Амазон парсер
Сравнение
Asin spotlight - это приложение на компьютер, быстродействие напрямую связано с мощностью компьютера.
Плюсы:
- Если мощный компьютер, будет очень быстро собирать данные
Минусы:
- Нагружает компьютер
Наш парсер - веб-приложение
Плюсы:
- Скрипт выполняется на сервере
- Можно запустить с любого устройства с браузером
Минусы:
- Чтобы скрипт быстро собирал данные, нужен мощный сервер и хорошее интернет соединение
Как работает?
- Запускается сервер, который ожидает ключевой фразы от пользователя.
- После ввода ключевой фразы в веб-интерфейсе и нажатия кнопки "Начать поиск", парсер заходит на сайт амазона и вводит запрос
- Получает страницу со списком товаров по запросу и фильтрами
- Выставляет фильтры
- Выбирает первую предложенную категорию
- Выбирает рейтинг: 3 звезды и выше
- Выбирает: Есть на складе

- После выставления фильтров, получается максимальное количество страниц и проходит по каждой из них для сбора всех товаров и их внешней информации
- Ссылка на товар
- Наименование
- Выставляет дату парсинга
- Asin
- Цена
- Есть ли на складе
- После сбора всех товаров, парсер переходит на каждую детальную страницу товара из полученного списка и собирает внутреннюю информацию.
- Название категории
- Название Бренда
- BSR
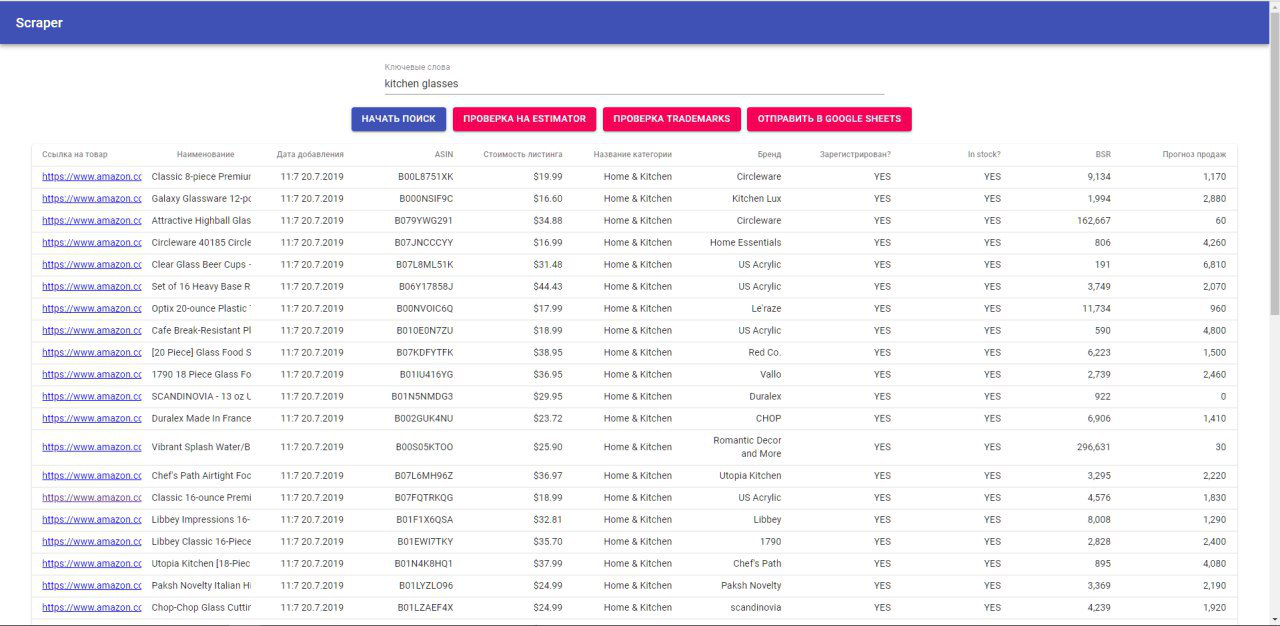
- Формируется таблица с внешней и внутренней информацией о товарах
- Становятся активными кнопки "Проверка бренда" и "Вычислить прогноз продаж"
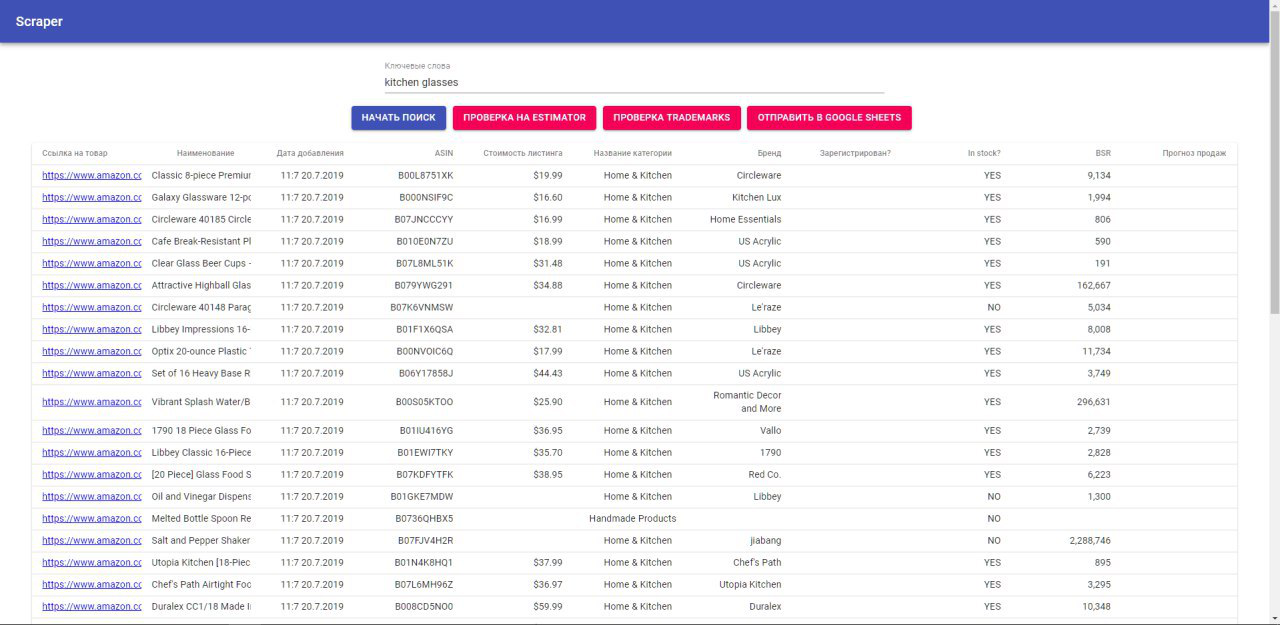
- Проверка бренда - парсер берет название бренда и проверяет на 2 сайтах: "https://www.trademarkia.com" и "https://trademarks.justia.com" и по полученной информации проставляет данные в таблицу. Так с каждым товаром.
