Роль процессора в программировании.

Сегодня мы с вами поговорим о файлах, кодировках, хекс редакторах, языках программирования, а также разберёмся более подробно как работает процессор.
Но перед тем как читать мою сегодняшнюю статью рекомендую ознакомиться с предыдущей, а то можете многое не понять.
Итак, начнём. Каждый файл это последовательность бит. Бит, в свою очередь, это ноль или единица. Любой текстовый файл, программа, музыка, фильмы, pdf, картинки последовательность нулей и единиц. Последовательность восьми бит называется байтом, а записывать байты удобно не как последовательность из восьми нулей и единиц, а в 16-теричной форме, как два символа. Например FF или AA. 16-теричная форма добавлена для удобства записи байтов.
Давайте разберёмся, правду ли я вам пишу, что любой файл это последовательность нулей и единиц? Как нам с вами в этом убедиться?
Для этого я воспользуюсь хекс редактором. Хекс редакторы - это программы с помощью которых можно открыть любой файл и посмотреть из каких нулей и единиц, битов и байтов, состоит файл.
Хекс редактор есть во всех популярных операционных системах.
Если мы говорим про Windows, то для него есть WinHex. В Linux и MacOS есть уже встроенный редактор под названием xxd.
Я буду показывать на примере Linux. Для начала я создам текстовый файл под название файлик и пропишу туда "My name is Alina", а далее проверю, что он создался:

Вот так вот это выглядит в графическом виде:


Для начала посмотрим данный файл в 16-теричной системе счисления:

А теперь в двоичной системе счисления:

Что же я прописала? Я обратилась к программе xxd, а далее я прописала -c 1. Данный аргумент выводит каждый байт в отдельной строчке, а аргумент -b означает вывод в байтах, далее я указала название самого файла.
Мы убедились на примере, что компьютер видит наш файл в виде нулей единиц.
Букву M он видит как 01001101.
Букву Y он видит как 01111001.
Каждый символ это действительно просто напросто последовательность нулей и единиц. Каждый байт у нас хранит 8 бит, в эти 8 байт помещается 1 символ.
Но что же это такое? Почему буква M это именно 01001101, буква Y это 00100000, а не другие значения? Всё, просто. Существует стандарт, он называется ASCII:

Данный стандарт в 16-теричной системе счисления.
Буква M у нас находится в колонке 4 сбоку и колонке D сверху:


А чтобы вы умели сходу видеть в 16-теричных числах двоиные, а в двоичных 16-теричные, то вам нужно выучить наизусть вот такую табличку. Я её вам прикрепляла в прошлом посте:

Получается, что 4d это 01001101.
А вот буква Y (01111001) записана в 16-теричной системе как 79:


Буква M в 16-теричной системе счисления у нас 4d, а буква Y это 79.
Погодите читать пост дальше. Вернитесь к табличке перевода выше и переведите эти 16-теричные числа 4d и 79 в двоичные самостоятельно. Можете куда-нибудь даже записать.
В двоичной системе, после вашего перевода по табличке получилось, что буква M это 01001101, а буква Y это 01111001.
Проверим верно ли это по тому результату, что показало выше в хекс редакторе:

