Stable Diffusion у себя дома
О чём эта инструкция.
Эта инструкция не будет учить вас делать идеальные картинки. Stable Diffusion сильно зависит от запросов, их формулирование отдельная наука, которую я и не знаю на самом деле. Цель инструкции - поделиться "протоптанной тропинкой", пайплайном для "превращения фоток в странноватый аниме-арт без какой-либо цензуры на домашнем компьютере". Для обычной генерации качественных картинок без обнаженки все ещё проще и удобнее пользоваться разными платными сервисами. Подозреваю, и для обнаженки тоже есть платные варианты.
Здесь мы будем ставить AUTOMATIC1111 - веб-интерфейс к Stable Diffusion, удобный, простой, полнофункциональный, бесплатный и поставляемый единым архивом, не требующим установку Python и git. Потом мы добавим в него ControlNet - дополнительные инструменты, которые как раз позволят нам превращать фотки в арт. Я расскажу куда в сборку положить модели и откуда их брать. И покажу, как я сам делал картинки.
Текст получился объёмным, однако основная его часть про установку и понадобится всего один раз. Зато подробно и со скриншотами.
Системные требования.
Понадобится Windows 10 или выше, 16ГБ памяти и минимум 10ГБ на жестком диске - не считая места на модели. Моя сборка с кучей (ненужных) моделей занимает 80ГБ, рекомендую ориентироваться на 20-30ГБ минимум. Кроме того потребуется видео-карта от Nvidia с как минимум 4ГБ памяти. Есть неофициальная поддержка карт от AMD и Intel, в том числе встроенных, но с ними вам, увы, придётся разбираться самостоятельно.
Установка AUTOMATIC1111
1. Идём вот сюда - https://github.com/AUTOMATIC1111/stable-diffusion-webui/releases/tag/v1.0.0-pre - и качаем куда-нибудь файл sd.webui.zip. Он маленький, 50мб, и это нормально.
2. Создаём папку, в которой всё это будет жить. Повторюсь, минимум 20ГБ на диске должно быть. Распаковываем в ту папку содержимое архива.
3. Заходим в папку, запускаем в ней файл update.bat - он почти мгновенно обновит сборку до актуальной. Закрываем это окно терминала.
4. Запускаем файл run.bat и идём пить чай: при первом запуске сборка скачает всё, что ей требуется для работы, а так же базовую модель Stable Diffusion 1.5. Это почти 10ГБ в сумме, так что какое-то время займёт в зависимости от скорости вашей сети.
5. Если всё прошло успешно, в браузере откроется новая вкладка с адресом 127.0.0.1:7860, которая будет выглядеть приблизительно так:
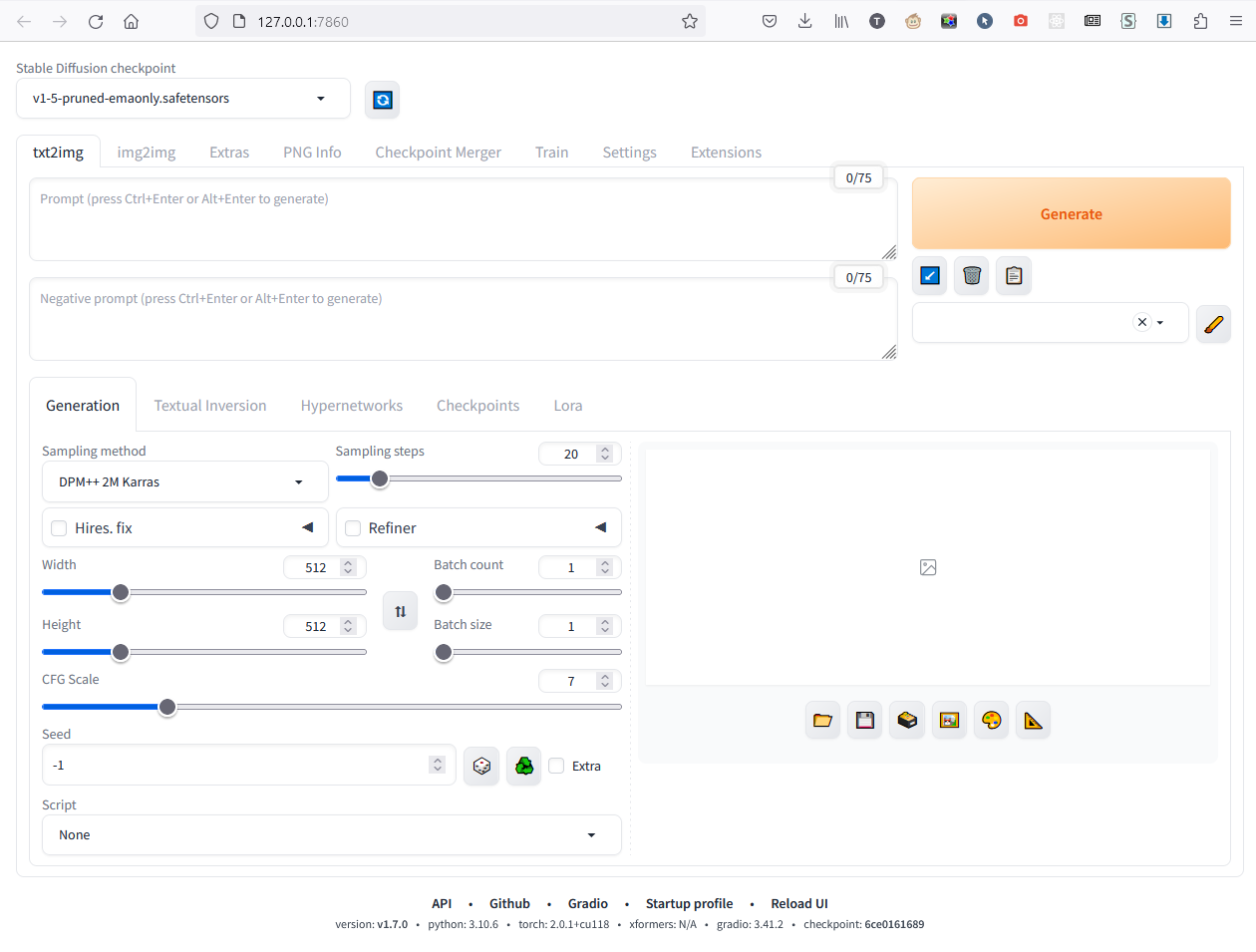
Это и есть веб-интерфейс к Stable Diffusion. Тот же run.bat используется для запуска в последующие разы; чтобы закончить работу, просто закрывайте консольное окно и вкладку браузера.
Установка ControlNet
1. В окне интерфейса идём в Extensions и там в Install from URL:
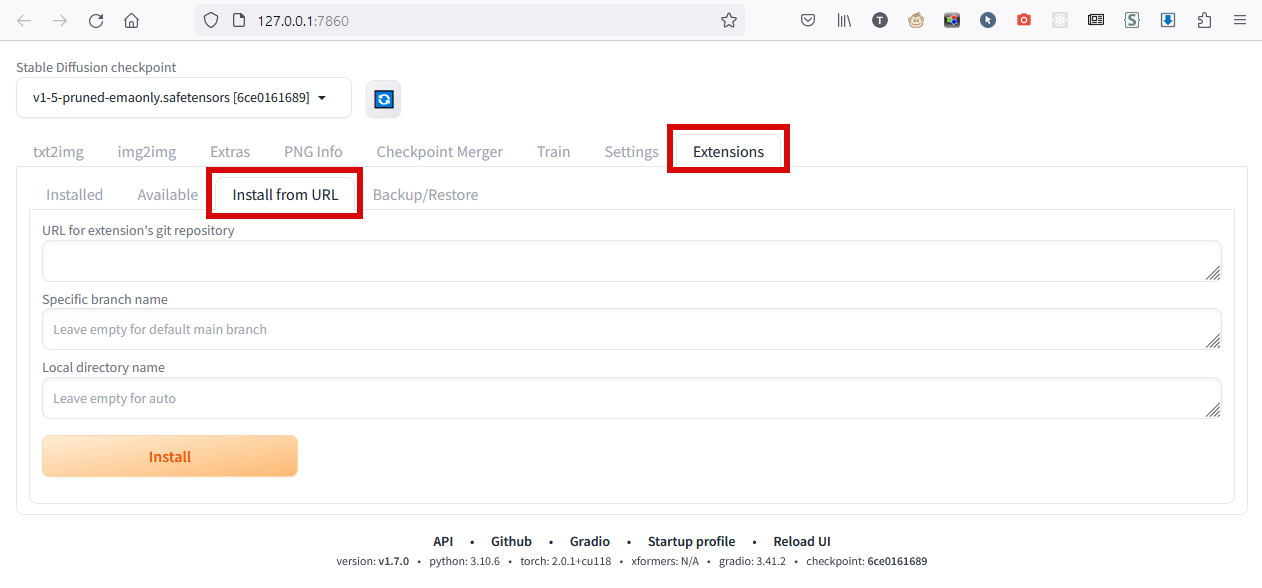
2. В поле URL for extension's git repository вставляем этот адрес https://github.com/Mikubill/sd-webui-controlnet и нажимаем Install.
