Устранение неполадок производительности NAT в Linux
Это перевод оригинальной статьи.
Технология NAT позволяет переопределять IP-адреса источника или назначения IP-пакетов, что делает её распространённой для решения проблемы нехватки публичных IP-адресов. Она позволяет нескольким хостам в сети получать доступ к внешним ресурсам через общий публичный IP-адрес. Кроме того, NAT обеспечивает безопасную изоляцию устройств в локальной сети, экранируя внутреннюю сеть.
Подписывайтесь на телеграм-канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
NAT в Linux реализован на основе модуля отслеживания соединений ядра. Таким образом, сохраняя состояние каждого соединения, он также оказывает определённое влияние на производительность сети. А что делать при возникновении проблем с производительностью NAT?
В этой статье несколько примеров подхода к анализу проблем производительности NAT.

Подготовка
Кейс основан на Ubuntu 18.04, но применим также к другим системам Linux. Ниже приведена конфигурация тестовой среды:
- Конфигурация машины: 2 CPU, 8 ГБ ОЗУ.
- Предустановленные инструменты: docker, tcpdump, curl, ab, SystemTap и т. д.
# Ubuntu $ apt-get install -y docker.io tcpdump curl apache2-utils # CentOS $ curl -fsSL https://get.docker.com | sh $ yum install -y tcpdump curl httpd-tools
SystemTap — это фреймворк динамической трассировки для Linux. Он преобразует пользовательские скрипты в исполняемые модули ядра, которые используются для мониторинга и трассировки поведения ядра. Установка производится следующим образом:
# Ubuntu apt-get install -y systemtap-runtime systemtap # Configure ddebs source echo "deb http://ddebs.ubuntu.com $(lsb_release -cs) main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-updates main restricted universe multiverse deb http://ddebs.ubuntu.com $(lsb_release -cs)-proposed main restricted universe multiverse" | \ sudo tee -a /etc/apt/sources.list.d/ddebs.list # Install dbgsym apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F2EDC64DC5AEE1F6B9C621F0C8CAB6595FDFF622 apt-get update apt install ubuntu-dbgsym-keyring stap-prep apt-get install linux-image-`uname -r`-dbgsym # CentOS yum install systemtap kernel-devel yum-utils kernel stab-prep
Для тестов мы будем использовать Nginx и клиент ab (ApacheBench). Будет задействовано две виртуальных машины. Ниже диаграмма, чтобы представить всё визуально.
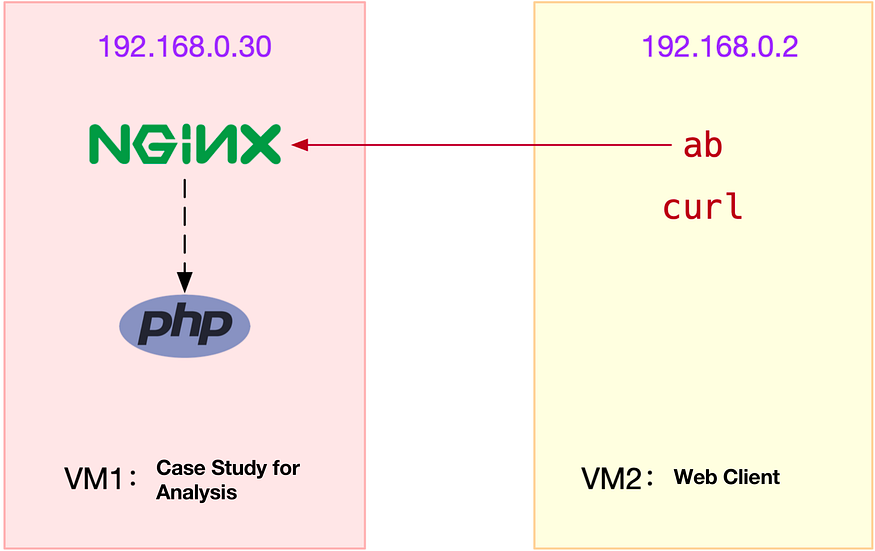
Затем открываем два терминала и подключаемся по SSH к каждой из машин по отдельности (в дальнейших шагах предполагается, что номера терминалов соответствуют номерам виртуальных машин на схеме) и устанавливаем упомянутые выше инструменты. Обратите внимание, что curl и ab нужно установить только на клиентской виртуальной машине (т.е. VM2).
Анализ
Чтобы сравнить проблемы с производительностью, вызванные NAT, мы сначала запустим службу Nginx без использования NAT и протестируем ее производительность с помощью ab.
