Как найти приложение, сильно загружающее CPU
Подписывайтесь на телеграм-канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
Известно, что нагрузка на CPU включает в себя не только выполнение процессов в пользовательском пространстве и пространстве ядра, но и обработку прерываний, ожидание ввода-вывода и потоки ядра. Поэтому, когда обнаруживается, что нагрузка на CPU системы очень высокая, вы можете не обнаружить тот самый тяжелый процесс. В этой статье разбираем эту ситуацию на примере связки Nginx и PHP.
Кейс
Для лабораторного окружения потребуются две виртуальные машины, как показано на рисунке ниже: ab(Apache Bench) — это распространённый инструмент тестирования производительности HTTP-сервисов, а также используемый для симуляции Nginx. Поскольку настройка Nginx и PHP может быть сложной, они упакованы в два образа Docker. Таким образом, запустив два контейнера, вы можете настроить среду симуляции.
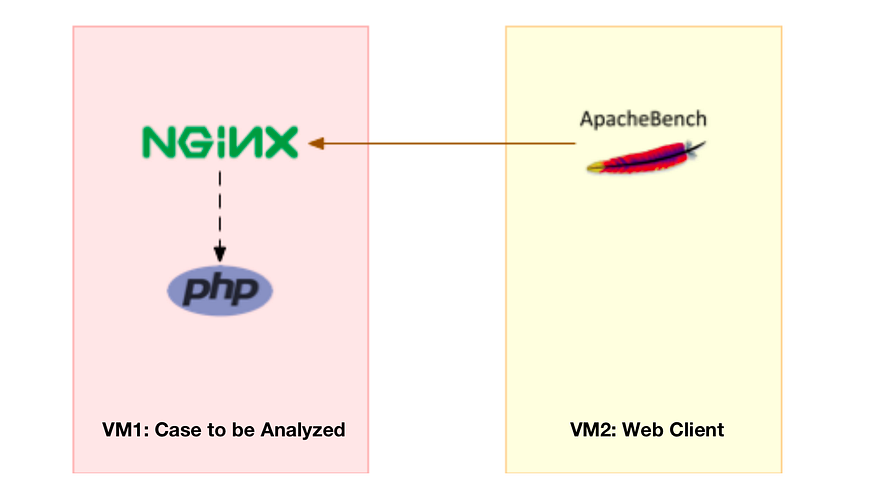
Видно, что одна машина используется как веб-сервер для имитации проблем с производительностью, а другая выступает в качестве клиента веб-сервера, создавая нагрузку на веб-сервис. Использование двух виртуальных машин обеспечивает изоляцию, предотвращая взаимное влияние.
Сначала на первом сервере выполним команду, чтобы запустить приложение Nginx и PHP:
$ docker run --name nginx -p 10000:80 -itd casestudy/nginx:sp $ docker run --name phpfpm -itd --network container:nginx casestudy/php-fpm:sp
Затем на втором сервере выполним curl для вызова http://[VM1 IP]:10000, чтобы убедиться, что Nginx работает корректно. Должен вернуться ответ с сообщением «It works!».
# 192.168.0.10 is the IP address of the first virtual machine. $ curl http://192.168.0.10:10000/ It works!
Теперь протестируем производительность сервиса Nginx. Выполним команду ab на втором сервере. Обратите внимание, что в отличие от предыдущей операции, на этот раз будет выполняться нагрузочный тест со 100 одновременными запросами и общим количеством запросов 1000, чтобы оценить производительность Nginx.
# Test Nginx performance with 100 concurrent requests and a total of 1000 requests. $ ab -c 100 -n 1000 http://192.168.0.10:10000/ This is ApacheBench, Version 2.3 <$Revision: 1706008 gt; Copyright 1996 Adam Twiss, Zeus Technology Ltd, ... Requests per second: 87.86 [#/sec] (mean) Time per request: 1138.229 [ms] (mean) ...
Из вывода abвидно, что Nginx обрабатывает в среднем чуть более 87 запросов в секунду, что может навести на мысль о его низкой производительности. Итак, в чём же именно заключается проблема? Давайте используем top и pidstat для дальнейшего изучения.