3. Процесс скачивания и установки займёт пару минут. После закройте вкладку в браузере и консольное окно, а когда всё закроется - снова запустите run.bat. Если всё прошло успешно, ControlNet появится в списке установленных расширений:
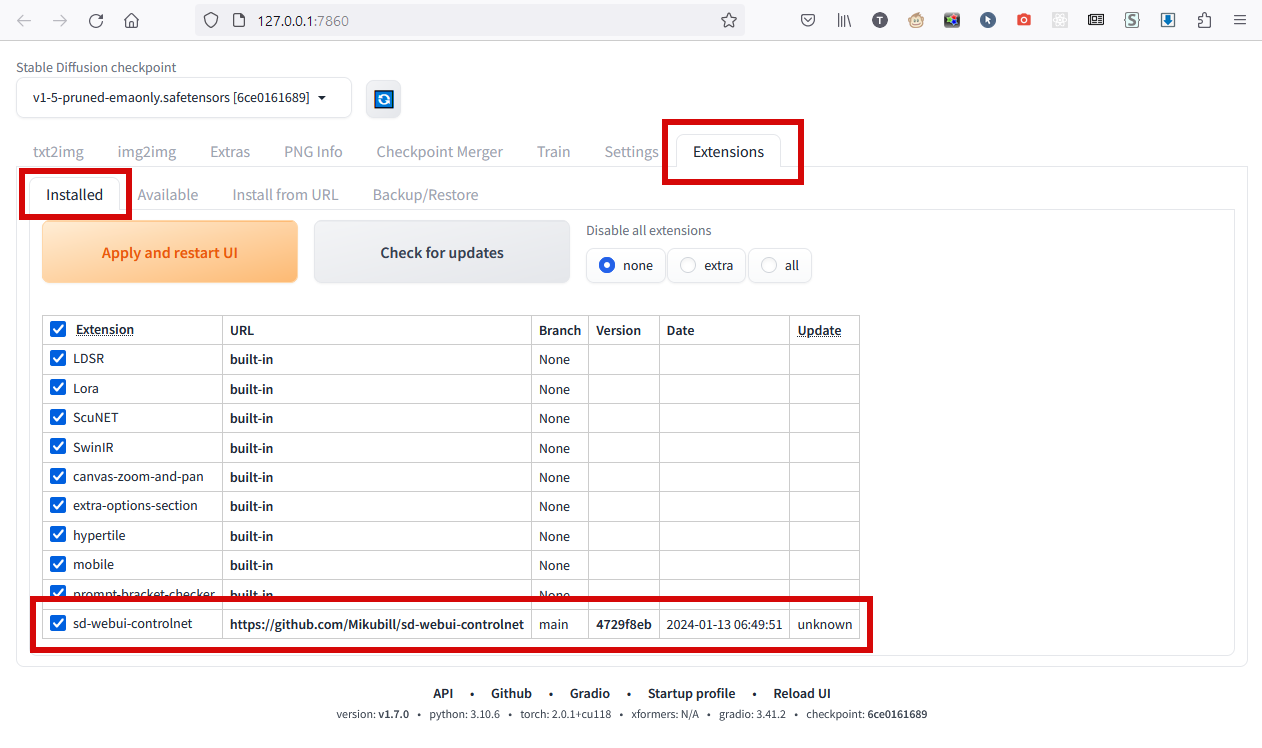
4. ControlNet может распознавать исходное фото разными способами, и для каждого способа должна быть скачана своя модель. Для фотографий больше всего подходит режим SoftEnge (о режимах я скажу позже), кроме того имеет смысл взять Depth, можно Lineart если будете использовать рисованные исходники и Openpose, если хотите пользоваться режимом распознавания позы. Всё это качается отсюда: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main - те файлы, которые по 1.4ГБ.
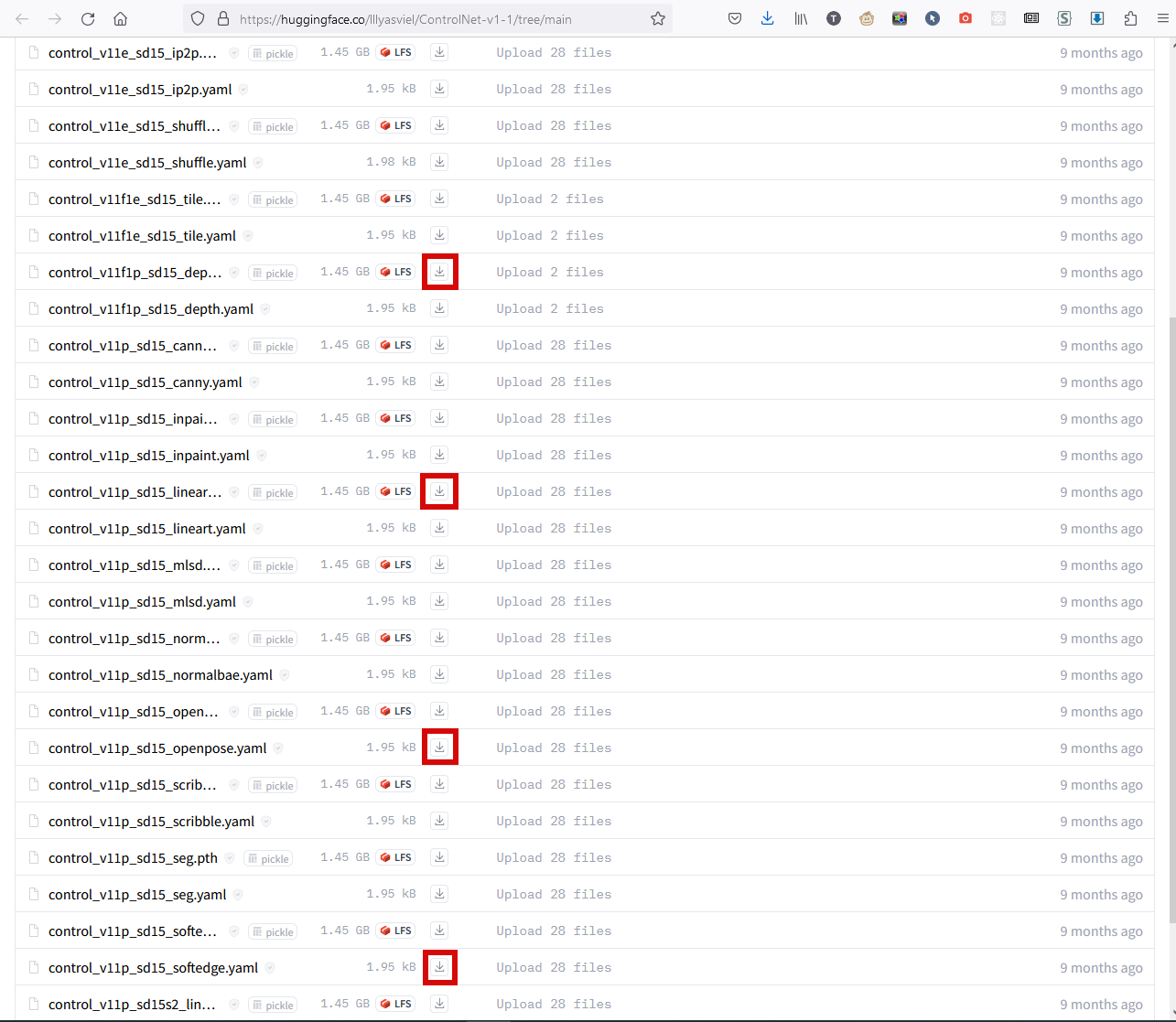
Вот эти четыре, которые перечислены, но лучше взять все (да, это 19ГБ в сумме). Все их нужно поместить в папку webui\extensions\sd-webui-controlnet\models.
В результате всего этого на главной странице веб-интерфейса должен добавиться раздел ControlNet:
Скачивание моделей и моделек.
Сборка поставляется с моделью Stable Diffusion 1.5 - это базовая модель, которая на мой взгляд особого интереса не представляет. Все остальные модели я брал с сайта CivitAI; внимание, по ссылке картинки 18+! Мои картинки я делал моделью Counterfeit-V3.0, на её примере и расскажу.