Всё верно. Я создала текстовый файл, открыла его как последовательность нулей и единиц. Эти нули и единицы для удобства преобразованы в 16-теричную систему счисления, и действительно, каждому байту соответствует 1 символ. Вот так вот всё и работает.
Но если внимательно подумать, то возникают сомнения. Табличка какая-то маленькая, в ней русских символов нет. Что с этим делать и как компьютер может закодировать русские символы Ь, Й, Ъ, Ы или Ё? В таблице нет буквы Ё, а на клавиатуре написать букву Ё мы можем. Как так получается? На самом деле кодировка ASCII абсолютно базовая, в ней количество символов очень ограниченно, их там 256.
Понятно, что в такое небольшое количество символов невозможно вместить все возможные символы всех алфавитов которые есть в мире. Поэтому ASCII простейшая однобайтовая кодировка, то есть 1 байту соответствует 1 символ. Если же нам нужно что-то более сложное, то тогда нам, для того, чтобы сохранить 1 символ - 1 байта уже мало. В 1 байте мы физически не можем сохранить больше чем 255 значений (считать нужно с нуля, 0, 1, 2, 3, 4, 5....255). Соответственно, если нам нужно хранить другие символы, то мы можем хранить 1 символ в виде нескольких байт (двух, трёх, четырёх и так далее).
Одной, из наиболее распространённых многобайтовых кодировок, является кодировка UNICODE, в частности UTF-8. В ней одному символу может соответствовать не один, а несколько байт. Если мы говорим про современные компьютеры, то кодировка UNICODE является стандартом по умолчанию. Не нужно сейчас использовать никакую другую кодировку, кроме кодировки UTF-8. В кодировке UTF-8 есть даже символы эмоджи, которые многие из вас так сильно любят. У каждого символа эмоджи тоже есть свой определённый код в кодировке UTF-8, поэтому вы отправляете эмоджи в разных мессенджерах друг другу, но фактически там просто отправляется определённый UNICODE символ.
В предыдущем посте я объяснила вам как работают транзисторы в процессоре. Но сейчас объясню более подробно. Многим людям это неинтересно, потому что у них напрочь убили интерес к этому в школе, когда пытались объяснить что транзистор это полупроводниковое устройство, он имеет переходы p и n, через него протекает ток, у него есть коллектор, эмиттер ещё и заставляли разные формулы писать, решать задачи. В общем, делали это таким образом, что человек это возненавидел и уже не хотел разбираться.
Как я уже писала, в прошлом посте, транзистор нужен вам затем, чтобы вы могли передавать нолик и единичку компьютеру, тем самым управляя им.
Первые транзисторы выглядели примерно вот так. Наверняка вы видели что-то подобное если копались в очень старой электронике:

Как видите у них есть 3 ножки вывода. Каждый из этих выводов имеет своё название.
Транзистор в компьютере используется как электронный переключать. Он может включать и выключать ток.
Представьте транзистор в виде трубы с водой:

Вода может либо идти, либо нет. Я могу открыть вентиль и вода побежит по трубе, такая же аналогия с током который идёт через транзистор. Если сравнить эту трубу с транзистором, то вход это у нас коллектор (1 ножка) - откуда бежит вода, выход тока эмиттер (3 ножка) - куда вода бежит, а база это сам вентиль который управляет этим потоком воды, позволяя ей течь или нет (2 ножка). Подав управляющий сигнал на базу можно включить наш транзистор и из него потечёт ток (компьютер выведет единичку). Также его можно выключить (компьютер выведет нолик). Это самое простое объяснение работы транзистора которое я смогла для вас придумать.
В современных процессорах таких транзисторов миллиарды. Но как же на квадратик 2.5 см на 2.5 см можно поместить десятки миллиардов транзисторов? Как удалось добиться такого уменьшения?
Примерно так выглядит современный процессор изнутри если с него снять крышку:


А вот так выглядят современные транзисторы под микроскопом:

Здесь и располагаются миллиарды транзисторов, размер каждого из которых колеблется в пределах нескольких нанометров.
1 нанометр = 0.000000001 метра (одну миллиардная).
Каждый транзистор в современных процессорах состоит из нескольких атомов и вручную такое не собрать. С данной задачей справляются с помощью компьютерного проектирования. Представьте насколько сложна его структура.
Если задуматься, то что такое программа? Программа - это набор инструкций для компьютера. Какие инструкции мы компьютеру дадим, то ровно такие инструкции он и выполнит. При этом стоит понимать, что когда вы программируете, то вы как раз таки управляете током на данных транзисторах, даёте компьютеру инструкцию как ему печатать нули и единицы. Всё работает именно так. В предыдущем посте я приводила вам пример с лампочкой, у неё есть всего два состояния - ноль и один.
Поэтому какие мы можем дать инструкции лампочке? Либо включить её, либо выключить. Никаких других инструкций мы ей дать не можем. То есть, для того, чтобы написать программу - процессору нужно дать какие-либо инструкции в виде нулей и единиц.
Но если бы программисты писали свой код в нулях и единицах, то это было бы очень сложно. Для того, чтобы облегчить процесс программирования и много людей легко смогло им заниматься, придумали высокоуровневые языки программирования. Это языки, которые практически полностью похожи на человеческую речь. Так как мировым языком считается английским, то и команды в программировании также все на английском.
Как на языке программирования python нам написать программу в которой мы зададим вопросы человеку, а затем выведем ему ответы на экран? Я создам текстовый файл, это может сделать любой из вас:


Разберу для вас что я тут написала.
Я создала переменную под названием name. Переменная сохраняет в себе значение которое вы ему присваиваете. Далее я написала =, значок = в python означает присвоить, потом я написала команду input, что переводится с английского как "ввод", открыла скобочки и написала что именно я хочу, чтобы ввёл человек, который откроет мою программу:

После этого я написала команду print, что переводится с английского как "печатать", открыла скобочку и прописала f.
f означает f-string (форматированная строка). В скобочках я написала, чтобы программа ответила пользователю и вставила туда переменную name, которая примет значение имени пользователя, после его ответа в первой строке:

Далее я создала переменную age, ей будет присвоено значение, которое введёт пользователь. Ввести я его попросила возраст. int нужно добавлять, когда на ввод мы хотим принять целое число. int сокращённо от integer, оно так и переводится с английского "целое число":

После этого я написала if age больше, либо равно 18, то вывести пользователю ссылку на сайт. if переводится с английского как "если":

Если же пользователю меньше 18 лет, то вывести, что ему запрещено посещать данный сайт. Else переводится с английского как "иначе":

Давайте я теперь проверю как работает моя программа. После её запуска меня просит сразу же ввести моё имя:


Я ввела. После этого программа приветствует меня и просит ввести мой возраст:


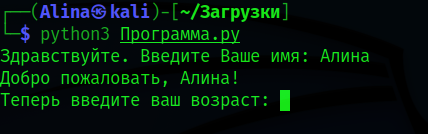
Я ввожу свой возраст и программа выдаёт мне ссылку на сайт:


Давайте теперь проверим, если бы мне было меньше 18 лет:


Как видите всё отлично работает. Теперь представьте, что на python можно было бы программировать на русском. Моя программа бы выглядела тогда вот так:

Или взять, к примеру, язык SQL. Это язык структурированных запросов, а если по простому, то язык для работы с базами данных.
Я написала такую "страшную" команду на данном языке:

Что же делает это команда? Эта команда из базы данных, из таблички users (пользователи), выбирает колонку phone (колонку с телефоном), а далее она выбирает эту колонку для той строчки, для которой email равен alinatwosouls@почта.com.
SELECT в переводе с английского означает "выбрать".
Если бы можно было написать это на русском, то выглядело бы это так:

Как видите ничего сложного в этом нет абсолютно. Тут не используются какие-то сложные высокопарно художественные английские слова.
Перед разработчиками современных языков программирования стоит задача сделать языки программирования максимально простыми для новичков, чтобы им писать код было легко и приятно. Чтобы тот код, который начинающие разработчики написали можно было легко модифицировать, поддерживать, обновлять в последствии, в том числе другим разработчикам.
В данный момент не нужно быть гением и языки программирования по типу python настолько лёгкие, что их может освоить даже 5-6 летний ребёнок.
Изначально программисты писали свои программы на языке ассемблер, он максимально приближен к машинному коду. Давайте теперь сравним python и ассемблер.
Я написала на языке ассемблер код, чтобы на экран выводилась строка "Hello World":

Теперь я написала тоже самое на языке python:

Вы наверняка меня спросите: "Зачем же сейчас изучать как работает компьютер изнутри и понимать ассемблер, если есть python и его аналоги?"
Язык ассемблера был создан в 1947 году и используется до сих пор. В рейтинге всех популярных языков, он находится примерно на дне, виной тому очередной стереотип людей которые зачем-то пытаются выявить плюсы и минусы по сравнению с языками более высокого уровня. В наше время писать программы на ассемблере, примерно как пытаться развести огонь трением деревянных палочек, но иногда сама окружающая среда заставляет нас прибегнуть к подобным действиям. В среде программирования такое иногда случается, когда без ассемблера программу просто не написать. Высокоуровневые языки не в состоянии решать задачи где необходим доступ к аппаратуре, размер программы суперкритичен, а скорость выполнения кода должна быть намного выше всех других языков. Это драйвера, компиляторы, операционные системы, многие компоненты вирусов и другие программы, которые так или иначе были написаны при участии языка ассемблера и которые пишутся теми людьми, которые не просто кодеры, а именно программисты.
Ограничения компиляторов в высокоуровневых языках не позволяют людям напрямую работать с памятью, использовать команды процессора, работать со стеком, а также они не позволяют посмотреть на программы без пелены абстракции и розовых очков. Большинство современных "программистов" не знают что они пишут и это главная проблема всех современных высокоуровневых языков программирования.
В далёкие времена, когда все писали код на ассемблере и не было альтернатив, то уже тогда было понятно что у этой модели нет будущего. Высокий порог входа означал огромную нехватку программистов, которых с каждым годом требовалось всё больше и это очень сильно тормозило весь прогресс.
Время как известно это деньги, поэтому процесс нужно было автоматизировать. Создали компиляторы, которые стали решать 90% всех низкоуровневых задач. Компиляторы породили языки высокого уровня, которые понизили порог входа и повысили скорость разработки в сотни раз. Изобретение гениальное.
Правда изначально подразумевалось, что люди которые будут их использовать, будут уже иметь при себе весь фундаментальный бэкграунд, знания об устройстве компьютера, команд процессора, ну и как минимум, будут понимать во что превращается их программа после компиляции. Процесс обучения с тех пор сильно изменился и в современном мире язык программирования, с которого начинается обучение среднестатистического программиста, как правило на нём и заканчивается. Высокоуровневые языки не дают понимания об устройстве самого творения программиста, и проблема тут не в самих языках, это важно понимать, проблема в подходе к обучению. В любой области есть базис на котором всё строится. Люди не придумали компьютер из воздуха, за этой разработкой стоят такие фундаментальные вещи как математика, физика, информатика, электротехника и так далее. Большинство людей не забираются так глубоко, весь их мир программирования ограничен абстракцией кода. Всё самое сложное, что можно было вырезать - вырезали, убрав 90%, тем самым повысив скорость "обучения" на эти же 90%. Я представляю это примерно вот так, в виде айсберга:

Всё что над водой это высокоуровневые языки программирования, всё что ниже язык ассемблера и знания об устройстве компьютера.
Язык ассемблера является набором инструкций в символическом виде. Берутся машинные инструкции программы и отображаются в виде слов, то есть, мы получаем программу на ассемблере. Примерно тоже самое происходит при дизассемблировании, думаю многие слышали такое слово. Изучать язык ассемблера сейчас означает - я хочу разобраться как работает мой код. Стремление людей понять как всё работает, это в принципе, единственный верный путь по которому нужно идти специалисту в любой области. Поэтому приводя какие-то минусы ассемблера по сравнению с другими языками - это тоже самое если сравнивать фундамент с домом, говоря что фундамент не нужен, потому что дом крутой.
Программы на языке ассемблера это программы без абстракций. Воспринимайте его как инструмент с помощью которого можно понять как работает компьютер. После изучения любого другого высокоуровневого языка здесь всё будет выглядеть немного странно. Всё к чему вы привыкли здесь не работает. Если раньше за вас всё делали компиляторы, а кнопка установить PyCharm или другую среду разработки была единственным сложным препятствием на пути перед написанием кода, то здесь по умолчанию нужно знать намного больше о процессе исполнения программ, начиная от её компиляции, заканчивая загрузкой в память. Нужно понимать из каких блоков она будет состоять, перед тем как бездумно кидаться её писать.
Попробую вам объяснить на примере. Не факт, что вы всё до конца поймёте, но я очень сильно постараюсь. Если вы не хотите напрягать мозги, то лучше закройте мой пост, потому что будет сложновато.
Повторюсь ещё раз, компьютер понимает как использовать программу только если она представлена в двоичном виде. Напишу код на языке ассемблер для архитектуры x86:

Данный код переведённый в машинный выглядит следующим образом:

Для первых компьютеров, когда ещё не было языков программирования, то все программы писались именно в таком виде, в виде нулей и единиц. Но это было крайне сложно и неудобно, поэтому было придумано значительное упрощение и язык ассемблера.
Чтобы это осознать поговорим про наборы символов. Как вы помните набор символов это таблица соответствий между символами и целыми числами.
Например, числу 01000001 по таблице ASCII соответствует символ A. Точно также, для каждой последовательности бит машинного кода существует соответствующая ему текстовая запись. Следовательно, зная эти соответствия, мы можем переписать двоичный машинный код в читаемый вид. Давайте я разобью машинный код, который у меня получился выше, по 8 бит, чтобы он был проще читаем:

А далее я разобью его по строкам:

И ещё раз покажу код который я написала для сравнения:

Первые 8 бит 10110010 идентичны фразе MOV DL. Следующие 8 бит 01100011 означают букву "c" в таблице ASCII:


Далее идёт фраза 10111000 - MOV EAX и 32 бита 10110000 00000001 00000000 00000000 - означают число 432:


Можете попробовать перевести данное двоичное число в десятичный вид, но если вы это сделаете, то удивитесь, ведь полученное вами число не будет равно 432. Почему это так я объясню ниже.
Далее идёт фраза 10111011 - MOV EBX, а ещё далее 00111011 00000010 00000000 00000000 - число 571:


Наконец, последние 16 бит 00000001 11011000 это фраза ADD EAX EBX:


Таким образом собрав все фразы вместе получим следующий код:



Пока не важно, что мой код делает, это я разберу позже. Но даже сейчас видно, что для человеческого мозга программа стала гораздо проще для восприятия. А теперь если к нашему коду дописать запятых, то мы получим язык ассемблера:

Прежде чем двигаться дальше разберу какие используются термины для описания написанного мной ассемблерного кода. Для этого рассмотрю первую строку:

MOV - это инструкция, то есть текстовое указание процессору выполнить заданное простейшее действие. Инструкция это самое минимальное действие которое программист может выполнить с компьютером. Процессор не может сделать ничего меньше чем инструкция. DL и "c" называют операнды, то есть входные данные инструкции. Ими могут выступать регистры, константы и адреса оперативной памяти. Я рассмотрела текстовый вид инструкции. Теперь перейду к её двоичному представлению:

Данное представление называется кодом инструкции. Иными словами, код инструкции это понятное процессору двоичное число, соответствующие инструкции с операндами, оно состоит из одного или более байт.
Чтобы в дальнейшем избежать путаницы объясню отличие инструкции от кода инструкции. Существует только одна инструкция MOV, но при этом у неё есть очень много кодов. Например, данная инструкция MOV DL, "c" имеет код 10110010 01100011. Если я захочу задать другую инструкцию, например, MOV AL, 5, то у неё уже будет другой код - 10110000 00000101. Компилятор знает все соответствия машинных кодов и инструкций, поэтому он умеет превращать язык ассемблера в машинный код.
Только что я переводила машинный код в язык ассемблера, а при компиляции всё происходит наоборот. То есть, у нас есть файл с программой понятной человеку, а при компиляции на выходе получается файл с программой понятной процессору.
Сначала мы пишем программу на языке ассемблера:

А произведя её компиляцию получаем файл с машинным кодом понятным процессору:

Теперь детально рассмотрю как мой код выполнится процессором.

MOV DL, "c" - я говорю процессору: "Помести в регистр DL букву c". Я использую регистр DL, так как его размер 8 бит, а буква "c" является ASCII буквой, то есть она помещается в 8 бит.
MOV EAX, 432 - "Помести в регистр EAX число 432". Здесь я использую регистр EAX, так как его размер 32 бита, а в коде я использую тип int, который также занимает 32 бита.
MOV EBX, 571 - "Помести в регистр EBX число 571". Здесь я использую регистр EBX, так как его размер, так как его размер 32 бита, а в коде я использую тип int.
ADD EAX, EBX - "Помести в регистр EAX сумму EAX + EBX".
CMP EAX, EBX - "Сравни значения в EAX и в EBX".
JNE 23 - "Если EAX не равно EBX, перейди по адресу 23". В данном случае 23 это адрес ячейки оперативной памяти с которой нужно начать выполнение кода если проверка вернёт истину. Почему адрес равен именно 23 объясню дальше.
MOV EBX, 7 - "Если выполнится условие выше, то в регистр EBX помести число 7."
MOV EBX, 9 - "Далее в регистр EBX помести число 9".
RET - говорю процессору, что программа завершена.
Я рассмотрела для вас каждую строку кода.
Теперь вернусь снова к первой части программы:

Посмотрите на самую первую инструкцию. В машинном коде она имеет следующее представление:

Если вы внимательно читали всё что я писала ранее, то поняли, что это 16 бит. А теперь вспомните, оперативная память имеет байтовую адресацию, поэтому машинный код любой инструкции кратен 1 байту, то есть 8 битам. Я сохранила букву "c" в регистр DL. Теперь давайте разберу как с ним работает процессор.
Машинный код попадает в процессор из оперативной памяти. Показываю на примере как этот код хранится в оперативной памяти:

Нулевая и первая ячейка теперь заняты, но при этом вы видите, что в памяти есть ещё пустые ячейки. В ячейках 2, 3, 4 и так далее, будет содержаться дальнейший код моей программы. Я объяснила вам то, что относится к самой первой инструкции.
Теперь давайте разберу более подробно.
Процессор читает из оперативной памяти за один раз одну ячейку, то есть 1 байт (8 бит). Сначала он прочитает нулевую ячейку, данная ячейка содержит инструкцию MOV DL. Имена регистров создаются при создании процессора, то есть они уникальны. Поэтому первый байт включает в себя инструкцию и указание процессору работать с регистром DL, при этом выполнение данного байта не имеет отношение к записи каких-либо данных в процессор, код просто указывает процессору в какое состояние перейти и процессор перещёлкивает свои транзисторы. Также по этому байту процессор понимает, сколько ещё байт необходимо прочитать, чтобы завершить инструкцию.
Теперь поговорим про имя инструкции MOV, это сокращённо от английского Move (двигать). Данная инструкция выполняет запись значения. Я показала вам всё, что нужно знать о нулевом байте кода программы. Теперь давайте соберём всё вместе. Прочитав значение 1011 0010, процессор понимает, что необходимо перейти в состояние для записи значения в регистр DL, а далее взять из оперативной памяти следующий 1 байт и записать его в регистр DL. Далее процессор переходит к следующей ячейке:


И теперь процессор должен записать этот байт в регистр DL, то есть ASCII букву "c". Таким образом процессор запишет 8 бит в регистр DL. С первой инструкцией разобрались.
Теперь посмотрим на вторую инструкцию:


В машинном коде она занимает 5 байт. Он начинает храниться со второго адреса. Код нашей программы хранится в оперативной памяти последовательно. Теперь посмотрим на ячейку с адресом 2. Она содержит код инструкции MOV EAX:

Прочитав значение 1011 1000, процессор понимает, что необходимо перейти в состояние для записи значения в регистр EAX, далее взять из оперативной памяти следующие 4 байта и записать их в регистр EAX. Вот эти:

Процессор должен записать в регистр EAX эти данные, то есть число 432. Для этого процессору необходимо загрузить 4 байта, то есть 32 бита в регистр размером 32 бита. Из-за байтовой адресации, за один раз можно читать только 1 ячейку памяти, то есть 8 бит. Следовательно процессору необходимо выполнить 4 чтения, чтобы заполнить регистр на 32 бита. Но тут опять же не всё так просто. Я записала в инструкцию число 432, но в оперативной памяти будет хранится 10110000 00000001 00000000 00000000. Так числа хранятся в дополнительном коде, то выполнив перевод из двоичной систему в десятичную, мы получим вот такое десятичное число "-1342111744". Исходя из инструкции, в регистр должно быть записано число 432, но оперативная память почему-то хранит другое. Казалось бы всё неверно. Но давайте теперь прочитаем это в обратном порядке:

Теперь после перевода из двоичной системы в десятичную мы получим 432. Можете проверить сами на калькуляторе:
00000000000000000000000110110000
https://programforyou.ru/calculators/number-systems
Почему же так происходит? Об этом напишу чуть позже. Сейчас продолжу разбор кода. Чтобы процессор мог правильно работать с числами, то байты записываются в регистр в обратном порядке.
Продолжу разбор кода и перейду к следующей инструкции:

И снова начну с того, что изображу хранение кода в оперативной памяти:

Посмотрим на ячейку с адресом 7. Она содержит код инструкции MOV EBX. Прочитав значение 10111011 процессор понимает, что необходимо перейти в состояние для записи значения в регистр EBX, затем взять из оперативной памяти следующие 4 байта и записать их в регистр EBX.