На этот раз на втором сервере установите уровень параллелизма 5 и продолжительность 10 минут ( -t 600). Таким образом, пока вы используете инструменты анализа производительности на первом сервере, Nginx по-прежнему будет находиться под нагрузкой.
Продолжайте выполнять команду ab на втором сервере:
$ ab -c 5 -t 600 http://192.168.0.10:10000/
Затем выполните команду top на первом сервере, чтобы наблюдать за нагрузкой на CPU системы:
$ top ... %Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker-containe 6947 systemd+ 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx 7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php-fpm 7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php-fpm 10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php-fpm 10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm 10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm 15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd 4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1 ...
Наблюдение за списком процессов в выводе команды top показывает, что максимальная нагрузка на CPU одним процессом составляет всего 2,7%, что не кажется очень высоким показателем.
Однако если взглянуть на строку загрузки CPU системой ( %Cpu), то можно увидеть, что общая загрузка CPU довольно высока: загрузка CPU пользователем (us) составляет 80%, системным CPU — 15,1%, а простаивающий CPU (id) — всего 2,8%.
Почему нагрузка на процессор пользователем так высока? Давайте ещё раз проанализируем список процессов на наличие подозрительных процессов:
- Процесс
docker-containerdиспользуется для запуска контейнеров, а загрузка CPU в 2,7% выглядит нормально. Nginxиphp-fpmзапускают веб-сервис, поэтому ожидается, что они используют некоторую часть ресурсов CPU, а загрузка CPU в 2% не является высокой.- При более глубоком рассмотрении видно, что оставшиеся процессы используют всего 0,3% ресурсов CPU, что, похоже, не приведет к тому, что загрузка CPU пользователем достигнет 80%.
Странно, что загрузка процессора пользователем составляет 80%, но мы просмотрели список процессов и всё ещё не нашли процессов с высокой загрузкой. Похоже, что команда top здесь не поможет. Есть ли другие инструменты для проверки загрузки процессора процессами? Помните старого друга pidstat? Его можно использовать для анализа использования CPU отдельными процессами.
Далее выполним команду pidstat на первом сервере:
# Outputs a set of data every 1 second (press Ctrl+C to stop) $ pidstat 1 ... 04:36:24 UID PID %usr %system %guest %wait %CPU CPU Command 04:36:25 0 6882 1.00 3.00 0.00 0.00 4.00 0 docker-containe 04:36:25 101 6947 1.00 2.00 0.00 1.00 3.00 1 nginx 04:36:25 1 14834 1.00 1.00 0.00 1.00 2.00 0 php-fpm 04:36:25 1 14835 1.00 1.00 0.00 1.00 2.00 0 php-fpm 04:36:25 1 14845 0.00 2.00 0.00 2.00 2.00 1 php-fpm 04:36:25 1 14855 0.00 1.00 0.00 1.00 1.00 1 php-fpm 04:36:25 1 14857 1.00 2.00 0.00 1.00 3.00 0 php-fpm 04:36:25 0 15006 0.00 1.00 0.00 0.00 1.00 0 dockerd 04:36:25 0 15801 0.00 1.00 0.00 0.00 1.00 1 pidstat 04:36:25 1 17084 1.00 0.00 0.00 2.00 1.00 0 stress 04:36:25 0 31116 0.00 1.00 0.00 0.00 1.00 0 atopacctd ...
Понаблюдав некоторое время, вы можете заметить, что загрузка процессора всеми процессами также невысока. Даже максимальная загрузка процессора Docker и Nginx составляет всего 4% и 3% соответственно, а общая загрузка процессора всеми процессами составляет всего 21%, что значительно меньше 80% загрузки процессора пользователем, которую мы наблюдали ранее.
Проблема связана с отсутствием важной информации в выводе предыдущих команд. Давайте ещё раз проанализируем вывод команды top, чтобы посмотреть, можно ли обнаружить что-то новое.
