[CRISP-DM] Анализ публичного набора данных — Iowa liquer saler
Задача: исследовать продажи спиртных напитков за 2 года в штате Iowa
__________________________________________________________________________________
Пояснение:
Для решения задачи будет использован фреймворк анализа данных CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных.
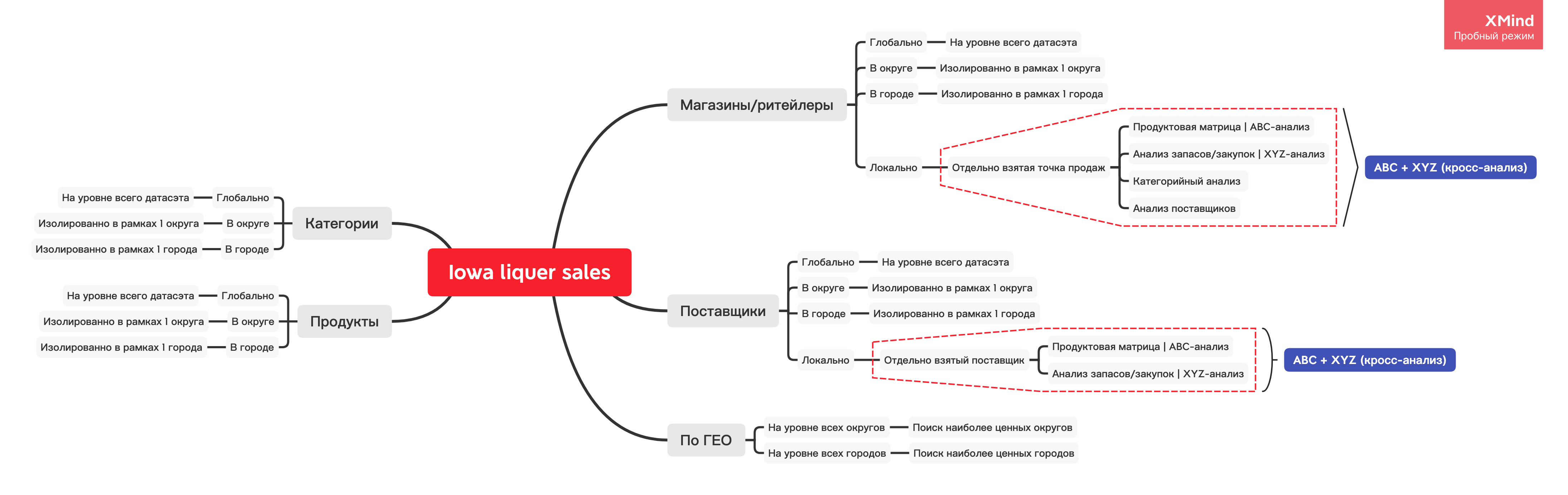
В рамках исследования мы пройдем ключевые этапы анализа, иллюстрированных ниже ↓
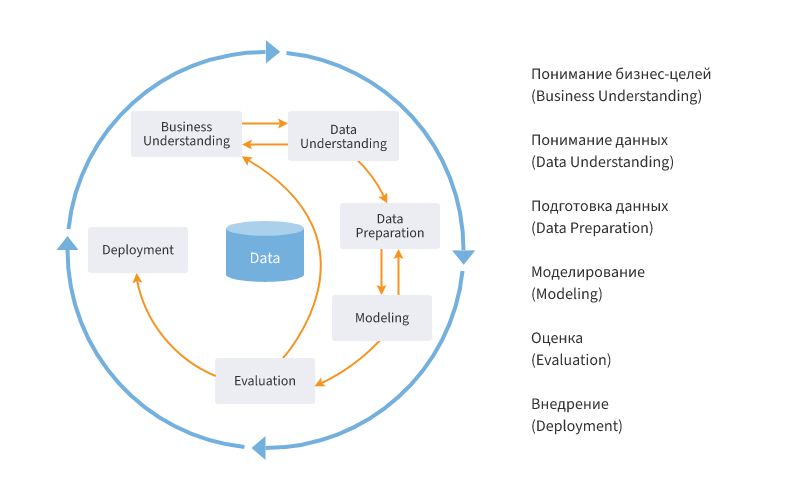
1) Понимание бизнеса (Business Understanding):
В силу высокого уровня неопределенности бизнес-целей анализа были определены следующие группы стэйкхолдеров:
• Ретейлеры/магазины
• Поставщики
• Регулирующие органы
1.1) Цели анализа:
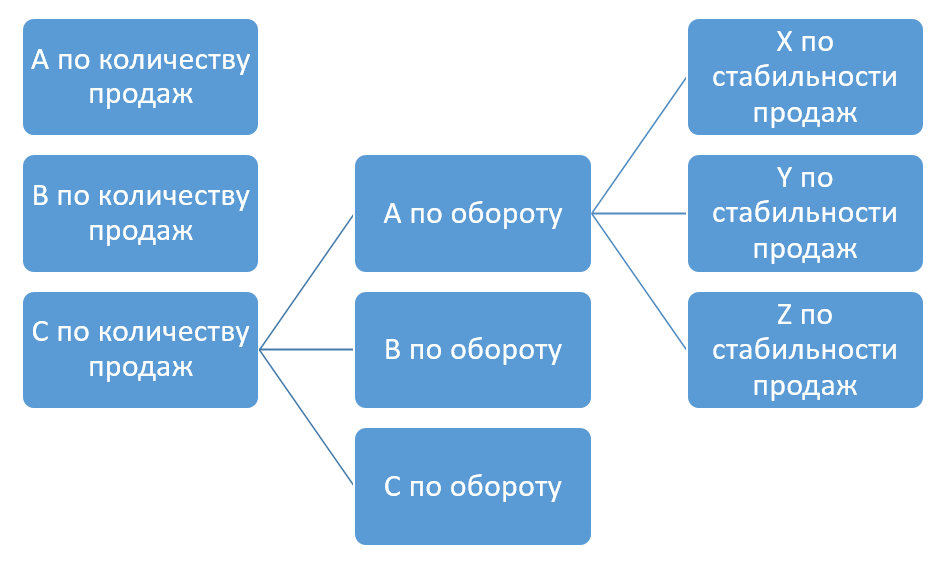
1.1.1) Ранжирование и группировка продуктовой матрицы в зависимости от влияния продукта на совокупный эффект, измеряемый денежными и количественными показателями продаж.
Инструмент достижения цели — ABC-анализ
