметить, что между индексом массы тела (ИМТ) и развитием диабета (y) существует положительная линейная зависимость, которую пытается уловить наша модель (красная линия). Но насколько хорошо ей это удаётся?
Функция cross_val_score из модуля model_selection пакета scikit-learn принимает в качестве аргументов объект модели, матрицу признаков, вектор с целевой переменной, метрику качества (в нашем случае neg_mean_squared_error) и cv.
Установка значения cv равным 10 означает, что для данных будет выполнена перекрестная оценка модели на 10 отложенных подвыборках по выбранной метрики качества и вернётся соответствующий массив из neg_mean_squared_errors.
Мы будем использовать среднее значение всех этих десяти результатов в качестве показателя того, насколько хороша модель.
# Импорт функции cross_val_score из модуля model_selection scikit-learn
from sklearn.model_selection import cross_val_score
# Сохранение десяти метрик в переменной mse
mse = cross_val_score(simple_lr,
bmi,
y,
scoring='neg_mean_squared_error',
cv=10)
# Получение среднего значения для оценки качества модели
mse.mean()
# -3906.9189901068407Таким образом, наша простая модель линейной регрессии simple_lr имеет среднее значение метрики neg_mean_squared_error, равное -3906,92.
Давайте посмотрим, насколько улучшится модель, если мы добавим дополнительные признаки, то есть построим модель множественной линейной регрессии.
Множественная линейная регрессия
Основные шаги остаются такими же, как и в предыдущей модели, за исключением того, что мы будем использовать всю матрицу признаков X, состоящую из десяти столбцов, вместо одного из них:
# обучение модели на всех признаках
multiple_lr = LinearRegression().fit(X, y)
# Сохраняем массив с результатами оценки качества
mse = cross_val_score(multiple_lr,
X,
y,
scoring='neg_mean_squared_error',
cv=10)
# Получение среднего значения метрик для оценки качества модели
mse.mean()
# -3000.3902901608426Мы видим, что добавление девяти оставшихся признаков в модель вместе с ИМТ увеличивает среднее значение neg_mean_squared_error почти с -3906.92 до примерно -3000.39, что является значительным улучшением.
Давайте посмотрим на все десять значений коэффициентов для модели multiple_lr:
# Сохранение массива, содержащего все десять коэффициентов multiple_lr_coeffs = multiple_lr.coef_ multiple_lr_coeffs # array([ -10.0098663 , -239.81564367, 519.84592005, 324.3846455 , # -792.17563855, 476.73902101, 101.04326794, 177.06323767, # 751.27369956, 67.62669218])
Обратите внимание, что ни одно из расчетных значений коэффициента не равно 0. Построим визуализацию по этим коэффициентам при помощи matplotlib:
# Извлечение имен столбцов из датафрейма df
feature_names = X.columns
# Используем matplotlib для построения графика
plt.figure(figsize=(10, 6))
plt.plot(range(len(multiple_lr_coeffs)), multiple_lr_coeffs)
plt.axhline(0, color = 'r', linestyle = 'solid')
plt.xticks(range(len(feature_names)), feature_names, rotation = 50)
plt.title("Coefficients for Multiple Linear Regression")
plt.ylabel("coefficients")
plt.xlabel("features")
plt.show()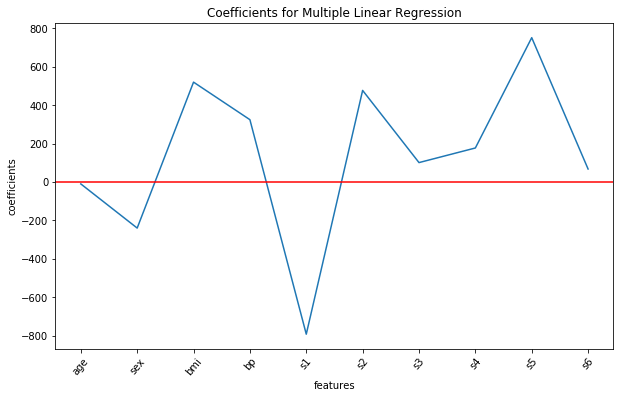
Мы видим, что в этой модели признаки ИМТ, s1, s2 и s5 оказывают значительное влияние на прогрессирование диабета, поскольку все они имеют высокие значения коэффициентов.
