Язык ассемблера.

В последнее время мне всё чаще начали задавать вопрос: "Как изучать язык ассемблера и нужно ли это вообще?"
Для того, чтобы дать ответ на этот вопрос самим себе, нужно прежде всего ответить вот на такой вопрос: "Изучать язык ассемблера чтобы что? Для чего?"
Язык ассемблера появился ещё 1947 году и используется до сих пор. Но в последнее время он незаслуженно находится в тени языков, причём обусловлено это глобальной коммерциализацией, направленной на то, чтобы в максимально короткие сроки получить как можно большую прибыль от своего продукта. Массовость и ширпотреб взяли верх над элитарностью, а язык ассемблера это элитное искусство. Гораздо выгоднее в относительно небольшие сроки ничего не смыслящего в программировании человека поднатаскать в таких языках как например python, java, javascript, php и так далее. И этот новичок будет способен более-менее создавать программы для работодателя не задаваясь такими сложными вопросами, а зачем и почему он это делает. Так намного легче, чем нанимать действительно самых лучших профессионалов по ассемблеру за большие деньги. Примером тому служит обширнейший рынок всевозможных курсов по программированию на любом языке, за исключения языка ассемблера.
Язык ассемблера это очень низкоуровневый язык программирования. Чтобы вы понимали, уровень здесь не означает "хороший" или "плохой", или чем выше уровень, тем лучше. Деление языков программирования на низкоуровневые и высокоуровневые подразумевают то, насколько прямо и непосредственно вы можете взаимодействовать с аппаратной частью того компьютера, на котором будет запускаться разработанная вами программа. Чем более низкоуровневый язык программирования, то тем ближе он к машинному кому, тем ближе вы должны взаимодействовать с железом. И язык ассемблера это ОЧЕНЬ низкоуровневый язык программирования. Вам буквально для того, чтобы выполнить что-либо, на каждом шагу нужно будет говорить процессору: "Перейди по такому-то адресу в памяти, возьми такие-то данные, перейди туда, возьми то, сделай это."

В данном случае будет более уместно и понятно, если я просто вам покажу.
Создам, с помощью текстового редактора nano, обычный текстовый файл под названием пример.py и создам программу, которая будет выводить на экран hello, world на языке программирования python. То есть, я буквально пишу print (переводится с английского "печатать"), а далее в скобках указываю, что мне нужно напечатать. Печатай hello, world:

Сохраню свой код и запущу в терминале:

Как видим всё успешно выполнилось.
Теперь создам файл под названием пример.asm и напишу аналогичную программу на языке ассемблера:


Следующим шагом я линкую получившийся object файл в файл запуска:


Как видим программа выполнилась.
Теперь, когда мы с вами хоть немного взглянули на ассемблерный код, давайте вернёмся с вами к вопросу, который я озвучила ранее: "Изучать ассемблер, чтобы что? Для чего?"
Сразу скажу, то, о чём я вам буду рассказывать, не знает 99% современных кодеров работающих в легальных компаниях официально, оно им просто не нужно, у них нет задач спускаться так глубоко в железо, они сидят пишут приложения и сайтики, чтобы получить свою зарплату. Современные высокоуровневые языки программирования изучить в десятки раз легче и быстрее, чем язык ассемблера.
Но эта тема на мой взгляд очень важна если вы хотите стать топовым iT'шником. Причём не важно на каком языке вы собираете писать C++, C#, Java, JavaScript, Python и так далее. Язык ассемблера даст вам понимание того, как устроен компьютер, как работает процессор, как он выполняет ваши программы, что процессор может, а чего не может. Вы разберётесь в таких важных темах как кэши, конвейры, ядра, регистры, машинные команды, что такое байты, биты, логические операции, производительность.
Если вы хотите стать крутым хакером, то вам очень часто придётся читать код на ассемблере и если вы будете понимать, что всё это значит, то вы получите мощный инструмент в вашей работе, который позволит вам решать сложные задачи, с которыми не справится большинство.

