Регулярные выражения в Python
Хочешь знать больше о Python?
Подпишись на наш канал о Python в Telegram!
Сайт pythonist.ru опубликовал перевод статьи «Python Regular Expression». Представляем его вашему вниманию.

Сегодня мы хотим поговорить о регулярных выражениях в Python. Пожалуй, стоит начать с определения. Регулярные выражения, иногда называемые re, regex или regexp, представляют собой последовательности символов, составляющие шаблоны, соответствия которым ищутся в строке или тексте. Для работы с regexp в Python есть встроенный модуль re.
Обычное использование регулярного выражения:
- Поиск подстроки в строке (
searchandfind) - Поиск всех подходящих строк (
findall) - Разделение строки на подстроки (
split) - Замена части строки (
sub)
Основы
Регулярное выражение – это комбинация символов и метасимволов. Из метасимволов доступны следующие:
\используется для игнорирования специального значения символа[]указывает на класс символов. Например: [a-z] — все буквы латинского алфавита в нижнем регистре, [a-zA-Z0-9] — все буквы в обоих регистрах плюс цифры^соответствует началу текста$обозначает конец текста.соответствует любому символу, кроме символа новой строки?обозначает одно или ноль вхождений|означает ИЛИ (совпадение с любым из символов, разделенных им)*любое количество вхождений (включая 0 вхождений)+одно и более вхождений{}указывает на несколько совпадений предыдущего RE.()отделяет группу в регулярном выражении
Обратная косая черта (backslash) \ используется в сочетании с другими символами и тогда приобретает особые значения. Если же необходимо использовать backslash просто как символ, без учета специального значения, его нужно «экранировать» еще одной обратной косой чертой – \\. Что касается специальных значений:
\dсоответствует любой десятичной цифре, это то же самое, что и [0-9]\Dсоответствует любому нечисловому символу\sсоответствует любому пробельному символу\Sсоответствует любому не пробельному символу\wсоответствует любому буквенно-числовому символу; это то же самое, что и [a-zA-Z0-9_].\Wсоответствует любому не буквенно-числовому символу.
Мы разобрали основы регулярных выражений (подробнее про них вы можете почитать тут). Теперь давайте посмотрим, какие методы доступны в модуле re.
re.search()
Этот метод возвращает совпадающую часть строки и останавливается сразу же, как находит первое совпадение. Таким образом, его можно использовать для проверки выражения, а не для извлечения данных.
Синтаксис: re.search(шаблон, строка)
Возвращаемое значение может быть либо подстрокой, соответствующей шаблону, либо None, если такой подстроки не окажется.
Давайте разберем пример: поищем в строке месяц и число.
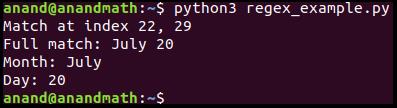
match = re.search(regexp, "My son birthday is on July 20")
print("Match at index %s, %s" % (match.start(), match.end())) #This provides index of matched string
print("Full match: %s" % (match.group(0)))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
print("The given regex pattern does not match")
re.match()
Этот метод ищет и возвращает первое совпадение. Но надо учесть, что он проверяет соответствие только в начале строки.
Синтаксис: re.match(шаблон, строка)
Возвращаемое значение, как и в search(), может быть либо подстрокой, соответствующей шаблону, либо None, если желаемый результат не найден.
Теперь давайте посмотрим на пример. Проверим, совпадает ли строка с шаблоном.
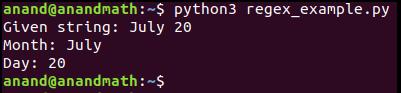
match = re.match(regexp, "July 20")
print("Given string: %s" % (match.group()))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))
Рассмотрим другой пример. Здесь «July 20» находится не в начале строки, поэтому результатом кода будет «Not a valid date».
match = re.match(regexp, "My son birthday is on July 20")
print("Given string: %s" % (match.group()))
print("Month: %s" % (match.group(1)))
print("Day: %s" % (match.group(2)))

re.findall()
Этот метод возвращает все совпадения с шаблоном, которые встречаются в строке. При этом строка проверяется от начала до конца. Совпадения возвращаются в том порядке, в котором они идут в исходной строке.
Синтаксис: re.findall(шаблон, строка)
Возвращаемое значение может быть либо списком строк, совпавших с шаблоном, либо пустым списком, если совпадений не нашлось.
Рассмотрим пример. Используем регулярное выражение для поиска чисел в исходной строке.
string = "Bangalore pincode is 560066 and gulbarga pincode is 585101"
match = re.findall(regexp, string)