В терминале 1 выполните следующую команду для запуска Nginx. Обратите внимание на опцию --network=host, которая указывает, что контейнер использует сетевой режим Host, то есть NAT не используется:
$docker run --name nginx-hostnet --privileged --network=host -itd casestudy/nginx:80
В терминале 2 выполните команду ab для проведения стресс-теста Nginx. Однако перед тестированием учтите, что ограничение Linux по умолчанию на количество открытых файловых дескрипторов относительно невелико. Например, на моём компьютере это значение составляет всего 1024:
# open files $ ulimit -n 1024
Итак, перед запуском ab необходимо увеличить этот лимит, например, до 65536:
$ ulimit -n 65536
Далее выполните командуab для проведения стресс-теста:
# -c represents the number of concurrent requests as 5000, and -n represents the total number of requests as 100,000.
# -r means continue the test even in the face of socket receive errors, and -s means set the timeout for each request to 2 seconds.
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30/
...
Requests per second: 6576.21 [#/sec] (mean)
Time per request: 760.317 [ms] (mean)
Time per request: 0.152 [ms] (mean, across all concurrent requests)
Transfer rate: 5390.19 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 177 714.3 9 7338
Processing: 0 27 39.8 19 961
Waiting: 0 23 39.5 16 951
Total: 1 204 716.3 28 7349
...Из этого вывода вы можете видеть, что:
Затем вернитесь к терминалу 1 и запустите приложение-пример. Приложение-пример прослушивает порт 8080 и использует DNAT для сопоставления порта 8080 на хосте с портом 8080 на контейнере:
$ docker run --name nginx --privileged -p 8080:8080 -itd casestudy/nginx:nat
После запуска Nginx вы можете выполнить iptables команду, чтобы подтвердить создание правила DNAT:
$ iptables -nL -t nat Chain PREROUTING (policy ACCEPT) target prot opt source destination DOCKER all -- 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL ... Chain DOCKER (2 references) target prot opt source destination RETURN all -- 0.0.0.0/0 0.0.0.0/0 DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:8080 to:172.17.0.2:8080
Видно, что в цепочке PREROUTING локальные запросы перенаправляются в цепочку DOCKER. В цепочке DOCKER TCP-запросы с портом назначения 8080 перенаправляются с помощью DNAT на порт 8080 сервера 172.17.0.2. Здесь 172.17.0.2 — это IP-адрес контейнера Nginx.
Затем выполните команду ab еще раз, но на этот раз измените номер порта в запросе на 8080:
# -c represents the number of concurrent requests as 5000, and -n represents the total number of requests as 100,000. # -r means continue the test even in the face of socket receive errors, and -s means set the timeout for each request to 2 seconds. $ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/ ... apr_pollset_poll: The timeout specified has expired (70007) Total of 5602 requests completed
Действительно, команда ab, которая ранее выполнялась успешно, теперь завершается сбоем и выдаёт ошибку тайм-аута соединения. Параметр, -s используемый ab устанавливает тайм-аут для каждого запроса в 2 секунды. Однако из вывода видно, что на этот раз было выполнено только 5602 запроса.
Поскольку мы запускаем ab тест для получения результатов, попробуем увеличить тайм-аут, например, до 30 секунд. Более длительный тайм-аут означает более длительное ожидание. Чтобы получить результаты быстрее, давайте также уменьшим общее количество итераций теста до 10 000:
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
...
Requests per second: 76.47 [#/sec] (mean)
Time per request: 65380.868 [ms] (mean)
Time per request: 13.076 [ms] (mean, across all concurrent requests)
Transfer rate: 44.79 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 1300 5578.0 1 65184
Processing: 0 37916 59283.2 1 130682
Waiting: 0 2 8.7 1 414
Total: 1 39216 58711.6 1021 130682
...Давайте ещё раз посмотрим на вывод ab. На этот раз результаты выглядят так:
Очевидно, что каждый показатель стал намного хуже, чем прежде.
В Netfilter для обеспечения корректной работы NAT необходимо выполнить как минимум два шага:
- Используйте хуки (функции) в Netfilter для изменения адреса источника или назначения.
- Используйте модуль отслеживания соединений conntrack для связывания запросов и ответов одного и того же соединения.
Может ли быть проблема в этих двух областях? Давайте попробуем использовать инструмент динамической трассировки SystemTap, чтобы выяснить это.