На странице модели (предыдущая ссылка) находите кнопку Download:
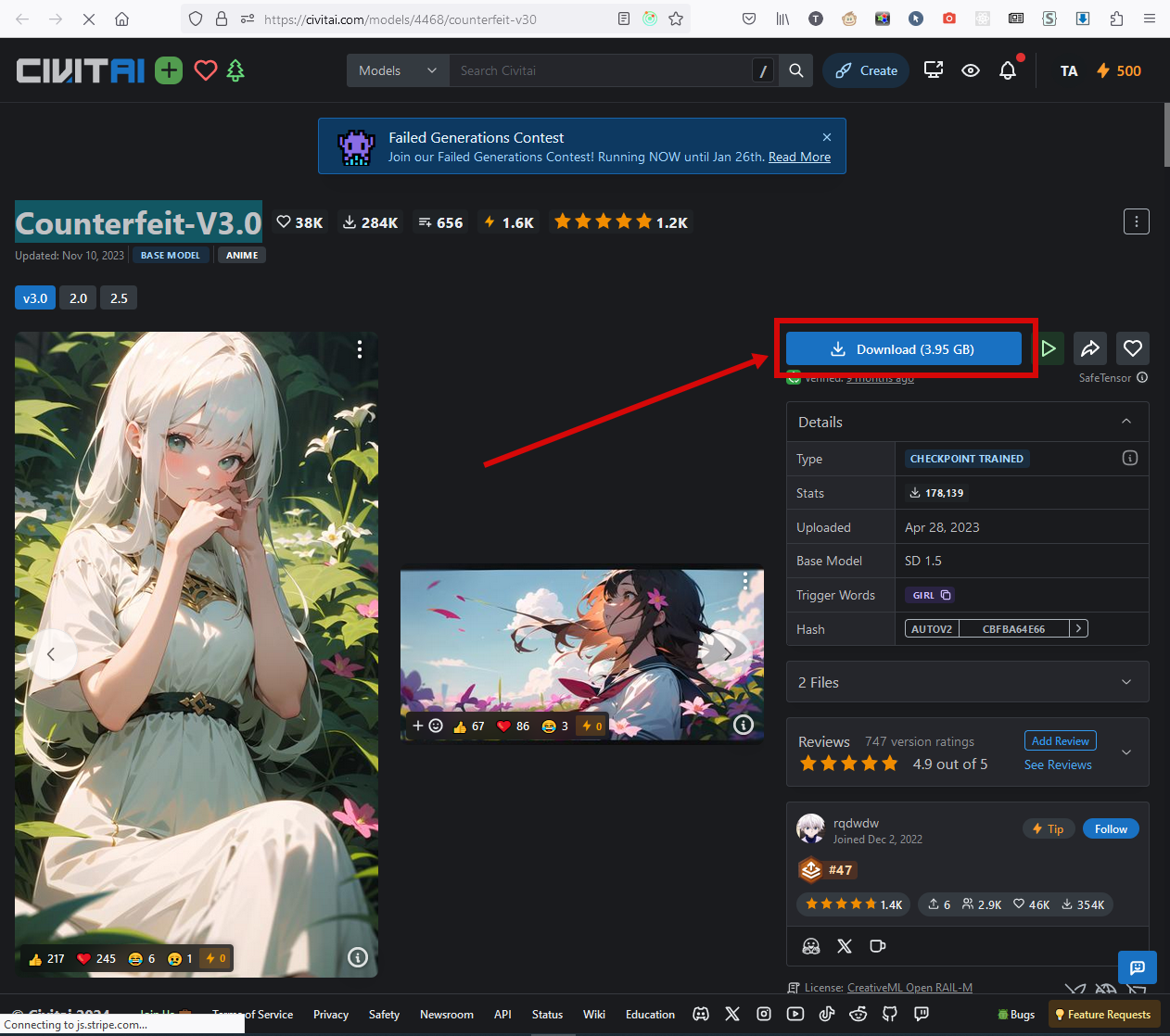
Она предложит сохранить файл CounterfeitV30_v30.safetensors. После скачивания его нужно переложить (или сразу сохранить в) папку webui\models\Stable-diffusion. После обновляете список доступных моделей:
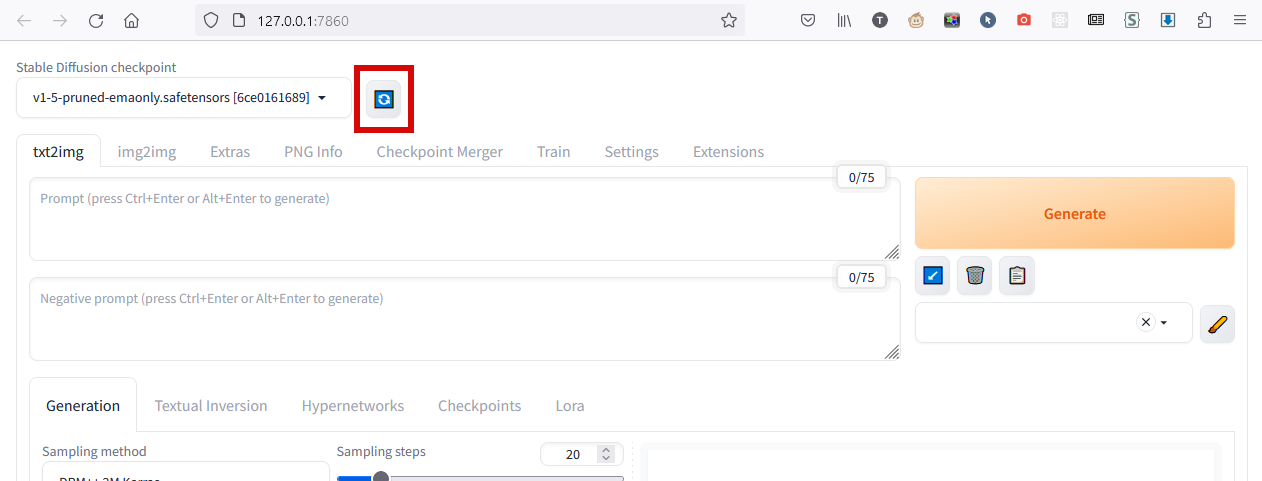
И выбираете из списка модель, которой будете пользоваться: CounterfeitV30_v30.safetensor.
На этом же сайте можно найти миллион других моделей. Отфильтруйте их для поиска приблизительно так:
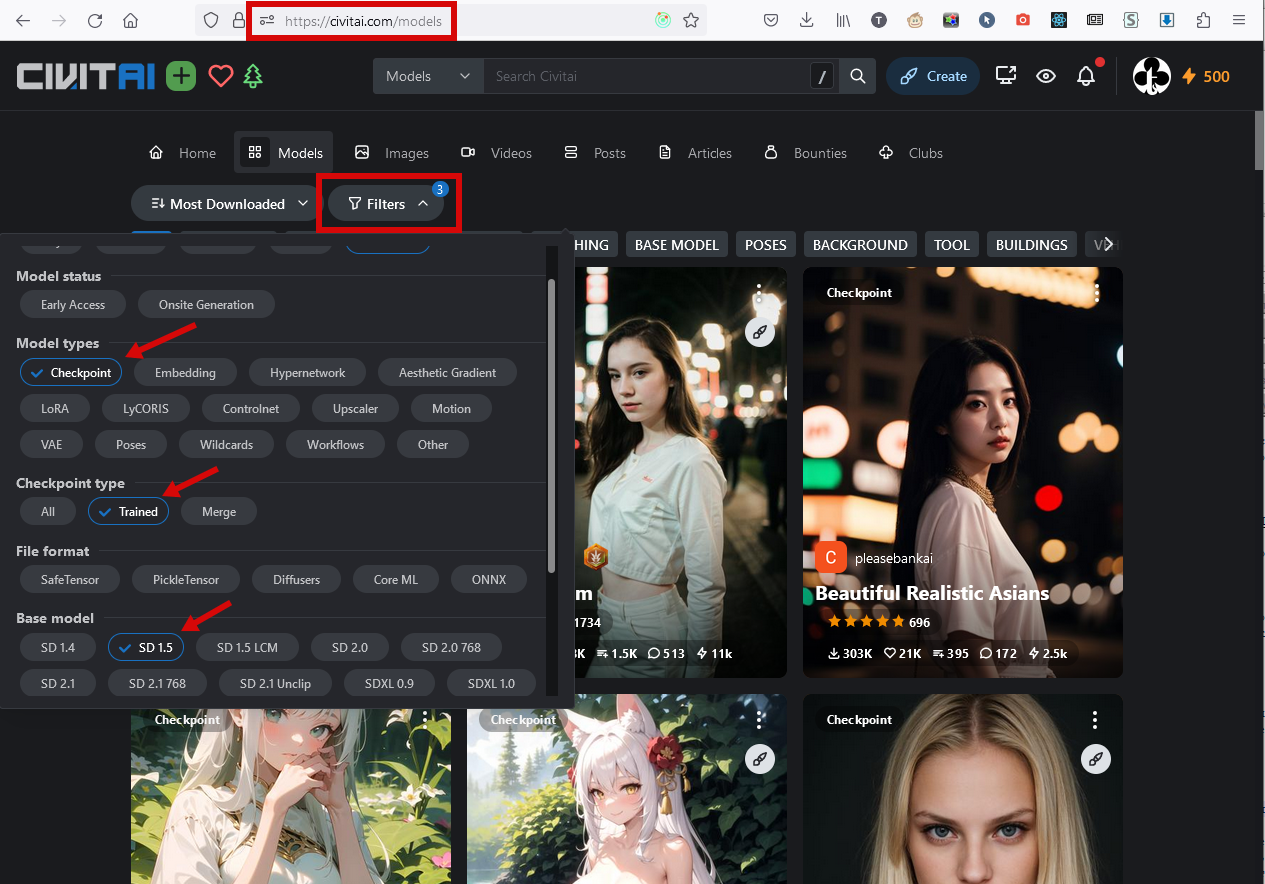
Кроме больших моделей (они называются checkpoint) есть ещё всякие хитрые модели поменьше, макросы и добавки, применяемые к текущей модели. Не буду вдаваться в детали, что это такое и чем отличается от моделей, тем более что сам не особо разбирался. Просто выдам те, которыми пользуюсь: Bad Hands 5, Easy Negative V2 и nsfwEM. Их нужно скачать - они микроскопические - и положить в папку webui\embeddings. Ниже я поясню, как ими пользоваться.
