C programming | Working with files II

There are two main types of data we can store in a file: ASCII or text data, and binary data. Binary serialization involves taking some arbitrary set of structured data and transform that data into a consistent stream of bytes.
Many high-level programming languages have custom solutions to achieve binary serialization, while in C there's not a standard solution at all.
Binary data encoding and decoding can be useful in two main fields:
- Networking.
- File saving.
We saw in the previous article how to encode and decode text data, using JSON as our main data structure type.
Text data files are portable and can be moved between computers with ease but, when we ask our computer to work with a text file, it needs to convert it to binary data somehow, which can be rather slow depending the situation.
In the other hand, working with binary data files needs no conversion at all, and usually these kind of files are smaller than text-based ones. We break down complex structures apart and write their individual properties into the buffer. Once it's done, when requested we can read the same data to reconstruct the complex structure.
The main downside is that we cannot print directly their content to our console.
Note that we are using specific byte sizes when defining data. This is important since when we design or use an actually binary file format, its contents are (or should be) ordered in structs specifying which data is inside. The way to know each part of the file is by interpreting those structs which contain the data values.
A practical example with data
Let's suppose we have to create a structured data format for a program that takes daily weather forecast data from the user.
We need at least some constant variables to be filled, such as sunlight hours, cloud formation's type, precipitation's type, rate and amount (if any), minimum and maximum humidity, minimum and maximum temperature, etc. Data the program can later use to make weather predictions and estimations, monthly statistics, etc.
— We can think of our structure as:
typedef enum {
CLEAR = 0,
CIRRUS,
CUMULUS,
STRATUS,
NIMBUS
} e_cloud;
typedef enum {
NONE = 0,
RAIN,
DRIZZLE,
SNOW,
SLEET,
HAIL
} e_precipitation;
typedef struct daily_forecast_t {
float sunlight_hours;
e_cloud cloud_type;
e_precipitation prec_type;
float prec_rate;
float prec_hours;
float prec_amount;
float min_temp;
float max_temp;
float average_temp;
float min_humidity;
float max_humidity;
float average_humidity;
} daily_forecast_t;— Now that we have our data structures defined we can create some data to work with. In a real program this data would come from the terminal emulator args or inputs, or from the input fields of a window made for the purpose.
daily_forecast_t day = {
.sunlight_hours = 14.2,
.cloud_type = 2,
.prec_type = 0,
.prec_rate = 0.0,
.prec_hours = 0.0,
.prec_amount = 0.0,
.min_temp = 7.0,
.max_temp = 21.2,
.average_temp = 0.0,
.min_humidity = 18.3,
.max_humidity = 25.6,
.average_humidity = 0.0
};
day.average_temp = (day.min_temp + day.max_temp) / 2;
day.average_humidity = (day.min_humidity + day.max_humidity) / 2;— The next step is to store this data so we don't loose any. In a binary format, using fwrite() should be enough. From the previous article, we know we need a FILE handler in write mode where to save our binary data.
FILE *out = fopen("day1.bin", "w");
if(out != NULL) {
fwrite(&day, sizeof(daily_forecast_t), 1, out);
fclose(out);
} else {
printf("%s\n", "there's been an error with the file.");
}— If we compile and execute our program, we should have a new file named day1.bin in the program's directory.
Trying to read it as plain text is going to print some weird stuff to the console:
$ less day1.bin 33cA^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@<E0>@<9A><99><A9>A<9A><99>aAff<92>A<CD><CC><CC>A<9A><99><AF>A day1.bin (END)
not so useful for the human eye.
Since we are inside a *nix machine, let's use hd to properly inspect the file.
$ hd day1.bin 00000000 33 33 63 41 02 00 00 00 00 00 00 00 00 00 00 00 |33cA............| 00000010 00 00 00 00 00 00 00 00 00 00 e0 40 9a 99 a9 41 |...........@...A| 00000020 9a 99 61 41 66 66 ca 41 66 66 12 42 99 99 f7 41 |..aAff.Aff.B...A| 00000030
This still isn't much useful for us as console readers, but the program can interpret the information contained in it much faster as if it were plain text.
— We suppose the file's content is fine, but we need a way to check it, and to read that data in a workable way. Let's create a read function to do so.
- Since we know how data is structured and it needs to be deconstructed in that specific way, first create a
daily_forecast_tvariable where to hold the read data.
daily_forecast_t day_data;
- Then create a
FILEhandler in read mode that reads the file we just saved. To prove it's working let's print the average data values we calculated.
