ЧТО ВЛИЯЕТ НА ОХВАТЫ? ОТ Технички ДО Лички

Я давно хотел написать эту статью, но честно было в лом...
Цель этой статьи - дать тебе более широкую картину касаемо охватов и внести более существенную ясность в то, что влияет на охваты в запретграм. В свое время я влезал в различные инстаДебри, в которые мало кому захочется залезть... Потому что нудно, трудно, да и вообще не интересно)
Садись поудобней онлайн земляк и вкушай нотки бытийных знаний...
Ктоб че не звездел, охваты - это супер важно. К кричалкам из разряда важны не охваты, а качество и те кто тебя смотрят - я отношусь как к фразам для красного словца.
Если при охватах 1к в своих сторис ты делаешь продаж на 1 лям, при охватах в 2к ты заработаешь очевидно больше(слово качественные охваты и осознанная ца влепляю по умолчанию, потому что это не отделимо от охватов) - с этим ты никак не поспоришь и контр аргументировать не сможешь.
Когда я говорю об охватах, я их делю на 4 составляющие:
И сейчас мы обсудим каждый в отдельности...
И тут все начинается с технического анализа, что это такое?
Когда у тебя что-то болит и ты не знаешь что, какие адекватные действия ты можешь сделать, чтобы боль прошла?
Что сделает адекватный терапевт, чтобы определить причину боли?
Загуглит все симптомы или заебенить их в чат джипити? Вероятно в будущем. Но не сейчас...
Тебе влепят направление на анализы и уже после того, когда у врача будут итоговые данные, он сможет поставить диагноз и прописать лечение...
Технический анализ — это сегментирование ваших подписчиков по различным критериям для выявления необходимых составляющих. Это анализы твоего аккаунта.
Одна из составляющих которая влияет на охваты в сторис и ленте - это некачественная аудитория
Кого можно отнести к некачественной аудитории с технической стороны?
Я выделяю несколько сегментов некачественной аудитории
- Гиверы — люди, которые принимают участие в различных гивах. Как правило, эти люди хотят принимать участие в этих гивах из-за того, что там разыгрывают что-либо(iPhone, бабки, тачка, квартира…) Во всех гивах по-разному.
- Боты — это искусственно созданные аккаунты для чего-либо (накрутка, спам).
- Аккаунты живых пользователей с большим количеством подписок. И тут разделим их на два сегмента:
- Есть люди просто с большим количеством подписок. Физики, которые реально подписываются на 1000 людей и следят почти за каждым, на кого они подписаны.
- Массфолловеры - это те, кто делают массовые подписки с целью того, чтобы человек на которого они подписываются заметил их.
Во втором случае подписки совершаются в рекламных целях. В первом считай что по зову сердца=)))
4. Марафонщики — это люди, которые становятся заядлыми посетителями различных марафонов (или ещё их можно назвать — вечные ученики). И если, например, сравнивать марафонщиков и гиверов, то марафонщики (люди, которые принимают участие в различных обучающих марафонах) — это, всё таки, более осознанные люди. Так как, они, в первую очередь, идут на оффер, который их зовёт получить новые знания, где придется ходить на прямые эфиры, возможно выполнять домашку.
Да, в марафонах надо совершить на порядок меньше подписок на кого-либо, но тем не менее, и среди марафонщиков появляются те, кто накапливает большое количество подписок, которые потом просто лень зачищать.