1.1.2) Ранжирование и группировка продуктовой матрицы по характеру спроса: насколько он стабилен и насколько точно его можно спрогнозировать?
Инструмент достижения цели — XYZ-анализ
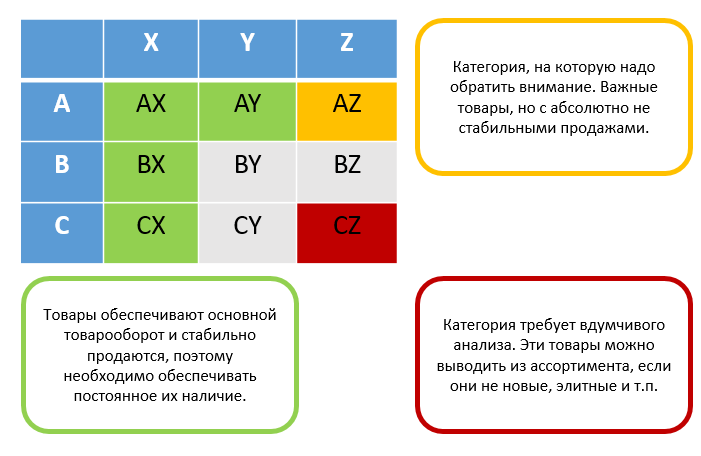
1.1.3) Разработать ряд рекомендаций по оптимизации продуктовой матрицы и управлению запасами через измерение совокупного влияния ряда синтетических метрик полученных в результате ABC и XYZ анализа на уровне отдельно взятого магазина
Инструмент достижения цели — перекрёстный ABC+XYZ-анализ
Иллюстрация инструментов:

2) Понимание данных (Data Understanding):
Данный этап позволил идентифицировать цели бизнеса и спроектировать процесс подготовки данных
2.1) Главные выводы:
2.1.1) Из названия "Iowa Liquor Sales" можно предположить, что набор данных содержит в себе сведения о продажах спиртных напитков розничными магазинами в штате Iowa. Но в процессе исследования был сделан вывод о том, что данные отражают товаропоток от поставщика до точки сбыта (что косвенно дает возможность делать выводы о продажах на уровне отдельно взятого магазина). Подобно ЕГАИС в рамках РФ.