- Вычислить прогноз продаж - парсер берет BSR и категорию каждого товара, заходит на "https://www.junglescout.com/estimator/" и по полученной информации проставляет данные в таблицу. Так с каждым товаром.
- Когда сформирована вся таблица становятся активной кнопка "Отправить в Google Sheets"
Проблемы и решения
На стадии разработки пришлось столкнуться с некоторыми ограничениями, как со стороны амазона, так и со стороны парсера.
Капча
Амазон как и любой другой крупный сервис не любит просто так отдавать большие массивы информации просто так и не хочет, чтобы их сервера падали под нагрузкой от ботов и скриптов. У него есть защита от ботов, парсеров, скриптов и DDoS атак.
На этапе разработки выявлено, что у него есть ограничение на 500 запросов в день. Потом он просит ввести капчу. Это не было предусмотрено в техническом задании. Но поскольку в таком случае, парсер мог бы работать только ограниченное количество времени в день, я взял на себя ответственность с надеждой, что мне это окупится и написал функционал, который общается с API сервиса по "решению капчи". Теперь когда парсер попадает на страницу "Robot Check", он берет изображение капчи, переводит его в base64 и отправляет в этот сервис, когда от сервиса получен ответ - парсер вводит капчу и скрипт продолжает работу.
Сейчас подключен сервис 2captcha
Бесплатного работающего аналога на рынке нет.
Вот тарифы (у нас обычная капча):

Многопоточность
После того, как парсер был написан, на стадии тестирования, была выявлена еще одна немаловажная проблема - скорость выполнения.
Наш парсер, это ускоренная эмуляция действий человека. Но при таком большом массиве данных, условный 1 человек будет делать это очень долго.
