Как работает память Linux?
Это перевод оригинальной статьи How Does Linux Memory Work?
Подписывайтесь на телеграм-канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
Подобно управлению процессором, управление памятью является одной из основных функций операционной системы. Память в основном используется для хранения системных и прикладных инструкций, данных, кэшей и многого другого.
Итак, как Linux управляет памятью? Давайте подробнее рассмотрим эту тему.
Маппинг памяти
Кстати, о памяти: можете ли вы сказать, какой объём памяти у вашего компьютера? Уверен, вы его хорошо помните, ведь это один из главных факторов при покупке компьютера. Например, объём памяти моего ноутбука — 36 ГБ.
Когда мы говорим об объёме памяти, например, о 36 ГБ, о которых я только что говорил, мы фактически говорим о физической памяти. Физическая память, также известная как основная память, в большинстве компьютеров в основном состоит из динамической памяти с произвольным доступом (DRAM). Прямой доступ к физической памяти есть только у ядра. Так как же процесс получает доступ к памяти?
Ядро Linux предоставляет каждому процессу отдельное виртуальное адресное пространство, и это адресное пространство является непрерывным. Таким образом, процессы могут легко обращаться к памяти, а точнее, к виртуальной памяти.
Виртуальное адресное пространство разделено на две части: пространство ядра и пространство пользователя. Диапазон адресного пространства варьируется в зависимости от разрядности процессора (максимального объёма данных, который может обработать одна инструкция). Например, для наиболее распространённых 32- и 64-битных систем ниже вы найдете 2 две диаграммы, представляющие их виртуальные адресные пространства:
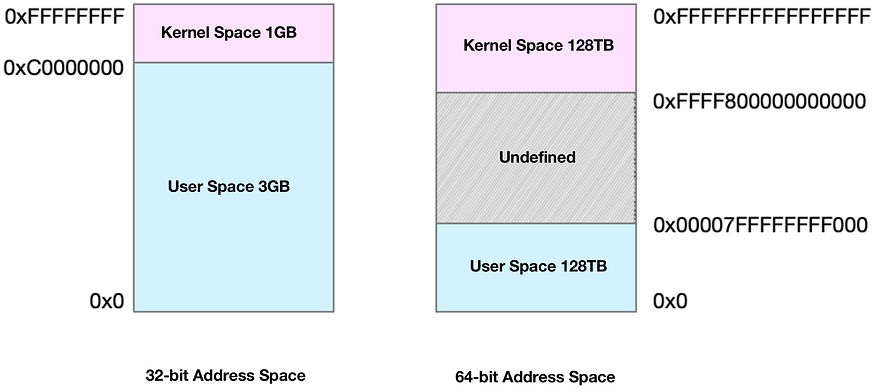
Отсюда видно, что в 32-битной системе пространство ядра занимает 1 ГБ сверху, а оставшиеся 3 ГБ — пользовательское пространство. В 64-битной системе и пространство ядра, и пользовательское пространство занимают по 128 ТБ, занимая соответственно верхнюю и нижнюю части всего пространства памяти, а средняя часть остаётся неопределённой.
Когда процесс находится в пользовательском режиме, он может получить доступ только к памяти пространства пользователя; доступ к памяти пространства ядра он может получить только в режиме ядра. Хотя, адресное пространство каждого процесса включает в себя пространство ядра, это пространство ядра фактически расположено в одной и той же физической памяти. Таким образом, когда процесс переключается в режим ядра, он может легко получить доступ к памяти пространства ядра.
Поскольку каждый процесс имеет большое адресное пространство, суммарный объём виртуальной памяти всех процессов, естественно, значительно превышает объём физической памяти. Следовательно, не вся виртуальная память выделяется в физической памяти; только та виртуальная память, которая фактически используется, выделяется в физической памяти. Управление выделенной физической памятью осуществляется посредством маппинга памяти.
