Машинное обучение для прогнозирования тенниса

Математическое моделирование тенниса набирает популярность на наших глазах. Каждый год появляются новые аналитические модели и сервисы, соревнующиеся друг с другом в точности прогнозирования исходов теннисных матчей. Это вызвано желанием заработать на стремительно растущем онлайн рынке спортивных ставок: нередки случаи, когда сумма ставок на отдельный матч в профессиональном теннисе достигает миллионов долларов.
В этом обзоре я рассмотрю основные математические методы прогнозирования тенниса: иерархические марковские модели, алгоритмы машинного обучения, а также разберу кейсы IBM, Microsoft и одного российского сервиса, использующих машинное обучение для прогнозирования результатов теннисных матчей.
Введение в проблему прогнозирования тенниса
Большой теннис – это отличное зрелище и большие деньги. Ассоциация теннисистов-профессионалов (ATP) ежегодно проводит более 60 профессиональных турниров в 30 странах. За телетрансляцией игры Энди Маррея против Милоша Раонича в финале Уимблдона 2016 следило свыше 13,3 млн. человек в одной только Великобритании. Ставки на теннис догоняют по популярности футбол. На крупнейшей в мире онлайн-бирже ставок Betfair общая сумма ставок на матч Маррей-Джокович в финале Уимблдона 2013 составила 63 млн. долларов. Потенциальная прибыль и научный интерес обусловили всплеск исследований в области алгоритмов точного прогнозирования теннисных матчей.
Система очков в теннисе имеет иерархическую структуру: матч состоит из сетов, которые состоят из геймов, которые состоят из отдельных очков. В большинстве современных подходов к прогнозированию тенниса эта структура используется для получения иерархических выражений вероятности победы игрока в матче на основе марковских цепей. Если считать, что очки в теннисе распределяются независимо и одинаково (independent and identical distribution, IID)[1], для получения выражения необходимо знать только вероятность выигрыша каждым игроком очка при подаче. На основании этой базовой статистики, которую легко получить из исторических данных в Интернете, можно вычислить вероятность выигрыша каждым игроком гейма, потом сета и, наконец, матча.

При всей изящности такого подхода, он не может быть признан идеальным. Представляя качества игроков только по одному параметру (выигранные очки при подаче) такой метод неспособен учитывать более тонкие факторы, которые также влияют на исход матча. Например, приверженность игрока определенной стратегии, время после травмы, общая усталость от предыдущих матчей могут лишь косвенно повлиять на прогноз матча, полученный методом иерархических моделей. Более того, характеристики самого матча – покрытие, местоположение, погода – вообще не учитываются в таком прогнозе.
Принимая во внимание огромное количество исторических данных по теннису, можно предложить альтернативный подход к прогнозированию теннисных матчей – машинное обучение. Параметры игроков и матча вместе с результатом матча могут составить обучающую выборку. Алгоритм машинного обучения с учителем может использовать эту выборку для построения функции предсказания результатов новых матчей.
Несмотря на то, что машинное обучение само собой напрашивается для решения проблемы прогнозирования тенниса, этот подход до недавнего времени привлекал значительно меньше внимания исследователей, чем стохастические иерархические методы. В большинстве исследований применения машинного обучения к теннису используются логистическая регрессия и нейронные сети. ROI наиболее точной модели, описанной в научной литературе, составляет 4,35%, что по заявлению автора на 75% лучше современных стохастических моделей [2].
Большинство онлайн-сервисов прогнозов на теннис (людей-прогнозистов не рассматриваем) используют именно стохастические модели и предлагают пользователям вероятности победы каждого игрока с сопутствующей статистикой, которую предлагается анализировать самостоятельно. Я рассмотрю более интересные случаи, когда с помощью алгоритмов машинного обучения анализируются не только вероятности выигрыша очка при подаче, но и историческая статистика по игрокам и параметры матча. Я рассмотрю кейсы таких гигантов как IBM, Microsoft, а также российского сервиса OhMyBet!, прогнозирующих теннис с помощью алгоритмов машинного обучения.
Но обо всем по порядку.
Данные для тенниса
Исторические данные по теннисным матчам широко доступны в интернете. Официальные сайты турниров, например, www.atpworldtour.com, предоставляют информацию об игроках и результатах матчей, а также результативность спортсмена по каждому матчу. Некоторые источники, например, www.tennis-data.co.uk, предоставляют исторические данные в структурированной форме (CSV или Excel файлы). Доступны и платные базы данных – более комплексные, на более длинные периоды и с лучшей точностью, например, база OnCourt.
Наиболее релевантные данные, которые можно взять из подобных баз данных, представлены в таблице ниже.
