Как ограничить использование CPU контейнером
В системе Linux две основные концепции для контейнеров — это Namespace и Cgroups. Ресурсы можно разделить на множество типов, таких как CPU, память, диск, сеть и т. д. Среди них вычислительные ресурсы являются самым базовым типом ресурсов, и всем контейнерам они необходимы. В этой статье мы обсудим, как ограничить использование CPU контейнером.
Подписывайтесь на канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
Взяв в качестве примера платформу Kubernetes, давайте рассмотрим определение спецификации в pod/контейнере ниже. В определении, связанном с ресурсами CPU, есть два элемента: Request CPU и Request CPU.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
env:
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "128Mi"
cpu: "2"Значения Request CPU и Request CPU в спецификации Pod будут контролировать ресурсы CPU контейнера через конфигурацию Cgroup CPU.
Далее рассмотрим использование CPU процессами, а затем посмотрим как создать несколько контрольных групп в подсистеме CPU Cgroup. Используя этот пример, поговорим про три самых важных параметра в CPU Cgroup: cpu.cfs_quota_us, cpu.cfs_period_us и cpu.shares.
Как понять загрузку CPU и CPU Cgroup?
Поскольку необходимо понять смысл CPU Cgroup, необходимо сначала рассмотреть концепцию использования CPU в Linux, поскольку основной целью CPU Cgroup является ограничение использования CPU.
Классификация использования CPU
Наиболее часто используемый метод проверки утилизации CPU — это запуск `top`. Глядя на вывод top на скриншоте ниже, на третьей строке, начинающейся с «%Cpu(s)», вы видите строку значений, например «0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st». Что же означает каждое значение в этой строке?
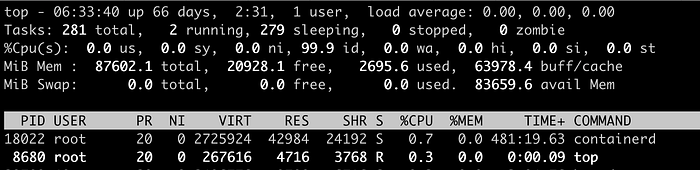
На изображении ниже горизонтальную ось будем рассматривать как временную шкалу. Её верхняя половина представляет собой пользовательское пространство Linux, а нижняя половина — пространство ядра. Для простоты понимания предположим, что есть только один CPU.
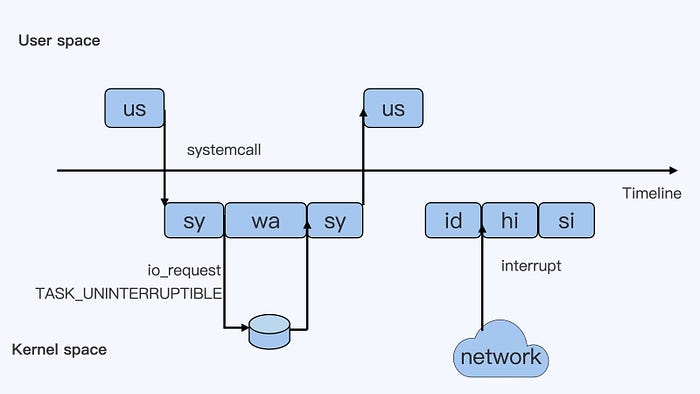
Предположим, что пользовательская программа начинает работать, что соответствует первому полю «us». «us» означает «user» и представляет использование процессора в пользовательском пространстве Linux. В обычном коде пользовательской программы, пока он не делает системный вызов, инструкции процессора, выполняемые этим кодом, принадлежат «us».
Когда этот код пользовательской программы делает системный вызов, такой как `read()`, чтобы прочитать файл, пользовательский процесс переключается из пользовательского пространства в пространство ядра. В пространстве ядра системный вызов `read()` выполняет некоторые операции на уровне файловой системы перед фактическим чтением файла с диска. Инструкции CPU, выполняемые во время этих операций, принадлежат «sy», что соответствует второму полю на изображении. «sy» означает «system» и представляет собой использование CPU в пространстве ядра.
Затем системный вызов `read()` отправляет запрос ввода-вывода на Linux Block Layer, запуская фактическую операцию чтения с диска. На этом этапе процесс обычно устанавливается в TASK_UNINTERRUPTIBLE. Linux отмечает это время как «wa», что соответствует третьему полю на изображении. «wa» означает «iowait» и представляет собой время ожидания ввода-вывода, где ввод-вывод относится к дисковому вводу-выводу.