Зачем нужна регуляризация?
Одним из ключевых допущений модели множественной линейной регрессии является отсутствие мультиколлинеарности между переменными. Это означает, что в идеале переменные не должны быть связаны друг с другом, либо связь должна быть очень слабой.
Если же наблюдается сильная корреляция между двумя признаками, это может вызвать ряд проблем. Включение одной из них в модель практически не улучшит ее, а только усложнит. Это противоречит принципу «бережливости» в построении моделей, который гласит, что более простая модель с меньшим количеством признаков лучше, чем сложная модель с избыточным количеством признаков.
Кроме того, в такой ситуации вся модель регрессии становится менее надежной, так как оценки коэффициентов имеют большую дисперсию. Это означает, что они плохо обобщают новые данные, и возникает проблема переобучения.
Корреляцию между всеми признаками можно визуализировать с помощью корреляционной матрицы:
X.corr().style.background_gradient(cmap = 'coolwarm')

Приведенная выше матрица показывает корреляции между признаками таким образом, что более темные оттенки красного подразумевают высокую положительную корреляцию, а более темные оттенки синего подразумевают высокие отрицательные значения корреляции.
В линейной модели, которую мы построили в предыдущем разделе, переменные s1 и s2 оказались важными. Однако, как видно из матрицы, они имеют очень высокую положительную корреляцию — около 0.897. Это, безусловно, вносит в модель проблему мультиколлинеарности.
Чтобы решить эту проблему, мы можем обратиться к методам регуляризации. Эти методы позволяют снизить дисперсию модели, добавляя некоторое смещение, что в итоге приводит к уменьшению общей ошибки. Меньшая дисперсия означает, что проблема переобучения будет автоматически решена, так как модель сможет успешно обобщать новые данные.
Методы регуляризации работают путем добавления штрафных коэффициентов к исходной функции потерь модели таким образом, что высокие значения коэффициентов снижаются. А признаки с очень низкими значениями коэффициентов (после штрафования) могут быть вообще отброшены. Это помогает уменьшать сложность модели.
Существует множество методов регуляризации, но мы сосредоточим внимание на трех наиболее часто используемых: Rigde, Lasso и Elastic Net.
Что такое Ridge-регрессия?
Ridge-регрессия (часто называемая L2-регуляризацией) — это метод регуляризации, целью которого является нахождение тех оптимальных значений коэффициентов, которые минимизируют следующую функцию потерь:

Здесь альфа — это гиперпараметр, представляющий силу регуляризации. Высокое значение альфа налагает высокий штраф на сумму квадратов значений коэффициентов.
Значение альфа может принимать любое положительное вещественное число. Когда альфа равна нулю, мы получаем реализацию стандартной множественной линейной регрессии.
Поскольку альфа является гиперпараметром, его оптимальное значение (которое максимизирует среднее значение neg_mean_squared_error для модели) можно найти с помощью алгоритма GridSearchCV в scikit-learn следующим образом:
# Импорт класса Ridge из модуля linear_model scikit-learn
from sklearn.linear_model import Ridge
# Импорт класса GridSearchCV из модуля model_selection scikit-learn
from sklearn.model_selection import GridSearchCV
# Создание словаря, содержащего потенциальные значения альфа
alpha_values = {'alpha': [0.001, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.08, 1, 2, 3, 5, 8, 10, 20, 50, 100]}
# Передача в GridSearchCV Ridge-модели, потенциальных альфа-значений,
# метрики качества
ridge = GridSearchCV(Ridge(),
alpha_values,
scoring='neg_mean_squared_error',
cv=10)
# обучение модели
print('Лучшее значение alpha:', ridge.fit(X, y).best_params_)
# Вывод среднего значения neg_mean_squared_error
print('Метрика качества:', ridge.fit(X, y).best_score_)
# Лучшее значение alpha: {'alpha': 0.04}
# Метрика качества: -2997.195810600043Мы видим, что регуляризация нашей модели множественной линейной регрессии увеличивает среднее значение neg_mean_squared_error с -3000.39 до примерно -2997.19. Улучшение небольшое, но есть.