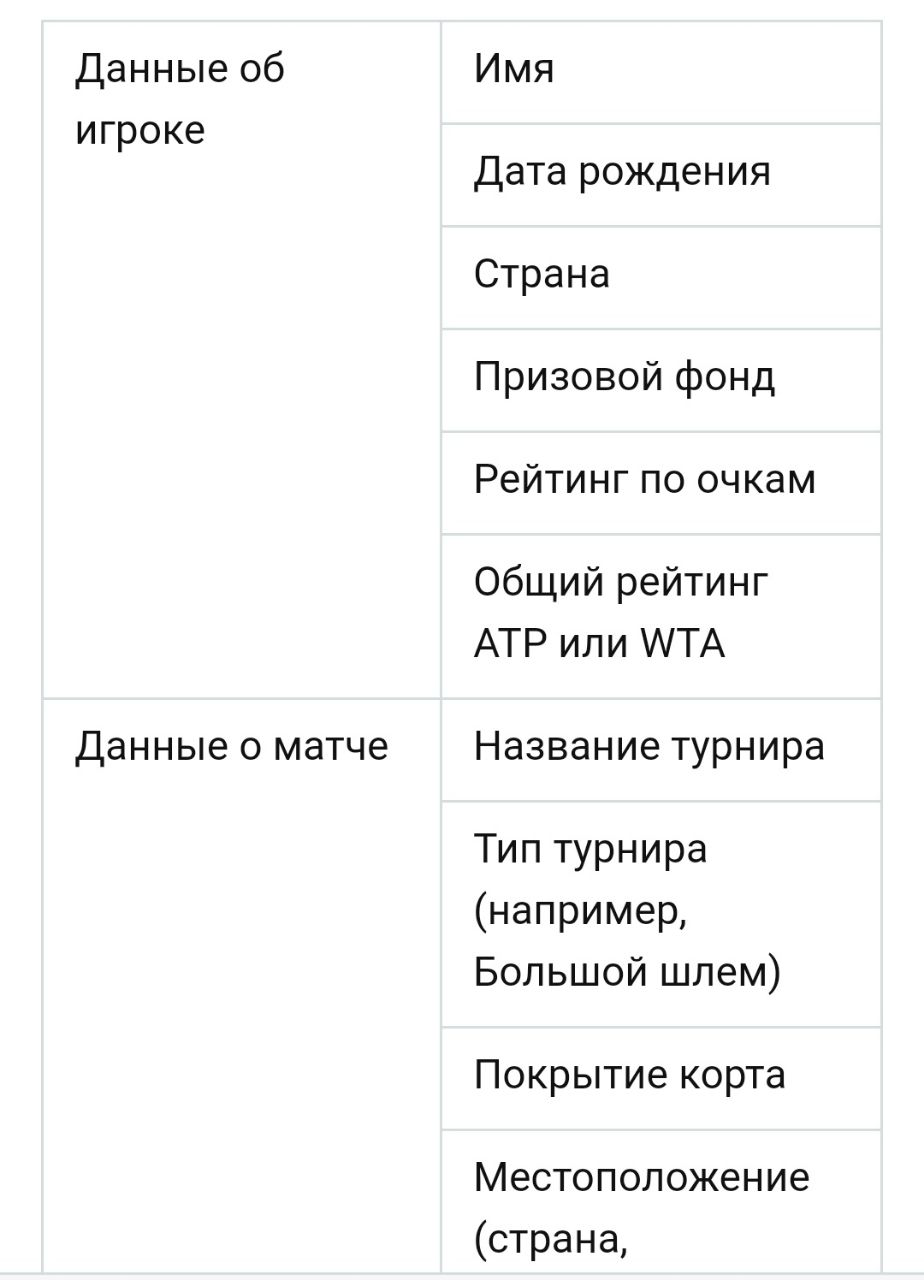
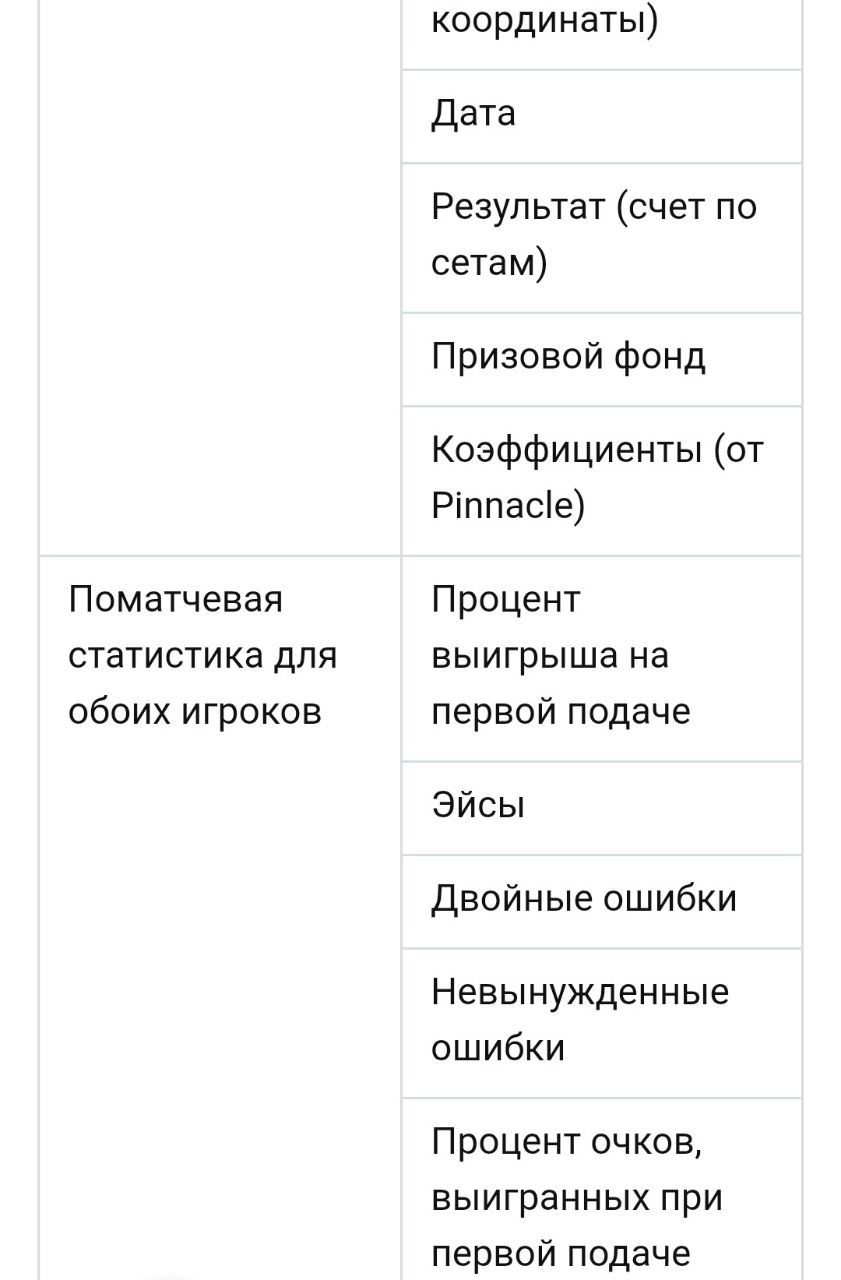
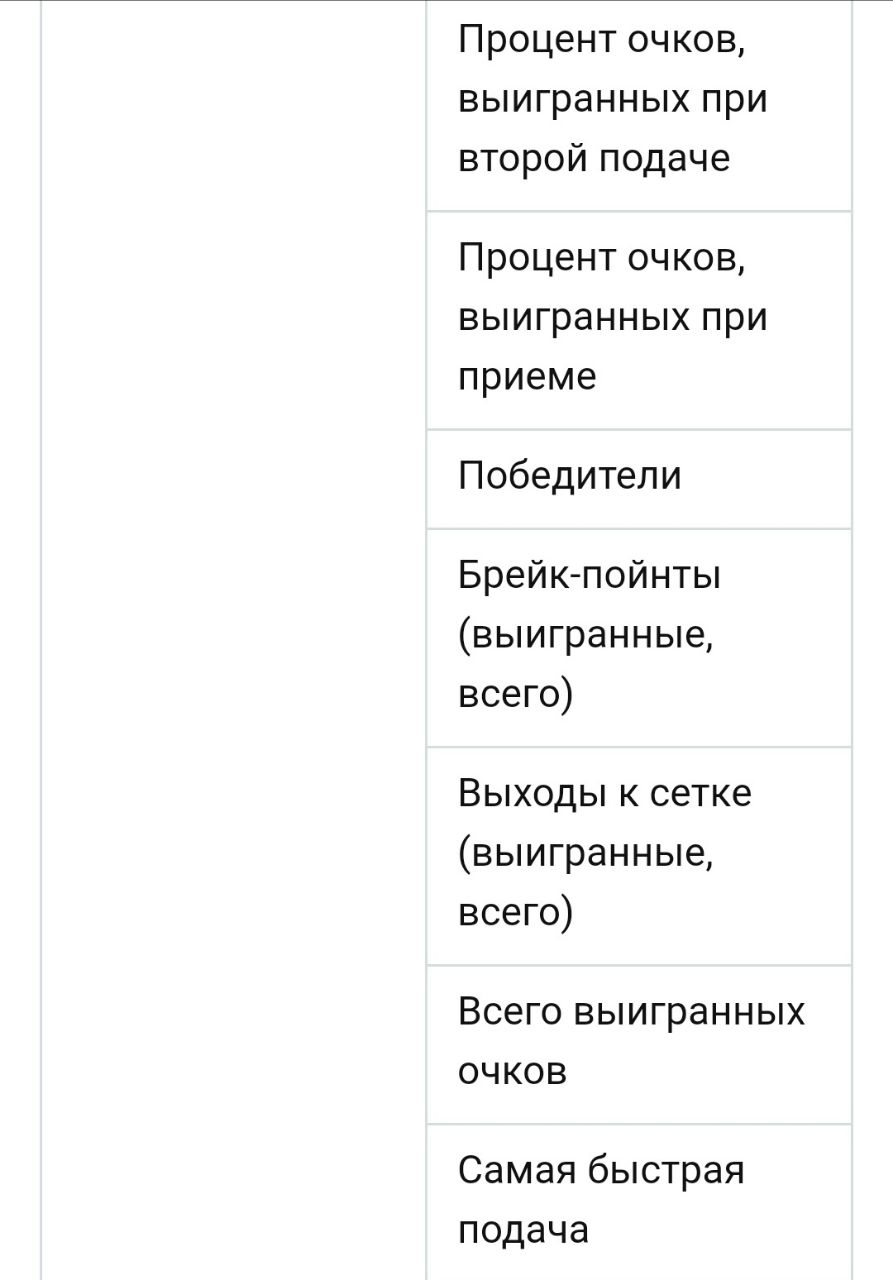
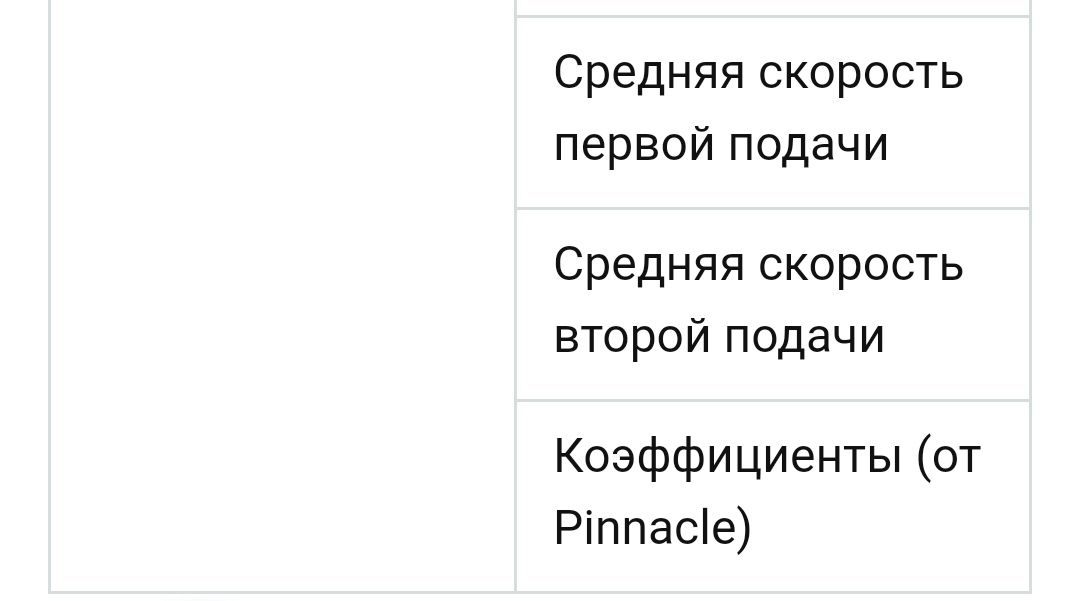
Для моделирования матча могут быть важны и такие данные как статистика по сетам и по очкам для каждого игрока. Эти данные можно получить путем парсинга таких сайтов как flashscore.com. Важно отметить, что с помощью технологии отслеживания мяча HawkEye для многих турниров можно получить данные более высокого качества и детализации, например, положение мяча и игрока в любой момент матча. Однако ассоциация ATP, владеющая этими данными, не выдает лицензии на их использование третьим сторонам.
Ставки на спорт
Существуют две основные категории ставок на теннис: предматчевые и live-ставки, различающиеся уровнем коэффициентов. Кроме того, сделать ставку можно не только на победителя матча, но и на множество других факторов, например, на счет в отдельных сетах, общее количество геймов, и т. д. Большинство прогностических моделей ориентированы на предматчевые ставки на победителя в матче, так как именно на этот тип ставок доступно больше всего исторических данных по коэффициентам, что позволяет провести наиболее полную оценку эффективности прогностической модели.
Ставки на теннисные матчи можно размещать либо в букмекерских конторах (онлайн и оффлайн), либо на биржах ставок. Традиционные букмекеры (например, Pinnacle) устанавливают коэффициенты на различные исходы матча, а клиент (беттор) играет против букмекера. В случае бирж ставок (например, Betfair) клиенты могут делать ставки против коэффициентов, установленных другими бетторами. Биржа уравнивает ставки клиентов и зарабатывает на сборе комиссии с каждой сыгравшей ставки.