Маппинг памяти, по сути, сопоставляет адреса виртуальной памяти с адресами физической памяти. Для завершения маппинга памяти ядро поддерживает таблицу страниц для каждого процесса, записывая взаимосвязь между виртуальными и физическими адресами, как показано на схеме ниже:
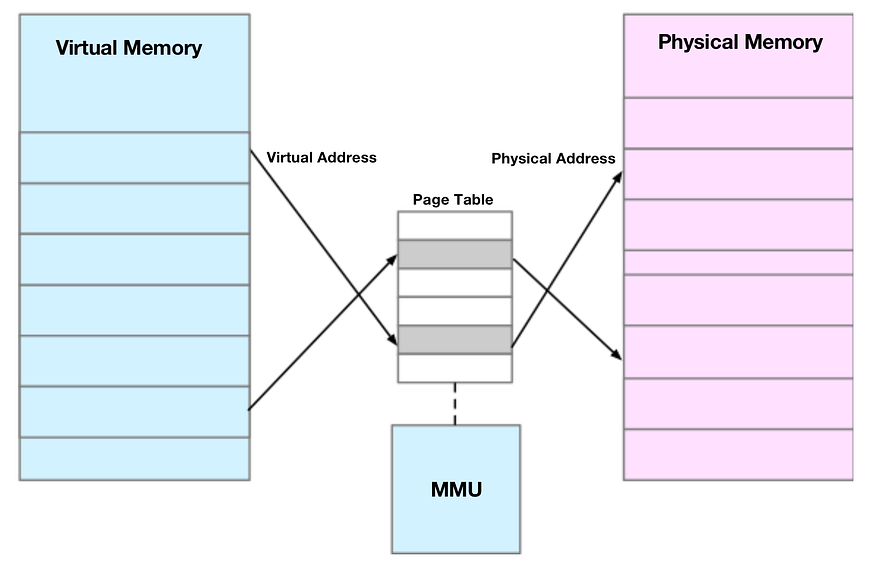
Таблица страниц фактически хранится в блоке управления памятью (MMU) центрального процессора, поэтому в обычных условиях процессор может напрямую обращаться к необходимой ему памяти через аппаратное обеспечение.
Когда процесс обращается к виртуальному адресу, которого нет в таблице страниц, генерируется исключение ошибки страницы. Затем система переходит в пространство ядра для выделения физической памяти, обновляет таблицу страниц процесса и, наконец, возвращается в пользовательское пространство для возобновления выполнения процесса.
TLB (Translation Lookaside Buffer) влияет на производительность доступа к памяти CPU, и это можно объяснить здесь.
Буфер TLB, по сути, представляет собой кэш для таблицы страниц в блоке памяти (MMU). Поскольку виртуальное адресное пространство процесса изолировано, а доступ к TLB осуществляется гораздо быстрее, чем к MMU, оптимизация использования кэша TLB за счёт сокращения переключений контекста и сбросов TLB может повысить производительность доступа к памяти процессора.
Однако важно отметить, что MMU управляет памятью не побайтно, а определяет минимальную единицу отображения памяти — страницу, обычно размером 4 КБ. Таким образом, каждая операция отображения памяти должна быть связана с объёмом памяти объёмом 4 КБ или целым числом, кратным 4 КБ.
Другая проблема, вызванная размером страницы всего в 4 КБ, заключается в том, что вся таблица страниц может стать очень большой. Например, в 32-битной системе для отображения всего адресного пространства требуется более 1 миллиона записей в таблице страниц (4 ГБ/4 КБ). Для решения проблемы слишком большого количества записей в таблице страниц в Linux предусмотрены два механизма: многоуровневые таблицы страниц и HugePages.
Многоуровневые таблицы страниц управляют страницами памяти, разделяя память на блоки, изменяя сопоставление с одного индекса на индекс блока и смещение внутри блока. Поскольку объём виртуальной памяти обычно составляет лишь небольшую часть от общего объёма, многоуровневые таблицы страниц хранят только используемые блоки, что значительно сокращает количество записей в таблице страниц.
Linux использует четырехуровневую таблицу страниц для управления страницами памяти, как показано на рисунке ниже, где виртуальный адрес делится на 5 частей: первые 4 записи используются для выбора страницы, а последний индекс представляет смещение внутри страницы.
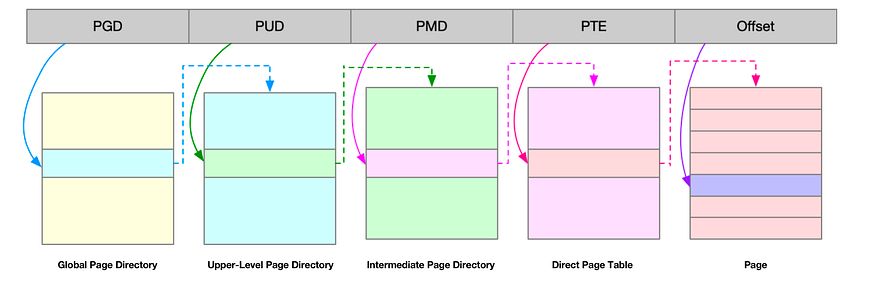
Как следует из названия, большие страницы — это блоки памяти, размер которых превышает размер стандартных страниц. Обычные размеры больших страниц — 2 МБ и 1 ГБ. Большие страницы обычно используются в процессах, требующих значительного объёма памяти, таких как Oracle и DPDK.