Или другой пример. Теперь нам нужно найти в заданном тексте номер мобильного телефона. То есть, в данном случае, нам нужно десятизначное число.
string = "Bangalore office number 1234567891, My number is 8884278690, emergency contact 3456789123 invalid number 898883456"
regexp = '\d{10}' # Регулярное выражение, соответствующее числу из ровно 10 цифр
match = re.findall(regexp, string)

re.compile()
С помощью этого метода регулярные выражения компилируются в объекты шаблона и могут использоваться в других методах. Рассмотрим это на примере поиска совпадений с шаблоном.
print(e.findall("I born at 11 A.M. on 20th July 1989"))
e = re.compile('\d') # \d - эквивалент [0-9].
print(e.findall("I born at 11 A.M. on 20th July 1989"))
p = re.compile('\d+') # группа из одной или более цифр
print(p.findall("I born at 11 A.M. on 20th July 1989"))
# ['1', '1', '2', '0', '1', '9', '8', '9']
re.split()
Данный метод разделяет строку по заданному шаблону. Если шаблон найден, оставшиеся символы из строки возвращаются в виде результирующего списка. Более того, мы можем указать максимальное количество разделений для нашей строки.
Синтаксис: re.split(шаблон, строка, maxsplit = 0)
Возвращаемое значение может быть либо списком строк, на которые была разделена исходная строка, либо пустым списком, если совпадений с шаблоном не нашлось.
Рассмотрим, как работает данный метод, на примере.
# '\W+' совпадает с символами или группой символов, не являющихся буквами или цифрами
# разделение по запятой ',' или пробелу ' '
print(re.split('\W+', 'Good, better , Best'))
print(re.split('\W+', "Book's books Books"))
# Здесь ':', ' ' ,',' - не буквенно-цифровые символы, по которым происходит разделение
print(re.split('\W+', 'Born On 20th July 1989, at 11:00 AM'))
# '\d+' означает цифры или группы цифр
# Разделение происходит по '20', '1989', '11', '00'
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM'))
# Указано максимальное количество разделений - 1
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM', maxsplit=1))
# ['Book', 's', 'books', 'Books']
# ['Born', 'On', '20th', 'July', '1989', 'at', '11', '00', 'AM']
# ['Born On ', 'th July ', ', at ', ':', ' AM']
# ['Born On ', 'th July 1989, at 11:00 AM']
re.sub()
Здесь значение «sub» — это сокращение от substring, т.е. подстрока. В данном методе исходный шаблон сопоставляется с заданной строкой и, если подстрока найдена, она заменяется параметром repl.
Кроме того, у метода есть дополнительные аргументы. Это count, счетчик, в нем указывается, сколько раз заменяется регулярное выражение. А также flag, в котором мы можем указать флаг регулярного выражения (например, re.IGNORECASE)
Синтаксис: re.sub(шаблон, repl, строка, count = 0, flags = 0)
В результате работы кода возвращается либо измененная строка, либо исходная.
Посмотрим на работу метода на следующем примере.
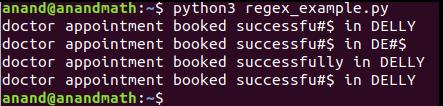
# Шаблон 'lly' встречается в строке в "successfully" и "DELLY"
print(re.sub('lly', '##39;, 'doctor appointment booked successfully in DELLY'))
# Благодаря использованию флага регистр игнорируется, и 'lly' находит два совпадения
# Когда совпадения найдены, 'lly' заменяется на '~*' в "successfully" и "DELLY".
print(re.sub('lly', '##39;, 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE))
# Чувствительность к регистру: 'lLY' не находит совпадений, и ничего в строке не будет заменено
print(re.sub('lLY', '##39;, 'doctor appointment booked successfully in DELLY'))
# С count = 1 заменяется только одно совпадение с шаблоном
print(re.sub('lly', '##39;, 'doctor appointment booked successfully in DELLY', count=1, flags=re.IGNORECASE))
re.subn()
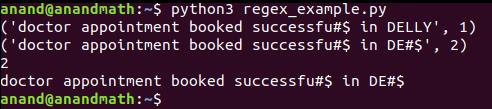
Функциональность subn() во всех отношениях такая же, как и sub(). Единственная разница – это формат вывода. subn() возвращает кортеж, содержащий общее количество замен и новую строку.
Синтаксис: re.subn(шаблон, repl, строка, count = 0, flags = 0)
print(re.subn('lly', '##39;, 'doctor appointment booked successfully in DELLY'))
t = re.subn('lly', '##39;, 'doctor appointment booked successfully in DELLY', flags=re.IGNORECASE)
# Это даст такой же вывод, как и sub()
re.escape()
Этот метод возвращает строку с обратной косой чертой \ перед каждым не буквенно-числовым символом. Это полезно, если мы хотим сопоставить произвольную буквенную строку, которая может содержать метасимволы регулярного выражения.
Чтобы лучше понять принцип работы метода, рассмотрим следующий пример.
# Здесь из не буквенно-цифровых символов есть только пробелы.
print(re.escape("doctor appointment booked successfully at 1PM"))
# Здесь есть , ' ', '^', '-', '[]', '\' - все эти символы не относятся к буквенно-цифровым
print(re.escape("He asked what is this [0-9], I said \t ^Numberic class"))

Заключение
Сегодня мы поговорили о регулярных выражениях в Python и о том, что необходимо для их понимания в любом приложении. Мы изучили различные методы и метасимволы, присутствующие в регулярных выражениях Python, на примерах.