Коэффициенты, предполагаемая вероятность и ROI
Коэффициент ставки означает прибыль, которую получит беттор, если верно угадает исход события. Например, если беттор верно спрогнозировал победу игрока, коэффициент на которого составляет 3,00, он получит 2 доллара на каждый поставленный доллар (в добавок к сумме самой ставки, которая возвращается). Если прогноз беттора оказался неверен, он теряет только сумму своей ставки независимо от коэффициентов. Существуют разные системы записи коэффициентов, наиболее популярными из которых являются десятичная или европейская (1,5, 2,00, 2,50 и т. д.) и дробная или британская (1/2, 1/1, 6/4 и т. д.).
Коэффициенты выражают предполагаемую вероятность исхода матча, то есть оценку букмекером истинной вероятности. В описанном выше примере с коэффициентом 3,00 (1 к 3) предполагаемая вероятность p победы игрока в матче равна 33%.
Прибыль за определенный период времени называется возвратом инвестиций (return on investment, ROI). В случае ставок на спорт ROI – это процент выигрыша с каждой сделанной ставки, усреднённый на дистанции. Упрощенная формула ROI при фиксированном размере ставки выглядит так:
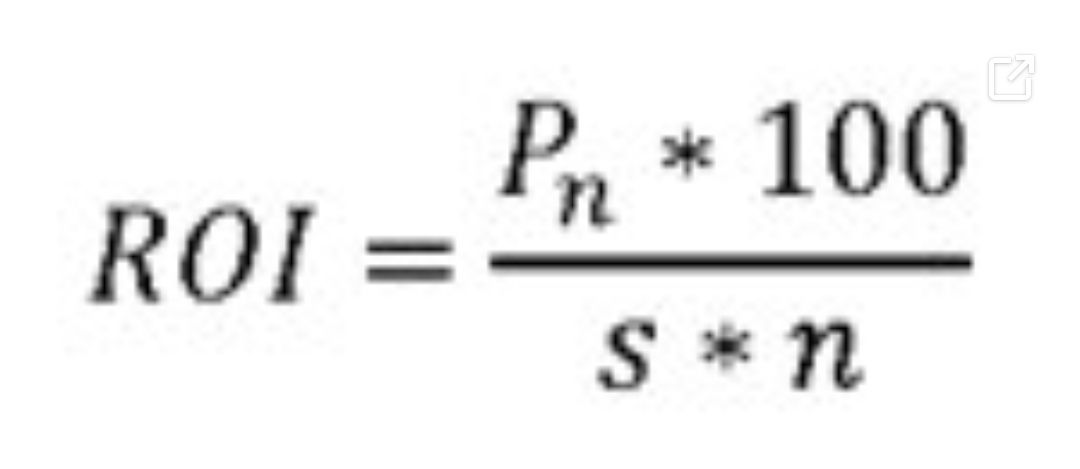
где Pn – общая прибыль на дистанции,
s — сумма одной ставки,
n — количество ставок (дистанция). ROI – это основной показатель успешности беттора, и, соответственно, – целевой показатель эффективности прогностической модели.
Измерение эффективности модели на основании ROI, вычисляемого на исторических данных рынка ставок, является общепринятым подходом в исследованиях в этой области (в том числе в [2], [4], [7]). Если в качестве целевого значения выбирать точность модели (процент верных прогнозов), то при тривиальной фильтрации матчей по низким коэффициентам (1,01-1,3) можно приблизиться к точности 90% и более, но по понятным причинам, ROI при этом будет отрицательной.
Стратегии ставок
Зная коэффициент и предполагаемую вероятность исхода матча, можно принять разные решения, сколько ставить и ставить ли вообще. Очевидно, что различные стратегии дают в итоге разный ROI. Как правило, для оценки эффективности прогностической модели используются три базовые стратегии. Пусть
si = размер ставки на игрока i
pibettor — оценка беттором вероятности победы игрока i
bi = чистый коэффициент при ставке на игрока i, вычисляемый как x-1 для десятичной записи коэффициентов или как x/y для дробной записи.
piimplied — предполагаемая вероятность победы игрока i, вычисляемая как (1/x)*100% для десятичной записи x, или как y/(y+x)для дробной записи x/y.