Вскоре после этого, когда диск возвращает данные, процесс получает данные в пространстве ядра, которые по-прежнему являются частью использования CPU в пространстве ядра, «sy», что соответствует четвертому полю на изображении.
Наконец, процесс переключается обратно в пользовательское пространство и получает данные файла в пользовательском пространстве. Это соответствует процессу, возвращающемуся в пользовательское пространство CPU usage, «us», которое представлено пятым полем на изображении.
Предположим, что после считывания данных пользовательский процесс переходит в спящий режим, поскольку ему больше нечего делать. Кроме того, предположим, что в этот момент нет других процессов, которым нужно работать на этом процессоре. Затем система перейдет в состояние «id», которое является шестым полем. «id» означает «idle» и представляет собой систему, находящуюся в состоянии простоя.
Если в этот момент сервер получит сетевой пакет данных, сетевая карта сгенерирует прерывание. Соответственно, CPU отреагирует на прерывание и войдет в процедуру обслуживания прерывания.
В этот момент CPU перейдет в состояние «hi», которое является седьмым полем. «hi» означает «hardware irq» и представляет собой CPU, обрабатывающий накладные расходы аппаратных прерываний. Поскольку процедура обслуживания прерываний должна отключать прерывания, время аппаратного прерывания не может быть слишком долгим.
Однако, работа после прерывания должна быть завершена. Если эта работа занимает много времени, что можно сделать? В Linux есть концепция программных прерываний (softirq), которая может справиться с этими трудоемкими задачами.
Можно считать это программное прерывание обработкой большей части работы по получению пакетов данных от сетевой карты. Затем CPU войдет в восьмой блок, «si». Здесь «si» означает «softirq» и представляет собой CPU, обрабатывающий накладные расходы программных прерываний.
Важно отметить, что ни «hi», ни «si» не влияют на время CPU какого-либо процесса. Это потому, что они не принадлежат ни одному процессу, пока обрабатываются.
Есть еще два типа использования CPU, о которых мы не говорили:
- Один из них — «ni», что означает «nice». Если процесс имеет положительное значение nice (1–19), это указывает на использование CPU процессом, работающим с более низким приоритетом.
- Другой — «st», что означает «steal» (украдка). «st» — это тип использования CPU, используемый в виртуальных машинах, указывающий, сколько времени забирают другие виртуальные машины на том же хосте.
Cgroups используются для ограничения использования ресурсов компьютера для определенных процессов. CPU Cgroup — это одна из подсистем Cgroups, используемая для ограничения использования процессора процессами.
Что касается использования CPU процессами, то оно состоит из двух частей: пользовательского пространства, которое включает us и ni, и пространства ядра, которое представляет собой sy.
Что касается wa, hi и si, которые связаны с вводом/выводом или прерываниями, CPU Cgroup их не ограничивает. Давайте теперь посмотрим, как работает CPU Cgroup.
Каждая подсистема Cgroups монтируется в каталог по умолчанию с использованием точки монтирования виртуальной файловой системы. CPU Cgroup обычно находится в каталоге /sys/fs/cgroup/cpu в дистрибутивах Linux.
В этом каталоге подсистемы каждая контрольная группа (cgroup) является подкаталогом, а отношения между этими cgroups образуют иерархическую древовидную структуру.
Например, начиная с верхнего уровня подсистемы, мы создаем две контрольные группы (т.е. два каталога) group1 и group2. Затем мы создаем еще две контрольные группы group3 и group4 под group2.
После этих операций мы создали иерархическую древовидную структуру контрольных групп. См. иллюстрацию ниже.
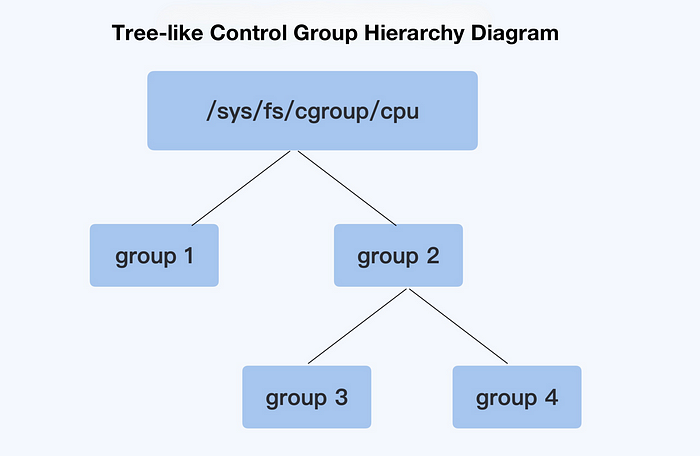
Итак, какая информация управления CPU Cgroup-related у нас есть в каждой контрольной группе? Здесь нам нужно посмотреть содержимое каждого каталога контрольной группы:
$ pwd /sys/fs/cgroup/cpu $ mkdir group1 group2 $ cd group2 $ mkdir group3 group4 $ cd group3 $ ls cpu.* cpu.cfs_period_us cpu.cfs_quota_us cpu.rt_period_us cpu.rt_runtime_us cpu.shares cpu.stat
Учитывая, что большинство программ на облачных платформах не являются запланированными процессами в реальном времени, а скорее обычными запланированными процессами (SCHED_NORMAL), нормальным алгоритмом планирования в Linux является CFS (Completely Fair Scheduler). Чтобы помочь понять что это за зверь такой, давайте рассмотрим параметры, связанные с CPU Cgroup и CFS, всего их три.