Поздравляю, на этом установка закончена!
Как превращать фото в арт, способ 1.
Первый способ использует только общие очертания исходной фотки для создания результата. Делается это с помощью ControlNet. На главном экране веб-интерфейса разворачиваем панель ControlNet:
Кликаем в центре пустого места слева Click to Upload и загружаем исходную фотку.
Включаем ControlNet (1), включаем превью (2), выбираем режим обработки исходного фото (3) и нажимаем превью (4):
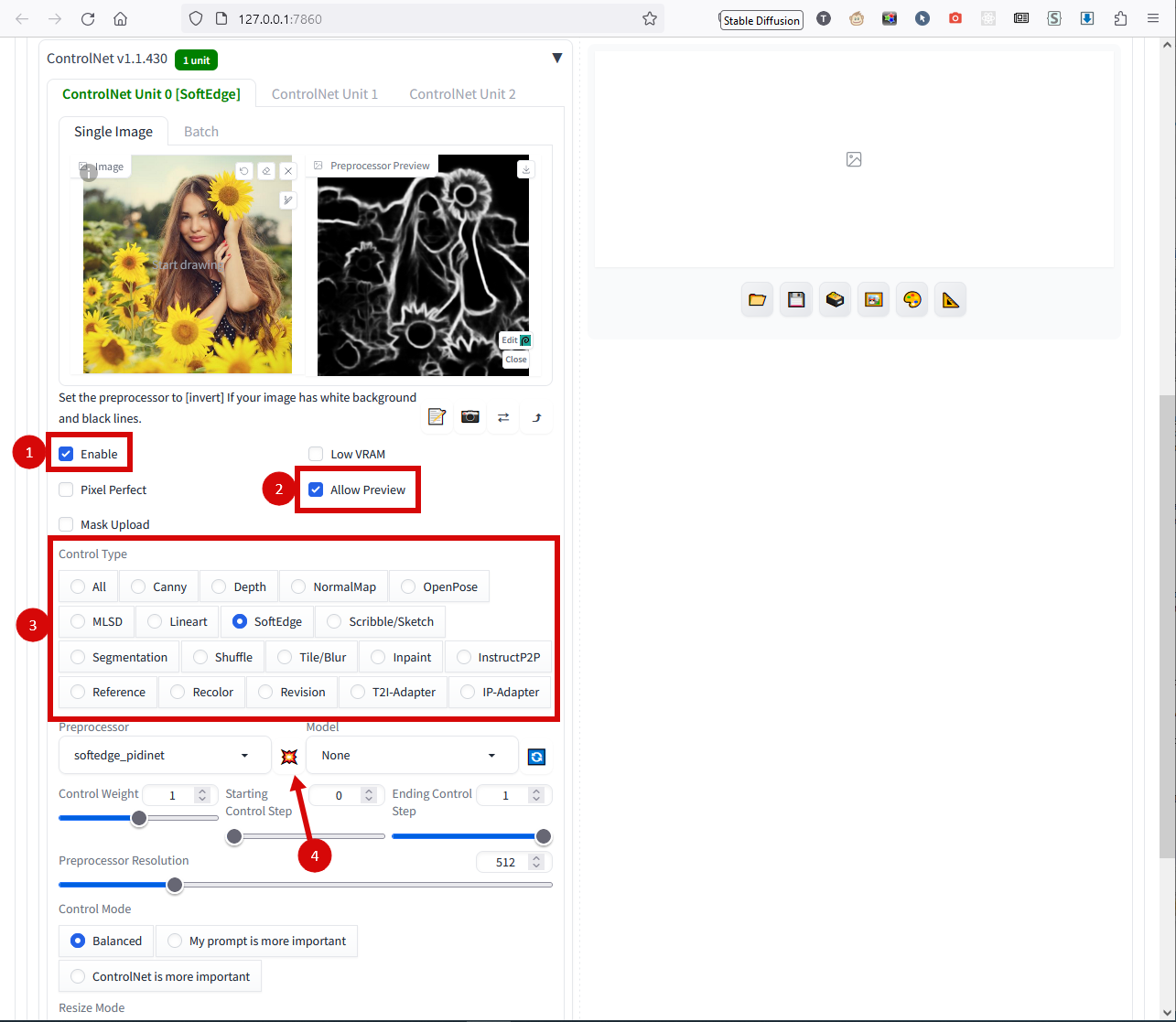