Ссылка на описание набора данных: https://mydata.iowa.gov/Sales-Distribution/Iowa-Liquor-Sales/m3tr-qhgy
Комментарий к данным:

Ключевые атрибуты:
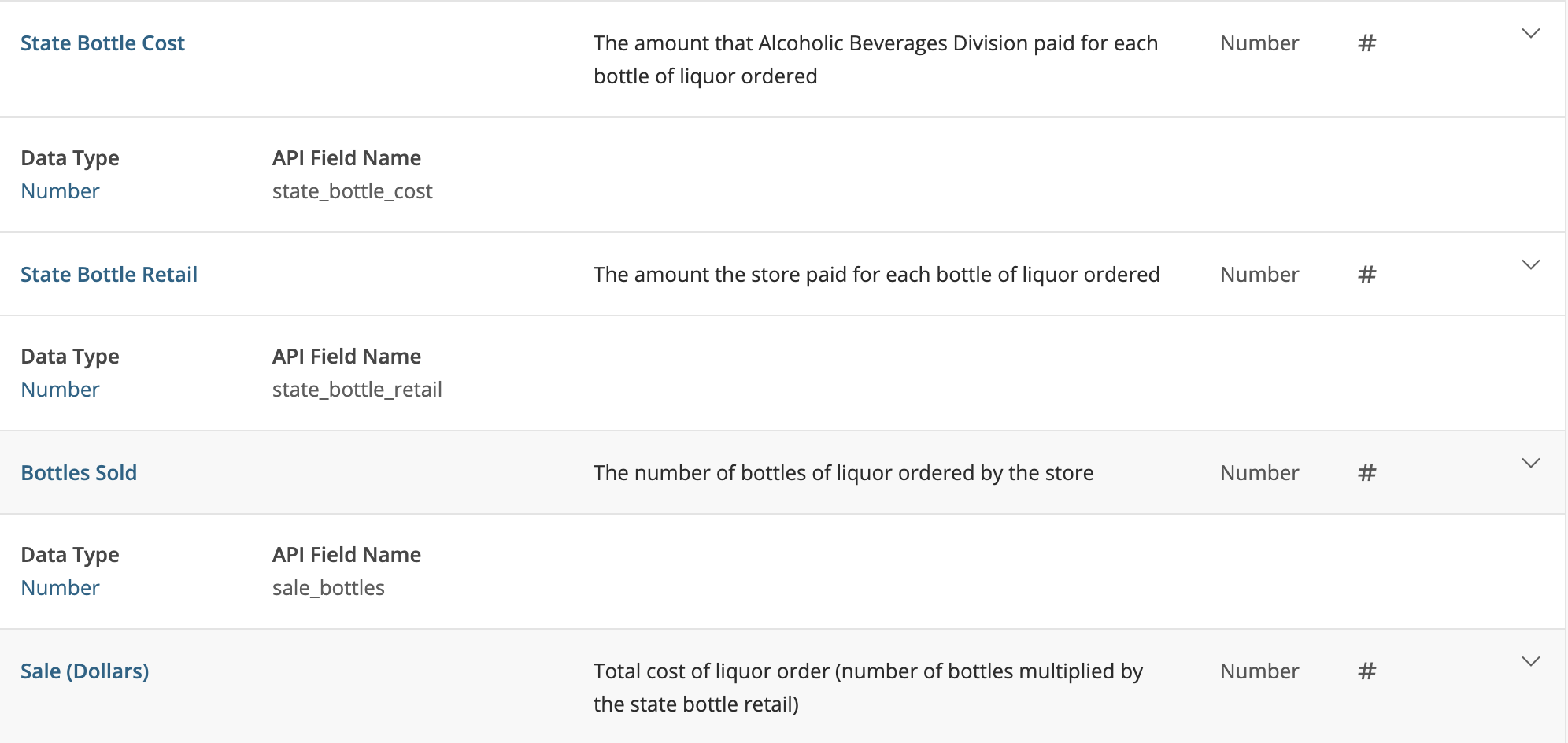
2.1.2) В процессе понимания данных, даже в условиях «полной неопределенности», получилось идентифицировать цели бизнеса и увидеть набор данных в неочевидных плоскостях
3) Подготовка данных (Data Preparation):
3.1) Отбор данных
3.1.1) Для реализации большинства графиков и таблиц дашборда в рамках Google Data Studio использовался исходный набор данных
3.1.2) Для реализации ABC и XYZ анализа составлен SQL запрос к исходному набору данных, в рамках которого, была произведена агрегация, разметка, сегментация и очистка данных.
3.2) Обеспечение качества данных
3.1) Нормализация текстовых атрибутов: описание товара, название магазина, название поставщика реализованы с помощью функции FIRST_VALUE(). Агрегирование входных атрибутов для FIRST_VALUE проведено в рамках оконной функции OVER(PARTITION BY(ID)) с партицированием по первичным ключам текстовых атрибутов. Таким образом все текстовые с общими уникальные идентификаторами были заполнены одинаковыми значениями