[Data Science] Фреймворки анализа данных: SEMMA, CIRISP-DM, KDD
1) SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных, предложенная американской компанией SAS.
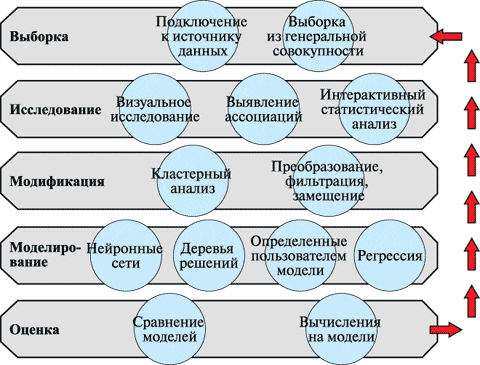
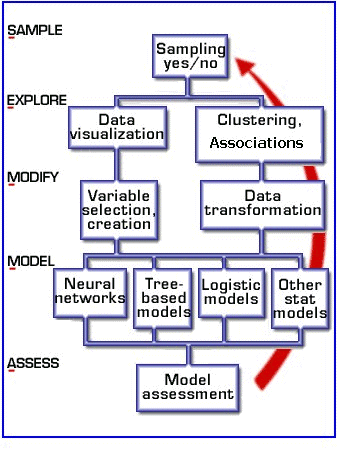
1.1) Из чего состоит SEMMA: этапы процесса Data Mining
- Выборка данных – формирование начального набора данных для моделирования (dataset), который должен быть достаточно большим, чтобы содержать достаточную информацию для извлечения, и в то же время ограниченным, чтобы его можно было эффективно использовать.
- Исследование – выявление ассоциаций, визуальный и интерактивный статистический анализ, понимание данных путем обнаружения ожидаемых и непредвиденных связей между переменными, а также отклонений с помощью визуализации данных.
- Модификация – применение методов выбора, создания и преобразования переменных при подготовке к моделированию: кластерный анализ, преобразование, фильтрация и замещение информации.
- Моделирование — применение методов построения и обработки моделей интеллектуального анализа данных: искусственные нейронные сети, деревья принятия решений, регрессионный анализ и т.д.
- Оценка – сравнение результатов моделирования между собой и с планируемыми показателями, анализ надежности и полезности созданных моделей.
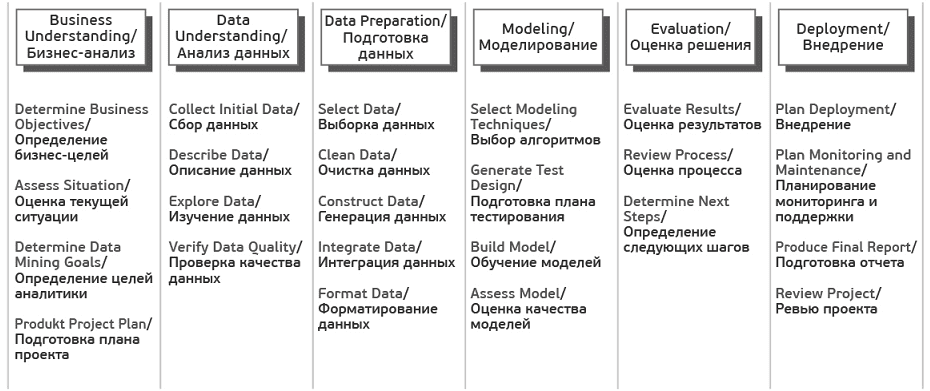
2) CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных.