Для фото я обычно использую режим SoftEdge, иногда ещё пробую Depth. Lineart подойдёт, если исходник не фотка, а что-нибудь типа карандашного наброска. Openpose постарается найти на фото человека, распознать его позу и перенести её в результат. Попробуйте другие, потыкайте в превью - вам будет видно, какую вспомогательную картинку в результате получит нейронка. Напомню, для каждого режима требуется своя модель, её в первый раз понадобится выбирать из списка, для каждого режима:
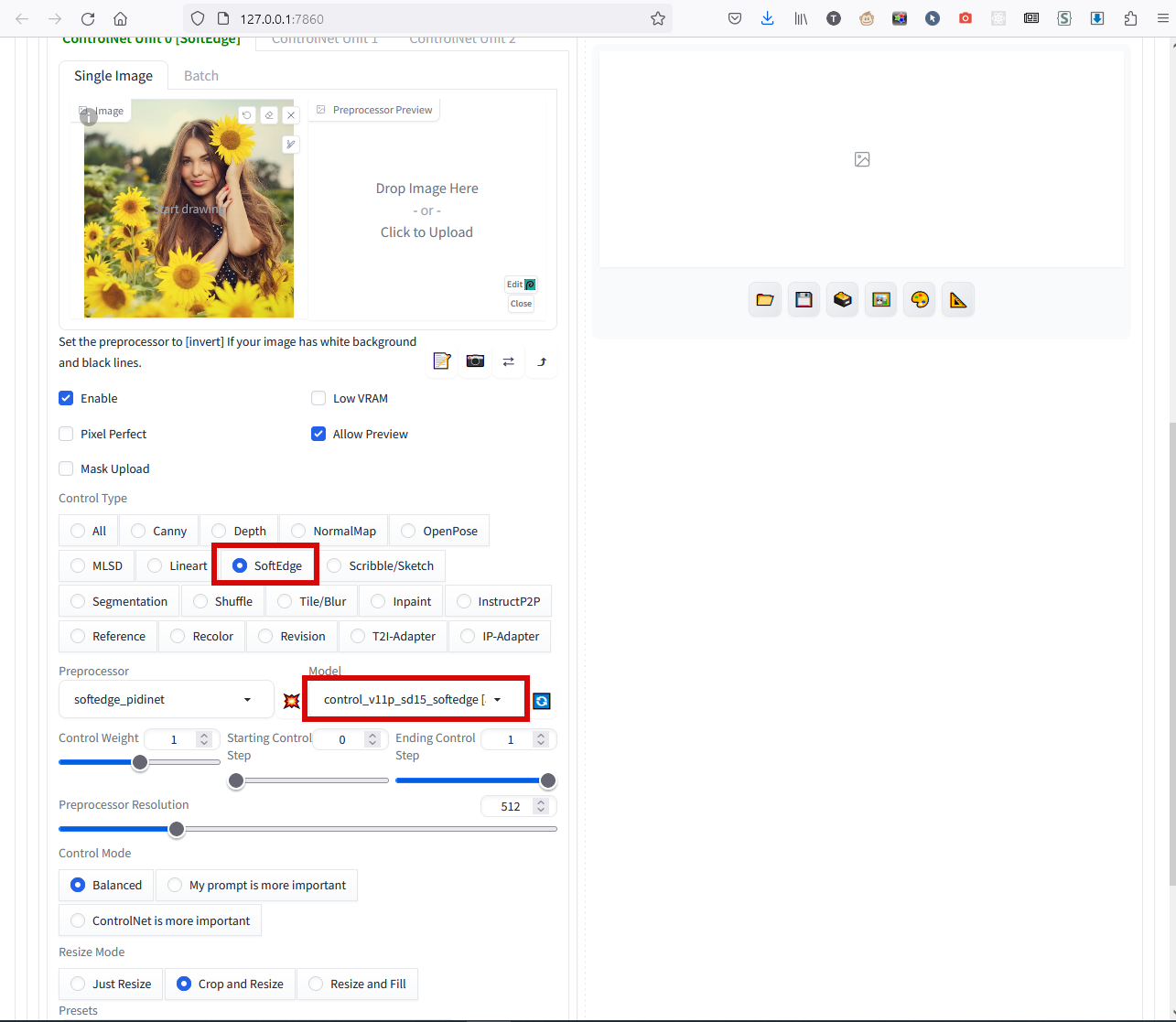
Картинка будет именно вспомогательной, потому запрос всё равно потребуется. Запрос вводится выше в первое же поле, негативный запрос (чего НЕ рисовать) - во второе:
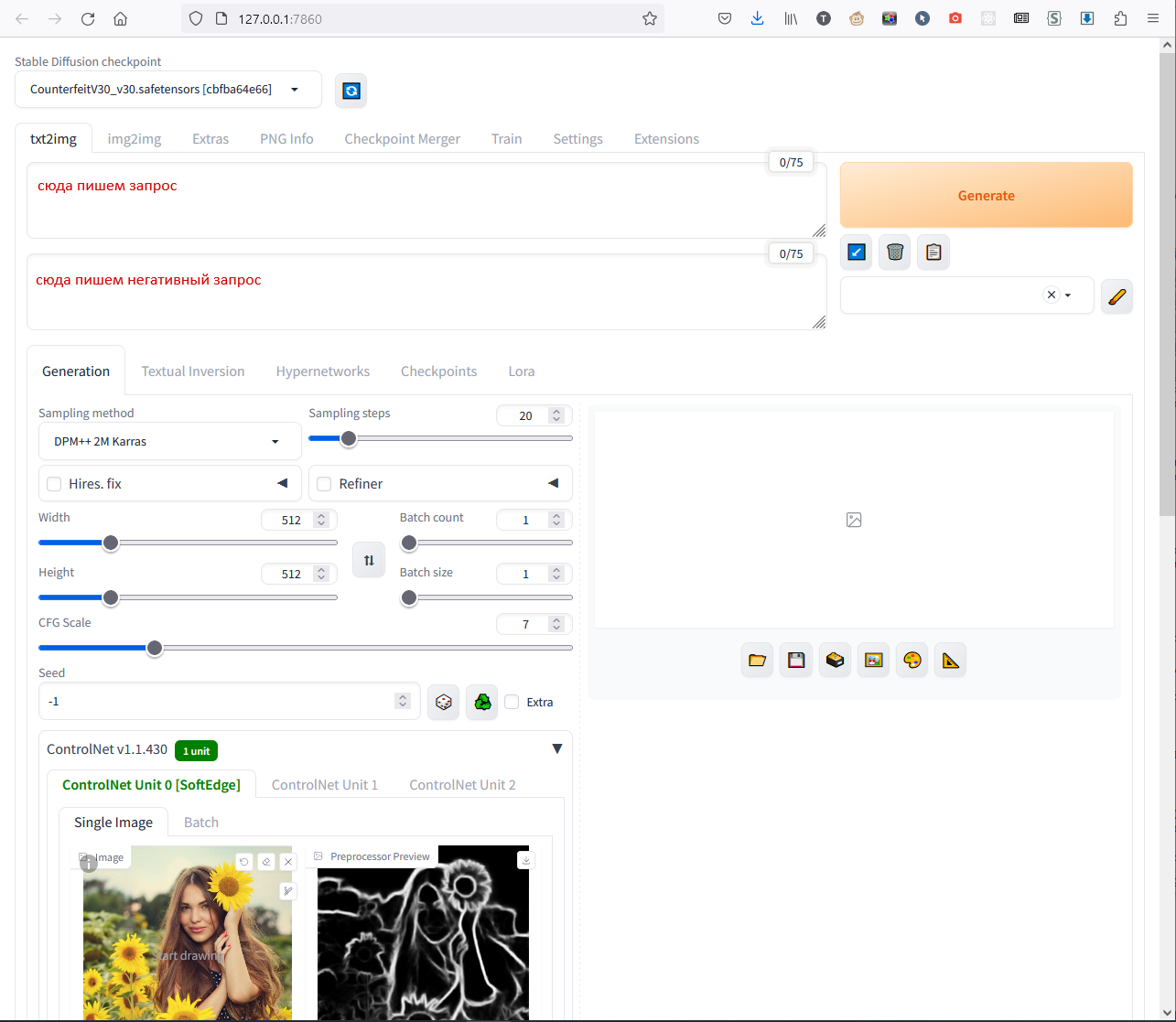
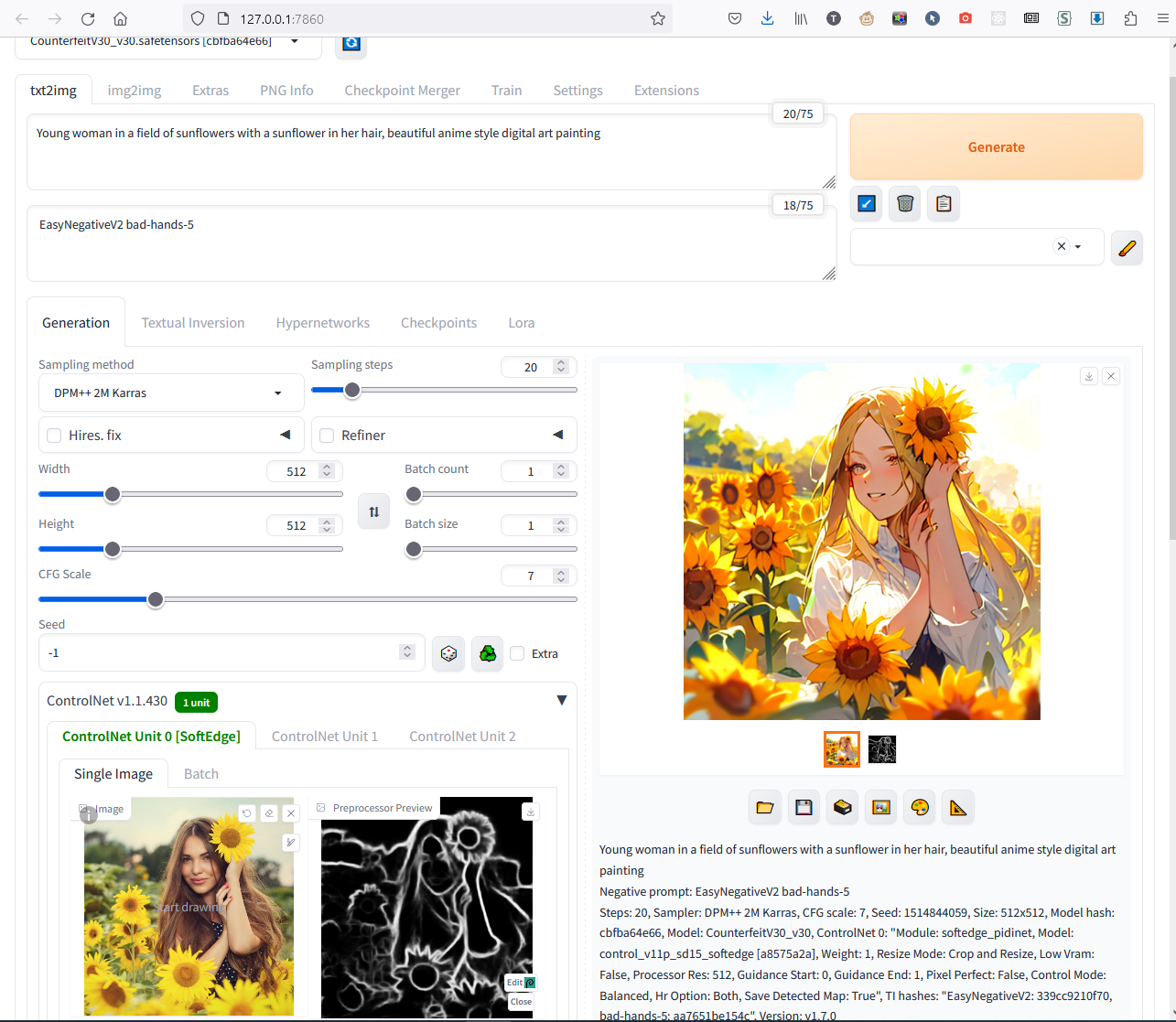
Во второе поле мы сразу вставим текст EasyNegativeV2, bad-hands-5 - это два макроса, которые мы скачали раньше, они улучшают качество картинки. При каждом рестарте веб-интерфейса не забывайте вводить их снова. Нажимаем Generate справа-сверху, и если всё сделано правильно, получится приблизительно так:
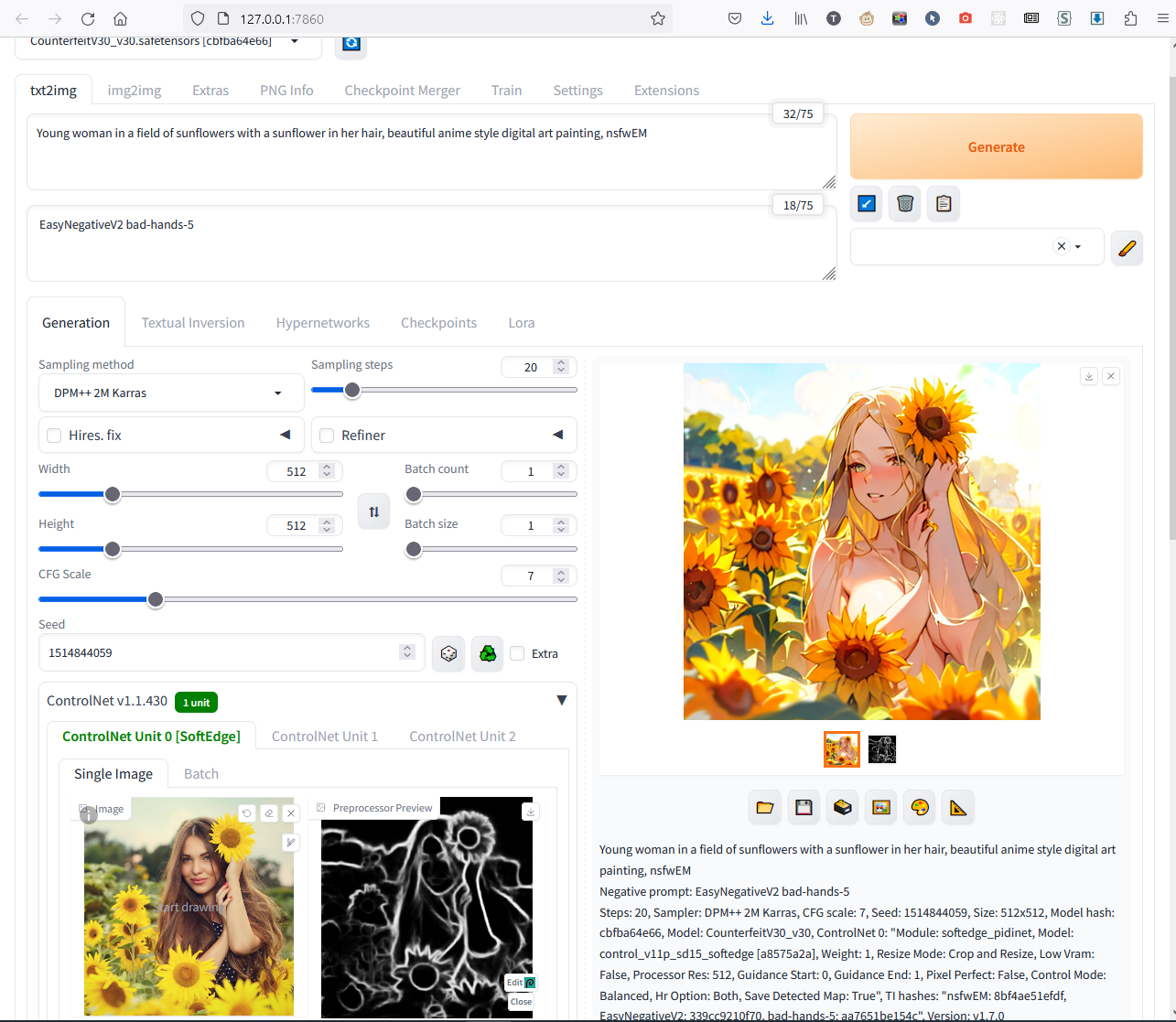
А если в верхнее поле добавить в начале или конце запроса nsfwEM - тоже примочка, которую мы качали раньше - нейронка изо всех сил постарается изобразить обнаженку:
Как превращать фото в арт, способ 2.
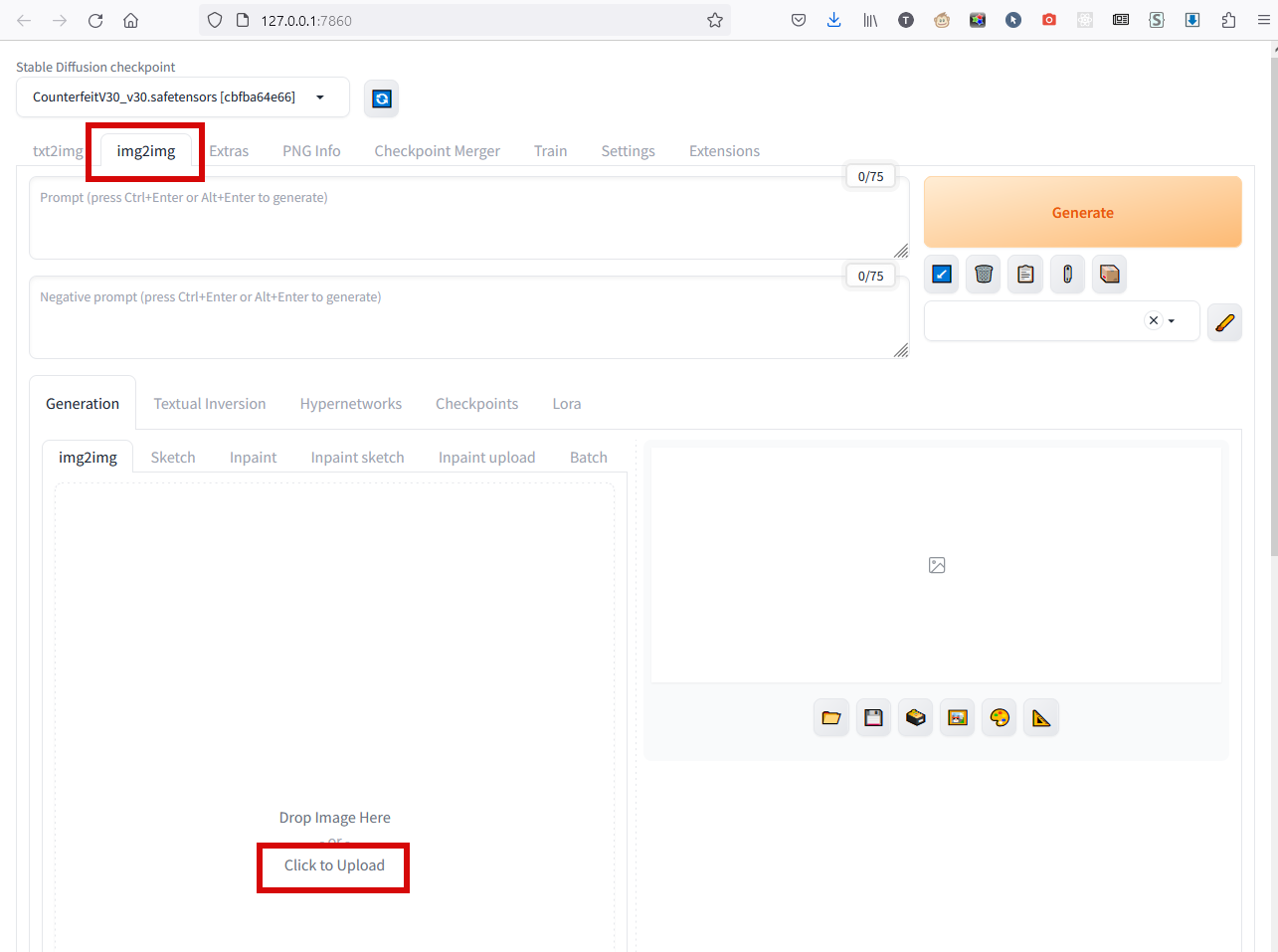
Кроме базового режима txt2img - "текст в изображение" - есть второй режим img2img, "из картинки в картинку":
В этом режиме из исходного фото будут взяты не только очертания, но и цвета. Запрос здесь тоже потребуется и правила его составления те же (и макросы тоже), но нужно ещё и выбрать исходную картинку в большое пустое поле слева. Здесь важный параметр - Denoising strength:
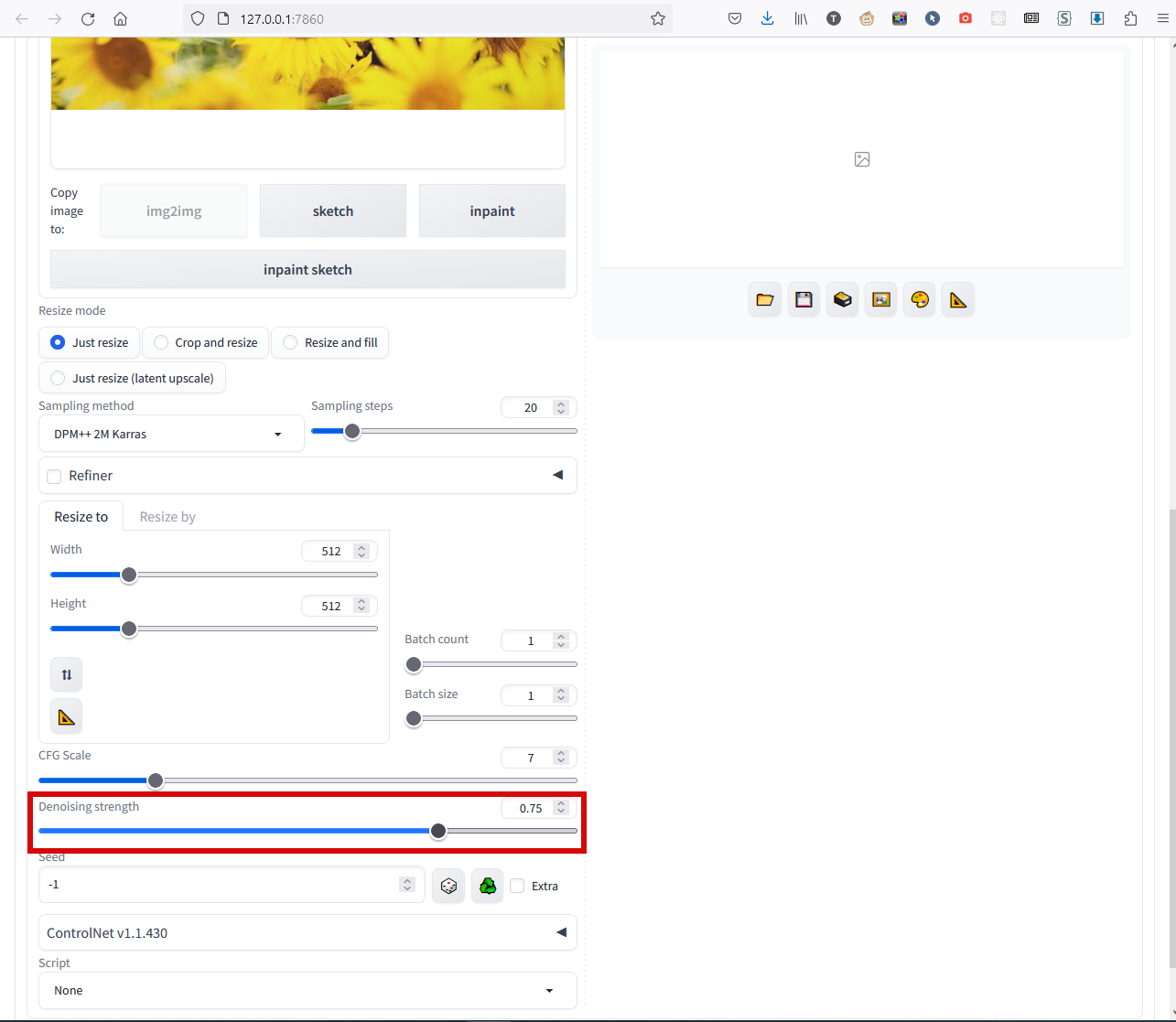