Первый параметр — cpu.cfs_period_us, который является периодом планирования алгоритма CFS. Обычно его значение равно 100000 в микросекундах, что составляет 100 мс.
Второй параметр — cpu.cfs_quota_us, который представляет собой количество времени, в течение которого этой контрольной группе разрешено работать в одном периоде планирования в алгоритме CFS. Например, когда это значение равно 50000, это означает 50 мс. Если разделить это значение на период планирования (cpu.cfs_period_us), 50 мс/100 мс = 0,5, таким образом, максимальная квота CPU, разрешенная для использования этой контрольной группой, составляет 0,5 CPU.
Из этого видно, что cpu.cfs_quota_us — это абсолютное значение. Если это значение равно 200000, что составляет 200 мс, то, разделив на период, 200 мс/100 мс=2 мы получим, что результат превышает 1 CPU. А это означает, что в это время контрольной группе нужна квота ресурсов в 2 CPU.
Давайте рассмотрим третий параметр — cpu.shares. Это значение — коэффициент распределения CPU Cgroup между контрольными группами, значение по умолчанию — 1024.
Предположим, в нашем предыдущем примере cpu.shares в group3 равен 1024, а в group4 — 3072. Это означает, что соотношение group3 к group4 составляет 1:3.
Что означает это соотношение? Давайте проиллюстрируем на конкретном примере. На машине с 4 CPU, когда и group3, и group4 требуют 4 CPU, фактическое распределение CPU будет следующим: group3 получает 1 CPU, а group4 получает 3 CPU.
Мы только что обсудили три ключевых параметра в CPU Cgroup. Далее воспользуемся несколькими примерами, чтобы лучше их понять.
В первом примере мы запускаем программу с именем `threads-cpu`, которая потребляет 2 CPU (200%), а затем добавляем PID этой программы в контрольную группу group3:
./threads-cpu/threads-cpu 2 & echo $! > /sys/fs/cgroup/cpu/group2/group3/cgroup.procs
Прежде чем изменить `cpu.cfs_quota_us`, заметим, что процесс `threads-cpu` использует 199% CPU, что составляет примерно 2 CPU, если смотреть с помощью команды `top`.

Затем обновляем `cpu.cfs_quota_us` в этой контрольной группе до 150000 (150 мс). Разделив это значение на `cpu.cfs_period_us`, мы получаем 150 мс/100 мс = 1,5, что эквивалентно 1,5 CPU. Кроме того, мы устанавливаем `cpu.shares` на 1024.
echo 150000 > /sys/fs/cgroup/cpu/group2/group3/cpu.cfs_quota_us echo 1024 > /sys/fs/cgroup/cpu/group2/group3/cpu.shares
На этом этапе, когда снова запустим `top`, увидим, что использование CPU процессом `threads-cpu` снизилось до 150%. Это связано с тем, что установленный `cpu.cfs_quota_us` вступил в силу, ограничив абсолютное использование CPU процессом.
Однако параметр `cpu.shares` еще не вступил в силу. Это связано с тем, что `cpu.shares` — это соотношение распределения ЦП между различными контрольными группами, и оно начинает работать только тогда, когда все CPU на всем сервере работают на полную мощность.

Давайте теперь запустим второй пример, чтобы понять `cpu.shares`. Сначала запустим программу из первого примера, а затем установим `cpu.cfs_quota_us` и `cpu.shares` для `group3`, как делали раньше. После настройки `group3`, запустим вторую программу и установим `cpu.cfs_quota_us` и `cpu.shares` для `group4`.