Изучив язык ассемблера вы сможете создавать более эффективные алгоритмы, они будут быстрее и смогут занимать меньше памяти. Вы сможете читать машинные коды, это поможет вам понять, что происходит не только в вашей программе, даже если она написана на каком-либо высокоуровневом языке, но и в той, для которой у вас нет исходников, то есть сторонние библиотеки и даже коды операционных систем. Знания языка ассемблера и понимание механизма современных процессоров это уже не среднестатистический навык, а профессиональный. Это поможет вам решать более сложные задачи.
Из всех ITшников, язык ассемблера знают 2-3 человека из 100, а остальные смотрят на таких людей, как на крутых экспертов.
Для начала расскажу немного теории.
Насколько я знаю, не все понимают, что такое биты и байты, даже умея кодить на высокоуровневых языках программирования. Это нормально, но только вначале пути. Поэтому те, кто из вас это уже знает - потерпите, а для остальных я начну с самого начала, для того, чтобы синхронизировать понимание основ. Я быстро пройдусь по основным темам.
Для начала вы должны понять, что такое двоичный код. Все электронные устройства вокруг вас работают на двоичном коде. Например, когда вы говорите по телефону, то телефон превращает 1 ваше слово примерно в 50 000 двоичных сигналов. А телевизор, чтобы показать вам что-то, принимает и преобразует миллионы таких сигналов в секунду. Фотографии и картинки из интернета, переписка с кем-то, музыка, всё это хранится в виде последовательности двоичных сигналов. Возможных вариантов таких сигналов всего 2. Если сигнал есть - это 1, если сигнала нет - это 0. То есть включено - это 1, выключено - это 0. Всё вокруг вас пронизано этими сигналами. Нолики и единички во всех электронных устройствах вокруг вас, такая незаметная вашему глазу параллельная цифровая реальность. Давайте теперь разберёмся, как информация из нашей человеческой реальности попадает в реальность компьютерную.

Для примера возьмём число 13. Давайте разберёмся каким образом число 13 превращается в последовательность из нулей и единиц, в число 1101.
Вспомним как устроены десятичные числа. Давайте считать от 1 до 13:
На 10 у нас возникает проблема, так как отдельной цифры для обозначения числа 10 у нас, в десятичной системе счисления нет. Для того, чтобы как-то с этим справиться были придуманы разряды. Число 10 состоит уже из 2 цифр. Одна из этих цифр стоит в разряде единиц (0), а вторая в разряде десятков (1). Получается, что у нас 1 десяток и 0 единиц. Число 11 это 1 десяток и 1 единица, а число 13 это 1 десяток и 3 единицы. Если мы будем считать дальше, например до 123, то это будет 1 сотня, 2 десятка, 3 единицы. Обратите внимание, что каждый следующий разряд в 10 раз больше предыдущего. В 1 десятке 10 единиц, а в 1 сотне 10 десятков. Это отлично работает, потому что у нас, в десятичной системе, есть 10 цифр. Но у компьютера, в двоичной системе, всего лишь 2 цифры, 0 и 1.
Если мы начнём считать в двоичной системе, то проблема возникает сразу же, потому что 1 это последняя цифра, которая есть у компьютера. Чтобы считать дальше нам понадобится следующий разряд и это будет разряд двоек. Добавляем в этот разряд единичку, а разряд единиц сбрасываем до нуля.
Следовательно если мы хотим написать 3, то это будет в двоичной системе 11. Дальше идёт число 4, и опять у нас кончились цифры, значит нужно добавить ещё 1 разряд.

Чтобы лучше прочувствовать как это работает посчитайте до 20 самостоятельно.
Теперь вы понимаете то, как электронные приборы представляют числа и как десятичные числа выглядят в них. Но как же числа помогают хранить тексты, изображения и так далее? Внутри процессора каждого современного компьютера миллионы маленьких переключателей, которые называются транзисторами. Каждый такой переключатель хранит один бит информации. Если переключатель включен, значит значение бита равно 1, если выключен, то 0. Эти переключатели объединены в группы по 8 штук, группа из 8 бит называется байтом. Байт это минимальный набор данных, то есть как бы неделимый кусок информации. Даже если нам нужно хранить совсем маленькое число, например 1, то компьютер задействует для этого 8 переключателей, то есть 1 байт и это будет выглядеть следующим образом:
В одном байте можно хранить число от 0 до 255, это легко проверить если перевести последовательно из 8 единиц в десятичную систему:
128 + 64 + 32 + 16+ 8 + 4 + 2 + 1 = 255
И если с числами всё более понятно, то как компьютер понимает, что например буква A это именно буква A? Для этого были придуманы системы обозначений символов и названы системами кодировок. Вот одна из таких таблиц:

В таких таблицах каждой букве, цифре и специальному знаку был присвоен уникальный номер - код символа. Теперь все компьютеры мира знают, что буква A это 65, буква B это 66, а буква C это 67. Есть A, B, C это последовательность чисел 65, 66, 67. А так, как компьютеры понимают только нули и единицы, то буквы A, B, C будут выглядеть для них как двоичный код, то есть как включенные и выключенные переключатели:
А что же насчёт картинок? Как именно компьютер заставляет появляться их на экране? Всё, что вы видите на экране компьютера состоит из маленьких точек. Эти точки называются пикселями. Каждый пиксель состоит из трёх маленьких лампочек:

То есть, каждый пиксель это 3 лампочки: красная, зелёная и синяя.
Каждая из этих лампочек может гореть с разной яркостью. Например, если горит только синяя лампочка с максимальной яркостью, то мы видим синюю точку, и чем меньше яркость синей лампочки, то тем темнее будет синий цвет. Если будут гореть красная и зелёная лампочка, то мы будем видеть жёлтый пиксель, а если будут гореть все 3 лампочки с максимальной яркостью, то белый. Так получается из-за особенности нашего зрения. А компьютер просто регулирует яркости свечения трёх лампочек для каждого пикселя.
Есть много моделей задания цвета числами, но самой популярной является модель RGB. В модели RGB каждый цвет задаётся от 0 до 255. То есть ноль - этого цвета нет, а 255 - это максимальное значение конкретного цвета. Если нам нужен красный цвет, то это 255 в красном канале и по нулям в других каналах. Если нам нужен чёрный цвет, то это по нулям во всех трёх каналах, ведь чёрный цвет это отсутствие любых цветов. Белый цвет противоположность чёрному, соответственно 255 во всех трёх каналах. То есть, 255 в красном канале, 255 в зелёном и 255 в синем. По максимум берём всех цветов и получаем белый цвет.
Для примера возьму синюю лампочку:

Значение яркости одной лампочки помещает в 1 байт, а всего для одного пикселя нужно 3 байта, по одному на каждую из лампочек. Всё, что изображено на мониторе, картинки и текст, одновременно присутствует в памяти компьютера. Для того, чтобы картинка появилась на мониторе, она должна быть записана в памяти. То есть, для того, чтобы вы увидели фотографию, внутри компьютера должны включиться и выключиться миллионы переключателей. В это же время на мониторе зажгутся миллионы лампочек с разной яркостью. И всё это ради одной фотографии.
Теперь немного о том, что такое программа. Программа это последовательность команд, которые вы даёте компьютеру. Например программа для рисования могла бы выглядеть так:
Включить переключатель под номером 1001.
Включить переключатель под номером 1002.
Включить переключатель под номером 1003.
Выключить переключатель под номером 1004.
И так 24 раза только для одной точки - пикселя.
А в одной картинке этих точек тысячи. Чтобы написать такую программу нужно много сил и времени. Нужно будет включить десятки тысяч переключателей так, чтобы получился код. Чтобы писать программы было легче, придумали такую штуку как уровни абстракций. Это значит, что есть программы которые делают простые вещи. Например, выводят точку на экран или двигают курсор мыши. Другие программы используют эти простые программы, чтобы делать что-то посложнее, например, рисуют линии используя программу для рисования точек.
Программу, которая рисует линии, использует другая программа, которая из линий может нарисовать окна и кнопки. Таких вспомогательных программ уже очень много и счёт им идёт на миллионы.

