Методы анализа потери пакетов на серверах Linux
Потеря пакетов относится к ситуации, когда в процессе отправки и получения сетевых данных пакет данных отбрасывается до того, как он достигнет приложения. Количество отброшенных пакетов, деленное на общее количество переданных пакетов, дает показатель потери пакетов, который является одним из важнейших показателей производительности сети.
Подписывайтесь на канал usr_bin, где я публикую много полезного по Linux, в том числе ссылки на статьи в этом блоге.
Потеря пакетов часто приводит к серьезному снижению производительности, особенно для TCP, где это обычно означает перегрузку сети и повторные передачи, что приводит к увеличению задержек в сети и снижению пропускной способности.
Далее будем использовать наиболее часто используемый реверс-прокси Nginx в качестве примера, чтобы показать, как анализировать проблемы потери сетевых пакетов.
Рассмотрим пример
Пример, который будем анализировать — это приложение Nginx, как показано на схеме ниже, где hping3 и curl являются клиентами Nginx. Nginx работает в контейнере Docker.
Выполняем команду hping3 для выполнения проверки доступа на Nginx. Обратите внимание, что мы не использовали ping, т.к. ping основан на протоколе ICMP, в то время как Nginx использует протокол TCP.
# -c отправляет 10 запросов, -S использоваие TCP SYN, -p указывает порт 80 $ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=3 win=5120 rtt=7.5 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=4 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=3.3 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=7 win=5120 rtt=3.0 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=3027.2 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss round-trip min/avg/max = 3.0/609.7/3027.2 ms
Из выходных данных hping3 видно, что было отправлено 10 пакетов запросов, но получено только 5 ответов, что указывает на уровень потери пакетов 50%. Наблюдая за RTT каждого запроса, можно увидеть значительные колебания, некоторые из которых составляют менее 3 мс, а другие более.
На основании этого, можно сделать вывод, что произошла потеря пакетов. Вероятно, что 3-секундный RTT вызван повторной передачей после потери пакетов. Так где же именно теряются пакеты?
Прежде чем приступить к устранению неполадок, давайте-ка рассмотрим подробнее принцип потери сетевых пакетов. Ниже схема, которую вы можете сохранить и даже распечатать:
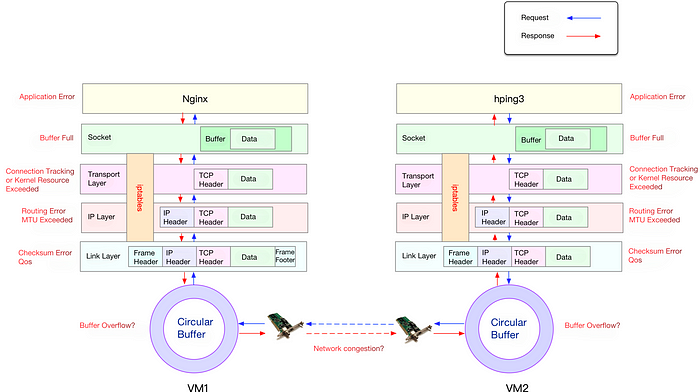
На схеме видно, что потенциальные места потери пакетов охватывают весь стек сетевых протоколов. Другими словами, потеря пакетов может произойти в любой точке пути. Если смотреть снизу вверх:
- Между двумя виртуальными машинами могут возникать сбои передачи данных, такие как перегрузка сети или ошибки линии.
- После того, как сетевая карта получает пакеты, может произойти потеря пакетов из-за переполнения кольцевого буфера.
- На канальном уровне потеря пакетов может произойти из-за неверных контрольных сумм сетевых фреймов, проблем с качеством обслуживания и т. д.
- На уровне IP потеря пакетов может произойти из-за сбоев маршрутизации, превышения размера MTU и т. д.
- На транспортном уровне потеря пакетов может произойти из-за не отвечающих портов, превышения ограничений ресурсов ядра и т. д.
- На уровне сокетов возможна потеря пакетов из-за переполнения буфера сокета.
- На прикладном уровне потеря пакетов может произойти из-за ошибок приложения.
- Кроме того, если настроены правила iptables, возможна потеря пакетов из-за правил фильтрации iptables.
Конечно, эти проблемы могут также возникнуть одновременно на обеих взаимодействующих машинах. Однако, предположив, что мы не внесли никаких изменений в VM2 и она только запускает простую команду hping3, давайте предположим, что это не является источником проблемы.
Для упрощения процесса устранения неполадок можем дополнительно предположить, что конфигурации сети и ядра на VM1 также верны. При таких предположениях все потенциальные проблемные области находятся внутри контейнера.
Примечание: В реальной среде проблемы могут возникать как внутри, так и снаружи контейнеров. Однако, этапы анализа и подход к траблшутингу как внутри, так и снаружи контейнеров одинаковы, просто требуют больше времени и усилий.
Далее приступим к устранению проблемы потери пакетов слой за слоем в стеке протоколов.
Канальный уровень
Сначала давайте рассмотрим самый нижний уровень, канальный уровень. Когда происходит потеря пакетов по таким причинам, как переполнение буфера сетевой карты, Linux записывает количество ошибок передачи и приема в статистику сетевой карты.