1. Ставка на предсказанного победителя
В простейшей стратегии беттор всегда ставит фиксированную сумму q на прогнозируемого победителя:
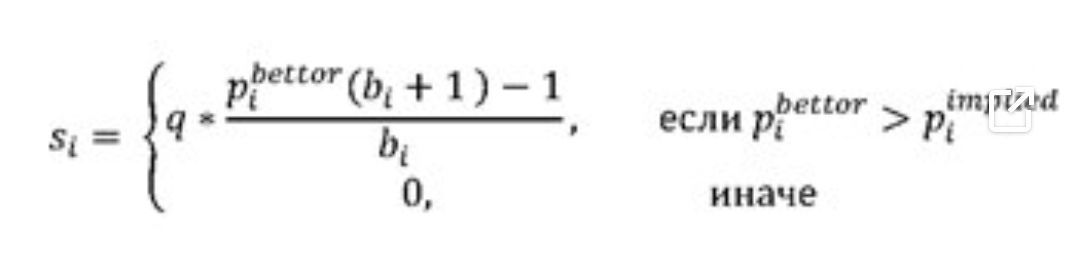
2. Ставка на предсказанного победителя с высоким коэффициентом
Беттор может увеличить прибыль, делая фиксированную ставку q только на матчи, где он имеет преимущество над букмекером, то есть оценка вероятности беттором победы игрока i выше, чем вероятность, предполагаемая коэффициентом букмекера. Иными словами, эта стратегия избегает ставок на предсказанного победителя, если коэффициент не компенсирует в достаточной мере риск ставки.

3. Ставка на предсказанного победителя по критерию Келли
В предыдущей стратегии беттор ставит фиксированную сумму, если по его оценке он имеет преимущество по коэффициентам перед букмекером, независимо от величины этого преимущества. Критерий Келлли, описанный Джоном Келли в 1956 г. [3], можно использовать для определения оптимального размера ставки на основании оценочного преимущества беттора и размера его банка. Доказано, что в долгосрочной перспективе критерий Келли оказывается эффективней все других стратегий.
Беттор ставит долю от максимального размера ставки q на предсказанного победителя, если по его оценке он имеет преимущество:
Фактически максимальный размер ставки
q – это доля от банка беттора, которая, соответственно, изменяется с течением времени, в зависимости от успеха предыдущих ставок. При оценке прогностических моделей
q часто принимается за константу, так чтобы все ставки одинаково влияли на результирующий ROI.
Важно отметить, что во всех трех стратегиях нельзя делать ставки на обоих игроков. Также, если при первой стратегии нужно ставить на каждый матч, рекомендованный моделью (при условии, что оценочная вероятность никогда не бывает ровно 0,5), то вторая и третья стратегии предполагают пропуск некоторых матчей.
Статистические модели
Большинство современных моделей для прогнозирования тенниса используют иерархические стохастические выражения на основе цепей Маркова. Ниже приводится обзор концепций, лежащих в их основе.
Марковские модели
Klaasen and Magnus [1] оспорили теорию IID, показав, что очки в теннисе распределяются не независимо и не одинаково. Однако они также показали, что отклонения от IID настолько малы, что использование этого допущения часто дает хорошие усредненные значения. Этот факт позволяет предположить, что для каждого очка в матче исход этого очка не зависит от предыдущих очков. Предположим далее, что мы знаем вероятность выигрыша очка при подаче каждым игроком. Пусть
p – вероятность того, что игрок
А выиграет очко при подаче,
q— вероятность того, что игрок
B выиграет очко при своей подаче. Используя допущение IID и вероятности выигрыша очков, можно построить марковскую цепь, описывающую вероятность победы игрока в гейме.
Формально, цепью Маркова называется система переходов между разными состояниями в пространстве состояний. Важным свойством системы является отсутствие памяти, то есть, следующее состояние системы зависит только от текущего состояния, а не от предшествующей последовательности состояний. Если принять счет в гейме за пространство состояний, а за переходы между состояниями – вероятности того, что игрок А выиграет или проиграет очко, получим цепь Маркова, отражающую стохастическую прогрессию счета в гейме. На рисунке ниже показана схема цепи для одного гейма с подачами игрока А. Обозначив p вероятность выигрыша очка при подаче и принимая допущение IID, получим, что все переходы, означающие очко, выигранное игроком А, имеют ту же вероятность, а все переходы, означающие проигранное очко, имеют вероятность 1–p.