Вернемся к первому серверу, снова запустим команду top и немного понаблюдаем:
$ top top - 04:58:24 up 14 days, 15:47, 1 user, load average: 3.39, 3.82, 2.74 Tasks: 149 total, 6 running, 93 sleeping, 0 stopped, 0 zombie %Cpu(s): 77.7 us, 19.3 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st KiB Mem : 8169348 total, 2543916 free, 457976 used, 5167456 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7363908 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6947 systemd+ 20 0 33104 3764 2340 S 4.0 0.0 0:32.69 nginx 6882 root 20 0 12108 8360 3884 S 2.0 0.1 0:31.40 docker-containe 15465 daemon 20 0 336696 15256 7576 S 2.0 0.2 0:00.62 php-fpm 15466 daemon 20 0 336696 15196 7516 S 2.0 0.2 0:00.62 php-fpm 15489 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:00.62 php-fpm 6948 systemd+ 20 0 33104 3764 2340 S 1.0 0.0 0:00.95 nginx 15006 root 20 0 1168608 65632 37536 S 1.0 0.8 9:51.09 dockerd 15476 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm 15477 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm 24340 daemon 20 0 8184 1616 536 R 1.0 0.0 0:00.01 stress 24342 daemon 20 0 8196 1580 492 R 1.0 0.0 0:00.01 stress 24344 daemon 20 0 8188 1056 492 R 1.0 0.0 0:00.01 stress 24347 daemon 20 0 8184 1356 540 R 1.0 0.0 0:00.01 stress ...
На этот раз начнём с нуля и рассмотрим каждую строку вывода команды top. Строка Tasks выглядит немного странно — в состоянии «Running» находятся 6 процессов (6 running). Не многовато ли?
Учитывая параметры ab теста, уровень параллелизма равен 5. Взглянув на список процессов, можно заметить, что php-fpm тоже 5, а с учётом Nginx общее количество процессов — 6, что не кажется чем-то удивительным. Но так ли это на самом деле?
Присмотритесь внимательнее к списку процессов и обратите внимание на процессы в состоянии Running (R). Заметили, что Nginx и все процессы php-fpm находятся в состоянии «Сон» ( S), а в состоянии «Выполняется» (R) находятся несколько процессов stress? Эти процессы stress довольно необычны и требуют анализа.
Используя pidstat проанализируем эти процессы, указав идентификаторы процессов (PID) с помощью опции -p. Сначала найдем PID этих процессов в выводе команды top. Например, выберем 24344, а затем выполним команду pidstat для проверки загрузки им процессора:
$ pidstat -p 24344 16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command
Странно, вообще ничего не выводится. Может быть, pidstat работает неправильно? Как уже упоминалось ранее, прежде чем делать вывод о неисправности утилиты для измерения производительности, лучше всего провести перепроверку с помощью другого инструмента. Итак, какой инструмент использовать? ps, пожалуй, самый простой и очевидный вариант. Давайте выполним следующую команду, чтобы проверить состояние процесса 24344:
# Find the process with PID 24344 among all processes $ ps aux | grep 24344 root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep --color=auto 24344
Вывода по-прежнему нет. Теперь, наконец, понятно в чём дело: процесс больше не существует, поэтому pidstat ничего не отображает. Поскольку процесс завершён, проблема с производительностью также должна быть решена. Давайте убедимся в этом с помощью команды top:
$ top ... %Cpu(s): 80.9 us, 14.9 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 12108 8360 3884 S 2.7 0.1 0:45.63 docker-containe 6947 systemd+ 20 0 33104 3764 2340 R 2.7 0.0 0:47.79 nginx 3865 daemon 20 0 336696 15056 7376 S 2.0 0.2 0:00.15 php-fpm 6779 daemon 20 0 8184 1112 556 R 0.3 0.0 0:00.01 stress ...
Похоже, произошла ещё одна ошибка. Результаты остались прежними: загрузка пользовательского процессора по-прежнему высокая — 80,9%, системного — около 15%, а простаивающий процессор — всего 2,8%. В состоянии «Выполняется» находятся процессы Nginx, stress и другие.
Но мы только что увидели, что процесса stress больше не существует. Как же он вообще может работать? При более внимательном рассмотрении вывода top выясняется, что на этот раз у процесса stress другой PID: старый PID 24344 исчез, и теперь он равен 6779.