Note that once we've read the file, we have the data stored in memory so it's a good practice to close the file before doing anything else.
FILE *in = fopen("day1.bin", "r");
if(in != NULL) {
fread(&day_data, sizeof(daily_forecast_t), 1, in);
fclose(in);
printf("Average temp from day has been: %.2f\nAverage humidity from day has been: %.2f\n", day_data.average_temp, day_data.average_humidity);
} else {
printf("%s\n", "there's been an error reading the file.");
}- After compiling and running it we should have something like this in the command line:
$ ./weather Average temp from day has been: 14.10 Average humidity from day has been: 30.95
— Right now, that data structure is filled daily and we have the ability to write a file per day. It'd be great if it could to be stored in a way we can manage days in months, and months in years.
So a month data structure could be:
typedef struct month_forecast_t {
int days; /* total days in month */
void *days_data; /* an array containing all days' data */
} month_forecast_t;and a year data structure could be:
typedef struct year_forecast_t {
int months; /* total months in a year */
void *months_data; /* an array containing all months' data */
} year_forecast_t;— If we want to pass our created day's data into a month_forecast_t first we need to allocate some memory for the month's data:
month_forecast_t january; january.days = 31; january.days_data = malloc(january.days * sizeof(daily_forecast_t));
and then we can pass the data to our desired day:
january.days_data[0] = day1;
Always remember to free() allocated memory once it's no longer needed.
Creating file formats
At this point, we have our structured data stored in a file, yet we have no way to determine which file is the correct one for our weather forecast program to load and read (except for the file extension if we decide a unique one, but that alone isn't so reliable as an identifier).
Getting it a bit worse, when we apply serialization we need to take care of the compiler's padding system and the way the computer and the OS represent data in binary form. That is Big Endian or Little Endian representation.
— From a technical view, Big Endian store the most significant byte at lower addresses while Little Endian does it the opposite way, storing the most significant byte at higher addresses.
Little Endian | Big Endian
32bit int memory | memory 32bit int
0A0B0C0D | .. | | | .. | 0A0B0C0D
| | | |___ | 0D | | | 0A | ___| | | |
| | |_____ | 0C | | | 0B | _____| | |
| |_______ | 0B | | | 0C | _______| |
|_________ | 0A | | | 0D | _________|
| .. | | | .. |In plain text we can say that Big Endian just represents the data the way we read it, and Little Endian represents the data flipped.
— File formats can help us defining and maintaining how our data should be interpreted, no matter which machine or OS the program is running in.
When creating file formats it's important to take care of the following aspects:
- Unique file identification
It's common between binary file formats to use the first bytes of the file to include a unique number that identifies the format. That is, the magic number or signature of the file.
- Versioning
Our program can grow in the future, and maybe it can handle new data, or maybe some parts are refactored and so the file format. In order to avoid wrong data parsing when this events happen, it's important to keep track of the file format's version.
There's no need to go crazy with conventions. One or two digits should be enough. A more professional approach can be starting at version 1.0.0 use the last digit for patch releases, the middle digit for minor releases and the left one for major releases.
- Header checksum
This is optional (depending on who you ask to) to add into a file format. It mainly let us know that the file isn't damaged.
- Offset to data
This provides a hint on where to start reading the data contained in the file.
Making a simple try for a file format is less scary than you may think. To make things easier from this point, let's use the extension .fct for our forecast program files.
— ADDING A FILE FORMAT HEADER
Diving into it, we have to create a HEADER struct that has to be read before our actual file's data.
typedef struct fct_header_t {
char identifier[12];
char version;
char data_offset;
} fct_header_t;We can also define a file_id in a way that can be almost unique:
const unsigned char fct_id[12] = {
//'«', 'F', 'C', 'T', ' ', '1', '0', '»', '\r', '\n', '\x1A', '\n'
0xAB, 0x46, 0x43, 0x54, 0x20, 0x31, 0x30, 0xBB, 0x0D, 0x0A, 0x1A, 0x0A
};— DEFINING A FILE STRUCTURE
Right now we have evolved our program, and just writing out the forecast structure for a day is no longer useful. We have to give our file a structure where we can handle both the header and the data.
typedef struct fct_file_t {
fct_header_t header;
daily_forecast_t data;
} fct_file_t;Then we can implement our write and read functions separately to make things tidier.