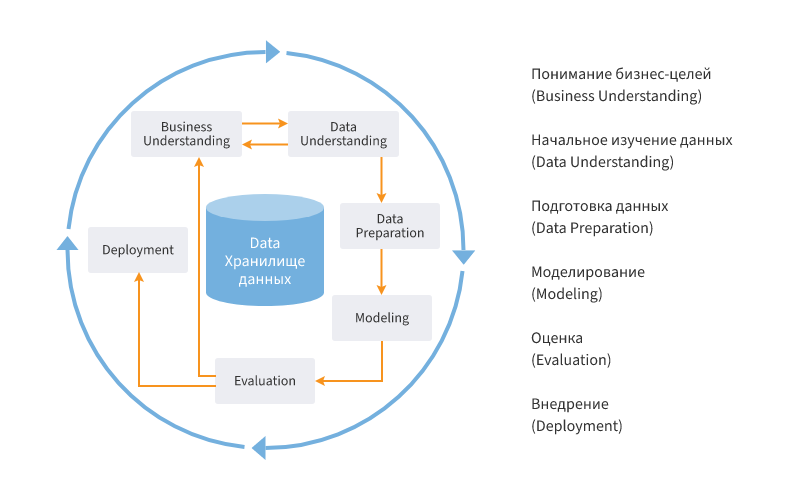
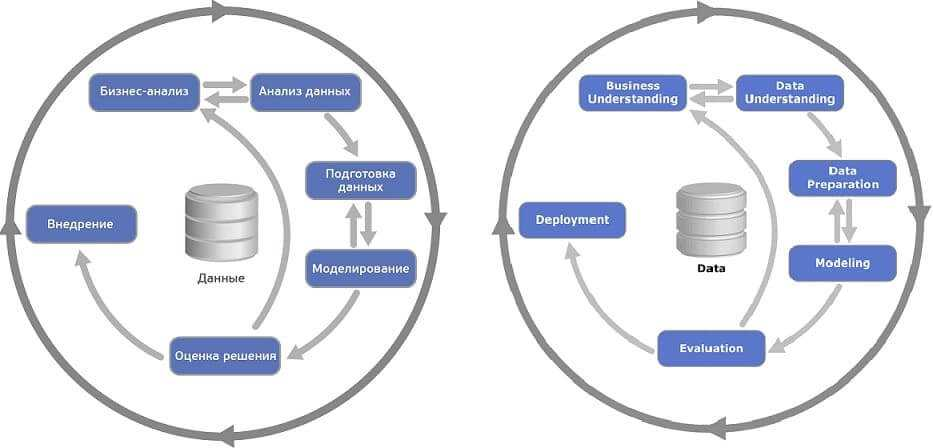
Рассмотрим подробнее фазы жизненного цикла исследования данных по CRISP-DM:
2.1) Понимание бизнес-целей (Business Understanding). На данном этапе производится исследование бизнес-процессов компании и предлагаются идеи относительно применения анализа данных для их совершенствования, формулируются конечные цели анализа. Для этого к обсуждению приглашается как можно больше заинтересованных специалистов и экспертов. Результатом этапа должен стать план аналитического проекта. Кроме этого, необходимо убедиться в целесообразности проекта, прежде чем тратить на него ресурсы. Задачи фазы Business Understanding:
- Определить бизнес-цели
- Оценить ситуацию
- Определить цели анализа данных
- Составить план проекта
2.2) Начальное изучение данных (Data Understanding). Данная фаза включает в себя более детальное изучение имеющихся данных. Ее цель — избежать непредвиденных проблем на стадии подготовки данных, которая, как правило, является самой сложной частью проекта. Начальное изучение данных предполагает организацию доступа к ним, их исследование с использованием таблиц и графиков, оценку качества данных и разработку соответствующей документации. Задачи фазы Data Understanding:
- Собрать исходные данные
- Описать данные
- Исследовать данные
- Проверить качество данных
2.3) Подготовка данных (Data Preparation). Является одним из наиболее важных и зачастую трудоемких этапов аналитического проекта, который может поглощать 50-70% времени, усилий и ресурсов. В зависимости от специфики компании и направления ее деятельности подготовка данных обычно включает:
- консолидацию данных;
- формирование выборок;
- обогащение данных
- очистку данных
- разделение данных на обучающие и тестовые
2.4) Моделирование (Modeling) – в этой фазе к данным применяются разнообразные методики моделирования, строятся модели и их параметры настраиваются на оптимальные значения. Обычно для решения любой задачи анализа данных существует несколько различных подходов. Некоторые подходы накладывают особые требования на представление данных. Таким образом часто бывает нужен возврат на шаг назад к фазе подготовки данных. Задачи фазы Modeling:
- Выбрать методику моделирования
- Сделать тесты для модели
- Построить модель
- Оценить модель
2.5) Оценка (Evaluation) – анализ количественных характеристик качества модели, подтверждение или опровержение того, что, благодаря построенной модели все бизнес-цели достигнуты. Основной целью этапа является поиск важных бизнес-задач, которым не было уделено должного внимания. Задачи фазы Evaluation:
- Оценить результаты
- Сделать ревью процесса
- Определить следующие шаги
2.6) Внедрение (Deployment) – в зависимости от требований фаза развертывания может быть простой (составление финального отчета) или сложной, например, автоматизация процесса анализа данных для решения бизнес-задач. Обычно развертывание — это внедрение полученных моделей в прикладную сферу. Задачи фазы Deployment:
- Запланировать развертывание
- Запланировать поддержку и мониторинг развернутого решения
- Сделать финальный отчет
- Сделать ревью проекта
3) Knowledge Discovery in Databases (KDD) – это процесс поиска полезных знаний в «сырых» данных.
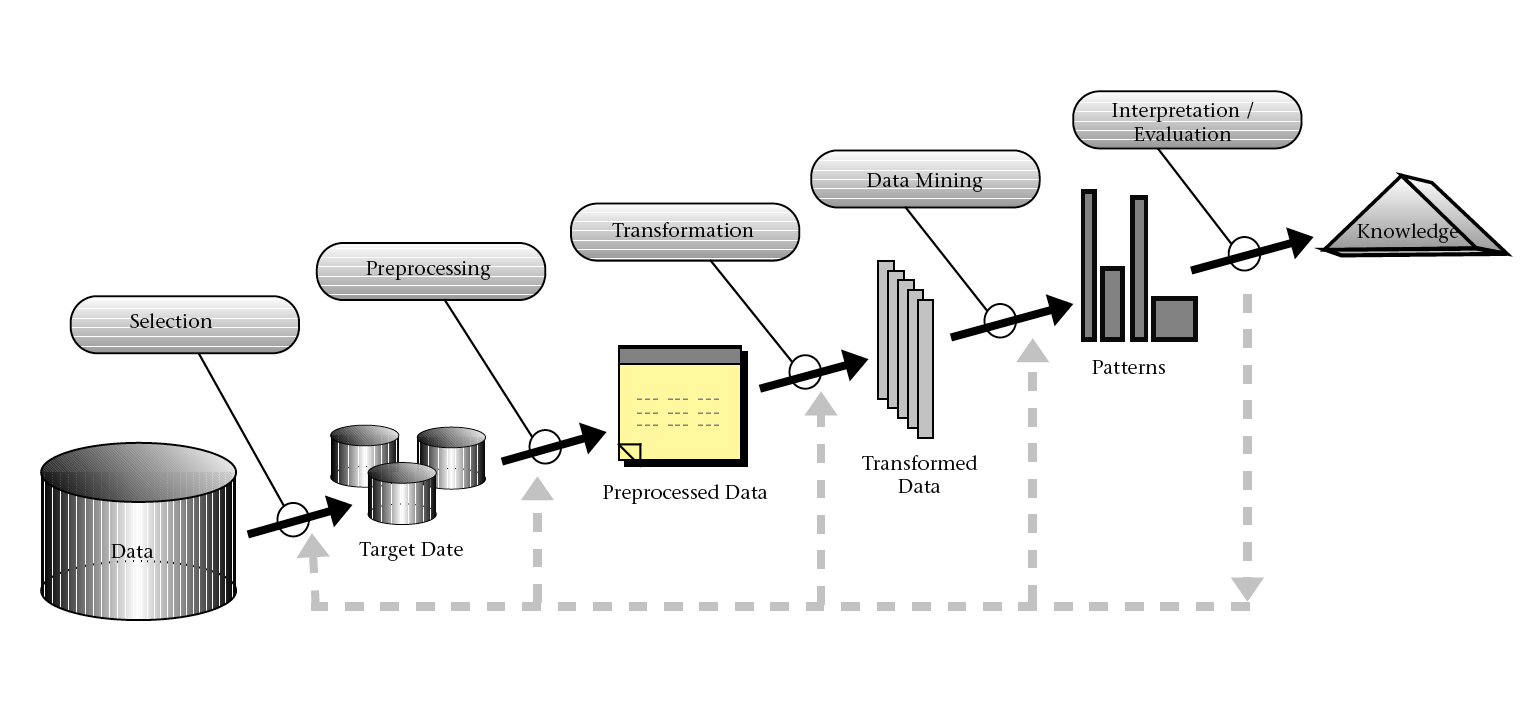

- Подготовка исходного набора данных. Этот этап заключается в создании набора данных, в том числе из различных источников, выбора обучающей выборки и т.д. Для этого должны существовать развитые инструменты доступа к различным источникам данных. Желательно иметь поддержку работы с хранилищами данных и наличие семантического слоя, позволяющего использовать для подготовки исходных данных не технические термины, а бизнес понятия.
- Предобработка данных. Для того чтобы эффективно применять методы Data Mining, следует обратить внимание на вопросы предобработки данных. Данные могут содержать пропуски, шумы, аномальные значения и т.д. Кроме того, данные могут быть избыточны, недостаточны и т.д. В некоторых задачах требуется дополнить данные некоторой априорной информацией. Наивно предполагать, что если подать данные на вход системы в существующем виде, то на выходе получим полезные знания. Данные должны быть качественны и корректны с точки зрения используемого метода DM. Поэтому первый этап KDD заключается в предобработке данных. Более того, иногда размерность исходного пространства может быть очень большой, и тогда желательно применять специальные алгоритмы понижения размерности. Это как отбор значимых признаков, так и отображение данных в пространство меньшей размерности.
- Трансформация, нормализация данных. Этот шаг необходим для приведения информации к пригодному для последующего анализа виду. Для чего нужно проделать такие операции, как приведение типов, квантование, приведение к "скользящему окну" и прочее. Кроме того, некоторые методы анализа, которые требуют, чтобы исходные данные были в каком-то определенном виде. Нейронные сети, скажем, работают только с числовыми данными, причем они должны быть нормализованы.
- Data Mining. На этом шаге применяются различные алгоритмы для нахождения знаний. Это нейронные сети, деревья решений, алгоритмы кластеризации, установления ассоциаций и т.д.
- Постобработка данных. Интерпретация результатов и применение полученных знаний в бизнес приложениях.