Что означает изменение PID процесса? На мой взгляд, это предполагает два варианта: либо эти процессы постоянно перезапускаются, либо это совершенно новые процессы. Есть две основные причины:
- Процессы могут постоянно прерываться и перезапускаться, например, из-за ошибок сегментации или конфигурации. В этом случае система может автоматически перезапускать процесс после его завершения.
- Эти процессы являются кратковременными, то есть представляют собой внешние команды, вызываемые другими приложениями через
exec. Эти команды обычно выполняются очень короткое время, а затем завершаются, что затрудняет их отслеживание с помощью таких инструментов, какtop, у которого слишком большой интервал между обновлениями(что мы и сделали в предыдущем случае).
Что касается stress, как уже упоминалось, это распространённый инструмент для стресс-тестирования. Его PID постоянно меняется, что похоже на кратковременные процессы, вызываемые другими процессами. Для продолжения анализа нужно найти родительский процесс.
Итак, как найти родительский процесс для процесса? Всё верно, можно использовать pstree для отображения взаимосвязей между процессами в древовидной структуре:
$ pstree | grep stress
|-docker-containe-+-php-fpm-+-php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]Отсюда видно, что stress — дочерний процесс, вызванный приложением php-fpm, и запущено несколько процессов stress (в данном случае их три). После того, как мы нашли родительский процесс, мы можем перейти к внутреннему устройству приложения для дальнейшего анализа.
Сначала необходимо проверить его исходный код. Выполните следующую команду, чтобы скопировать исходный код примера приложения в каталог app, а затем используем grep для поиска кода, который может вызывать команду stress:
# Copy the Source Code Locally
$ docker cp phpfpm:/app .
# Search for Code that Calls the stress Command Using grep
$ grep stress -r app
app/index.php:// fake I/O with stress (via write()/unlink()).
app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);Команда stress действительно вызывается напрямую в файле app/index.php.
Давайте посмотрим на исходный код app/index.php:
$ cat app/index.php
<?php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
?>В исходном коде видно, что команда stress вызывается для каждого запроса, чтобы имитировать нагрузку на операции ввода-вывода. Согласно комментариям, stress использует write() и unlink() для создания нагрузки на операции ввода-вывода, что, вероятно, является основной причиной повышенной нагрузки на CPU.
Однако stress создает нагрузку на систему ввода-вывода, тогда как в выводе команды top мы наблюдали повышение загрузки как пользовательского, так и системного CPU, но при этом не было увеличения показателя iowait. Что здесь происходит? Действительно ли stress является причиной повышенной загрузки CPU?
Необходимо дальнейшее расследование. Из кода видно, что добавление параметра verbose=1 к запросу позволит просмотреть вывод stress. Попробуйте выполнить следующую команду на втором сервере:
$ curl http://192.168.0.10:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [19607] (394) <-- worker 19608 returned error 1
[3] => stress: WARN: [19607] (396) now reaping child worker processes
[4] => stress: FAIL: [19607] (400) kill error: No such process
[5] => stress: FAIL: [19607] (451) failed run completed in 0s
)Из сообщения об ошибке mkstemp failed: Permission denied и failed run completed in 0s следует, что команда stress не была выполнена из-за проблем с правами доступа и завершилась с ошибкой. Это указывает на ошибку в PHP-коде, где команда пытается вызвать stress, но не создаёт временные файлы из-за недостаточных прав доступа.
Из этого можно сделать вывод, что высокая загрузка CPU пользователем была вызвана тем, что процессы stress не смогли инициализироваться из-за ошибок прав доступа.
Выявив проблему, следует ли приступать к оптимизации?
Пока рано! Поскольку это всего лишь гипотеза, нужно подтвердить, действительно ли проблема с выполнением stress была вызвана большим количеством процессов. Какие инструменты или метрики можно использовать для этого?
Ранее мы использовали такие инструменты, как top, pidstat и pstree, но не обнаружили большого количества процессов stress.
perf — это инструмент для анализа событий производительности процессора, подходящий для данной ситуации. Выполним команду perf record -g на первом сервере и подождем некоторое время (например, 15 секунд), прежде чем нажать кнопку Ctrl+C для выхода. Затем запустим perf report, чтобы просмотреть отчёт.