— MAKING A WRITE FUNCTION
Moving the write components out of the main() function allows us to call the function where needed, when needed in a cleaner way.
We can pass to it a fct_file_t parameter as well as a filename parameter (in the form of a char*).
One cool addition is to implement an auto extension for the file name. This is almost useless in terms of functionality, but gives the user the ability to fast check the file in a file explorer visually.
int write_to_file(fct_file_t fct, char *filename) {
/* auto append file extension */
char *ext = ".fct";
strcat(filename, ext);
/* open in write mode*/
FILE *out = fopen(filename, "w");
/* check if there's a problem with the file before doing anything*/
if(out != NULL) {
fwrite(&fct, sizeof(fct_file_t), 1, out);
fclose(out);
printf("%s written!\n", filename);
return 0;
} else {
printf("there's been an error with the file %s", filename);
return 1;
}
}We can handle specific chunks of data by creating buffers and passing the info through functions like memcpy() .
Let's say we have the following header:
fct_file_t file1 = {
.file_header = header,
.data = day1
};and we want to copy just the header to a buffer:
unsigned char *header_buffer = (unsigned char*)malloc(sizeof(fct_header_t));
The code would perform something like this:
identifier (12) -> ab 46 43 54 20 31 30 bb 0d 0a 1a 0a -> header_buffer version (1) -> 01 -> header_buffer data_offset (1) -> 0e -> header_buffer
which we can confirm by printing out the value of the header_buffer:
printf("header_buffer content:\n");
for(int i = 0; i < sizeof(fct_header_t); i++)
printf("%02x ",header_buffer[i]);
printf("\n");Now we can use our buffer for many things, since it's structured and we can handle the information.
— MAKING A READ FUNCTION
Same as the write function, moving the read file instructions away from the main() function gives us more freedom later when scaling the program.
One key part in the reading function are to check if the data is valid for our program. We can achieve it by comparing the file header id against our known fct_id we created earlier using memcmp().
int read_from_file(char *filename){
/* generate a temporal fct_file type to store read data */
fct_file_t tmp_fct;
/* open in read mode */
FILE *in = fopen(filename, "r");
/* check if there's a problem with the file before doing anything*/
if(in != NULL) {
fread(&tmp_fct, sizeof(fct_file_t), 1, in);
fclose(in);
/* verify it's a valid fct file comparing the header id */
if (memcmp(&tmp_fct.file_header.id, fct_id, 12) != 0) {
printf("%s\n", "Not a FCT V1 file or corrupted file. Identifier isn't valid");
return 1;
}
/* print some file header info */
printf("fct file version is %d\n", tmp_fct.file_header.version);
printf("we can skip %d bytes to reach our data\n\n", tmp_fct.file_header.data_offset);
/* test print some file data */
printf("Average temp from day has been: %.2f\nAverage humidity from day has been: %.2f\n", tmp_fct.data.average_temp, tmp_fct.data.average_humidity);
printf("Cloud type from day has been: %d\nPrecipitation type from day has been: %d\n", tmp_fct.data.cloud_type, tmp_fct.data.prec_type);
return 0;
} else {
printf("there's been an error with the file %s", filename);
return 1;
}
}— MAKING A FLEXIBLE FILE FORMAT
At this point we can save forecast data for a day and read it back. Scaling the project, we could make our program ask the user to create a forecast session, initializing a data structure inside the program that can be stored in a file that understand days inside months, and months inside years (using the structs we proposed earlier in the article).
That way we would be able to give flexibility to the users, allowing them to work with data for an entire year, appending and/or modifying values over one file across time.
A practical example with existing file formats
Having to deal with existing file formats is another reality worth looking at. Usually when designing a program to interact with other programs' data, it's common to use file formats that actually exist.
Tasks like saving or reading pixel data for images and video, loading or writing samples data for audio have already a huge amount of available file formats to work with.
Unless we need a custom tailored data format to our software (because of encryption or efficiency), using existing file formats can give us some benefits like:
- Avoid to reinvent the wheel.
- Portability.
— We are going to check the TGA image file format for the example, so we need to find the file specification to know where to start.
TGA files store red, green and blue channels with 8 bit precision each. This leaves us with 24 bits per pixel.
TGA files also offer an additional 8 bit alpha channel that can be really useful. Assuming we are working with RGBA it should be 32 bit per pixel.
According to the format specification we have a header which contains the following data:
- Image ID length (1 byte) usually contains the date and time the file was created.
