Linux — мощь AWK
Подписывайтесь на телеграм-канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
Среди этих инструментов для обработки текста в Linux AWK выделяется как универсальная утилита командной строки, которая неплохо справляется с обработкой структурированного текста, такого как CSV-файлы, логи и другие файлы данных.
Что такое AWK

AWK, названный в честь своих создателей Ахо, Вайнбергера и Кернигана, — это скриптовый язык, предназначенный для обработки текста. Благодаря простому синтаксису AWK эффективен при поиске в файлах строк, содержащих определённые шаблоны и выполнении заданных действий над этими строками. AWK — это не просто команда; это полноценный язык программирования, предлагающий переменные, операторы управления потоком, массивы и функции.
Ключевые особенности AWK
- Сканирование и обработка шаблонов: AWK сканирует файл построчно, ища шаблоны, заданные пользователем. Если строка соответствует одному из шаблонов, AWK выполняет соответствующее действие.
- Встроенные функции обработки текста: включает набор функций для обработки строк, арифметических операций и ввода/вывода, что делает его надежным инструментом для обработки текста.
- Обработка текста, ориентированная на поля: AWK обрабатывает каждую строку как запись, а каждое слово, разделенное пробелами, как поле, что упрощает обработку структурированного текста.
Начнем
Давайте подготовим следующий пример вывода команды netstat:
$ cat netstat.txt Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp 0 0 192.168.1.5:22 192.168.1.1:53822 ESTABLISHED tcp6 0 0 :::80 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN udp 0 0 0.0.0.0:68 0.0.0.0:* udp6 0 0 :::546 :::*
Теперь давайте вызовем простую команду awk:
$ awk '{print $1, $4}' netstat_output.txt
Proto Local
tcp 127.0.0.1:3306
tcp 0.0.0.0:22
tcp 192.168.1.5:22
tcp6 :::80
tcp6 :::22
udp 0.0.0.0:68
udp6 :::546awk: Вызывает программу AWK, предназначенную для сканирования шаблонов и обработки текста.'{print $1, $4}': Задаёт действие, которое должно быть выполнено над каждой строкой входного файла. В AWK действия заключаются в фигурные скобки{}. Это действие указывает AWK вывести первое ($1) и четвёртое ($4) поля каждой строки, разделённые пробелом. Поля в AWK обычно представляют собой слова, разделённые пробелами, хотя это можно настроить.
Фильтр AWK
Утилита AWK структурирована вокруг концепции шаблонов и действий, которые записываются следующим образом:
pattern { action }- Шаблоном может быть регулярное выражение, реляционное выражение, шаблон диапазона или даже специальный шаблон (
BEGINилиEND). Когда строка входных данных соответствует шаблону, AWK выполняет соответствующее действие. Если шаблон не указан, действие выполняется для каждой строки входных данных. - Действие это блок команд AWK, заключённый в фигурные скобки
{ ... }, который выполняется при совпадении входных данных с шаблоном. Действия могут изменять данные, вычислять результаты или создавать выходные данные.
Как работает фильтрация
- Чтение входных данных: AWK считывает входные данные построчно, разбивая каждую строку на поля на основе разделителя полей (по умолчанию — пробел).
- Применение шаблонов: для каждой строки AWK оценивает заданные шаблоны в порядке их появления в скрипте. Шаблон может быть простым, например, условие на значение поля (
$1 == "somevalue") или соответствием регулярному выражению (/regex/). - Выполнение действий: когда строка соответствует шаблону, AWK выполняет соответствующее действие над этой строкой. Действия могут включать печать или изменение полей, выполнение вычислений и любые другие операции, поддерживаемые AWK.
- Продолжение процесса: этот процесс повторяется для каждой строки ввода, пока все входные данные не будут использованы.
$ awk '$3==0 && $6=="LISTEN"' netstat_output.txt tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp6 0 0 :::80 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN
$3==0$3: Это условие проверяет, равно ли третье поле ($3) каждой строки нулю.$6=="LISTEN": Это условие проверяет, является ли шестое поле ($6) в точности равным строке «LISTEN».&&: Это логический оператор «И». Он объединяет два условия, то есть для выполнения части действия скрипта AWK оба условия должны быть истинны. Если хотя бы одно из условий ложно, строка далее не обрабатывается. Другие доступные логические операторы:!=,>,<,>=,<=.
Если мы хотим включить заголовок, мы можем использовать встроенную переменную NR:
$ awk '$3==0 && $6=="LISTEN" || NR==1' netstat_output.txt Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN tcp6 0 0 :::80 :::* LISTEN tcp6 0 0 :::22 :::* LISTEN
Некоторые общие предопределенные переменные AWK:
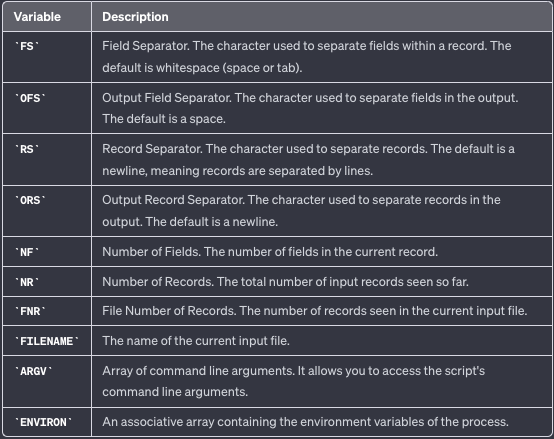
Сопоставление строк AWK
AWK обрабатывает текст, считывая построчно, разделяя каждую строку на поля и проверяя каждое поле или всю строку целиком на соответствие заданным шаблонам. Эти шаблоны могут представлять собой литеральные строки, регулярные выражения или их комбинацию, что обеспечивает гибкий подход к поиску совпадений. При обнаружении совпадения AWK выполняет заданные действия над строкой, например, выводит её на экран, сохраняет в файл или даже оперативно изменяет текст.