Благодаря этим механизмам процесс может получать доступ к физической памяти через виртуальные адреса, соответствующие сопоставлениям таблицы страниц. Итак, как же эта память используется в процессе Linux?
Структура пространства виртуальной памяти
Во-первых, нам необходимо подробнее разобраться в распределении пространства виртуальной памяти. Пространство ядра, расположенное наверху, выглядит просто, но пользовательское пространство, расположенное ниже, фактически разделено на несколько различных сегментов. На примере 32-битной системы я нарисовал диаграмму, иллюстрирующую их взаимосвязь.
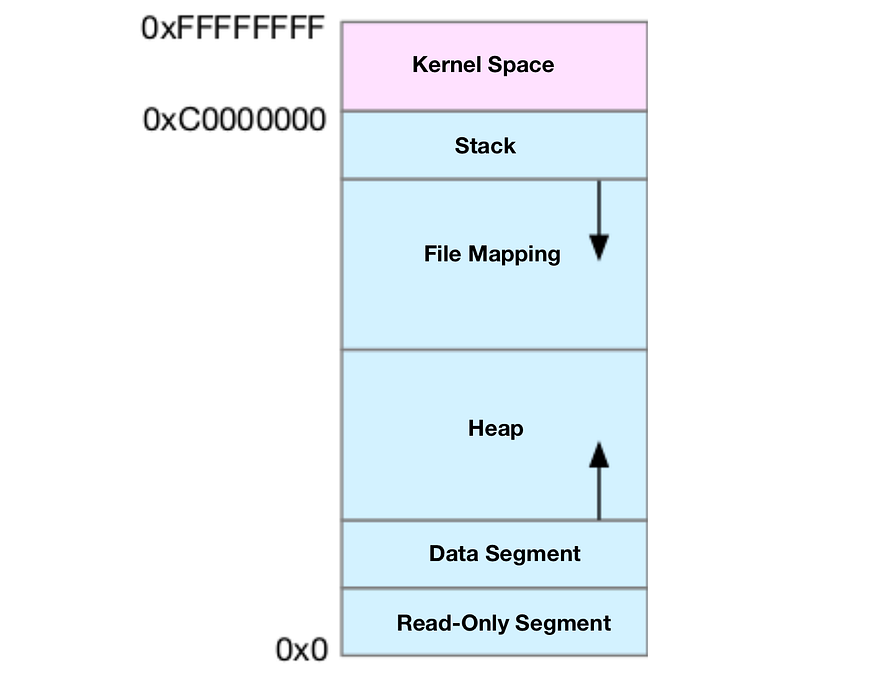
На этой диаграмме вы можете увидеть, что в памяти пользовательского пространства имеется пять различных сегментов памяти, расположенных от низшего к высшему.
- Сегмент только для чтения: включает код и константы.
- Сегмент данных: включает глобальные переменные.
- Куча: включает динамически выделяемую память, увеличивающуюся от нижних адресов.
- Сегмент отображения файлов: включает динамические библиотеки, общую память и т. д., увеличиваясь сверху вниз от более высоких адресов.
- Стек: включает локальные переменные и контексты вызова функций. Размер стека фиксирован, обычно около 8 МБ.
В этих пяти сегментах памяти память в куче и сегменте отображения файлов выделяется динамически. Например, с помощью функций malloc() стандартной библиотеки C или mmap() можно динамически выделять память в куче и сегменте отображения файлов соответственно.
На самом деле, структура памяти в 64-битной системе похожа, но объём памяти значительно больше. Поэтому возникает более важный вопрос: как именно выделяется память?
Выделение и освобождение памяти
Функция malloc() в стандартной библиотеке языка C используется для выделения памяти. Существуют две основные реализации системного вызова для malloc(): brk() и mmap().
Для небольших блоков памяти (менее 128 КБ) стандартная библиотека языка C использует brk() метод выделения памяти, который включает перемещение вершины кучи для выделения памяти. Эта память не возвращается системе сразу после освобождения, а кэшируется для повторного использования.
Для больших блоков памяти (более 128 КБ) mmap() используется непосредственно для выделения, то есть выделяет память из сегмента отображения файла.