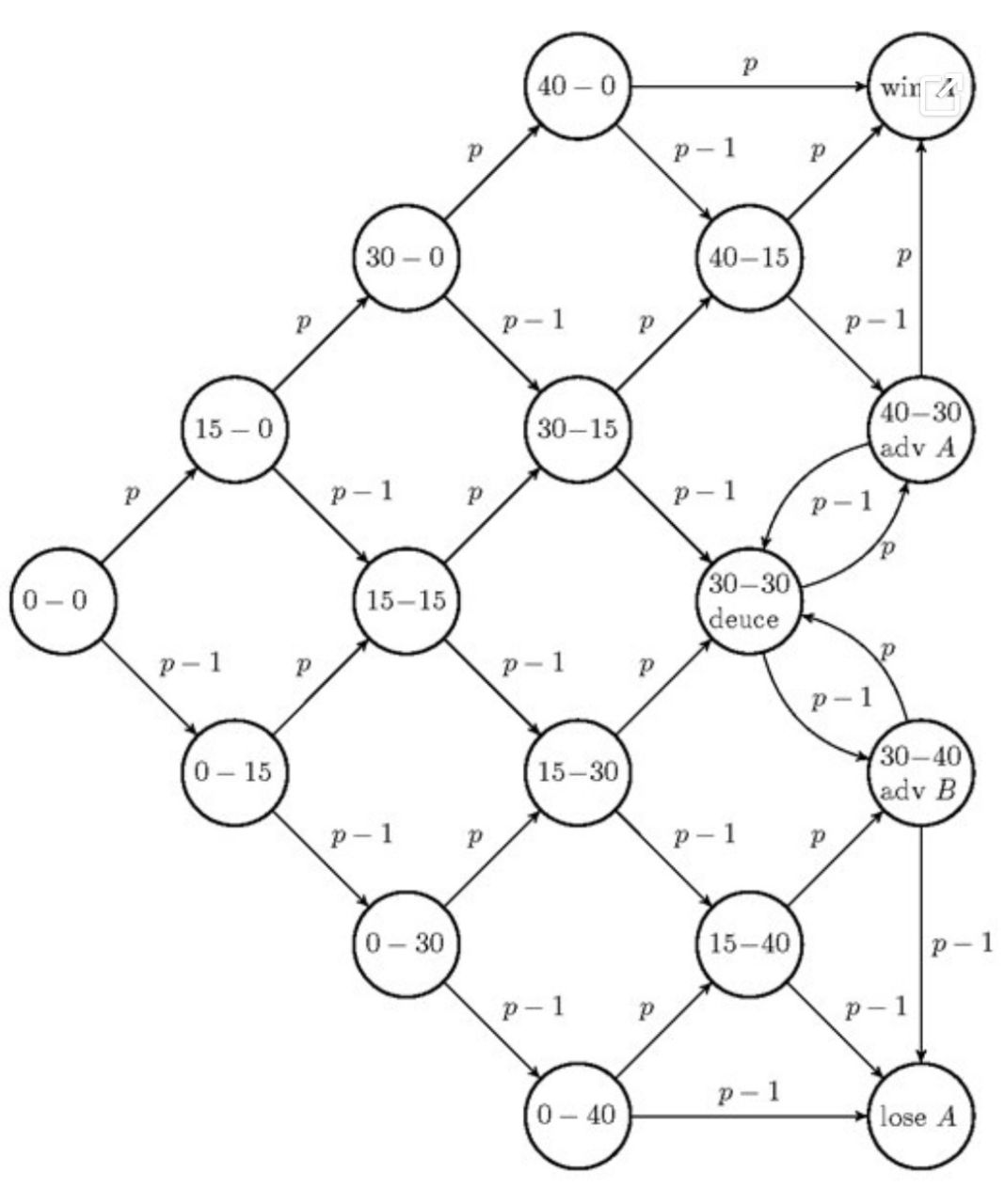
Марковская цепь для гейма в матче, где подает игрок А [2].
За счет иерархической структуры теннисного матча строятся дополнительные марковские цепи, моделирующие прогрессию очков в тай-брейках, сетах и матчах. Например, в модели матча будут два исходящих перехода из каждого неокончательного состояния, помеченные вероятностями выигрыша и проигрыша отдельного сета игроком. Диаграммы таких моделей можно посмотреть в [4].
Иерархические выражения
На основании идеи моделирования теннисных матчей при помощи марковских цепей Barnett and Clarke [5] и O’Malley [6] разработали иерархические выражения вероятности победы определенного игрока во всем матче.Барнет и Кларк описывают вероятность победы игрока А в гейме при своей подаче Pgame с помощью следующего рекурсивного определения:
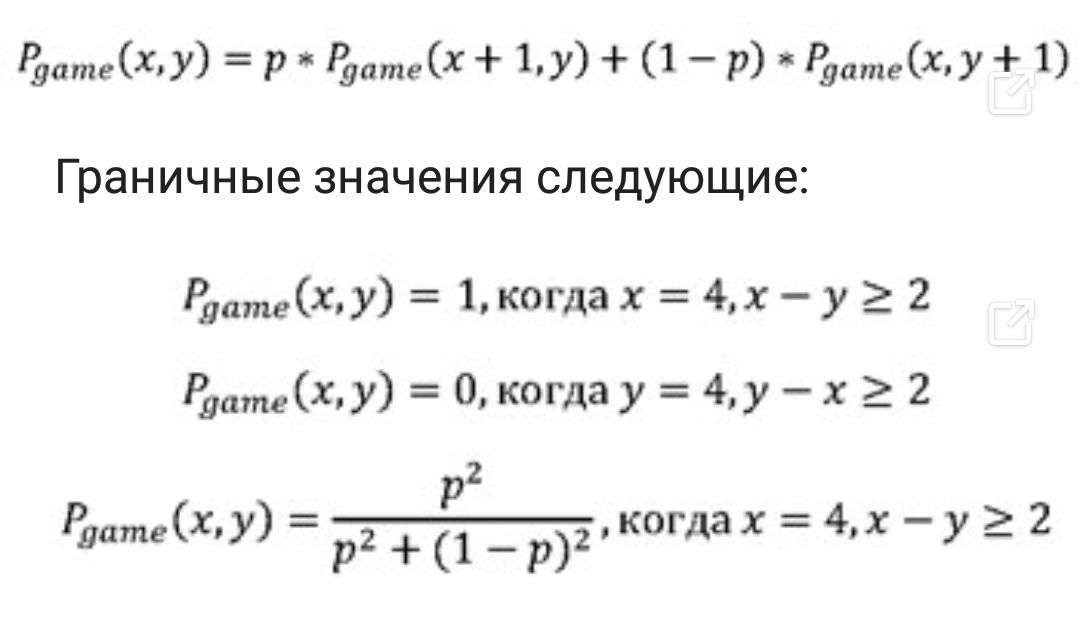
В приведенных выражениях р – это вероятность выигрыша игроком А очка при подаче, x и y – количество очков, выигранных соответственно игроками А и В. Это выражение полностью соответствует марковской цепи на рисунке выше. Барнет и Кларк также определяют сходное выражение вычисления вероятности выигрыша по сетам на основании вероятностей выигрыша отдельных геймов и тай-брейков (которые тоже зависят от вероятностей выигрыша при подаче). Наконец, вероятность выигрыша в матче можно рассчитать с использованием ранее определенных выражений. Получается, что итоговое выражение для вероятности победы в матче зависит только от вероятности выигрыша очка при подаче каждым из игроков.
Оценка вероятности выигрыша при подаче
Остается вопрос, как оценить эти вероятности выигрыша очка при подаче для еще не сыгранных матчей. Барнет и Кларк приводят метод оценки таких вероятностей из исторической статистики игроков:

где
fi – процент очков, выигранных при подаче игроком i
gi – процент очков, выигранных при приеме мяча игроком i