Когда мы получили ссылку с выставленными фильтрами, мы должны пройтись по каждый из страниц и собрать все ссылки на товары и потом по каждой из этих ссылок перейти и собрать детальную информацию.
Возьмем небольшой кусок работы скрипта:
Что будет если у парсера будет 5000 тысяч товаров в запросе на сбор детальной информации после выставления фильтров и получения всех ссылок на товары?
При условии, что у парсера хорошее интернет соединение - заход на 1 страницу, сбор на ней информации и закрытие этой страницы занимает ~2 секунды. Из этого мы получаем ((5000*2)/60)/60 = ~3 часа нужно чтобы собрать только детальную информацию, но это еще не весь парсер.
Представьте, что теперь еще нужно каждый товар прогнать через 3 медленных сайта по проверке бренда и вычислению прогноза продаж, там один товар может занимать до 3 секунд на 1 сайт.
3 часа + 4 часа + 4 часа + 4 часа = ~15 часов на получение полной таблицы из 5000 тысяч товаров
Так бы работал скрипт по ТЗ в одном потоке, но опять же этот вариант мало кого устроит, поэтому я поступил также как с прошлой проблемой и решил ее, все еще надеясь, что мне это окупится.
Чтобы решить данную проблему, я написал функционал многопоточности, в ядре скрипта можно указать количество потоков. В будущем можно будет перенести эту константу в веб-интерфейс.
Как работает многопоточность?
Скрипт запускает задачи, которые выполняются синхронно.
Допустим мы выставили, что парсер должен работать в 10 потоках и возьмем ту же задачу на 5000 товаров. Теперь эти ~15 часов можно поделить на 10 и мы получим 1.5 часа.
Следовательно теперь скорость работы скрипта можно увеличить в зависимости от вычислительных мощностей компьютера или сервера на котором будет запущен скрипт парсера.
Ставим 40 потоков и парсер соберет внешние и детальные данные за ~4,5 минуты и прогонит данные через сервисы за ~17,5 минут = ~22 минуты на обработку такого большого массива данных.
Оптимизация загрузки страниц
И такого времени выполнения скрипта мне показалось много и я решил оптимизировать загрузку страниц.
Обычно браузер запрашивает все данные, которые предоставляет сайт и все эти данные начинает качать и только потом рендерится страница.
Я эти запросы заблокировал.
При загрузке страницы, наш парсер не отправляет запросы:
- на изображения
- на скрипты
- на шрифты
Теперь загрузка каждой страницы уменьшилась ~0.5-1.5 секунды в зависимости от того, каким сайтом мы пользуемся в данный момент времени - амазоном или сторонними сервисами.
Возможные подводные камни
Бан
Есть вероятность того, что у амазона есть ограничения на запросы в целом на один IP. Т.е есть дневной лимит запросов, который можно обойти вводом капчи, а может быть общий лимит запросов на IP, после которого IP может попасть в бан. И если такое когда-то случится - я предлагаю сделать функционал "Proxy", т.е после какого-то количества запросов на амазон у нашего парсера будет подменяться IP.
Верстка страниц и постоянная поддержка
Когда амазон решит поменять структуру сайта или структуру страницы продукта, или наименования блоков, скрипт может перестать парсить переименованный блок или вообще перестать работать. Это не проблема, но из-за этого парсеру нужна постоянная поддержка, чтобы в коде менять селекторы запрашиваемых данные.Тоже самое со сторонними сервисами.
Сервер
Чтобы парсер работал в большом количестве потоков и быстро выполнялся, нужен мощный сервер.
Дополнительные функции
Ниже опишу как можно усовершенствовать парсер
- Сделать удобную таблицу (С сортировкой, фильтрами, поиском, пагинацией)

- Выставление фильтров в самом веб-интерфейсе, а не использовать статические в коде (Например выбор категории, выставление рейтинга и прочие)
- Подключение сокетов. Данные в таблицу будут поступать по мере обратки 1 страницы, а не отработки части скрипта. Т.е будет красивая постепенная подгрузка данных.
- Подключить нейросеть вместо 2captcha для распознавания капчи. Сейчас технологии позволяют сделать разгадывание такой капчи. Это сэкономит деньги.
- Сделать десктопную версию парсера, чтобы он запускался на компьютере и потреблял мощности компьютера пользователя, а не серверные.