Процессор должен записать в регистр EBX эти данные, то есть число 571. И как я сказала уже ранее, байты записываются в регистр в обратном памяти порядке, мысленно переверните их.
Мы разобрались с третьей инструкцией. Перейдём к следующей:

Посмотрим на ячейку с адресом 12. Она содержит часть кода инструкции:

Это инструкция сложения. Прочитав значение из 0000 0001, процессор понимает, что необходимо прочитать ещё один байт, чтобы вычитать весь код инструкции. Поэтому процессор переходит к следующей ячейке:

В ней он читает окончание кода инструкции. Прочитав значение 1101 1000, процессор понимает, что необходимо перейти в состояние сложения значений EAX и EBX, а далее записать в регистр EAX сумму EAX и EBX. Тогда выполнив сложение, процессор получит следующее. Он возьмёт значение в регистре EAX:

И прибавит к нему значение регистра EBX:

В результате полученная сумма запишется в регистр EAX.
С последовательностью выполнения кода разобрались.
Переходим ко второй части кода:


Данная инструкция имеет следующий машинный код:

Но прежде чем разбирать данный машинный код, рассмотрю что такое сравнение чисел. Для выполнения сравнения достаточно вычесть числа и посмотреть на результат. Поясню, если результат вычитания двух чисел ноль, то это значит что числа равны. Если результат не ноль, то числа не равны. Если старший бит ноль, то число EAX больше, если же в результате вычитания мы получим, что старший бит будет единицей, то в этом случае число EAX меньше. Зная всё это вернусь к коду. Данная ячейка это часть кода инструкции CMP EAX, EBX:

CMP расшифровывается как Compare, что означает "сравнить значения". Так как первый байт это только часть кода инструкции, то прочитав значение 0011 1001, процессор понимает, что необходимо прочитать ещё один байт, чтобы вычитать весь код инструкции. Поэтому процессор переходит к следующей ячейке:

В ней он читает окончание кода инструкции CMP EAX, EBX. Прочитав значение 1101 1000, процессор переходит в состояние вычитания и затем вычитает из значения в EAX значение в EBX. То есть, по сути сравнение чисел это их вычитание, при этом процессору нужно знать что он получил в результате вычитания, а для этого ему необходимо где-то внутри себя хранить результат разности. Поэтому для хранения промежуточных состояний в процессоре есть регистр FLAGS на 64 бита. При этом для работы сравнения не требуются все биты данного регистра. Если вычитание не равно нулю, то в бит с индексом 6 старшим битом запишется ноль. Глядя на числа которые я написала в коде, можно понять что они не равны нулю, поэтому так и произойдёт.
То есть, инструкция сравнения CMP просто вычитает числа и в зависимости от результата записывает различные биты в регистр FLAGS, в частности равна ли разность нулю. На этом с данной инструкцией всё. Перехожу к следующей:

Из неё сразу видно, что она занимает два байта. Вот так будет выглядеть хранение кода в оперативной памяти:

Давайте рассмотрим ячейку под номером 16:

Она содержит код инструкции JNE, что является сокращением от фразы Jump if Not Equal. То есть, перейти по адресу, если сравниваемые значения не равны. Таким образом прочитав значение 0111 0101, процессор проверяет результат сравнения. В ячейку номер 6, первый бит у нас записался как 0, то есть числа не равны, поэтому процессор читает следующий байт из оперативной памяти:

Если перевести данное двоичное число в десятичный вид, то получим число 5. Но если посмотреть сюда, то у меня тут записано число 23:

Давайте разберёмся зачем я это сделала. Прочитав значение 0000 0101 процессор понимает, что ему необходимо пропустить 5 ячеек, перейти в адрес 23 и с него продолжить выполнение кода. То есть, сейчас процессор смотрит на ячейку 17, пропустив 5 ячеек он тем самым окажется в ячейке 23. С этой инструкцией разобрались.
Идём дальше. Следующая инструкция:

Теперь покажу хранение данного кода в оперативной памяти:

Как видите данный код хранится с 18 по 22 ячейку, следовательно мы не попадём в них следуя из условия, так как процессор должен перейти по адресу 23.
Перейду к следующей инструкции:


Мы перешли к ячейке 23. Но прежде чем разбирать исполнения кода в ней вспомните, что я прописала:

Если код выполнится, то наша программа перейдёт на 23 ячейку.
И последняя строчка нашей программы:

RET сокращение от слова RETURN, данная инструкция означает завершение программы. То есть, прочитав значение 1100 0011, процессор понимает, что программа выполнена и завершает её.