Давайте визуализируем все десять коэффициентов модели:
# Создание объекта, содержащего наилучшую модель
best_ridge_model = Ridge(alpha=0.04)
# Извлечение оценок коэффициентов для всех десяти признаков
best_ridge_coeffs = best_ridge_model.fit(X, y).coef_
# Построение графика c коэффициентами для всех десяти признаков
plt.figure(figsize = (10, 6))
plt.plot(range(len(feature_names)), best_ridge_coeffs)
plt.axhline(0, color = 'r', linestyle = 'solid')
plt.xticks(range(len(feature_names)), feature_names, rotation = 50)
plt.title("Coefficient estimates from Ridge Regression")
plt.ylabel("coefficients")
plt.xlabel("features")
plt.show()
Ранее признаки s1 и s2 выделялись как значимые, однако значения их коэффициентов значительно уменьшаются после регуляризации. Признаки bmi и s5 по-прежнему значимы.
Что такое Lasso-регрессия?
Lasso-регрессия, также известная как L1-регуляризация, представляет собой метод регуляризации, который работает по тем же принципам, что и Ridge, но с одним существенным отличием. В случае Lasso штрафной коэффициент определяется как сумма абсолютных значений оценок коэффициентов, а не их квадратов.
Таким образом, цель Lasso-регрессии состоит в том, чтобы найти те оптимальные оценки коэффициентов, которые минимизируют следующую функцию потерь:

Здесь альфа по-прежнему является гиперпараметром, представляющим силу регуляризации. Высокое значение альфа налагает высокий штраф на сумму величин значений коэффициентов. Значение альфа может быть любым положительным вещественным числом, как и раньше.
Мы можем использовать следующий код, чтобы получить оптимальное значение альфа в случае Lasso-регрессии с использованием алгоритма GridSearchCV:
# Импорт класса Lasso из модуля linear_model scikit-learn
from sklearn.linear_model import Lasso
# Создание словаря, содержащего потенциальные значения альфа
alpha_values = {'alpha': [0.001, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06,0.07, 0.08, 1, 2, 3, 5, 8, 10, 20, 50, 100]}
# Передача в GridSearchCV модели, потенциальных альфа-значений,
# метрики качества
lasso = GridSearchCV(Lasso(),
alpha_values,
scoring='neg_mean_squared_error',
cv=10)
# Обучение модели
print('Лучшее значение alpha:', lasso.fit(X, y).best_params_)
# Вывод среднего значения neg_mean_squared_error
print('Метрика качества:', lasso.fit(X, y).best_score_)
# Лучшее значение alpha: {'alpha': 0.06}
# Метрика качества: -2987.4275179741567Видим, что использование Lasso приводит к несколько лучшим результатам, чем применение Ridge-регуляризации. Среднее значение neg_mean_squared_error увеличивается почти на 14 единиц, с -3000.39 до -2987.43 (по сравнению с -2997.19 для Ridge-регуляризации).
Давайте визуализируем все десять значений коэффициентов для Lasso:
# Создание объекта, содержащего наилучшую Lasso-модель
best_lasso_model = Lasso(alpha=0.06)
# сохранение значений коэффициентов для всех десяти признаков
best_lasso_coeffs = best_lasso_model.fit(X, y).coef_
# Построение графика значений коэффициентов для всех десяти объектов
plt.figure(figsize = (10, 6))
plt.plot(range(len(feature_names)), best_lasso_coeffs)
plt.axhline(0, color = 'r', linestyle = 'solid')
plt.xticks(range(len(feature_names)), feature_names, rotation = 50)
plt.title("Coefficient estimates from Lasso Regression")
plt.ylabel("coefficients")
plt.xlabel("features")
plt.show()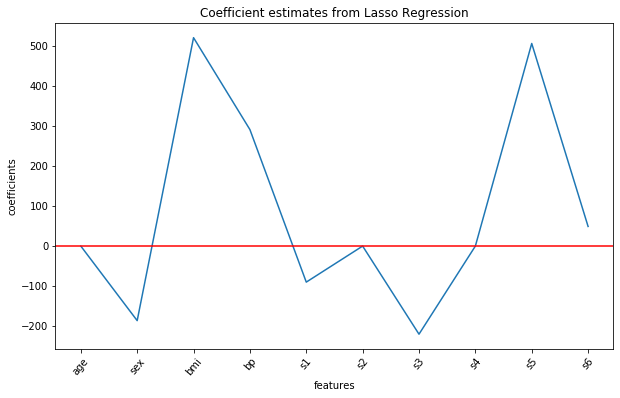
Lasso-регуляризация полностью исключает из модели признаки age, s2 и s4 (поскольку их коэффициенты равны 0) и даёт нам более более простую модель с меньшим количеством признаков и с общим лучшим результатом.
