Интересное время
На протяжении своего развития, человечество ставило себе всё более сложные и амбициозные цели — построить:
- самую высокую пирамиду
- корабль, который пересечёт океан
- машину, которая поднимет человека в воздух
- устройство, которое будет считать за человека в миллионы раз быстрее
- алгоритм, который будет принимать решения за человека быстрее, и нередко, и точнее
И каждая ступень справедливо воспринимается современниками чуть ли не как чудо. И время между такими рывками с каждым разом всё сильнее сокращается. Человечество сломя голову несется в, прости господи, технологическую сингулярность: когда рутинные задачи решаются всё быстрее и дешевле, общество перестраивается под новые реалии и так далее.
И вот, случается очередной виток прогресса. Лучшие умы человечества взмывают в воздух, успешно преодолевая новые препятствия. Они делятся своими новыми знаниями, показывая дорогу всем остальным — но в этот момент откуда-то из оврага доносится звуки возни, ругани, пьяных криков и смачных ударов.
Прервавшие благоговейную тишину смотрят на полет, чешут голову дубинами и в голове возникает всего одна мысль: "А с помощью этой хреновины получится ёбнуть моего соседа по-сильнее? Нет? Ну и хули вы тут дурью маетесь? Да куда только мир катится: в соседнем овраге нам вот-вот болото осушат, а эти со своими игрушками носятся. Никакого уважения к исторической справедливости. А ведь это болото исторически принадле..."
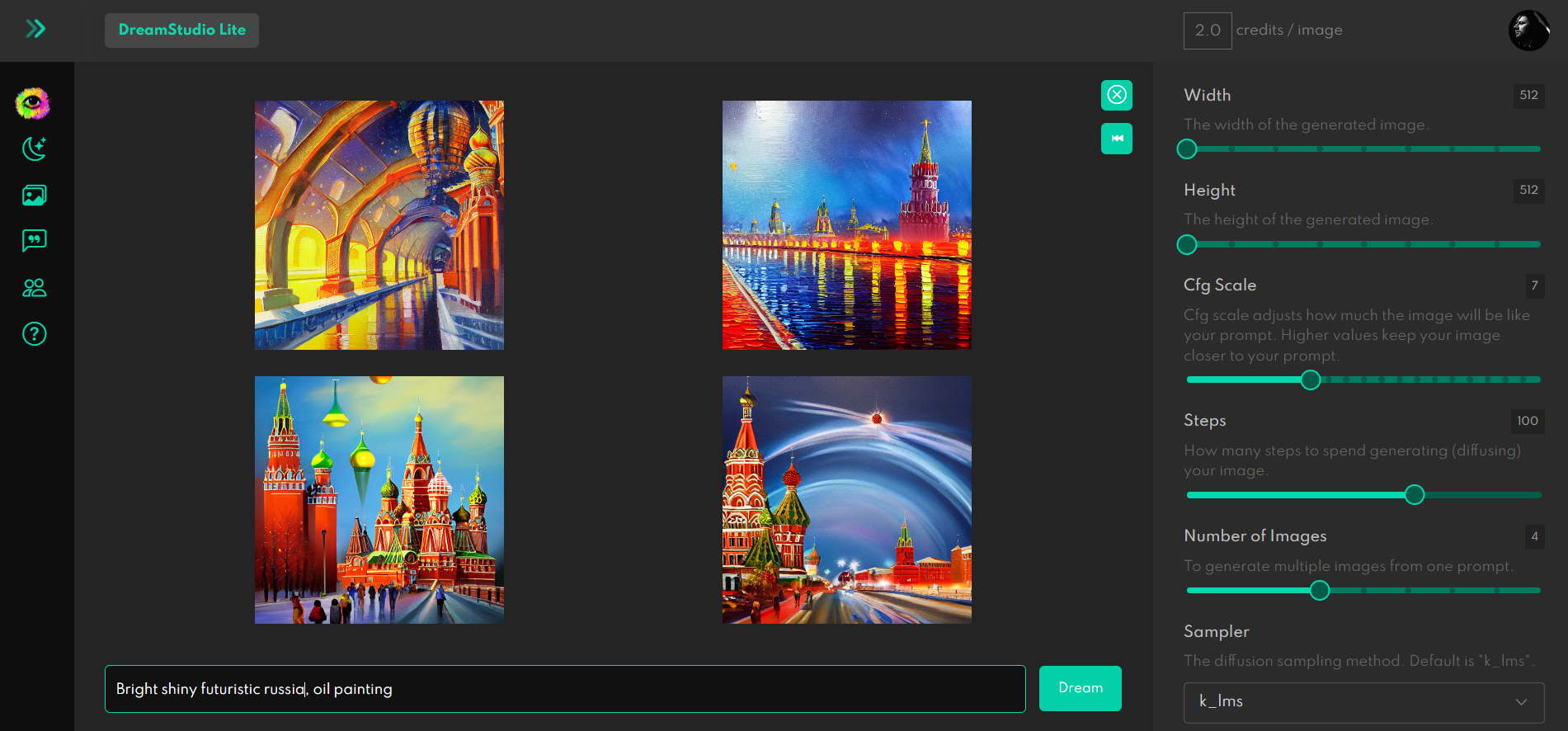
Человечество всю историю достигало всё новых высот (иногда откатываясь назад, но тем не менее), и вот вчера случилась, как мне кажется, очередная веха: в открытый доступ выложили нейронную сеть для генерации изображений по текстовому описанию — Stable Diffusion.