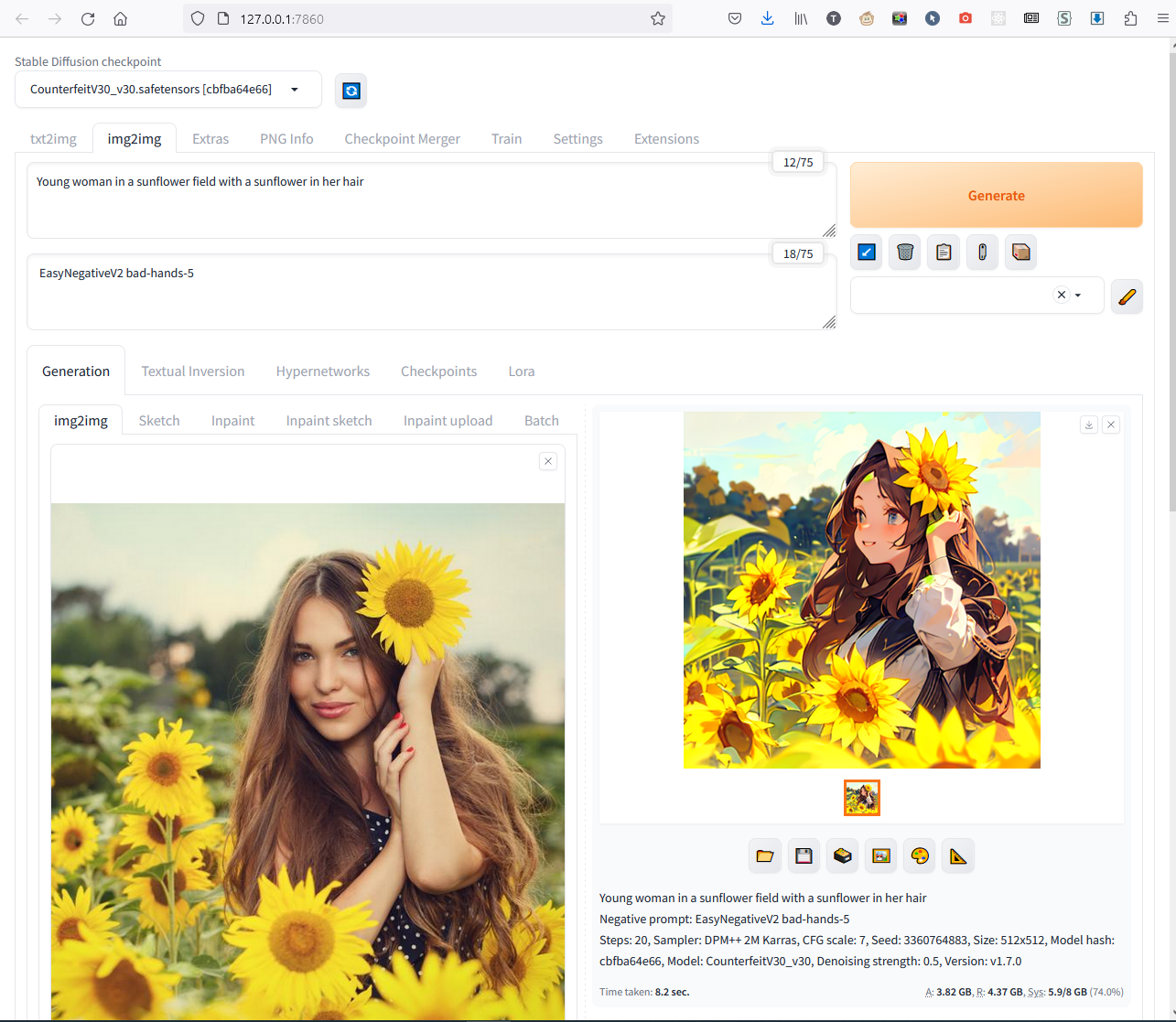
Чем меньше число, тем более похожим на исходное фото получится результат. Обычно значения около 0.5-0.6 дают лучший результат, здесь - 0.5:
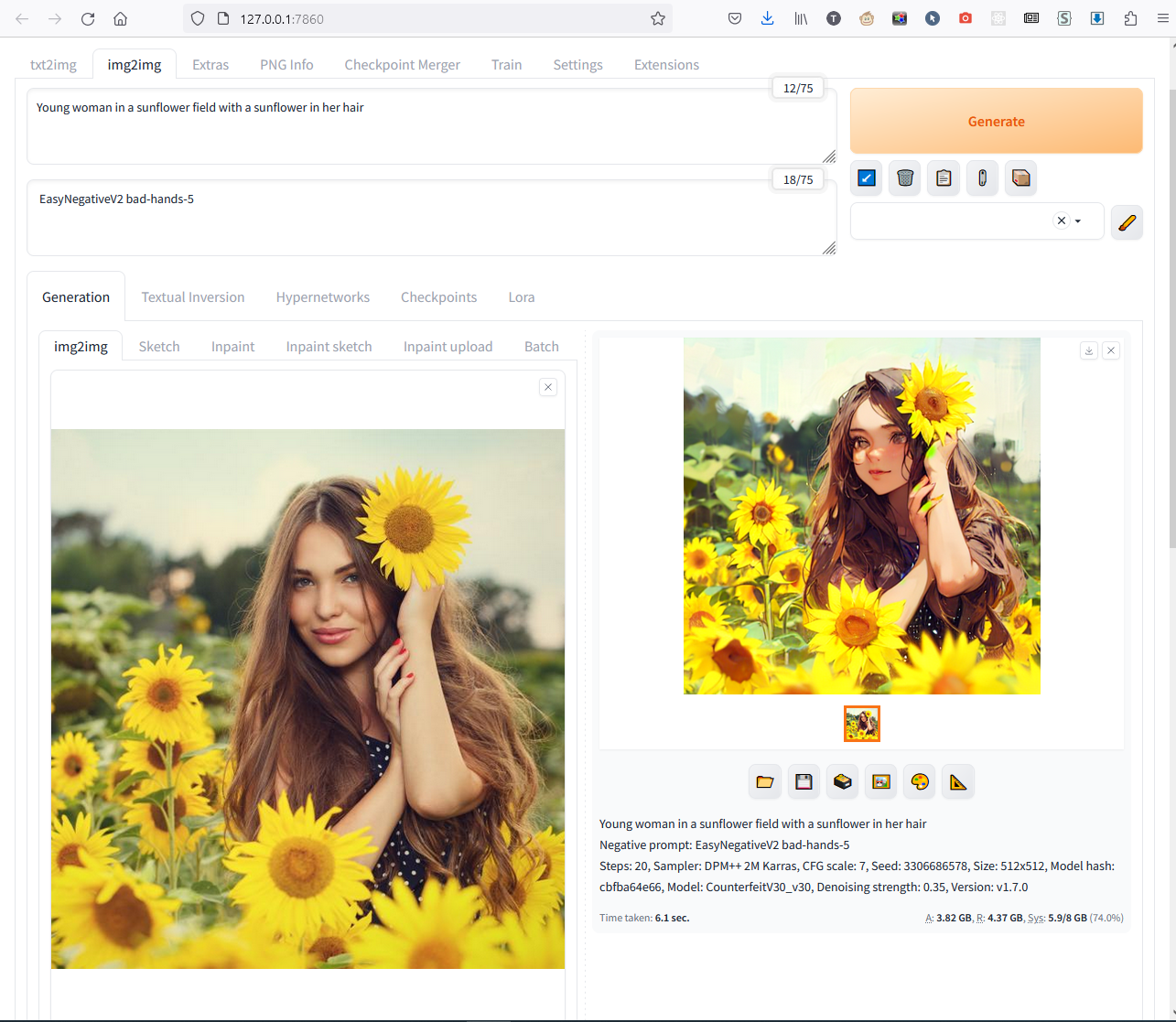
В методе img2img тоже можно пользоваться ControlNet, тогда из исходного фото возьмутся и очертания, и цвета. Он так же включается ниже в левой части и всё там такое же:
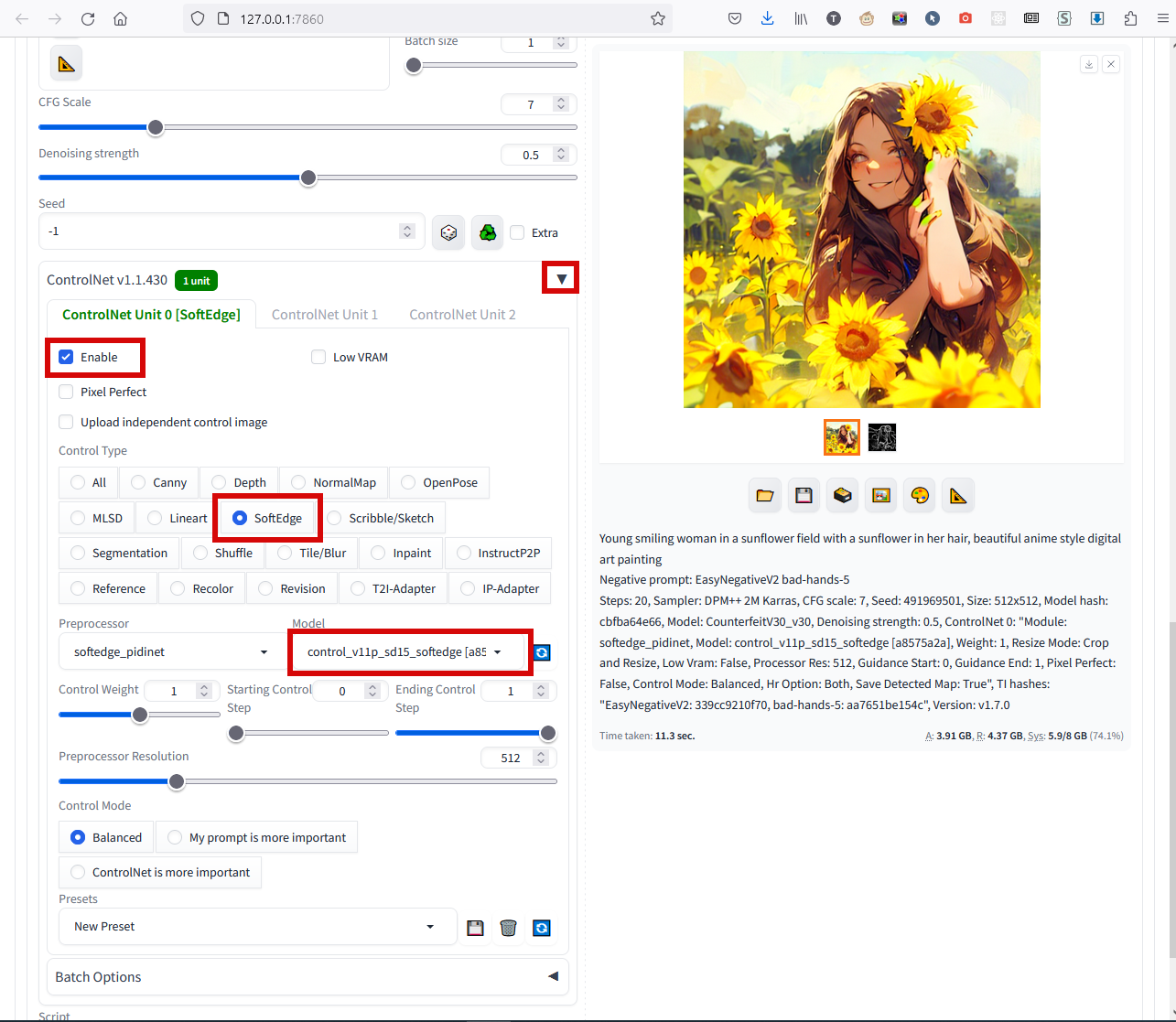
Комплексный подход img2img + ControlNet позволяет перегнать в стиль выбранной модели почти любую фотку, но обычно хватает и txt2img + ControlNet.