# Record Performance Events, Wait for About 15 Seconds, and Then Press Ctrl+C to Exit $ perf record -g # View the Report $ perf report
Таким образом, вы можете увидеть отчет об эффективности, показанный на рисунке ниже:
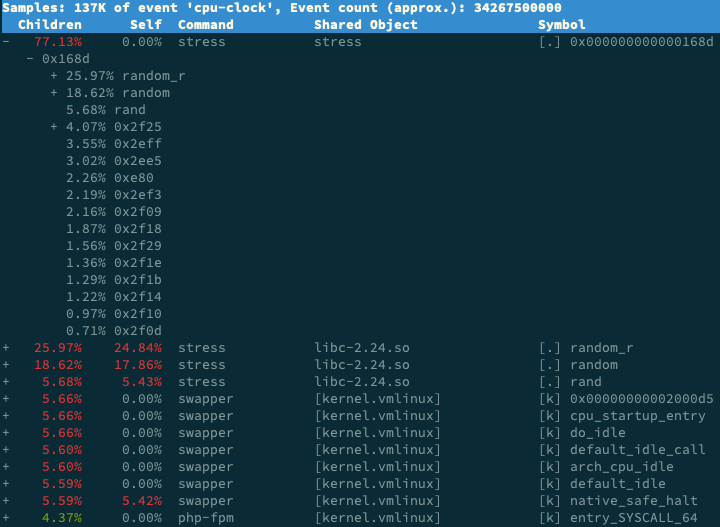
stress занимает 77% всех событий, и в его стеке вызовов функция random() выделяется больше остальных. Похоже, она действительно является основным виновником повышенной загрузки процессора. После этого анализа оптимизация становится простой: устранение проблемы с правами доступа и сокращение или полное прекращение вызовов stress снизят нагрузку на процессор.
Конечно, реальные боевые проблемы часто сложнее, чем в данном случае. Определив команду, вызывающую узкое место, вы можете обнаружить, что её вызов является неотъемлемой частью базовой логики приложения и не может быть легко облегчён или удалён.
На этом этапе необходимо провести дальнейшее расследование, чтобы понять, почему вызванная команда вызывает такие проблемы, как высокая загрузка CPU или увеличение объема ввода-вывода.
execsnoop
В случае выше использовались такие инструменты, как top, pidstat и pstree для анализа проблемы высокой загрузки процессора в системе и обнаружили, что повышенная загрузка процессора была вызвана короткоживущими процессами stress. Однако, процесс анализа был довольно сложным. Существуют ли более эффективные методы мониторинга таких проблем?
execsnoop — это инструмент, специально разработанный для мониторинга кратковременных процессов. Он использует ftrace для отслеживания вызовов exec() в режиме реального времени и выводит базовую информацию о кратковременных процессах, включая PID процесса, PID родительского процесса, аргументы командной строки и результаты выполнения.
Например, при использовании execsnoop для мониторинга случая, описанного выше, будет напрямую предоставлен родительский PID процессов и аргументы командной строки, в т.ч. для команд stress и их аргументы командной строки. Вы можете наблюдать, как создаются многочисленные процессы stress непрерывно:
# Press Ctrl+C to Stop $ execsnoop PCOMM PID PPID RET ARGS sh 30394 30393 0 stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1 sh 30398 30393 0 stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1 sh 30402 30400 0 stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1 sh 30405 30393 0 stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1 ...
execsnoop использует ftrace, широко распространенную технологию динамической трассировки, обычно применяемую для анализа поведения ядра Linux во время выполнения.
Заключение
При возникновении необъяснимых и необычных ситуаций, связанных с загрузкой CPU, следует в первую очередь учитывать, что причиной проблемы могут быть кратковременные процессы. Это может быть вызвано двумя причинами:
- Приложение напрямую вызывает другие бинарные программы , которые обычно недолговечны и не могут быть легко обнаружены с помощью таких инструментов, как
top. - Само приложение постоянно вылетает и перезапускается, а инициализация ресурсов во время процесса запуска может потреблять значительную часть ресурсов CPU.
Для таких типов процессов можно использовать pstree или execsnoop, чтобы найти их родительские процессы, а затем исследовать основную причину проблемы в родительском приложении.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.