Что произошло после блока инсты? Скосило кучу людей, которые висят мертвым грузом в аккаунте и никак не проявляют активность. И это живые люди у которых было 200-300-700-1200 подписок... не суть
Главное, что даже сейчас после блокирования очередного впн, какой-то % людей продолжает отпадать и будет продолжать, а твой аккаунт будет терять в охватах, если ты не будешь привлекать новую аудиторию.
Также, часть пользователей на впн сократили время провождения в инсте. Кто-то заходит пару раз в неделю, кто-то раз в месяц и это тоже отражается на охватах.
Что относится к некачественной аудитории с технической стороны я тебе обрисовал
Теперь идем к следующим техническим моментам и распаковываем чутка глубже
Например, есть аккаунт и часть его тех данных такие:
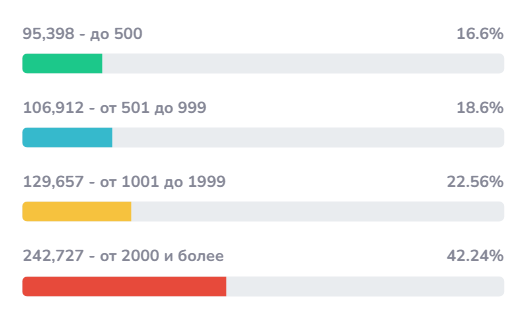
Видишь желтую и красную графу?
В аккаунте почти 65% аудитории у которой свыше 1к подписок.
То что у 65% подписчиков данного аккаунта сейчас полнейшая жопа в их лентах постов и сторис + инста допом подкидывает от себя различные рекомендации в виде контентных единиц...
Ежесуточная контентная конкуренция разная. Сегодня в ленте твоего подписчика Паши у которого 1200 подписок в ленте вышло 100 новых постов, завтра 70, послезавтра 150.
Чем меньше подписок у твоего подписчика и чем ниже ежесуточная контентная конкуренция, тем легче тебе пробиться в онлайн экран твоего подписчика - ЭТО КОНСТАНТА
В сторис тоже самое, сегодня сторьки выложили 70 человек из 1200 на которых подписан твой подписчик Паша. Завтра 120, а после завтра 170
И ТУТ РАБОТАЕТ ТАЖЕ САМАЯ КОНСТАНТА, ЧТО И ВЫШЕ
Помнишь как в феврале прошлого года резко взлетели охваты у тех аккаунтов, которые что-либо постили в сторис? Все потому что большинство людей молчали и вообще не знали, что можно говорить, а что нельзя... Я привожу этот пример т.к довольно показательный и понятен всем.
И у каждого из твоих подписчиков контентная конкуренция ИНДИВИДУАЛЬНА, потому что у каждого свой пул экспертов, пабликов или блогеров, которые нравятся.
ЗАЛЕТНЫЕ ОХВАТЫ, ИХ Я ТОЖЕ ОТНОШУ К ТЕХНИЧКЕ
- Например, ты запостил рилс и он залетел в топы. Люди смотрят рилс, залетают в сторис , но не подписываются на твой аккаунт. Да, ты сделал касание с человеком, ты красава. Но залетные охваты чутка искажают объективную картину охватов от ТВОИХ подписчиков
- Купил реклу, человек зашел и глянул твои сторьки - то же самое
- А теперь представь что аккаунт данные которого выше на скрине, запостит пост. Что будет? Ведь в его ленте шлак... Его пост может собрать как 10.000, так и 20.000 охватов, но при этом соберет 50 - 300 лайков, а ведь в этом аккаунте больше 500.000 подписчиков!!!
Все это из-за того, что те же гиверы тупо скролят свою засранную ленту, пока их глаз серьезно не зацепится за какую-либо контентную единицу, а охваты при скролинге будут засчитываться каждому проскроленному посту. Плюс не забывай, что с гивов в большей степени идет не релевантная ЦА
Если человек подписался на тебя - первое время твои сторьки будут выскакивать у него первыми. Чем чаще твой подписчик взаимодействует с твоим аккаунтом, тем чаще ты будешь у него в топах.
Если человек лайкнул, репостнул, сохранил, откоментил твой пост - твои новые посты будут появляться у него в интересном