Главная программа компьютера это операционная система, она превращает включенные и выключенные переключатели в другие программы. Компьютер без операционной системы это просто коробка с микросхемами. Любая же программа это просто текст на языке программирования записанный в файл. Этот текст называется исходным кодом программы. Чтобы заработать, программа из исходного кода должна быть переведена в нули и единицы, то есть в машинный код. Есть 2 вида программ, которые это делают. Это компиляторы и интерпретаторы. По принципу работы они сильно различаются. Компилятор читает исходный код, то есть текст на языке программирования целиком, делает его перевод и создаёт законченный вариант программы на машинном языке, который затем и выполняется. Язык ассемблера является именно компилируемым. После того как программа откомпилирована, компилятор и исходный код больше не нужны и программа может выполняться самостоятельно. Интерпретатор же переводит и выполняет программу строка за строкой. Исходный код программы обрабатываемый интерпретатором должен заново переводиться на машинный язык при каждом запуске программы.
Нужно ли это всё понимать? Я считаю, что да. Ведь всё, что вы видите вокруг из электронных приборов в какой-то мере результат программирования. Космические корабли, автомобили, светофоры и другие электронные устройства. Везде в основе есть строки кода. Даже если вы не собираетесь заниматься программированием профессионально, то вы должны хотя бы в общих чертах представлять как устроен современный мир. Зная всё это, вы сможете видеть то, чего раньше не замечали.
Бит это единица измерения информация. Это её минимальный кусочек, что так и переводится с английского языка, где этот термин и был введён. Бит может иметь всего 2 состояния: 0 или 1, A или B, красный или синий. То есть, от нас зависит как мы интерпретируем эти значения. Возможность описать битом 2 значения это конечно же здорово, но что если нам нужно 3 значения? В таком случае мы можем использовать комбинацию из двух битов и такая комбинация называется битовое поле:

Теперь мы можем использовать для значений комбинации всех возможных в этих двух битах вариантов: 00, 01, 11, 10:

И хотя мне нужно было всего 3 значения, но я получила 4. Теперь от меня зависит, буду я использовать весь диапазон этих значения или только то, что мне нужно. Если же я возьму битовое поле из 3 битов:

То у меня уже будет 8 возможных комбинаций:

Я думаю вы уже заметили некую закономерность, увеличивая размер поля на 1 бит - мы увеличиваем количество возможных значений в 2 раза. Например, для битового поля состоящего из 4 бит:

Мы получим 16 возможных значений:

Здесь возникает прямая аналогия с обычными десятичными числами. 1 разряд позволяет нам представить 10 чисел от 0 до 9, а 2 разряда в 10 раз больше, от 0 до 99.
И всё же, зачем нужны были биты? Неужели нельзя было просто обойтись десятичными числами? В принципе можно, но это было бы сложно. Инженерам электронщикам тогда нужно было бы сделать электронную схему, которая могла бы обработать такие числа, и использовать их не только для вычислений, но и для логики, например, условий, циклов, вызовов процедур и других операций. Простой же бит, с его двумя значениями, можно представить простыми состояниями. Есть сигнал, нет сигнала, есть заряд, нет заряда, плюс, минус, высокое напряжение, низкое напряжение. Используя такие простые состояние можно построить логическую схему, которая и будет реализовывать различные алгоритмы. Именно поэтому вам нужно разбираться в битах, байтах и двоичной логике. Оперировать просто битовыми полями разного размера неудобно, поэтому их сгруппировали в байты. Байт - это битовое поле из 8 битов:

Байт имеет 256 различных значений. Байт - это число. Это число может иметь разные смыслы, то есть значение байта зависит от интерпретации. Например, если интерпретировать байт как натуральное число, то есть, целое, неотрицательное число, то мы сможем одним байтом представить десятичные числа в диапазоне от 0 до 255, всего 256. И такой же точно байт можно использовать, чтобы представить не только положительное, но и отрицательное значение. И было бы удобно выбрать такой диапазон, чтобы можно было представить одинаковое количество как отрицательных, так и положительных чисел. Если 256 поделить на 2, то будет 128. Удобно было бы представить значение от -128 до 128, но нужно ещё одно для нуля. Вместе же с нулям мы получаем 128 * 2 + 1 = 257, что уже нельзя представить одним байтом. В итоге пришлось забрать одно лишнее значение из положительного диапазона. И для целых значений байта у нас получается диапазон от -128 до 127. Немного ассиметрично, но иначе нельзя представить нечётное количество значений в байте. С другой стороны у нас получается 128 значений со знаком минус и ещё столько же без, а также байт можно интерпретировать не только как число, но и как номер чего-либо.
Все символы, которые вы можете использовать в компьютере, пронумерованы и представлены в виде таблицы, где каждому символу соответствует какой-то номер. Разумеется, что символы бывают разные, в разных алфавитах, причём есть ещё и знаки препинания, иероглифы и даже смайлики, поэтому таблиц с такими символами существует тоже великое множество.
Очень советую посмотреть этот очень интересный ролик для большего понимания, в нём очень хорошо всё объяснено.
Современный компьютер это самое сложное устройство, с которым вы можете взаимодействовать. Компьютер состоит из нескольких устройств, каждое из которых само по себе тоже является отдельным компьютером:

Даже компьютерная мышь содержит внутри себя плату с компьютером вычисляемым смещение поверхности. Когда мы говорим о компьютере, то мы подразумеваем так называемый системный блок, который состоит из модулей: процессор, оперативная память, материнская плата, блок питания, видеокарта, винчестер. И каждый из этих компонентов тоже является компьютером. И из всех этих модулей самым главным является процессор. Именно он выполняет программы. Например, если нашей программе нужно вывести на экран букву, то тогда центральный процессор отправит набор данных и команд другому процессору находящемуся внутри видеокарты, она сформирует изображение и отправит сигнал другому устройству, монитору. Монитор же управляется своим собственным процессором и программами для того, чтобы это в конце концов появилось на экране. Это очень сложный процесс, который совершенствовался десятки лет. И к счастью, нам не нужно детально указывать компьютеру, какой набор задач нужно выполнить чтобы вывести символы на экран. Нам достаточно сделать некоторые минимальные действия, а дальше, вся эта сложная система сама сделает остальную работу выполняя свои программы написанные до нас другими программистами.
Язык ассемблер это язык машинных команд, он предназначен только для действий выполняемых процессором. То есть, на ассемблере нельзя напечатать страницу текста на принтере, потому что принтер находится за пределами системного блока, это вообще другое устройство. Также на ассемблере нельзя вывести звук, потому что вывод звука производит другое устройство - звуковая карта со своим собственным процессором и программами. На ассемблере вы не сможете записать файл на жёсткий диск, потому что это тоже отдельный компьютер со своими программами. Вы также не сможете вывести на экран пиксель, потому что этим занимаются другие устройства.
Процессор может выполнять машинные команды, которые позволяют ему оперировать числами внутри небольшого количества ячеек памяти, которые называются регистрами. И этими машинными командами процессор и выполняет различные алгоритмы.

Для взаимодействия же со всеми устройствами, которые находятся рядом, процессор использует в основном 3 модуля:
- Контроллер прерываний. Он позволяет обратиться к конкретному устройству, передать ему информацию и получить её.
- Системная шина. Условно говоря кабель, по нему процессор может отправлять и принимать данные.
- Оперативная память. Она позволяет хранить данные, передаваемые через системную шину.
Я написала вам немного упрощённую схему, но в принципе это всё, что доступно процессору. Программа это последовательно машинных команд, которые выполняет процессор производя различные математические и логические операции над числами. То есть, программа - это всегда обработка чисел. Процессор не может, например, вывести картинку на экран в принципе. Зато он может считать массив чисел описывающие пиксели этой картинки из одной области памяти и записать в другую область (оперативную), которая используется видеокартой как массив пикселей. В результат мы увидим эту картинку на экране монитора. Точно также для процессора не существует текста. Он просто обрабатывает последовательности чисел, каждое из которых соответствует определённой букве в таблице символов.
Таким образом, процессор - это обработчик чисел, и только человек придаёт этим числам смысл. Текст, звук, картинка, 3D модель, либо что-то другое. Нужно ли это понимать? Да. Именно тогда, когда вы пытаетесь описать сущности и процессы числами, начинается настоящее программирование. Вы конечно же можете не говорить о числах рассуждая о сущностях, классах, паттернах, потоках и описывать это словами, но такой процесс обычно называется проектированием программ. А когда вы начнёте реализовывать алгоритмы и описывать сущности, то вам придётся это сделать в виде операций над числами.
Теперь кратко поговорим про память. Я заметила, что большинство людей используют термин "память компьютера" не подразумевая, что у этого термина есть несколько совершенно разных трактовок. И если для обычного кодера это вполне нормально, то для настоящего программиста, разбирающегося в языке ассемблера, это недопустимо.
Память в компьютере - это всегда его оперативная память. Это такие микросхемы, которые сами по себе тоже являются отдельными компьютерами со своими чипами и программами:

Именно в оперативной памяти хранятся все данные и программы, которые доступны процессору. Данные также могут быть записаны на жёсткий диск или флешку. Но это - не память! Это устройства хранения данных. Память принципиально отличается от устройства хранения данных тем, что она содержит в себе данные только пока к ней подключено электропитание. Как только вы выключили компьютер, то вся информация из памяти исчезает. Мало того, даже когда компьютер включён, информация в памяти не может храниться долго, всего несколько миллисекунд, то есть тысячных долей секунды. Из-за этого оперативная память несколько десятков раз в секунду полностью перезаписывается заново. Это называется регенерация памяти.
Кроме оперативной памяти в современном компьютере есть ещё один тип памяти под названием кэш (Cache). Это сверхбыстрая память, которую не нужно обновлять, так как она сделана немного по другому принципу, но она обходится значительно дороже, чем оперативная память. Поэтому в современном компьютере её мало. Кэш применяется для хранения копии данных из оперативной памяти. Например, если процессору нужно считывать один за другим символы из строки, то если обращаться за каждым байтом отдельно в оперативную память, процессору придётся довольно долго ждать пока будет считано запрошенное значение и такой алгоритм будет работать долго. Но если компьютер запишет в кэш копию данных из оперативной памяти, и будет считывать данные из кэша, то процесс пойдёт в разы быстрее.
Кроме того, в современных процессорах есть встроенный кэш, ещё более быстрая память. Получается как бы кэш кэша. Это позволяет ускорить работу алгоритмов ещё в несколько раз. Но при неумелом подходе и не понимая как эти кэши работают с памятью процессора, при написании программ вы можете легко свести на нет всю эту оптимизацию.

Теперь поговорим о регистрах. Регистр - это ячейка памяти внутри процессора, это самый быстрый вид памяти. Машинные команды, то есть команды процессора, предназначены в основном для работы с регистрами, хотя многие команды могут также работать и с оперативной памятью. Большинство алгоритмов строится по одному принципу, сначала мы загружаем в регистры данные из оперативной памяти, потом мы выполняем с этими данными нужные операции, а в конце сохраняем результат обратно в память. Разумеется, есть множество алгоритмов, в которых мы только загружаем данные и не сохраняем, или наоборот, или даже вообще не используем регистры. Но в 80% случаев нам нужны регистры для временного размещения данных. Регистров очень мало, их настолько мало, что у этих ячеек памяти есть свои собственные имена. Например, EAX, EBX, ECX и так далее. Их не хватит для хранения массивов данных. Их едва хватает даже для простых алгоритмов, а главная проблема для всех алгоритмов постараться выкрутиться и обойтись небольшим количеством регистров, чтобы реализовать задачу. В принципе можно не заморачиваться с регистрами и использовать переменные в памяти, но тогда алгоритмы будут работать медленно, в разы, а иногда и в десятки раз медленнее, чем если бы мы не обращались в оперативную память лишний раз.
Нам понадобится 2 справочника от компании Intel, разработавших самые популярные процессоры линейки Pentium и Core. Кроме Intel, процессоры, которые могут выполнять такие же машинные команды, делает компания AMD. В последнее время они также достигли впечатляющих результатов значительно потеснив на рынке позиции Intel.
Однако, на самом деле, для программиста процессоры Intel и AMD, практически идентичны, за исключением нескольких нюансов. Эти компании десятилетиями, совместно, разрабатывали свои процессоры, они обменивались патентами и технологиями. Поэтому сейчас внутри Intel полно фичей от AMD, а у а AMD от Intel. Поэтому я не буду превозносить одну компанию над другой или их процессоры, для меня они одинаково прекрасны. Просто мне нужно было выбрать какой-то один источник информации, чтобы вам всё показать. Я выбрала Intel, но вы если хотите, можете найти всю ту же информацию в справочнике от AMD.
Давайте перейдём на сайт intel и скачаем документацию к процессору:
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
Вам нужно будет открыть эти 2 страницы:

Открываем первую документации и качаем её:


Откроем первую документацию. Она содержит довольно большое оглавление:

Всё скриншотить не буду, можете посмотреть оглавление самостоятельно, оно в 10 раз больше. В нём содержится описание всех фич процессора, его модули, история возникновения, система команд, описание различных процессов и подсистем. Здесь много всего интересного, поэтому я рекомендовала бы прочитать весь этот справочник целиком. Когда я изучала язык ассемблера, то я прочитала его вдоль и поперёк. И да, это всё на английском языке.
Тут есть такой раздел, который называется BASIC PROGRAM EXECUTION REGISTERS:

В нём описываются главные регистры процессора. Все эти регистры условно делятся на 4 группы:

Здесь также есть картинка, в которой эти группы описаны:

Самое важное это регистры общего назначения. На картинке выше схематично изображено 8 регистров общего назначения, которые называются EAX, EBX, ECX, EDX, ESI, EDI, EBP, ESP. И вот эти 31 0 - это номера двоичных разрядов или же номера битов:

Это означает, что каждый из этих 8 регистров состоит из 32 битов (4 байтов). Эти регистры предназначены для размещения данных.
Вторая группа, это так называемые сегментные регистры, а 15 0 означает, что здесь каждый регистр состоит из 16 битов (2 байтов):

Эти регистры хранят в себе адрес или описание сегментов данных с которыми сейчас работает процессор.
Следующий регистр называется EFLAGS. Это регистр состоящий из так называемых флагов:

Флагами здесь называются отдельные биты, а в некоторых случаях битовые поля, которые имеют особое значение для процессора. Тут этих флагов 32.
Последний регистр называется EIP. Это указатель на следующую команду, которую будет выполнять процессор:

Все команды процессора пронумерованы. Они состоят из последовательности чисел и находятся в памяти. И когда процессор выполнил очередную команду, то этот регистр, который по сути является указателем на адрес в памяти, переводится на следующую команду и процессор выполняет следующую команду.
Далее регистры данных описаны более детально и мы можем узнать назначение каждого из них:

Регистр EAX называется аккумулятором для операндов и результатов. Для многих команд это единственный главный регистр, который должен содержать какие-то данные для выполняемой команды.
Регистр EBX это указатель на данные в сегменте данных. И для некоторых команд этот регистр автоматически используется, процессор подразумевает, что в нём находится указатель на нужные данные.
Регистр ECX традиционно используется как счётчик в различных циклах и строковых операциях.
Регистр EDX это указатель ввода - вывода, но на самом деле также широко используется в различных математических операциях.
Следующие 4 регистра: ESI, EDI, ESP, EBP. Они в основном используются не для оперирования данными, а для указания на эти данные. То есть, являются указателями.
ESI и EDI часто являются парными регистрами, в которых ESI указывает на то, откуда мы берём данные, а EDI, куда мы записываем результат.
Регистр ESP это указатель на стек в особую область памяти, в которой процессор хранит адреса функций и их параметры.
Регистр EBP также используется для данных, которые мы передадим в функцию.
Однако работать с 4-байтными регистрами не всегда удобно. Поэтому некоторые регистры разбиты на регистры меньше размера. В этой таблице это указано:
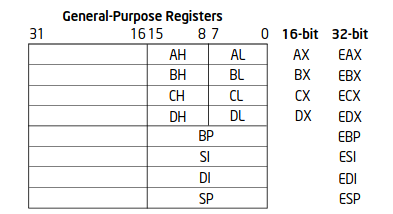
То есть, регистр EAX, который на самом деле является 4-байтным, на самом деле состоит из 2 частей. Младшая его половина называется регистр AX. И в некоторых командах, если мне нужно обратиться к 2-байтовому регистру, я буду использовать именно это имя. А если я укажу EAX, то будет использован 4-байтный регистр. В свою очередь 2-байтный регистр AX также делится на 2 однобайтных регистра, AH и AL. В некоторых командах, я могу указать в качестве одного из параметров любой из этих регистров. К сожалению вот эта старшая часть не имеет названия и не делится пополам:

Я не могу обратиться к четвёртому по счёту байту в этом регистре, за счёт чего приходится изворачиваться, перемешивать местами содержимое этих регистров, сдвигать их влево или вправо, для того чтобы получить доступ к этой старшей части. Эти же регистры вообще не делятся:
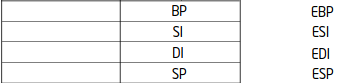
Они изначально подразумевались как указатель. Поэтому почти во всех командах, все указатели трактуются как 16-битные или 32-битные. Но в принципе, сейчас каждый из этих регистров может использоваться практически во всех операциях и уже нет такой узкой направленности у всех этих регистров.
В первых поколениях процессора регистры были маленькими. Они использовали только 2-байтные регистры. В процессорах 8086 и 80286, регистров было мало и они были маленькими. В следующем процессоре, который появился в 1985 году и назывался 80386, эти регистры стали 32-разрядными и программировать стало гораздо легче. Однако во всех современных процессорах, эти 32-разрядные регистры, были увеличены ещё в 2 раза, и теперь писать алгоритмы с таким количеством регистров стало намного проще, чем раньше.
Теперь коснусь системы команд. Их довольно много. Давайте откроем второй документ, который мы скачали и посмотрим:




Это примерно 1/5 всех команд, дальше скриншотить не буду, а то займёт много места.
На первый взгляд может показаться, что это что-то нереально сложное и возможно дискомфортное, но на самом деле если посидите и разберётесь, то вы поймёте их особенности и вам станет ориентироваться в них гораздо проще. Возьму одну команду из списка:

Команда ADD выполняет сложение.

Эта команда выполняет операцию логического "и".
Кроме таких простых команд, тут конечно же есть много непростых команд.
Я хотела бы упомянуть про ещё одну очень важную тему, которую очень часто затрагивают обсуждая архитектуру процессора:

Этот раздел описывает основные режимы, в которых может работать процессор. Этих режимов у него несколько и вот этот режим самый основной:

Он называется режим реальных адресов. Это стартовый режим, в который переходит процессор после включения питания. И в этом режиме, он изображает из себя самый древний процессор Intel 8086. В этом режиме доступны только 2-байтные регистры и очень урезанная система команд. Этот режим нужен для того, чтобы операционная система могла корректно стартовать. И после того, как стартует современная операционная система, она переводит процессор в защищённый режим:

И как написано в описании, это является родным состоянием процессора. Именно в этом режиме процессору становятся доступны все его регистры, дополнительные режимы, важнейшие механизмы по типу многозадочности, виртуальной памяти, различные уровни превилегий, особые виды прерываний, а также возможности переходить в другие какие-то режимы, по типу виртуализации или режим системного управления:

Но собственно сейчас, в современных операционных системах, режим системного управления уже особо не используется, потому что он уже слегка морально устарел. Сейчас этот режим уже называется режимом совместимости:

Он является как бы подрежимом, в котором может работать современный процессор. И в этом режиме, также как и в защищённом режиме, мы не сможем оперировать процессором, потому что это находится исключительно во владении операционной системы. А для наших программ, процессор предлагает 64-разрядный режим, который называется x64:

Это слегка упрощённая модель защищённого режима, но это упрощение даёт нам роль определённых бонусов, за счёт чего наши программы писать проще и они работают быстрее.
Так вот, этот режим реальных адресов называется x86:

Потому что он описывает общую для всех 86-х процессоров архитектуру. А вот этот режим:

Называется x64, потому что это 64-разрядный режим. Это может слегка запутать, потому что x86 это про семейство процессоров, а x64 это про разрядность этих процессоров, но это то, с чем нам приходится работать.
Это я могу наблюдать проверив какой процессор у меня:

Как видите у меня 64-разрядный процессор 86 семейства.
Надеюсь, теперь вы хотя бы в общих чертах представляете как всё это устроено.