Поскольку сегодняшний случай представляет собой сценарий стресс-тестирования со значительно сниженным числом одновременных запросов, и мы знаем, что виновником является NAT, у нас есть основания подозревать, что потеря пакетов происходит в ядре.
Мы можем вернуться к терминалу 1 и создать файл скрипта с именем dropwatch.stp и записать в него следующее содержимое:
#! /usr/bin/env stap
############################################################
# Dropwatch.stp
# Author: Neil Horman <nhorman@redhat.com>
# An example script to mimic the behavior of the dropwatch utility
# http://fedorahosted.org/dropwatch
############################################################
# Array to hold the list of drop points we find
global locations
# Note when we turn the monitor on and off
probe begin { printf("Monitoring for dropped packets\n") }
probe end { printf("Stopping dropped packet monitor\n") }
# increment a drop counter for every location we drop at
probe kernel.trace("kfree_skb") { locations[$location] <<< 1 }
# Every 5 seconds report our drop locations
probe timer.sec(5)
{
printf("\n")
foreach (l in locations-) {
printf("%d packets dropped at %s\n",
@count(locations[l]), symname(l))
}
delete locations
}Этот скрипт отслеживает вызов функции ядра kfree_skb() и подсчитывает количество потерянных пакетов. После сохранения файла выполните команду stap для запуска скрипта отслеживания потери пакетов. Вот пример работы утилиты stap для SystemTap:
$ stap --all-modules dropwatch.stp Monitoring for dropped packets
Если вы видите вывод «Мониторинг отброшенных пакетов» от начала проверки, это означает, что SystemTap скомпилировал скрипт в модуль ядра и начал его выполнение.
Далее переключитесь на терминал 2 и ab снова выполните команду:
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
Затем вернитесь к терминалу 1 и посмотрите на вывод команды stap:
10031 packets dropped at nf_hook_slow 676 packets dropped at tcp_v4_rcv 7284 packets dropped at nf_hook_slow 268 packets dropped at tcp_v4_rcv
Вы заметите, что в этой позиции происходит большое количество отбрасываний пакетов nf_hook_slow. Судя по этому имени, можно предположить, что в функции-хуке Netfilter есть проблема с отбрасыванием пакетов. Однако пока не подтверждено, связано ли это с NAT. Далее нам нужно отследить выполнение nf_hook_slow, что можно сделать с помощью perf.
Переключитесь на терминал 2 и ab снова выполните команду:
$ ab -c 5000 -n 10000 -r -s 30 http://192.168.0.30:8080/
Затем вернитесь к терминалу 1 и выполните следующие команды:
# Record for a while (e.g., 30 seconds) and then press Ctrl+C to stop. $ perf record -a -g -- sleep 30 # Output report $ perf report -g graph,0
В интерфейсе отчёта perf введите, /чтобы начать поиск, затем во всплывающем диалоговом окне введите nf_hook_slow. Затем разверните стек вызовов, чтобы получить следующий граф вызовов:
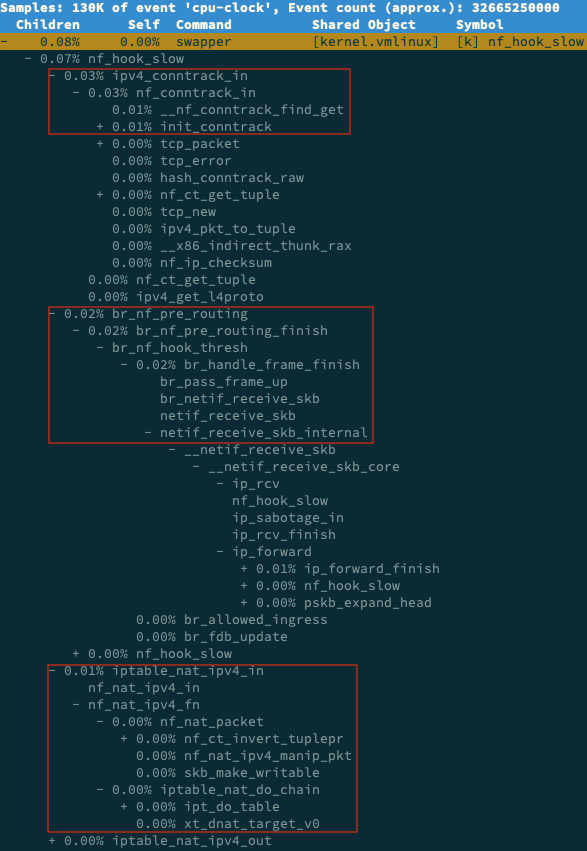
Из этого графика видно, что nf_hook_slow вызывается в основном в трёх местах: ipv4_conntrack_in, br_nf_pre_routing, и iptable_nat_ipv4_in. Другими словами, nf_hook_slow участвует в основном в трёх действиях:
- При получении сетевых пакетов он ищет соединения в таблице отслеживания соединений и назначает объекты отслеживания (корзины) для новых соединений.
- Он пересылает пакеты в Linux-мосте. Это связано с тем, что экземпляр Nginx в данном примере представляет собой Docker-контейнер, а сетевое взаимодействие контейнеров реализовано через мост.
- При получении сетевых пакетов он выполняет DNAT, то есть пересылает пакеты, полученные на порт 8080, в контейнер.
Итак, мы выявили три источника снижения производительности. Все эти источники являются частью механизмов ядра Linux, поэтому следующий шаг оптимизации, естественно, предполагает изменения на уровне ядра.
Ядро Linux предоставляет пользователям множество настраиваемых параметров, которые можно просматривать и изменять через proc и sys. Кроме того, для просмотра и изменения настроек ядра можно использовать sysctl.
Например, поскольку тема статьи — DNAT, основанный на conntrack, давайте сначала посмотрим, какие параметры конфигурации conntrack предоставляет ядро.
Продолжайте выполнять следующую команду в терминале 1:
$ sysctl -a | grep conntrack net.netfilter.nf_conntrack_count = 180 net.netfilter.nf_conntrack_max = 1000 net.netfilter.nf_conntrack_buckets = 65536 net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60 net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120 net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120 ...
Здесь вы можете увидеть три наиболее важных показателя:
net.netfilter.nf_conntrack_count: Текущее количество записей отслеживания подключений.net.netfilter.nf_conntrack_max: Максимально допустимое количество записей отслеживания подключений.net.netfilter.nf_conntrack_buckets: Размер таблицы отслеживания соединений.
Итак, этот вывод говорит, что текущее количество записей отслеживания подключений составляет 180, максимально допустимое — 1000, а размер таблицы отслеживания подключений составляет 65536.
Вспомните команду ab, которую мы использовали ранее, с количеством одновременных запросов 5000 и общим количеством запросов 100 000. Очевидно, что настройки таблицы отслеживания на регистрацию только 1000 соединений недостаточно.
Фактически, когда ядро сталкивается с ненормальным состоянием, оно регистрирует информацию в журнале. Например, в предыдущем тесте ядро уже сообщало об ошибке «nf_conntrack: table full» в журналах. Вы можете увидеть это, выполнив dmesg команду:
$ dmesg | tail [104235.156774] nf_conntrack: nf_conntrack: table full, dropping packet [104243.800401] net_ratelimit: 3939 callbacks suppressed [104243.800401] nf_conntrack: nf_conntrack: table full, dropping packet [104262.962157] nf_conntrack: nf_conntrack: table full, dropping packet
Сообщение net_ratelimit означает, что многие журналы были сжаты, что является мерой предосторожности, принимаемой ядром для предотвращения атак на журналы. Ошибка «nf_conntrack: table full» означает, что значение nf_conntrack_max слишком мало.
Однако достаточно ли просто увеличить размер таблицы отслеживания соединений? Прежде чем её настраивать, необходимо понимать, что таблица отслеживания соединений фактически представляет собой хеш-таблицу в памяти. Если количество отслеживаемых соединений слишком велико, это может привести к значительному потреблению памяти.
Фактически, параметр nf_conntrack_buckets, который мы видели ранее, — это размер хеш-таблицы. Каждая запись в хеш-таблице представляет собой связанный список (называемый контейнером), а длина связанного списка равна nf_conntrack_max делённому на nf_conntrack_buckets.
Например, мы можем оценить размер памяти, занимаемой таблицей отслеживания соединений, при указанной выше конфигурации:
# The size of the connection tracking object is 376, and the size of the linked list item is 16. nf_conntrack_max * 376 +nf_conntrack_buckets * 16 = 1000*376+65536*16 B = 1.4 MB
Далее увеличим значение nf_conntrack_max до большего значения, например, установим его равным 131072 (что в 2 раза больше nf_conntrack_buckets):
$ sysctl -w net.netfilter.nf_conntrack_max=131072 $ sysctl -w net.netfilter.nf_conntrack_buckets=65536
Затем вернитесь к терминалу 2 и повторите команду ab. Обратите внимание, что на этот раз мы устанавливаем тайм-аут обратно на исходные 2 секунды:
$ ab -c 5000 -n 100000 -r -s 2 http://192.168.0.30:8080/
...
Requests per second: 6315.99 [#/sec] (mean)
Time per request: 791.641 [ms] (mean)
Time per request: 0.158 [ms] (mean, across all concurrent requests)
Transfer rate: 4985.15 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 355 793.7 29 7352
Processing: 8 311 855.9 51 14481
Waiting: 0 292 851.5 36 14481
Total: 15 666 1216.3 148 14645Действительно, теперь вы можете видеть, что:
- Запросов в секунду: 6315 (6576 без NAT)
- Время на запрос: 791 мс (760 мс без NAT)
- Время подключения: 355 мс (177 мс без NAT)
Эти результаты намного лучше, чем в предыдущем тесте, и близки к базовым результатам без использования NAT.
Однако, все равно может быть интересно, что именно находится в таблице отслеживания подключений и как она обновляется.
Вы можете использовать conntrack командную строку для просмотра содержимого таблицы отслеживания подключений. Например:
# -L means list and -o means display in extended format. $ conntrack -L -o extended | head ipv4 2 tcp 6 7 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51744 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51744 [ASSURED] mark=0 use=1 ipv4 2 tcp 6 6 TIME_WAIT src=192.168.0.2 dst=192.168.0.96 sport=51524 dport=8080 src=172.17.0.2 dst=192.168.0.2 sport=8080 dport=51524 [ASSURED] mark=0 use=1
Видно, что команда conntrack отображает информацию о каждом соединении, включая протокол, состояние соединения, IP-адрес и порт источника, IP-адрес и порт назначения, а также состояние отслеживания. Поскольку формат фиксирован, вы можете использовать такие инструменты, как conntrack awk и sort conntrack, для статистического анализа.
Например, снова используем ab в качестве примера. После запуска команды ab в терминале 2 вернитесь в терминал 1 и выполните следующую команду:
# To count the total number of connections being tracked
$ conntrack -L -o extended | wc -l
14289
# To count the number of TCP connections in each state
$ conntrack -L -o extended | awk '/^.*tcp.*$/ {sum[$6]++} END {for(i in sum) print i, sum[i]}'
SYN_RECV 4
CLOSE_WAIT 9
ESTABLISHED 2877
FIN_WAIT 3
SYN_SENT 2113
TIME_WAIT 9283
# To count the number of connections for each source IP
$ conntrack -L -o extended | awk '{print $7}' | cut -d "=" -f 2 | sort | uniq -c | sort -nr | head -n 10
14116 192.168.0.2
172 192.168.0.96В этом разделе подсчитывается общее количество треков подключений, количество треков подключений в различных состояниях для протокола TCP и количество треков подключений для каждого исходного IP-адреса. Видно, что большинство треков TCP-подключений находятся в состоянии TIME_WAIT, и большинство из них относятся к IP-адресу 192.168.0.2 (это виртуальная машина VM2, выполняющая команду ab).
Эти треки соединения в состоянии TIME_WAIT будут очищены по истечении времени ожидания, которое по умолчанию составляет 120 секунд. Для проверки выполните следующую команду:
$ sysctl net.netfilter.nf_conntrack_tcp_timeout_time_wait net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
Поэтому, если у вас очень большое количество подключений, желательно также рассмотреть возможность соответствующего уменьшения тайм-аута.
Помимо этих распространённых конфигураций, conntrack также предлагает множество других вариантов конфигурации. Вы можете обратиться к документации n f_conntrack, чтобы настроить её в соответствии с вашими потребностями.
Заключение
Сегодня мы разобрали, как устранять неполадки и оптимизировать проблемы производительности, вызванные NAT.
Поскольку NAT реализован на основе механизма отслеживания соединений в ядре Linux, при анализе проблем производительности NAT можно начать с анализа conntrack. Например, с помощью таких инструментов, как SystemTap и perf, можно проанализировать поведение conntrack в ядре. Затем можно оптимизировать работу, настроив параметры ядра netfilter.
Фактически, этот тип NAT в Linux, реализованный посредством отслеживания соединений, часто называют NAT с отслеживанием состояния, и поддержание этого состояния влечет за собой высокие затраты производительности.
Таким образом, помимо настройки поведения ядра, в сценариях, где отслеживание состояния не требуется (например, когда требуется только предопределенное сопоставление IP-адресов и портов без динамического сопоставления), мы также можем использовать NAT без сохранения состояния (например, с использованием tc или разработки на основе DPDK) для дальнейшего повышения производительности.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.