И еще парочка скринов из интересного


Когда я усиленно качал хеши и вел свой курс "el maximo" мне нравилось делать посев теневого актива(не знал больше 4 лет назад как назвать и назвал именно так). Когда человек благодаря хешам видит твой пост и делает целевое действие(лайк, коммент, сохранение, репост), но не подписывается на тебя, инста будет показывать ему в его интересном твои новые посты - это и есть "посев теневого актива".
ЭТО ВАЖНО ПОНИМАТЬ ПРО ОХВАТЫ В СТОРЬКАХ, НО НЕ ОБЯЗАТЕЛЬНО ЧИТАТЬ
Если ты имеешь 50к подписчиков и в течении недели тебя в среднем смотрит 10-15к человек... Это не значит что тебя ежесуточно смотрят одни и теже люди
Можно ли выявить тех кто смотрит тебя каждый день в течении недели, вот прям пологинно? Да)
Просто ежесуточно постишь свои сторис и парсишь всех кто тебя смотрит, а потом проводишь пересечение баз через программки. Тебе может кто-то скажет, что со сторис можно собрать максимум 1к просмотревших, а я скажу нет. Хоть и есть такое ограничение, его можно обойти)
Так вот, если тебя в течении недели смотрит в среднем 10-15к человек, будет очень хорошо, если костяк людей которые смотрят тебя каждый день в течении этой недели, будет составлять хотя бы 60-70%. ЭТО НОРМ.
Разумеется если мы возьмем промежуток в месяц - этот костяк сильно уменьшится.
Все это проверить и отследить оч легко для того, кто норм шарит в парсинге и умеет работать с пересечением баз. Но думаю это не та штука, которая вам сильно нужна, однако она прикольна тем что дает более объективную картину на тех же запусках.
Часто про запуски говорят - "Я сделал запуск при охватах 1000 на 2 миллиона рублей", но это говорят про средние цифры. По итогу там может быть всего 500-600 человек, которые смотрели прогрев ОТ/ДО и коснулись абсолютно всех единиц контента в сторис. К чему я? Некоторые даже не понимают, что они гораздо круче чем сами думают.
Играться с парсингом и пересечениями можно по-разному, но вернемся к техничке...
Если % некачественной аудитории выше 30% в аккаунте, то техничка аккаунта уже начинает влияет на охваты. Это верно в большинстве случаев, всегда есть исключения и тут одно из главных это очень крупные аккаунты
Поэтому когда меня клиенты спрашивали за средние цифры чистки и тех анализа - я говорил, что каждый случай индивидуальный
Если в аккаунте 70% некачественной аудитории, бесполезно стараться вытаскивать охваты в жопасторис контентом, даже если ты гуру сторитела, ты не сможешь сделать охваты в сторис равные 15-20-25-30% от количества подписчиков. Скорее грыжу заработаешь
Почему многие рилсники заебываются с охватами в сторис и даже при 100к подписчиках их охваты зачастую равны 3-4к просмотрам в сторис? Потому что рилсы не отсекают некач ца, там нет кнопки "показывать ролик только тем у кого до 1к подписок в профиле, патамучтааа мне нафиг не нужны те у кого мноГа паТписааак".
И для многих рилсников низкие охваты стали нормой. Ведь не понятно, а почему в их сторис происходит жопаболь с охватами... А если не понятно, значит так и должно быть(НЕТ).
Некачественная аудитория с тех стороны может приходить с любого вида трафика, но блогеры это единственный инструмент где ты заранее можешь ловчее прогнозировать и контролировать приход некачественной ца. И сделать это очень просто, чекай процент некачественной ца у блогера перед покупкой рекламы, через тот же елоко и слушай своих менеджеров(если они норм).
ТЕПЕРЬ ДАВАЙ ЗАКРОЕМ ВОПРОСЫ ПО ЧИСТКЕ
Я тебе просто напишу чек-лист основных моментов
Чтобы сейчас сделать качественную чистку и вытянуть охваты из жопы, тебе надо сделать:
- Сбор своих подписчиков
- Сбор всей активной аудитории за последние 6 месяцев(Тех кто лайкает, комментирует, смотрит сторис и пишет в директ). Тех кто смотрит сторис собирай сейчас минимум в течении 1 месяца. Как собрать сторьки? Веб версия инсты+код страницы.. смекаешь? Можно даже тупо делать скрины тех кто смотрит сторис, а потом перевести скрины в текст с помощью различных программ(Сорян, более прикольные способы оставлю пока что себе)
- Далее из базы подписчиков вычитаешь базу всех активных юзеров и у тебя останется база тех кто вообще не проявлял какую-либо активность на твоей странице
- Базу НЕ актива сегментируешь по количетсву подписок(6-7к/5-4к/4-3к/3-2к/2-1к)
- Начинаешь зачищать весь этот не актив начиная сверху вниз, постепенно повышая норму действий твоего аккаунта
- После чистки, чтобы быстрей восстановить охваты привлекаешь 10% новой аудитории с помощью блогеров
Не над ток мне задать вопросы - А это безопасно? А аккаунт не заблокируют? А мне чистка поможет?
Если руки не из МУЗГУЛЮС ГЛЮТЕУС и делать все правильно, чистка помогает всем и это абсолютно безопасная штука, просто раскачивайте норму действий аккаунта постепенно.
Сейчас пару слов скажу за инстаотписку, спамгард и инстахиро. Из-за этих сервисов ты только угробишь свою потенциальную прибыль.
- Эти сервисы не будут собирать тех, кто смотрит твои сторис в течении месяца и они делают кривой парсинг
- Эти сервисы парсят через моб версию инсты, а парсить надо только через веб версию тк там нет ограничений, которые есть в мобильном парсинге.
- Через эти сервисы ты не вычислишь качественно оформленных ботов, которые имеют по 200-300-500-700 подписок
- Через эти сервисы ты не вычислишь живых людей, которые отвалились с блоком инсты и теперь висят мертвым грузом
В прошлом 50% моих клиентов - это те люди, которые использовали данные сервисы и которые поняли, что угробили свои аккаунты. За много лет эти сервисы никак не доработали, потому что нет смысла... Сделать качественную чистку без вкроплений ручного труда невозможно.
Тут сразу добавлю - ко мне идти не надо, я этой темой уже не занимаюсь. Мне это просто не интересно, я от этого скила уже давно взял то, что хотел.
ОБОЛОЧКА

Вот сколько этого на рынке? 50%?60%?70%?
Этого дохуя... Этого было дофига 2 года назад, 3 года назад, 4 года назад...
Не... ты не пойми меня не правильно, ситуация в контенте меняется в лучшую сторону, но микроскопическими подлупнными шагами...