Эти два метода имеют свои преимущества и недостатки.
- Преимущества
brk(): Кэшированиеbrk()может уменьшить количество ошибок страниц и повысить эффективность доступа к памяти. Однако память, выделенная черезbrk(), не возвращается операционной системе после освобождения, что может приводить к фрагментации при частом распределении и освобождении.. - Преимущества
mmap(): память, выделенная с помощьюmmap(), возвращается системе после освобождения, что позволяет избежать фрагментации. Однако при выделении памяти черезmmap()возникают ошибки страниц, что может увеличить нагрузку на ядро в сценариях с интенсивным использованием памяти. Поэтомуmalloc()используетmmap()только для больших блоков памяти.
Разобравшись с этими двумя методами, важно отметить, что при этих вызовах память фактически не выделяется. Она выделяется только при первом обращении к памяти из-за ошибок страниц, что запускает выделение памяти ядром.
В целом, Linux использует систему «партнёров» для управления выделением памяти. Мы уже упоминали, что память управляется блоком управления памятью (MMU) постранично, и система «партнёров» также управляет памятью постранично, объединяя соседние страницы для уменьшения фрагментации (например, вызванной brk()).
Вы можете задаться вопросом, как выделяется память для объектов размером меньше страницы, например, менее 1 КБ.
На практике существует множество объектов размером меньше страницы, и выделение отдельной страницы для каждого из них привело бы к ненужному расходу памяти. Поэтому в пользовательском пространстве память, выделенная с помощью malloc() через brk() кэшируется для повторного использования, а не немедленно возвращается в систему. В пространстве ядра Linux использует распределитель slab для управления небольшими объектами памяти. Slab можно рассматривать как кэш, построенный поверх системы buddy, в основном для выделения и освобождения небольших объектов в ядре.
Что касается памяти, то если она только выделяется, а не освобождается, это может привести к утечкам памяти и, в конечном итоге, исчерпанию системной памяти. Поэтому, когда память больше не нужна, приложениям приходится вызывать free() или unmap() для её освобождения.
Конечно, система не позволит процессу использовать всю доступную память. При нехватке памяти система использует несколько механизмов для её освобождения, например:
- Освобождение кэша: использование алгоритма LRU (Least Recently Used) для освобождения наиболее давно используемых страниц памяти.
- Освобождение редко используемой памяти: перемещение редко используемой памяти в область подкачки на диске. Этот процесс называется выгрузкой страниц, и при повторном обращении к памяти данные считываются с диска в память, что называется загрузкой страниц.
- Завершение процессов: когда памяти критически мало, система может использовать OOM (недостаточно памяти) для завершения процессов, потребляющих большие объемы памяти, чтобы защитить систему.
Второй метод, предполагающий освобождение редко используемой памяти, использует пространство подкачки. Пространство подкачки — это часть диска, используемая как расширение оперативной памяти. Оно временно хранит неиспользуемые данные и извлекает их при необходимости.
Таким образом, пространство подкачки увеличивает объём доступной памяти системы. Однако следует отметить, что подкачка происходит только при нехватке памяти, и поскольку скорость чтения/записи на диске значительно ниже, чем у оперативной памяти, подкачка может привести к серьёзным проблемам с производительностью.
Третий метод, OOM (Out of Memory), представляет собой механизм защиты ядра. Он отслеживает использование памяти процессами и назначает oom_score каждому процессу разрешение на основе его использования памяти:
- Выше
oom_score: процесс использует больше памяти и с большей вероятностью будет завершен OOM. - Низкое
oom_score: процесс использует меньше памяти и имеет меньшую вероятность быть завершенным OOM.
Чтобы настроить oom_score, администраторы могут вручную задать значение oom_adj для процесса через файловую систему /proc.
Диапазон значений oom_adj составляет [-17, 15]; более высокое значение означает, что процесс с большей вероятностью будет завершен OOM, тогда как более низкое значение означает, что это менее вероятно, где -17 означает «не завершать».
Например, следующая команда может изменить значение параметра oom_adj для sshd процесса на -16, что снизит вероятность его завершения OOM:
echo -16 > /proc/$(pidof sshd)/oom_adj
Как проверить использование памяти
Понимая распределение памяти, а также её выделение и повторное использование, вы должны иметь общее представление о том, как работает память. Конечно, реальная работа системы более сложна и включает в себя и другие механизмы, но здесь я рассмотрел только основные принципы. Эти знания дадут вам чёткую основу для понимания операций с памятью, а не просто набор технических терминов.