Да, я уже слышу эти голоса и вижу закатывающиеся глаза: "Опять ты со своими айтишными штучками, поовсюду уже эти нейронные сети, черт бы их побрал. Сходи лучше в парк погуляй, на природу съезди, голову проверти". Но не всё так просто. (И не так сложно, в общем)
Человечество всегда стремилось автоматизировать и ускорить рутину: мельница, печатная машинка, швейная машинка, компьютер, домашний принтер и так далее. Благодаря новым инструментам качество нашей жизни улучшалось, потому что человек был способен освободить свои ресурсы на решение более важных задач, чем вырисовывание букв или сложение в столбик.
С появлением нейронных сетей начался бум различных алгоритмов для разнообразнейших задач. Где-то более успешно, где-то менее, а где-то пугающе хорошо. Сначала нейронные сети научились работать с изображениями: распознавать, какая буква написана (видео 1993 года с демонстрацией первой такой сети), потом с текстом, но там было сильно сложнее.

Пример: для обучения нейронных сетей используется приём с незначительным изменением входных данных для улучшения обощающих способностей модели. Чтобы она распознавала собачку, которая смотрит не только слева, но и справа. И если картинку можно повернуть, отразить, приблизить, сделать темнее, светлее и так далее, то что можно сделать с текстом, чтобы изменить вход, но сохранить смысл? (Если вдруг стало интересно, вот хороший обзор того, что удалось придумать)
Надеюсь, хотя бы на таком простом примере удалось показать, что работать с текстом несколько сложнее, чем с изображениями. И это я ещё молчу о языковых особенностях, всяких "казнить нельзя помиловать", то что "часы могут идти, когда лежат, и стоять, когда висят" и прочие кошмары.
Относительно давно люди всё-таки научились обучать модели на парах картинка-текст, чтобы нейронная сеть описывала словами то, что изображено на картинке. Когда я прочитал впервые об этой новости, ничего не понимал тогда ещё в этом и подумал: "Фантастика, будущее уже наступило".