Наш инста и тг рынок не напоминает, а? Причем можешь самостоятельно перевести в любой контентный формат и везде отследишь повторяющиеся шаблоны от которых люди не оч хотят отходить...
В постах нужна сочная картинка и учиться создавать ее надо уже сейчас, а не когда нейросетка заменит 90% контента существующего в соц сетях
В заголовках тоже, как 3 года назад, так и сейчас одна и та же проблема
"Топ 5 книг которые изменили мою жизнь"
Твоя ЦА когда читает подобные заголовки, она уже затылочной частью головы заранее предполагает, что там будет написано и звучит это примерно так: -
"О! Блеять! Опять топ 7 ошибок при анализе блогеров"
"О божечки благословенный!!! Да хранит господь твою душу за эти топ 7 ошибок при анализе блогеров, которые изменят мою жизнь и привнесут в нее святой Грааль по привлечению десятков тысяч подписчиков"
Мне парой кажется, что люди которые выкладывают такие посты, думают именно так.
"Топ 7 ошибок при анлизе блогеров" - это то что транслирует абсолютное большинство. Там где большинство - надо уметь выделяться. Там где тема поста безальтернативна(например пишет про эту тему меньшинство, там можно сильно не придумывать с заголовком, а где ЕБЕЙШАЯ КОНКУРЕНЦИЯ - там надо изголяться, чтобы придумать интересный заголовок и пост ).
- Если вы юзаете заголовки на своих публикациях, читкани хотя бы обложки менс хелс, космополитан или еще кого. Выбери с обложек топовые заголовки и подкрути под свою публикацию
- В крайнем случае лови 600 заголовков шардакова, если ты не безнадежен то это поможет разбудить фантазию https://shardakov.com/wp-content/uploads/2021/09/Zagolovki-600-formul-Shardakov.pdf
Тексты - это основа всего. Инстапосты, лонгриды, видео, сценарии... абсолютно все начинается с текстов.
По текстам скажу одну фичу, которая мешает большинству - пиши так, как общаешься в жизни. Не надо этого присущего многим официоза, которому обучают в школе и универе.
ТОВ, брендвил - это отличные составляющие текста и контента, которые формируют и дополняют твою уникальность и помогают сделать тебя БЕЗАЛЬТЕРНАТИВНЫМ. Когда ты сформировал эти составляющие, твои охваты выше, признание больше, лояльность ближе, а за этим следует уважение и любовь к тебе как к эксперту.
Ну конечно же твои охваты выше, когда в твоей жизни лухари и образы которые встречаются в жизни большинства изредка или редко. Кто скажет обратное - я посоветую пойти и поселиться в бомжатник, транслировать это раскачивая свой аккаунт с нуля и потом продать свои обучалки)))
Лухари не надо стесняться, бояться, надо просто стараться жить свою лучшую жизнь. И она может быть разная... иногда хочется затворничества, иногда бегать по горам, а иногда и слетать на Мальдивы бизнес классом.
Люди всегда будут следить охотнее за тем к чему стремятся. Будут искать схожесть с автором, чтобы почувствовать похожие качества или события из жизни, ведь если это есть, значит и у них есть шанс это достичь. Это круто, это мотивирует.
Представим что у тебя профильная расцветка твоего личного бренда зеленая и весь твой аккаунт отражает это...
Актуальные, фотки в ленте которые содержат зеленую кофточку, сникерсы, футболка, задний фон... Понял, да?
Со временем у твоих подписчиков начнет формироваться ассоциация ТЫ = ЗЕЛЕНЫЙ ЦВЕТ, но также последует и привыкание...
Предположим в течении 1,5 лет люди видят все зеленое в твоем профиле, а потом хуяк и фотка тебя в голубом костюме единорога

И твои охваты бац и подпрыгнули, потому что ты сломал у подписчиков уже сформированный шаблон касаемо себя...
Тоже самое и в стиле жизни. Показываешь лухари лайф, перелеты частными рейсами, а потом хуяк и сидишь у старого друга в потрепанной однушке и ешь доширак и у людей рвется шаблон и включается режим -свой-, который увеличивает лояльность, вовлечённость и тд
Вытаскивать из себя свои НЕ ШАБЛОНЫ, которые не соотвествуют большинству и траслируя их в жизнь - ты увеличиваешь вовлеченность и свои охваты. Не забывай в первую очередь формировать свою личность, прокачивать себя.
Распаковки эт канеш все хорошо, но они про прошлое и настоящее. А надо смотреть в первую очередь в будущее. Многие сильно зацикливаются на распаковке личности или экспертности, хотя лучше бы свой ТОВ лайф формировали и брендвил усиливали.
Текст, видео, войс, подкаст...
Верны ли утверждения авторов, которые говорят, что настал тренд коротких видео и все люди сейчас готовы потреблять ТОЛЬКО короткие видео?!
Люди смотрят короткие видео только у тех, кто говорит что за ними тренд. Люди смотрят короткие видео только у тех, кто не делает другие форматы контента, кроме коротких видео.
У авторов, которые создают БЕЗАЛЬТЕРНАТИВНЫЙ контент, люди готовы потреблять любой формат контента, потому что НЕТ АЛЬТЕРНАТИВЫ.
Ты кем хочешь быть? Безальтернативным автором или автором одного формата?
ЛИЧНОСТЬ и ТОВ АВТОРА ПЕРВИЧНЫ
Качай ТОВ, улучшай брендвил, качай хард и софт скилы - это важнее чем формат. Потому что прокачав эти составляющие твой контент будет шериться твоими подписчиками вне зависимости от формата
ЛИЧНОСТНЫЕ
Личностные моменты, которые ты имеешь сейчас, являются твоей оболочкой которую ты будешь транслировать в массы. Это скелет твоей бытийности и аутентичности. Это то что выделяет тебя на фоне других блогов и создает БЕЗАЛЬТЕРНАТИВНОСТЬ тебя и твоего контента.
Давай на примере. Вот какой я человек?
Когда у меня нет настроения, я могу быть слегка хамоватым. Когда у меня много дел и я захожу в продуктовый магазин, мне не нравятся люди, которые идут в проходах магазина очень медленно. А когда у меня мало дел и я никуда не спешу, меня изредка злят люди, которые в магазине суетятся и куда-то спешат.