./threads-cpu/threads-cpu 2 & # запуск программы, которая использует 2 CPU echo $! > /sys/fs/cgroup/cpu/group2/group3/cgroup.procs # добавление PID процесса в control group echo 150000 > /sys/fs/cgroup/cpu/group2/group3/cpu.cfs_quota_us # ограничение CPU в 1.5 CPUs echo 1024 > /sys/fs/cgroup/cpu/group2/group3/cpu.shares
./threads-cpu/threads-cpu 4 & # апуск программы, которая использует 4 CPU echo $! > /sys/fs/cgroup/cpu/group2/group4/cgroup.procs # добавление PID процесса в control group echo 350000 > /sys/fs/cgroup/cpu/group2/group4/cpu.cfs_quota_us # ограничение CPU в 3.5 CPU echo 3072 > /sys/fs/cgroup/cpu/group2/group3/cpu.shares # соотношение group4 к group3 равно 3:1
У нас есть всего 4 CPU на сервере, где программе в group3 нужно 2 CPU, а программе в group4 нужно 4 CPU. Несмотря на то, что cpu.cfs_quota_us ограничил абсолютное значение использования CPU для каждого процесса (1,5 CPU для group3 и 3,5 CPU для group4, что в сумме составляет 5 CPU, что превышает 4 CPU на сервере), в этом сценарии наконец-то вступает в игру cpu.shares.
При соотношении долей group4:group3=3:1 на сервере с общим количеством 4 CPU процессам group4 должно быть выделено 3 CPU, а процессам group3 будет выделено 1 CPU. Можно проверить это, используя команду `top`.
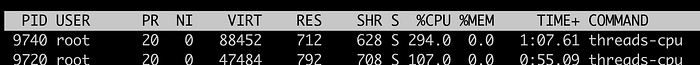
Ниже приведена сводка параметров CPU Cgroup:
- `cpu.cfs_quota_us` и `cpu.cfs_period_us` определяют максимальные ресурсы CPU, доступные всем процессам в каждой контрольной группе.
- `cpu.shares` определяет относительную долю ресурсов CPU, доступных каждой контрольной группе в подсистеме CPU Cgroup. Однако эта пропорция вступает в силу только тогда, когда CPU полностью используются в системе.
Объяснение феномена
После объяснения основных концепций использования CPU в Linux и Cgroup CPU давайте вернемся к первоначальному вопросу «как ограничить использование CPU контейнером». Когда фундамент заложен, этот вопрос становится проще объяснить.
Сначала Kubernetes создает контрольную группу (Cgroup) в подсистеме CPU Cgroup для каждого контейнера и назначает процессы контейнера этой контрольной группе.
На этом этапе Limit CPU необходимо установить верхний предел доступного CPU для контейнера. Объединив параметры, которые мы обсуждали ранее, мы можем определить, как рассчитывается предел CPU контейнера.
Ограничение CPU контейнера определяется путем деления cpu.cfs_quota_us на cpu.cfs_period_us. Более того, в операционной системе значение cpu.cfs_period_us обычно является фиксированным значением, которое Kubernetes не изменяет. Поэтому изменяем только cpu.cfs_quota_us.
С другой стороны, Request CPU — это количество ресурсов CPU, которые контейнер может гарантированно получить независимо от того, сколько ресурсов CPU запросили другие контейнеры, даже если весь CPU сервера полностью занят. Итак, как этого добиться?
Очевидно, нужно задать параметр cpu.shares: в Cgroup CPU cpu.shares == 1024 представляет долю 1 CPU. Таким образом, значение для Request CPU будет «n», а соответствующее назначение cpu.shares будет «n*1024».
Заключение
На самом деле, первоначальный вопрос, который мы задали, «как ограничить использование CPU контейнера», скрывает другой вопрос: как контейнеры устанавливают значения параметров в своей CPU Cgroup? Чтобы решить этот вопрос, нужно знать параметры CPU Cgroup. Поэтому я подробно описал основные параметры CPU Cgroup, включая эти три: cpu.cfs_quota_us, cpu.cfs_period_us и cpu.shares.
Среди них cpu.cfs_quota_us (разрешенное время выполнения для этой контрольной группы в период планирования), деленное на cpu.cfs_period_us (используется для установки периода планирования), определяет верхний предел использования CPU в каждой контрольной группе CPU Cgroup.
Также необходимо понимать параметр cpu.shares, который определяет относительную долю доступных CPU в подсистеме CPU Cgroup среди контрольных групп. Эта пропорция вступает в силу только тогда, когда CPU в системе полностью заняты.
Наконец, после понимания значения ключевых параметров CPU Cgroup, становится легко объяснить Limit CPU и Request CPU в Kubernetes: Limit CPU — это верхнее предельное значение CPU в контрольной группе Cgroup контейнера, а значение Request CPU — это значение cpu.shares в контрольной группе.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.