В 2019 году вышла чисто модель языковая GPT-2, которая навела шуму. А в 2020 вышла GPT-3, которая взяла новую высоту. Они могли связано отвечать на вопросы, продолжать заданный текст, сочинять стихи и так далее. (С русской версией можно поиграться здесь, но она какая-то глупенькая, лучше позапускать тут английскую версию). Да, зачастую надо перебирать несколько вариантов, чтобы получить хороший ответ, но:
- это бесплатные версии, которые могут быть также урезанными и соптимизированными
- как и с любым инструментом, надо набить руку и научиться обращаться
- вспомните про сложность работы с языковыми моделями вообще
Параллельно с этим, естественно, продолжали развиваться модели, работающие с изображениями, они учились генерировать фантастические вещи:
- неуклюжие ещё картины, которые продавались за сотни тысяч долларов (октябрь 2018)
- людей, которых практически не отличить от реальных (декабрь 2018)
- фотореалистичные пейзажи, которые можно рисовать набросками (март 2019)
- deep-fake и замена лиц
- и много чего ещё
Но с генеративной точки зрения изображения и текст всё ещё были далеки друга, пока в начале 2021 года OpenAI не выпустила DALL-E, а весной 2022 DALL-E 2. Они придумали и обучили модель так, чтобы она по тексту генерировала изображение. В зависимости от запроса это могло быть стилизацией под какого-нибудь художника или технику, фотореалистичным изображением того, что никогда не существовало (ну или по крайне мере, не было в обучающей выборке, символом DALL-E стало кресло-авокадо) - чем угодно, что выучилась связывать с текстом нейронная сеть.

Задача, которая ещё несколько лет назад казалась неподъемной, вдруг оказалась решенной. Создатели DALL-E описали архитектуру и используемый подход, но для воспроизведения этого мало: для обучения своей модели нужны колоссальные вычислительные мощности. И, пока создатели давали ограниченный доступ к генерациям только единичным блогерам и журналистам, энтузиасты пытались как-то воспроизвести результаты доступными средствами, развивая и улучшая идеи DALL-E. Результатом стали:
- Craion -- очень скромная, но порой веселая далли-образная поделка
- DiscoDiffusion, который по тексту умеет генерировать видео. Выглядит интересно, но далеко до реализма
- MidJourney, которая стала заслуженным конкурентом DALL-E. Но ни подробностей архитектуры, ни кода создатели не раскрывают -- только платный доступ, зато для всех желающих.
И вот недавно появилась ещё одна модель -- Stable Diffusion. Уровень и качество генераций можно посмотреть здесь или здесь. Меня впечатляет. Особенно с учетом того, что в отличие от конкурентов, создатели SD заявляли несколько важных вещей:
- То что они выложат модель в открытый доступ со всем необходимым для запуска
- В отличие от аналогов сопоставимого качества, она не потребует для работы дорогого оборудования, подойдет любой игровой компьютер (главное требование к видеокарте)
И вот вчера это случилось. И это примечательно даже не тем, что "теперь есть нейронная сеть, которая умеет рисовать картины". Я вижу в этом другое.
Это иллюстрация того, к чему может привести обмен знаниями и опытом, сотрудничество, упорство, вера в людей и целеустремленность. И в этой затянувшейся заметке я постарался передать то, какой огромный путь пришлось пройти нашему миру, чтобы а) добиться решения такой невозможной еще совсем недавно задачи б) безвозмездно отдать решение людям.
И самое поразительное, что значительную текстово-визуальную информацию о мире, которой оперирует нейронная сеть для генерации, создателям удалось вместить в какие-то жалкие 6 гигабайт. Как 2-3 фильма в хорошем качестве.
Просто невероятно и не укладывается в голове, на что способны люди.

Как и то, что параллельно со всем этим, где-то взрываются бомбы, разрушаются жизни и, можно сказать, цивилизации. Люди умирают за какие-то геополитические фантомы, вбитые им головы идеи, которые не стоят ни одной отданной за них жизни. Жизни людей, которые вместо того, сидеть в окопе с автоматом, могли бы приносить пользу человечеству, получив достойное образование и расширяя границы возможного.
И вот этим ощущением невыносимого диссонанса между устремляющимся в будущее прогрессом и разворачивающейся средневековой бойней, которую поддерживает немалая часть населения моей цивилизованной, как будто бы, страны, я и хотел поделиться.
А желающих потрогать будущее, приглашаю позапускать StableDiffusion здесь. При регистрации дают 200 кредитов. В настройках можно указать количество и настройки изображений, от этого будет зависеть количество потраченных кредитов. Когда кредиты закончатся, придется как-то докупать. (Ну и пока что не прикрыли возможность зарегистрировать несколько почтовых ящиков)