Я люблю доширак и мне не впадел изредка выпить Рязанского жигулевского у падика

Я могу заплатить 50к в сутки за отель, потому что люблю комфортный отдых

Я обожаю горы, но очкую большой высоты😂

Я люблю баню, особенно те которые на берегу озера

Я не люблю читать, прям от слова СОВСЕМ, но читаю кипу литературы т.к. это прокачивает мои скилы и меня как личность

Я купил беху т.к. пересмотрел в детстве парочку фильмов, после которых стал мечтать о том, чтобы моей первой тачкой была Х5

Я слушаю музон от классики до рока и шансона

Я люблю готовить для своей семьи

Я не вижу целью своей жизни - заниматься благотворительностью. Но я частенько закидываю деньги на разные благотворительные моменты, потому что я чувствую себя после этого хорошо

Меня зажигает засолить рыбу или закоптить ее, больше чем полет на частном джете.


Люблю иногда покупать крепкий алко и не пить его. Мне просто нравится, что у меня есть свой бар

Я люблю деньги, потому что они делают жизнь моей семьи и меня лучше. Они воплощают в жизнь мои мечты, цели. Я люблю эту кружку на фотке, потому что когда-то давно мне ее подарила бабушка

Я бываю злым, добрым, сильным, уверенным, слабым, ресурсным, устойчивым, гибким. Я отношусь к людям так, как они относятся ко мне. Ценю тех, кто ценит меня и забиваю болт на тех, кто не таков. Я бываю разным. Я человек.
Все это в отдельности - это просто факты обо мне.
В совокупности и на стыке этих фактов, моих скилов, личностных качеств, тов и всего остального - рождается аутентичность, которая складывается в определенные образы у моей аудитории, которые выделяют меня на фоне моих коллег.
- Отдыхает в отелях за 50к в сутки и ест доширак - чувак не зазнался и не в группе этих занощевых богачей
- Любит горы, готовить, баню - обычный парень, такой же как и я
- Читает книжки и закидывает изредка на благотворительность - явно не тупое дерьмо. Да и буквы в статье складывать умеет.
- А еще он просто человек со своими минусами, плюсами
Теперь смотри, если просто сказать про доширак. Много людей скажет - ну и че тут такого, я тож лопаю доширак, когда готовить в падел или когда с похмелуги лежу
Но другое дело когда создается контраст. Когда отель за 50к в сутки+доширак. Он влияет на довольно большой пласт аудитории совершенно по-другому.
Многих людей задрало лухари и для тех кого оно задрало, обычный нюанс связанный с тем что мне не впадлу есть доширак говорит о том - что этот чувак свой, он не зазнался и ему можно доверять.
Важно из себя вытаскивать бытийные моменты, потому что это помогает найти людям тебя среди масс и дать понять им, что ты такой же как они(ты свой).
Ведение блога в начале - это ебейшия работа, нагрузка на физику и нервную систему и со временем нагрузка переезжает в фоновое состояние, которое ты уже не чувствуешь, потому что просто привык.
Ведение своего блога, транслирование своих мыслей, ценностей, удач и неудач - это одно из лучших занятий в мире. Надо просто стараться жить свою лучшую жизнь, постоянно учиться, делать себя лучше и просто это показывать... Звучит вроде легко, да?
А на деле пиздец как сложно...
Выбирая этот путь и следуя ему - твоя жизнь точно изменится на 180 градусов в лучшую сторону. Но не забывай, что помимо всех благ которые несет блогинг - ты принимаешь и все сложности с испытаниями, которые сопровождают его.
Вступить в стезю блогинга однажды, стало одним из лучших решений в жизни. Блогинг меня сильно изменил и я сильно рад этим изменениям.
И мне очень странно наблюдать, как куча людей отказываются от всех благ блогинга, забивая болт на его ведение.
АЛГОРИТМЫ
Я всегда отделяю алгоритмы инсты от всего остального
Если у тебя в норме техничка, оболочка, личностные моменты - ты вообще не тот человек которому стоит париться за алгоритмы. Если техничка твоего аккаунта в жопе, оболочка и личностные моменты тоже, то какие тебе алгоритмы?!
Они на тебя работать не будут...
Глобально алгоритмы меняются крайне редко. Что значит для меня глобально? Это когда хроно лента сменилась на умную
Я не оч люблю когда говорят - "алгоритмы в инсте поменялись!" по мне так правильнее сказать, что алгоритмы усовершенствовались/доработались.
Важно понимать что контент в инстаграм подстраивается индивидуально под каждого пользователя на основе различных технических данных об этом пользователе. Технических, потому что инста не видит глазами как мы и не распознает как человек. Она распознает кодом, через различные действия пользователя.
И вот вам перевод статьи с англ от одного прогера, который когда-то кодил запретграм.⠀
Система “Рекомендованное” в поиске Инстаграм
Разработка основных блоков построения поиска.
Прежде чем мы смогли приступить к созданию механизма рекомендаций, который справляется с огромным объемом фотографий и видео, ежедневно загружаемых в Instagram, мы разработали базовые инструменты для решения трех важных задач. Необходимо было проводить быстрые масштабные эксперименты, чтобы получить более четкий сигнал о широте интересов людей, и нам нужен был эффективный, с точки зрения вычислений, способ обеспечить высокое качество и актуальность наших рекомендаций. Эти нестандартные методы были ключом к достижению наших целей:
Быстрая итерация с IGQL: новый предметно-ориентированный язык
Создание оптимальных алгоритмов и методов рекомендаций - это постоянная область исследований в сообществе машинного обучения, и процесс выбора правильной системы может широко варьироваться в зависимости от задачи. Например, один алгоритм может эффективно определять долгосрочные интересы, другой может работать лучше при определении рекомендаций на основе недавнего контента. Наша команда инженеров работает над различными алгоритмами, и нам нужен был способ как эффективно опробовать новые идеи, как и легко применять многообещающие идеи к крупномасштабным системам, не беспокоясь о последствиях для вычислительных ресурсов, таких как процессор и память. Нам нужен был метаязык, специфичный для индивидуальной предметной области, который обеспечивал бы нужный уровень абстракции и собирал все алгоритмы в одном месте.
Чтобы решить эту проблему, мы создали и запустили IGQL, предметно-ориентированный язык, оптимизированный для поиска кандидатов в системе рекомендованных. Его исполнение оптимизировано под C ++, что помогает минимизировать задержки и вычислительные ресурсы. Он также расширяемый и простой в использовании при тестировании новых исследовательских идей. IGQL имеет статическую проверку и является высокоуровневым. Инженеры могут писать алгоритмы рекомендаций в стиле Python и быстро и эффективно выполнять их на C ++.
. let (seedid = идентификатор пользователя)
понравилось (max_nnum_retretrieve = 30)
. accountmbedding_conficonfig = по умолчанию)
. postedmaxmediapmediaunt = 1account = 10)
. filter (nonblemodelthresmodel2)
. rank (rank_model = defaultmodel = по умолчанию)
. diversifythod = round_robin)
В приведенном выше примере кода вы можете увидеть, как IGQL легко читаемый даже для инженеров, которые мало работали с языком. Он помогает собрать несколько этапов рекомендаций и алгоритмов принципиальным образом. Например, мы можем оптимизировать группу сгенерированных кандидатов, используя правило объединения в запросе, чтобы вывести взвешенное сочетание нескольких выходных подзапросов. Изменяя их вес, мы можем найти комбинацию, которая обеспечивает лучший пользовательский опыт.
IGQL упрощает выполнение задач, типичных для сложных систем рекомендаций, таких как построение вложенных деревьев по правилам комбайнера. IGQL позволяет инженерам сосредоточиться на машинном обучении и бизнес-логике, лежащей в основе рекомендаций, а не на логистике, например, на выборе нужного количества кандидатов для каждого запроса. Это также обеспечивает высокую степень повторного использования кода. Например, применить средство ранжирования так же просто, как добавить однострочное правило к нашему запросу IGQL. Небольшое дополнение в нескольких местах, таких как ранжирование аккаунтов и ранжирование контента, публикуемых этими аккаунтами.
Встраивание аккаунтов для персонализированного ранжирования списка.
Люди публикуют в Instagram миллиарды высококачественных медиафайлов, которые можно использовать в качестве ресурсов для исследования. Трудно поддерживать четкую и постоянно развивающуюся систему каталога для самых разных сообществ по интересам в «Рекомендованном» - с различными темами, от арабской каллиграфии до моделей поездов и слайма. В результате моделям, основанных на контенте, сложно охватить такое разнообразие сообществ, основанных на интересах.
Поскольку в Instagram есть большое количество учетных записей, ориентированных на интересы, основанных на определенных темах, таких как кошки Девон-рекс или старинные тракторы, мы создали конвейер поиска, который ориентирован на информацию на уровне учетной записи, а не на уровне контента. Создавая встроенные аккаунты, мы можем более эффективно определять, какие аккаунты тематически похожи друг на друга. Мы делаем вывод о внедрении учетных записей, используя ig2vec, структуру встраивания, подобную word2vec. Как правило, фреймворк встраивания word2vec изучает представление слова на основе его контекста в предложениях в теле обучения. Ig2vec обрабатывает идентификаторы учетных записей, с которыми взаимодействует пользователь - например, человек лайкает посты страницы - как последовательность слов в предложении.
Применяя те же методы, что и word2vec, мы можем предсказать учетные записи, с которыми человек, вероятно, будет взаимодействовать в данный момент пользования Instagram. Если человек взаимодействует с последовательностью учетных записей в одном сеансе, это с большей вероятностью будет тематически сравниваться со случайной последовательностью других учетных записей Instagram. Это помогает нам идентифицировать тематически похожие аккаунты.