ai – процент первых подач игрока i
aav – cредний процент первых подач для всех игроков
bi – процент выигрыша при первой подаче игрока i
ci– процент выигрыша при второй подаче игрока i
di – процент выигрыша при приеме первой подачи игроком i
ei – процент выигрыша при приеме второй подачи игроком i
Итак, для матча между игроками А и В мы можем оценить вероятности выигрыша очка при подаче игроками А и В соответственно как fABи fBA, используя следующее уравнение:
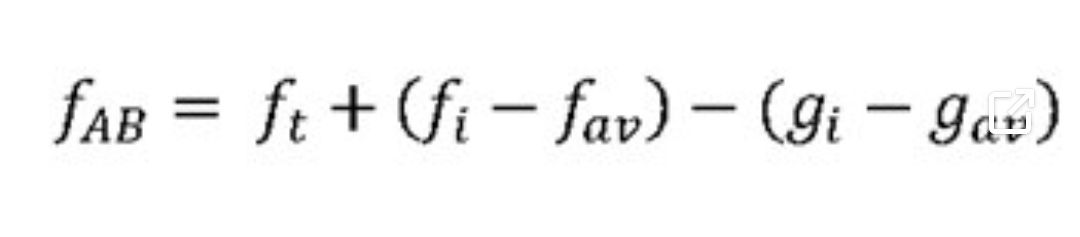
где
ft – средний процент очков, выигранных при подаче на турнире
fav– средний процент очков, выигранных при подаче для всех игроков
gav – средний процент очков, выигранных при приеме для всех игроков
Современные модели
Современные модели прогнозирования тенниса основаны на описанных иерархических стохастических выражениях. Knottenbelt [7] уточнил модели Барнета, использовав для вычисления вероятности выигрыша очка при подаче только матчи с общими соперниками игроков, вместо всех прошлых соперников. Этот подход позволяет снизить погрешность, возникающую из-за того, что игроки в прошлом встречались с соперниками разного уровня. Madurska [4] далее расширила модель общего соперника Кноттенбельта, использовав разные вероятности выигрыша очка при подаче для разных сетов. Таким образом, автор отказалась от допущения IID и ее модель отражает накопление физической усталости у игрока по ходу матча. Модель общего соперника Кноттенбельта и посетовая модель Мадурски – это наиболее современные статистические модели, авторы утверждают, что ROI по их моделям составил соответственно 6,8% и 19,6% в сравнении с рынком ставок на матчи турниров WTA Большого шлема 2011 года. Модель общего соперника также тестировалась на более крупной и разнообразной выборке из 2173 матчей ATP 2011 г. и показала ROI 3,8%.
Продолжение следует....
Подписывайтесь на наши каналы:
Ставки @sportcashpro
Обучение @smartbetspro