Итак, изучив принципы работы памяти, как мы можем проверить использование памяти системой?
Здесь первым инструментом, который, возможно, придёт вам в голову, будет free команда. Ниже приведён пример вывода команды free :
$ free
total used free shared buff/cache available
Mem: 8169348 263524 6875352 668 1030472 7611064
Swap: 0 0 0Вы можете увидеть, что команда free выводит таблицу, где значения по умолчанию отображаются в байтах. Таблица состоит из двух строк и шести столбцов. Две строки отображают использование физической памяти (Mem) и пространства подкачки (Swap), а шесть столбцов отображают:
- total: Общий объем памяти.
- used: объем используемой памяти, включая общую память.
- free: объем неиспользуемой памяти.
- shared: объем памяти, используемый общими ресурсами.
- buff/cache: размер кэша и буферов.
- available: объем памяти, доступный для новых процессов.
Важное замечание касается последнего столбца — Available (Доступно). Available включает в себя не только неиспользуемую память, но и кэш, доступный для восстановления, поэтому обычно превышает объём неиспользуемой памяти. Однако не все кэши можно восстановить, так как некоторые из них могут всё ещё использоваться.
Однако мы знаем, что free показывает общее использование памяти всей системой. Если вы хотите проверить использование памяти отдельными процессами, можно использовать такие инструменты, как top или ps. Например, ниже приведён пример вывода команды top:
# Press M to Sort by Memory Usage
$ top
...
KiB Mem : 8169348 total, 6871440 free, 267096 used, 1030812 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7607492 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
430 root 19 -1 122360 35588 23748 S 0.0 0.4 0:32.17 systemd-journal
1075 root 20 0 771860 22744 11368 S 0.0 0.3 0:38.89 snapd
1048 root 20 0 170904 17292 9488 S 0.0 0.2 0:00.24 networkd-dispat
1 root 20 0 78020 9156 6644 S 0.0 0.1 0:22.92 systemd
12376 azure 20 0 76632 7456 6420 S 0.0 0.1 0:00.01 systemd
12374 root 20 0 107984 7312 6304 S 0.0 0.1 0:00.00 sshd
...Вверху вывода команды top отображается общая статистика использования памяти системой. Она похожа на вывод команды free, поэтому мы не будем повторять её здесь. Вместо этого сосредоточимся на столбцах, связанных с памятью, таких как VIRT, RES, SHR и %MEM.
Вот что представляют собой эти столбцы:
- VIRT: Общий объём виртуальной памяти процесса. Включает всю запрошенную процессом память, даже если она ещё не выделена физически.
- RES: Объём резидентной памяти процесса. Это фактический объём физической памяти, используемой процессом, без учёта пространства подкачки и разделяемой памяти.
- SHR: объём разделяемой памяти, используемой процессом. Сюда входит память, разделяемая с другими процессами, загруженными динамическими библиотеками и сегментами кода программы.
- %MEM: процент физической памяти системы, используемый процессом.
Помимо понимания этих базовых данных, при просмотре вывода команды top стоит учитывать ещё два важных момента:
- Виртуальная память против физической: виртуальная память часто не отображается напрямую в физическую память. Как видно из вывода, объём виртуальной памяти процесса (VIRT) обычно значительно превышает объём резидентной памяти (RES).
- Общая память (SHR): столбец SHR не всегда отображает объём памяти, которая действительно используется совместно. Например, он включает сегменты кода программы и неразделяемые динамические библиотеки, а также объём памяти, фактически разделяемой между процессами. Таким образом, для определения общего использования памяти не следует просто суммировать значения SHR по процессам.
Заключение
Сегодня мы рассмотрели принципы работы памяти в Linux. Типичный процесс видит только виртуальную память, предоставляемую ядром, которая отображается системой в физическую память посредством таблиц страниц.
Когда процесс запрашивает память через malloc(), память выделяется не сразу. Она выделяется только при первом обращении через исключение ошибки страницы, которое перехватывается ядром.
Поскольку виртуальное адресное пространство процесса намного больше физической памяти, Linux предоставляет ряд механизмов для обработки нехватки памяти, таких как освобождение кэша, пространство подкачки (Swap) и обработка нехватки памяти (OOM).
Если вам нужно понять, как система или процесс использует память, вы можете использовать такие инструменты анализа производительности, как free, top и ps. Эти инструменты относятся к числу наиболее распространённых инструментов анализа производительности, и важно уметь ими пользоваться и понимать значение различных предоставляемых ими показателей.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.