Мы определяем показатель расстояния (метрику) между двумя учетными записями - те, которые использовали при обучении, -основанное на косинусных расстояниях или точечном продукте. Исходя из этого, мы выполняем поиск в KNN (алгоритм поиска ближайшего соседа), чтобы найти тематически похожие аккаунты с встроенным аккаунтом. Наша встроенная версия охватывает миллионы учетных записей, и мы используем современную систему поиска ближайших соседей Facebook FAISS в качестве вспомогательной инфраструктуры поиска.
Для каждой встроенной версии, мы обучаем классификатора предсказывать тему набора учетных записей исключительно на основе встраивания. Сравнивая прогнозируемые темы с темами, помеченными людьми для учетных записей в удерживаемом наборе, мы можем оценить, насколько хорошо алгоритм отражают тематическое сходство.
Получение учетных записей, похожих на те, к которым ранее проявлял интерес конкретный человек, помогает нам сузиться до меньшего персонального рейтингового списка для каждого человека простым, но эффективным способом. В результате мы можем использовать новейшие модели машинного обучения с интенсивными вычислениями для обслуживания каждого человека сообщества Instagram.
Предварительный отбор подходящих кандидатов с помощью модельной дистилляции.
После того, как мы используем ig2vec для определения наиболее релевантных учетных записей на основе индивидуальных интересов, нам понадобится способ ранжировать эти учетные записи таким образом, чтобы он был новым и интересным для всех. Для этого потребуется прогнозирование наиболее подходящих медиа для каждого человека каждый раз, когда он прокручивает страницу «Обзор».
Например, оценка даже всего 500 фрагментов мультимедиа через глубокую нейронную сеть для каждого раза прокрутки требует большого количества ресурсов. И все же, чем больше постов мы оцениваем для каждого пользователя, тем выше вероятность найти лучшие, наиболее персонализированные медиа из их списка.
Чтобы максимизировать количество носителей для каждого запроса на ранжирование, мы ввели модель дистилляции ранжирования, которая помогает нам предварительно отбирать кандидатов перед использованием более сложных моделей ранжирования. Наш подход состоит в том, чтобы обучить сверхлегкую модель, которая учится на наших основных моделях ранжирования и пытается максимально приблизиться к ним. Мы записываем входных кандидатов с функциями, а также выходы из наших более сложных моделей ранжирования. Затем модель дистилляции тренируется на этих данных с ограниченным набором функций и более простой структурой модели нейронной сети для воспроизведения результатов. Его целевая функция - оптимизировать потерю ранжирования NDCG (показатель качества ранжирования) по сравнению с результатами основной модели ранжирования.
В качестве кандидатов на ранжирование для более поздних этапов высокопроизводительных моделей ранжирования, мы используем посты с наивысшим рейтингом из модели дистилляции.
Настройка имитирующего поведения модели дистилляции сводит к минимуму необходимость настройки нескольких параметров и поддержки нескольких моделей на разных этапах ранжирования. Используя эту технику, мы можем эффективно оценивать больший набор медиафайлов, чтобы находить наиболее релевантные медиафайлы для каждого запроса ранжирования, сохраняя при этом контроль над вычислительными ресурсами.
Как мы создали Explore (Поиск)
После создания ключевых строительных блоков, необходимых для простого экспериментирования, эффективного определения интересов людей и создания эффективных и актуальных прогнозов, нам пришлось объединить эти системы вместе для работы. Используя IGQL, встраивание учетных записей и нашу технику дистилляции, мы разделили системы рекомендаций Explore на два основных этапа: этап генерации кандидатов (также известный как этап поиска) и этап ранжирования.
Во-первых, генерирование кандидатов, мы используем учетные записи, с которыми люди взаимодействовали раньше (например, лайкнули или сохранили медиафайлы из учетной записи) в Instagram, чтобы определить, какие другие учетные записи могут быть интересны людям. Мы называем их исходными учетными записями. Начальные аккаунты обычно составляют лишь часть аккаунтов в Instagram, имеющих схожие или одинаковые интересы. Затем мы используем методы встраивания учетных записей для определения учетных записей, похожих на исходные. Наконец, на основе этих учетных записей мы можем найти медиа, опубликованные в этих учетных записях или с которыми они взаимодействовали.
Есть много разных способов взаимодействия людей с аккаунтами и медиа в Instagram (например, подписка, лайк, коммент, сохранение и репост). Также существуют разные типы мультимедиа (например, фото, видео, сторис и прямые эфиры), что означает, что существует множество источников, которые мы можем создать, используя аналогичную схему. Используя IGQL, процесс становится очень простым - разные источники-кандидаты просто представлены как разные подзапросы IGQL.