Что такое Elastic Net регрессия?
Регуляризация Elastic Net сочетает в себе преимущества Lasso и Ridge-регуляризации в одной инструменте. Функция потерь, которая должна быть минимизирована для неё, равна:

Приведенная выше функция потерь имеет два гиперпараметра: alpha и l1_ratio. Альфа в случае регуляризации Elastic Net — это константа, которая умножается на штрафы и для L1 (Lasso), и для L2 (Ridge). Гиперпараметр l1_ratio называется параметром смешивания таким образом, что 0 <= l1_ratio <= 1.
Когда l1_ratio равен 1, это означает, что доля L1 (Lasso) равна 100%, а доля L2 (Ridge) равна 0%, то есть по факту просто делается Lasso-регуляризация. Аналогично, когда l1_ratio равно 0, это то же самое, что обычная Ridge-регуляризация.
Оптимальные значения как для alpha, так и для l1_ratio могут быть определены с помощью алгоритма GridSearchCV следующим образом:
from sklearn.linear_model import ElasticNet
alpha_values = {'alpha': [0.00005,0.0005,0.001, 0.01, 0.05, 0.06, 0.08, 1, 2, 3, 5, 8, 10, 20, 50, 100],
'l1_ratio': [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,1]}
elastic = GridSearchCV(ElasticNet(),
alpha_values,
scoring='neg_mean_squared_error',
cv=10)Давайте теперь взглянем на лучшие значения для гиперпараметров alpha и l1_ratio, а также качество Elastic Net:
print(elastic.fit(X, y).best_params_)
# {'alpha': 0.06, 'l1_ratio': 1}
print(elastic.fit(X, y).best_score_)
# -2987.4275179741567В этом случае наилучшее значение l1_ratio оказывается равным 1, что совпадает с Lasso-регуляризацией. Следовательно, лучший результат остается таким же, как и полученный ранее.
Резюме
Давайте сравним коэффициенты, полученные из следующих методов:
- Множественная линейная регрессия без регуляризации
- Регуляризация с помощью Ridge
- Регуляризация с использованием Lasso
Следует отметить, что в нашем случае результаты применения регуляризации Elastic Net были идентичны результатам Lasso, поэтому мы не будем рассматривать их отдельно.
Ниже представлен код, который отображает оценки коэффициентов из всех трёх моделей в виде датафрейма:
# Создание датафрейма, содержащего коэффициенты трёх моделей
comparing_models = pd.DataFrame({'without_regularization': multiple_lr_coeffs,
'Ridge': best_ridge_coeffs,
'Lasso': best_lasso_coeffs},
index=feature_names)
display(comparing_models) 
Кроме того, мы можем визуализировать значения коэффициентов для всех трёх моделей на одном графике для более наглядного сравнения. Вот как это можно сделать:
comparing_models.plot(figsize = (10, 6))
plt.axhline(0, color = 'r', linestyle = 'solid')
plt.title("Coefficients for Linear, Ridge & Lasso Regressions")
plt.ylabel("coefficients")
plt.xlabel("features")
plt.show()
- Ridge-регуляризация значительно снижает значения коэффициентов, приближая их к нулю, однако не устанавливает их точно в ноль.
- Lasso-регуляризация же, напротив, полностью исключает некоторые признаки из модели, такие как "age", "s2" и "s4" в нашем примере, присваивая их коэффициентам нулевые значения. Это упрощает модель.
Кроме того, Lasso-регуляризация демонстрирует лучшую метрику качества (-2987.43) из всех трех моделей. В этом конкретном случае она является явным победителем, однако не всегда так бывает.
Lasso-регуляризация обычно показывает лучшие результаты, когда относительно небольшое количество признаков имеют большие коэффициенты, такие как "bmi" и "s5" в нашем примере.
А Ridge-регрессия демонстрирует более высокую эффективность, когда коэффициенты имеют примерно одинаковый размер, то есть все признаки влияют на целевую переменную примерно одинаково.
Источник: QuantInsti
👉🏻Подписывайтесь на PythonTalk в Telegram 👈🏻