Литеральные строки и регулярные выражения
AWK поддерживает два основных типа сопоставления строк: литеральные строки и регулярные выражения. Сопоставление литеральных строк так же просто, как поиск точного слова или фразы в тексте. Например, поиск слова «error» в файле журнала может быть таким же простым:
$ awk '/error/' example.log ... 2023-07-01 10:05:00 Error: Connection timeout ...
Регулярные выражения предлагают более мощный и гибкий способ поиска по шаблонам. Например, для поиска любой строки, начинающейся с даты в YYYY-MM-DD формате:
$ awk '/^[0-9]{4}-[0-9]{2}-[0-9]{2}/' example.logСопоставление по конкретным областям
Одной из сильных сторон AWK является возможность выполнять поиск по полям. По умолчанию AWK считает пробелы и табуляции разделителями полей, что позволяет выполнять целенаправленный поиск внутри определённых полей. Например, если вам нужно найти строки, где второе поле указывает на ошибку:
$ awk '$3 == "Error:"' example.log 2023-07-01 10:05:00 Error: Connection timeout
Разделение файлов AWK
Разделение файлов с помощью AWK выполняется просто, с использованием перенаправления. Следующий пример демонстрирует разделение файла по шестому полю, что довольно просто (где `NR!=1` означает, что заголовок не обрабатывается).
Рассмотрим сценарий, в котором мы хотим использовать AWK для разделения CSV-файла на несколько файлов на основе значения определённого поля. В этом примере представьте, что у нас есть CSV-файл с именем employees.csv и следующим содержимым:
ID,Name,Department,Salary 1,John Doe,Engineering,50000 2,Jane Smith,Marketing,45000 3,Emily Davis,Engineering,55000 4,Chris Brown,Marketing,40000
Мы хотим разделить этот файл на отдельные файлы для каждого отдела, исключив заголовок из разделённых файлов. Для этого выполним следующую команду AWK:
$ awk -F, 'NR!=1{print > $3".csv"}' employees.csv-F,: Устанавливает запятую в качестве разделителя полей, поскольку мы имеем дело с CSV-файлом.NR!=1: Это условие пропускает первую запись (строку заголовка).print > $3".csv": Для каждой строки (кроме заголовка) эта команда выводит всю строку в файл, имя которого соответствует значению в третьем поле (Department) с расширением.csv. Таким образом, строки, относящиеся к одному отделу, собираются в соответствующие файлы.
Приведенная выше команда создаст следующие два файла:
1,John Doe,Engineering,50000 3,Emily Davis,Engineering,55000
2,Jane Smith,Marketing,45000 4,Chris Brown,Marketing,40000
Статистика AWK
Рассмотрим пример: у нас есть CSV-файл с sales_data.csv с данными о продажах разных товаров за разные месяцы. Наша цель — использовать AWK для расчета общего объема продаж каждого товара и отображения результатов.
Product,Month,Sales WidgetA,January,150 WidgetB,February,90 WidgetA,March,200 WidgetC,January,400 WidgetB,March,120 WidgetC,February,300
Давайте выполним следующую команду:
$ awk -F, 'NR>1 {sales[$1]+=$3} END {for (product in sales) print product ", Total Sales: " sales[product]}' sales_data.csvОжидаемый результат будет выглядеть так:
WidgetA, Total Sales: 350 WidgetB, Total Sales: 210 WidgetC, Total Sales: 700
Другой пример — подсчёт размера файла. Следующая команда вычисляет общий размер всех файлов C, CPP и H.
$ ls -l *.cpp *.c *.h | awk '{sum+=$5} END {print sum}'Скрипт AWK
Скрипт AWK — это мощный инструмент для обработки текста и извлечения данных, широко используемый в Unix-подобных операционных системах. Он обрабатывает последовательности записей и полей, применяя к тексту заданные шаблоны и действия. Скрипты AWK могут использоваться для решения различных задач, таких как суммирование данных, создание отчетов и работа с текстом.
Структура скрипта AWK
Скрипт AWK обычно имеет следующую структуру:
pattern { action }
pattern { action }
...- Шаблон: условие или регулярное выражение, определяющее, к каким записям (обычно строкам текста) должно применяться действие. Если шаблон не указан, действие применяется ко всем записям.
- Действие: блок команд AWK, заключённый в фигурные скобки
{}, который выполняется при совпадении шаблона с записью. Действия могут включать печать или изменение текста, выполнение вычислений и многое другое.
Запуск скрипта AWK
Скрипты AWK можно запускать двумя способами:
$ awk 'script' input_file
$ awk -f script_file.awk input_file
Предположим, у вас есть CSV-файл sales.csv со следующим содержимым:
Month,Product,Sales January,Apples,100 February,Apples,150 January,Bananas,90 February,Bananas,95
Вам нужно рассчитать общий объём продаж каждого товара. Скрипт AWK сохранённый в файл summarize_sales.awk, будет выглядеть так:
BEGIN { FS = "," }
NR > 1 { sales[$2] += $3 }
END {
for (product in sales)
print product, sales[product]
}Заключение
В заключение отмечу, что AWK является надёжным инструментом для разработчиков, системных администраторов и аналитиков данных. Сочетание простоты, эффективности и мощности делает его бесценным инструментом для всех, кто занимается обработкой текста и анализом данных в Unix-подобных системах.
Работаете ли вы с большими наборами данных, оптимизируете файлы журналов или автоматизируете создание отчетов, AWK обеспечивает функциональность и гибкость, необходимые для эффективного выполнения этих задач.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.