С помощью различных типов источников мы можем найти десятки тысяч подходящих кандидатов для обычного человека. Мы хотим убедиться, что контент, который мы рекомендуем, безопасен и подходит для глобального сообщества людей всех возрастов в Explore. Используя различные сигналы, мы отфильтровываем контент, который мы можем идентифицировать как неподходящий, прежде чем мы создадим соответствующий список для каждого человека. В дополнение к блокировке контента и дезинформации, потенциально нарушающего политику, мы используем системы машинного обучения, которые помогают обнаруживать и фильтровать контент, такой как спам.
Затем для каждого запроса на ранжирование мы определяем тысячи подходящих медиа для обычного человека, отбираем 500 кандидатов из подходящего инвентаря и затем отправляем кандидатов ниже по цепочке на этап ранжирования.
Имея 500 кандидатов, доступных для ранжирования, мы используем трехступенчатую инфраструктуру ранжирования, чтобы помочь сбалансировать компромисс между релевантностью ранжирования и эффективностью вычислений. У нас есть три этапа ранжирования:
Первый проход: модель дистилляции имитирует комбинацию двух других стадий с минимальными функциями; выбирает 150 наиболее качественных и наиболее подходящих кандидатов из 500.
Второй этап: облегченная модель нейронной сети с полным набором плотных функций; выбирает 50 самых качественных и актуальных кандидатов.
Последний этап: модель глубокой нейронной сети с полным набором плотных и разреженных функций. Выбирает 25 наиболее качественных и наиболее подходящих кандидатов (для первой страницы сетки Explore(поиска)).
Эта анимация описывает инфраструктуру ранжирования, состоящую из трех частей, которую мы используем для достижения баланса между релевантностью ранжирования и эффективностью вычислений.
Если модель дистилляции первого прохода имитирует две другие стадии в порядке ранжирования, как мы определим наиболее релевантный контент на следующих двух стадиях? Мы прогнозируем индивидуальные действия, которые люди совершают в отношении каждой публикации, будь то положительные действия, такие как лайк и сохранение, или отрицательные действия, такие как «Смотри меньше подобных сообщений» (SFPLT). Для прогнозирования этих событий мы используем многозадачную нейронную сеть с несколькими метками (MTML). Общий многослойный перцептрон (MLP) позволяет нам фиксировать общие сигналы от различных действий.
Иллюстрация нашей текущей архитектуры модели последнего прохода.
Мы комбинируем прогнозы различных событий, используя арифметическую формулу, называемую ценностной моделью, чтобы зафиксировать значимость различных сигналов с точки зрения принятия решения о релевантности контента. Мы используем взвешенную сумму прогнозов, такую как [w_like * P (Like) + w_save * P (Сохранить) - w_negative_action * P (Negative Action)]. Если, например, мы думаем, что человеку важнее сохранить пост из Поиска, чем лайкнуть его, то и вес этого действия должен быть выше.
Мы также хотим, чтобы Explore стал местом, где люди смогут найти богатый баланс между новыми интересами и существующими. Мы добавляем простое эвристическое правило в модель ценности, чтобы увеличить разнообразие контента. Мы понижаем рейтинг постов от одного автора или одного исходного аккаунта, добавляя штрафной коэффициент, чтобы вы не видели несколько постов от одного и того же человека или одного исходного аккаунта в Поиске. Этот штраф увеличивается по мере того, как вы опускаетесь в ранжированном пакете и встречаетесь с большим количеством постов от того же автора.
Мы ранжируем наиболее релевантный контент на основе окончательной оценки модели ценности каждого ранжирующего кандидата в порядке убывания. Наш автономный инструмент воспроизведения - вместе с инструментами байесовской оптимизации - помогает нам эффективно и постоянно настраивать модель ценности по мере развития наших систем.
Постоянная проблема машинного обучения
Одна из самых захватывающих частей создания Explore - это постоянная задача поиска новых и интересных способов помочь нашему сообществу находить наиболее интересный и актуальный контент в Instagram. Мы постоянно развиваем Instagram Explore, добавляя медиа-форматы, такие как сторис и новые типы контента, такие как Магазин и видео IGTV.
Масштабирование сообщества Instagram и списков требует создания культуры быстрого экспериментирования и эффективности разработчиков, чтобы надежно рекомендовать лучшее из Instagram для индивидуальных интересов каждого человека. Наши специальные инструменты и системы дали нам прочную основу для непрерывного обучения и повторения, которые необходимы для создания и масштабирования Instagram Explore.
Дочитал? Красава!
Всех обнял! И даже вредин! Твой бро t.me/slava_smm
За отметки в сторис и пересылку друзьям буду сильно благодарен! Это для меня очень ценно)