- Color map type (1 byte) handles whether a color map is included. Can be
0or1. - Image type (1 byte) contains compression and color type information.
- Color map specification (5 bytes) describes the color map.
- Image specification (10 bytes) has Image dimensions and format.
—This gives us an 18 byte header where we know which data goes to each part. We can translate that info into a struct like this:
typedef struct tga_header_t {
char id_size;
char color_map_type;
char image_data_type;
short int color_map_origin;
short int color_map_length;
char color_map_depth;
short int x_origin;
short int y_origin;
short image_width;
short image_height;
char bits_per_pixel;
char image_descriptor;
} tga_header_t; Next we have to define how our pixels are constructed:
typedef struct pixel_t {
unsigned char r;
unsigned char g;
unsigned char b;
unsigned char a;
} pixel_t;So a TGA file can be described as such struct:
typedef struct tga_file_t {
tga_header_t header; /* a header struct defining the type of TGA */
pixel_t *pixels; /* the pixels forming the image */
} tga_file_t;Now if we want to open a TGA file and check what info does it have inside the header we can create a read function like this:
int read_tga_file(char *filename) {
FILE *fptr;
fptr = fopen(filename, "r");
tga_header_t tmp_header;
pixel_t *pixels;
tga_file_t tmp_file;
if(fptr != NULL) {
/* in order to get the image width and height we have to
jump into the desired position of the file.
Since we know that they are 12bytes from the origin, we can use
fseek() */
fseek(fptr, 12, SEEK_CUR);
fread(&tmp_file.header.image_width, 2, 1, fptr);
fread(&tmp_file.header.image_height, 2, 1, fptr);
printf("image %s has width: %d and height %d\n", filename, tmp_file.header.image_width, tmp_file.header.image_height);
} else {
printf("there's been an error with the file %s\n", filename);
return 1;
}
}If we want to work with the pixel data, we need to create some space to handle their information.
We know that an image is constructed in two dimensions (x and y) given a size for each dimension (width and height). At each point of that 2D grid there's a pixel, which we assume contains four values as color information (RGBA).
tmp_file.pixels = malloc(tmp_file.header.image_width * tmp_file.header.image_height * sizeof(pixel_t));
To avoid having garbage data we can initialize each value to zeros:
for(int i=0; i<tmp_file.header.image_width * tmp_file.header.image_height; i++) {
tmp_file.pixels[i].r = 0;
tmp_file.pixels[i].g = 0;
tmp_file.pixels[i].b = 0;
tmp_file.pixels[i].a = 0;
}Now we can read the image. Let's change some color values as a quick test. Here we have a function that stores the referenced value from an actual image pixel into our own pixel data, only leaving the green channel to its absolute value.
/* TGA is Little Endian encoded, so values in pixel are bgra instead of rgba. */
void change_pixel_color(pixel_t *pixel, unsigned char *p_value) {
pixel->a = p_value[3];
pixel->r = p_value[2];
pixel->g = 255; /* p_value[1]; */
pixel->b = p_value[0];
}So after allocating our pixel data from the file pointer we can run that function until we reach the last pixel in the image like this:
int n = 0;
char p_value[4];
while(n < (tmp_file.header.width * tmp_file.header.height) ) {
fread(p, 1, 4, fptr);
change_pixel_color(&(tmp_file.pixels[n]), p_value);
n++;
}
fclose(fptr);To write the data out into a file we can whether reopen our file in write mode and overwrite data there, or open a new file in write mode, and then store the new pixel data along with a TGA header.
Here's a result of a four pixel TGA Image passed through the previous change_pixel_color() function:
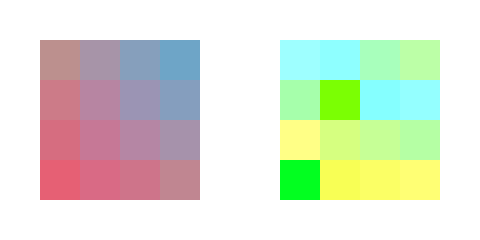
Summing up
Now that we've covered both ways of storing data from a program inside the computer, it's time for your creativity to flow in your next project.
Some data types and projects require more tailored byte buffers than just a bulk read and a bulk write of bytes. That topic will be covered in other series of articles.
Full working examples of the code shown above are coming to the unixworks repository. Stay tuned, and I'll see you in the next article (: