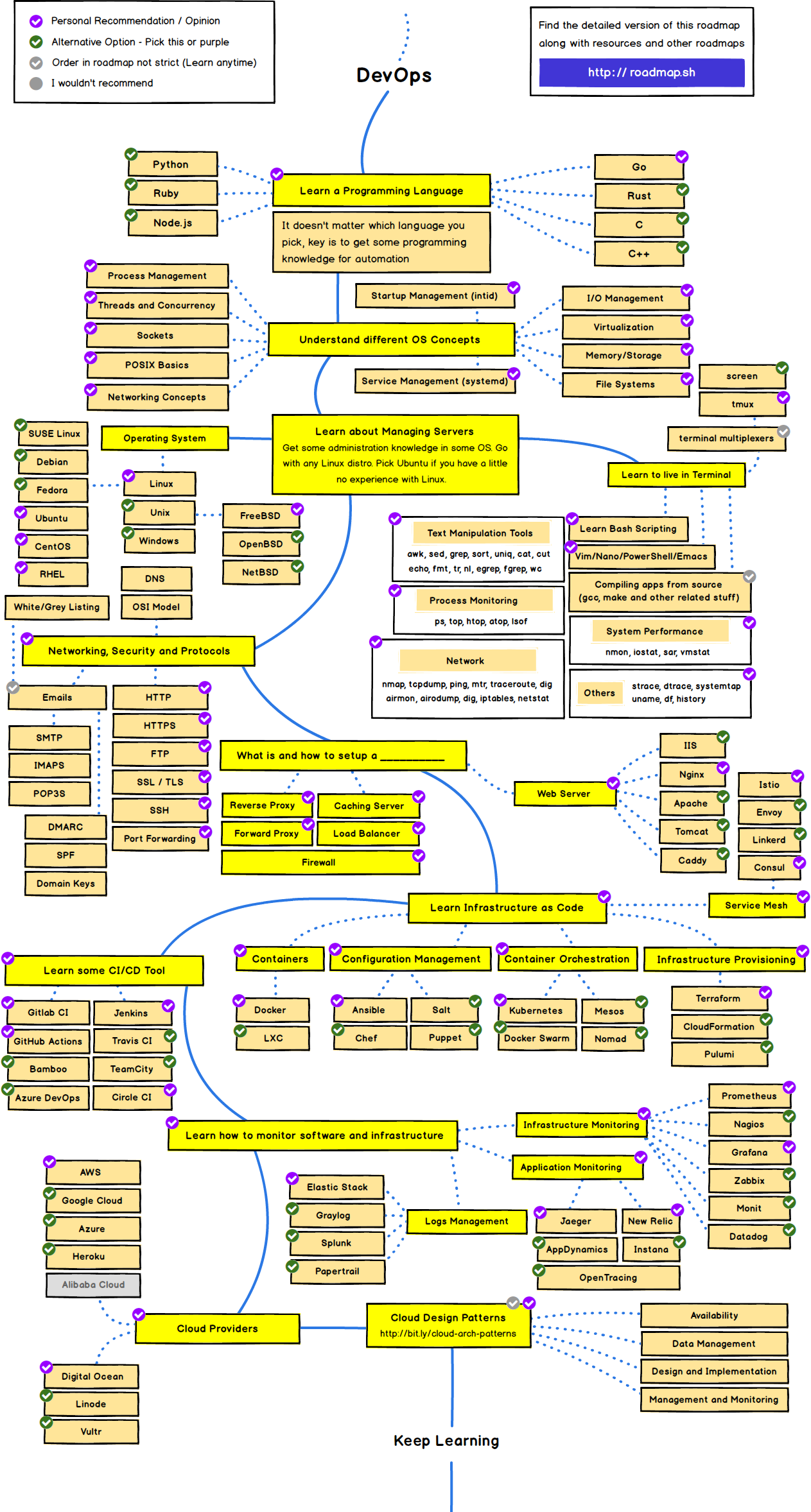
[Big data] Архитектура
Big data - это совокупность инструментов и методов структурирования параллельной/распределенной обработки, вычислений, а также хранения данных.
1) Общая схема (on-premise)
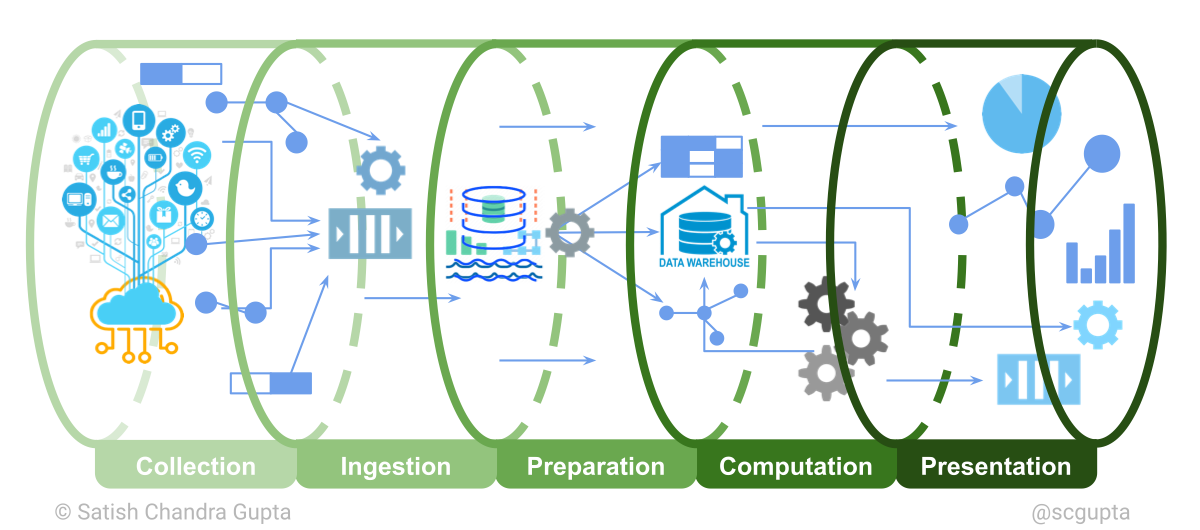
1.1) Collection(сбор): Источники данных (мобильные приложения, сайты, веб-приложения, микросервисы, IoT устройства интернет-вещей, операционные базы данных)
1.2) Ingestion(прием): Инструменты для импорта-экспопрта данных в различные источники (HTTP, MQTT, брокеры сообщений, и д.п.). Данные могут передаваться в двух формах: поток и отложенная загрузка. Все эти данные записываются в озеро данных.
1.3) Preparation(подготовка): это ряд операция по извлечению, преобразованию, загрузки данных (ETL) для очистки, преобразования и каталогизации больших двоичных объектов и потоков данных в озере данных; Подготовка данных к их использованию для машинного обучения и сохранения в хранилище данных.
1.4) Computation(вычисление): на этом этапе производится анализ данных и машинное обучение. Вычисление может быть комбинацией пакетной и потоковой обработки. Модели и аналитические данные (как структурированные данные, так и потоки) сохраняются обратно в хранилище данных.
1.5) Presentation(презентация): Информация представляется через дашборды, графики, емэйлы, SMS, пуш-уведомления, микросервисы. Выводы модели машинного обучения представляются через микросервисы.
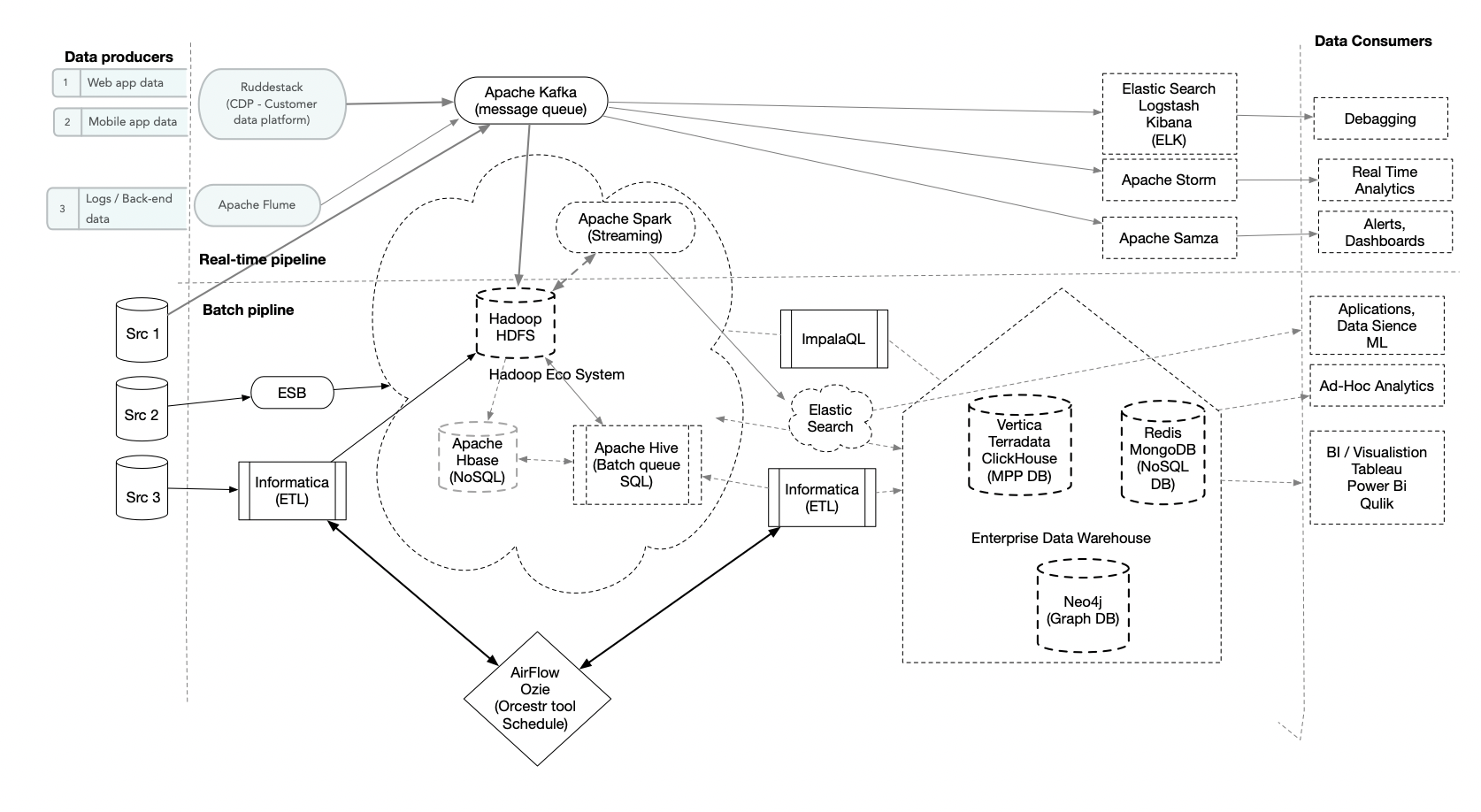
2) Шаблоны on-premise решений с технологиями
2.1) Из интернета
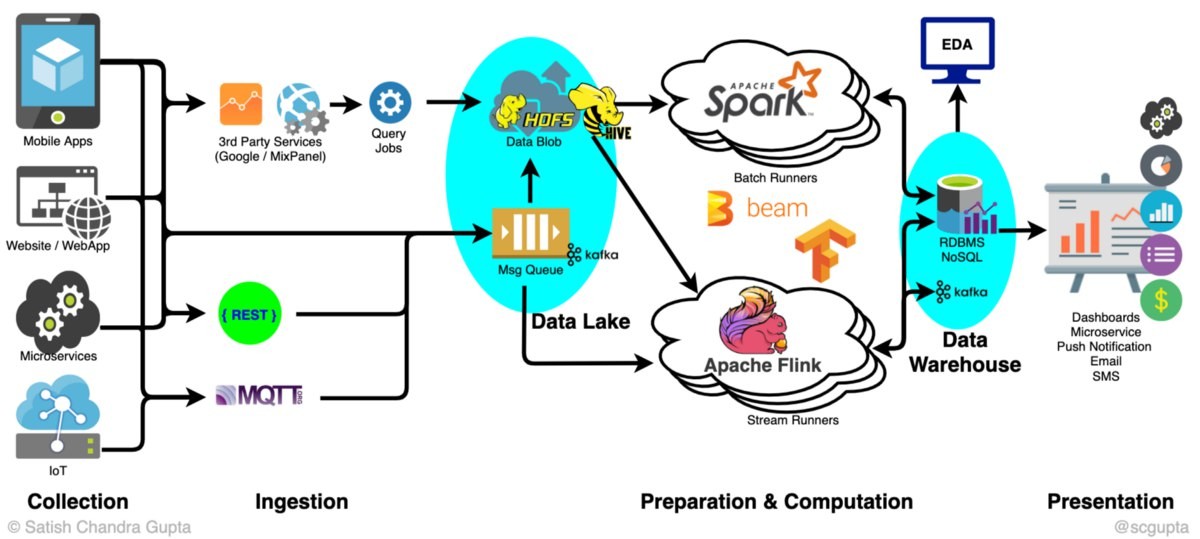
2.2) Реализация от себя
3) Шаблоны облачных решений Cloud solution
3.1) Amazon

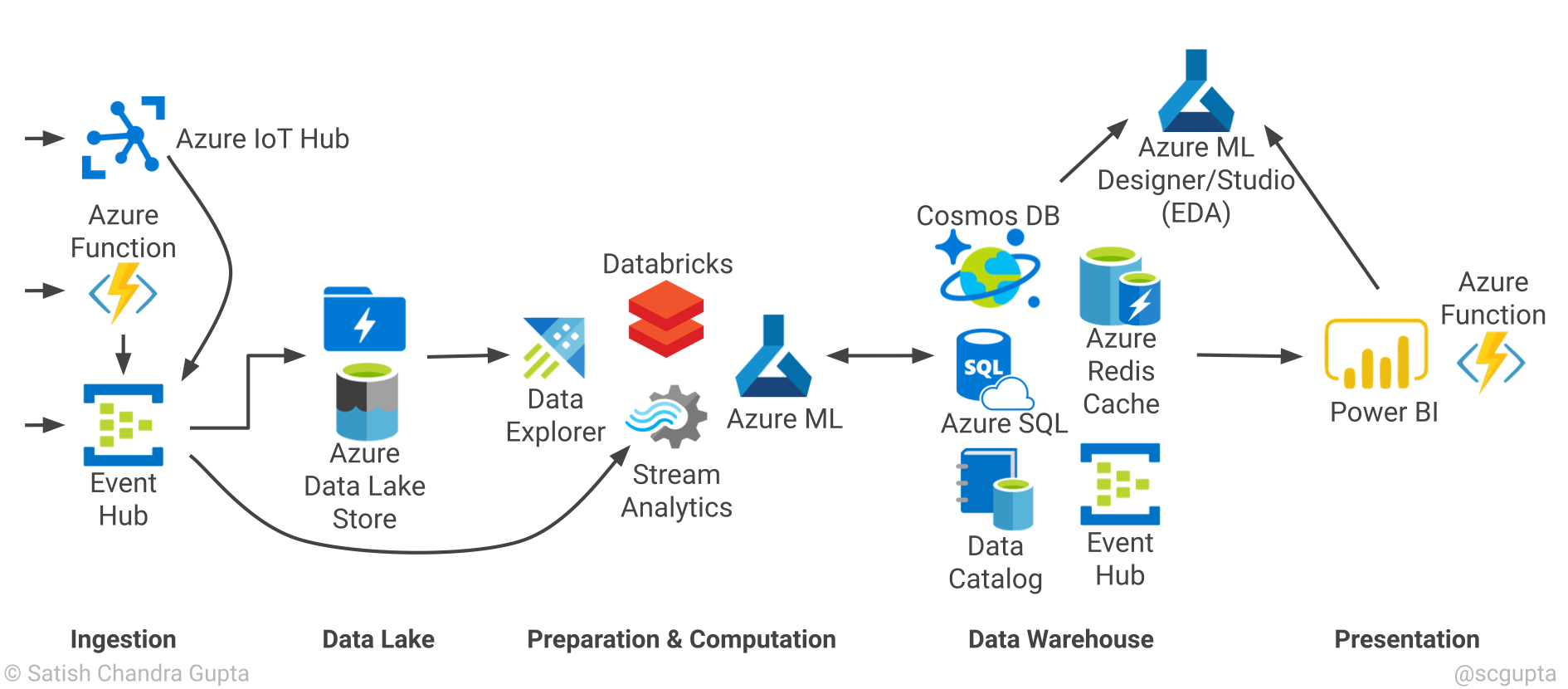
3.2) Microsoft Azure
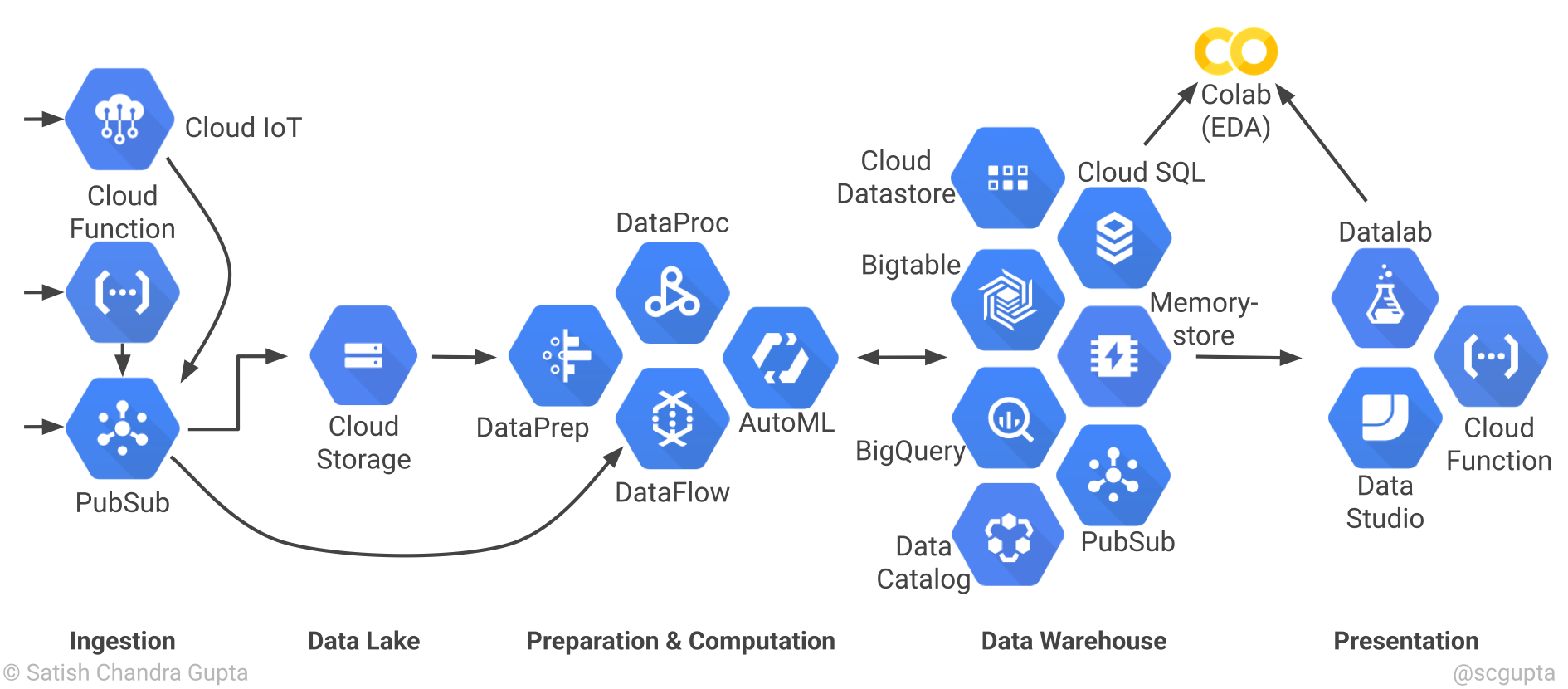
3.3) Google
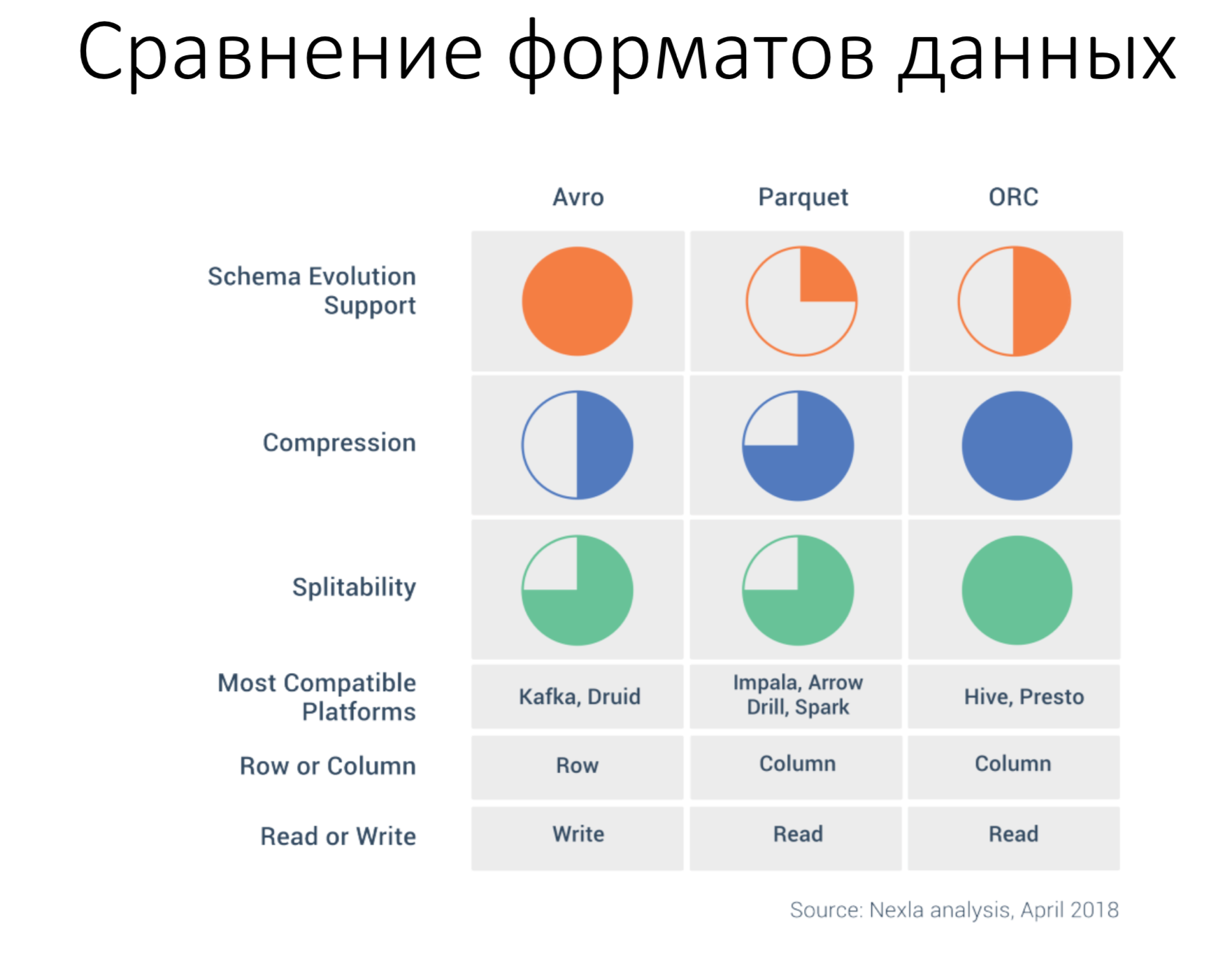
4) Форматы данных и их особенности
5) Big Data Landscape 2019

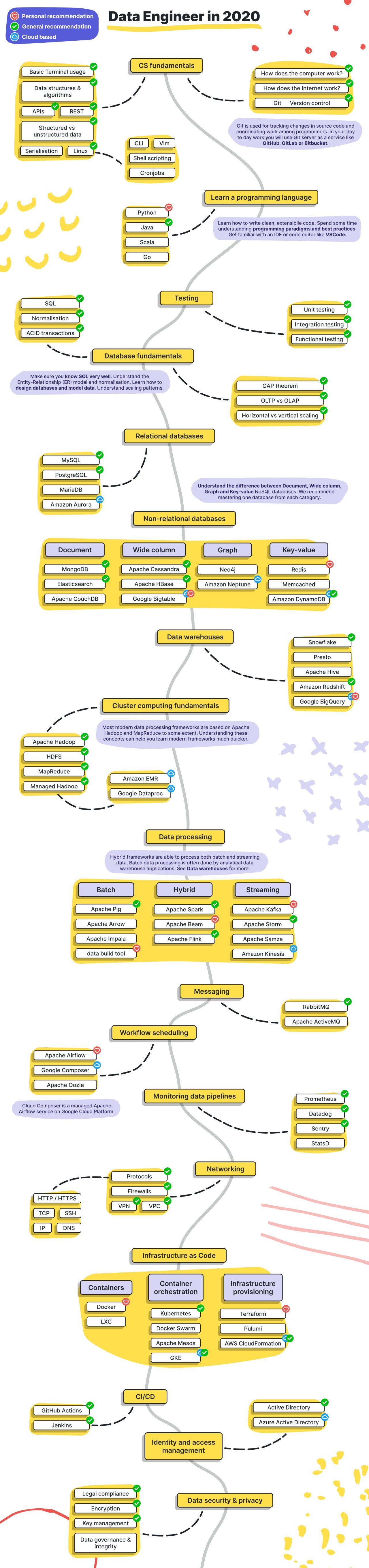
6) Дорожная карта Data Engineer
7) Дорожная карта DevOps