Можно использовать ethtoolили netstatдля проверки записей потери пакетов сетевой карты. Например, можно выполнить следующую команду в контейнере для проверки потери пакетов:
root@nginx: netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 100 31 0 0 0 8 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 LRU
Выходные данные RX-OK, RX-ERR, RX-DRP и RX-OVR представляют собой общее количество полученных пакетов, общее количество ошибок приема, количество пакетов, отброшенных после попадания в кольцевой буфер по другим причинам (например, из-за нехватки памяти), и количество пакетов, отброшенных из-за переполнения кольцевого буфера соответственно.
Аналогично, TX-OK, TX-ERR, TX-DRP и TX-OVR представляют собой аналогичные метрики для передач, указывающие общее количество переданных пакетов, общее количество ошибок передачи, количество пакетов, отброшенных после попадания в кольцевой буфер по другим причинам, и количество пакетов, отброшенных из-за переполнения кольцевого буфера соответственно.
Обратите внимание, что поскольку виртуальные сетевые интерфейсы контейнеров Docker представляют собой пару устройств veth, один конец которых подключен к eth0 внутри контейнера, а другой — к мосту docker0 на хосте, драйвер veth не реализует сетевую статистику. Поэтому использование команды ethtool -S предоставляет сводную информацию о сетевом трафике в контейнерах Docker.Из этого вывода мы не нашли ошибок, что указывает на то, что виртуальный сетевой интерфейс контейнера не терял пакетов. Однако важно отметить, что если QoS настроен с использованием таких инструментов, как tc, потеря пакетов, вызванная правилами tc, не будет включена в статистику сетевой карты.
Поэтому далее нужно проверить, настроены ли правила tc на eth0 и посмотреть, есть ли потеря пакетов. Давайте продолжим в терминале контейнера и выполним команду tc. На этот раз обратите внимание на добавление опции -s для вывода статистики:
root@nginx: tc -s qdisc show dev eth0 qdisc netem 800d: root refcnt 2 limit 1000 loss 30% Sent 432 bytes 8 pkt (dropped 4, overlimits 0 requeues 0) backlog 0b 0p requeues 0
Из вывода tc видно, что правило очередности моделирования сети (qdisc netem) настроено на eth0 с 30% потерей пакетов. Если посмотреть на статистику, то видно, что было отправлено 8 пакетов, но 4 были отброшены.
Похоже, это является причиной того, что пакеты ответов Nginx отбрасываются модулем netem.
Теперь, когда мы определили проблему, решение простое: нам просто нужно удалить модуль netem. Мы можем в терминале контейнера выполнить следующую команду, чтобы удалить модуль netem из tc:
root@nginx: tc qdisc del dev eth0 root netem loss 30%
Проблема была решена после удаления? Давайте повторно выполним предыдущую команду hping3, чтобы посмотреть, есть ли какие-либо проблемы сейчас:
$ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.9 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=1003.8 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=5 win=5120 rtt=7.6 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=6 win=5120 rtt=7.4 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=3.0 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 5 packets received, 50% packet loss round-trip min/avg/max = 3.0/205.9/1003.8 ms
К сожалению, из выходных данных hping3 видно, что уровень потери пакетов по-прежнему составляет 50%, а также наблюдаются значительные колебания RTT — от 3 мс до 1 с.
Очевидно, проблема не решена, и потеря пакетов все еще происходит. Поскольку мы уже проверили канальный уровень, давайте продолжим анализировать сетевой уровень и транспортный уровень, чтобы посмотреть, есть ли там какие-либо проблемы.
Сетевой уровень и транспортный уровень
Мы знаем, что существует множество факторов на сетевом и транспортном уровнях, которые могут вызвать потерю пакетов. Однако подтверждение потери пакетов на самом деле довольно простое, поскольку Linux предоставляет обобщенную информацию об отправке и получении для каждого протокола.
Продолжим работу в терминале контейнера и выполним следующую команду, чтобы увидеть обобщенную информацию об отправке и получении для каждого протокола, а также сообщения об ошибках:
root@nginx: netstat -s
Ip:
Forwarding: 1
31 total packets received
0 forwarded
0 incoming packets discarded
25 incoming packets delivered
15 requests sent out
Icmp:
0 ICMP messages received
0 input ICMP message failed
ICMP input histogram:
0 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
Tcp:
0 active connection openings
0 passive connection openings
11 failed connection attempts
0 connection resets received
0 connections established
25 segments received
21 segments sent out
4 segments retransmitted
0 bad segments received
0 resets sent
Udp:
0 packets received
...
TcpExt:
11 resets received for embryonic SYN_RECV sockets
0 packet headers predicted
TCPTimeouts: 7
TCPSynRetrans: 4
...Команда netstat суммирует статистику отправки и получения для различных протоколов, таких как IP, ICMP, TCP и UDP. Однако, поскольку цель — устранение неполадок с потерей пакетов, нас в основном интересует количество ошибок, потерянных пакетов и повторно переданных пакетов.
Согласно выводу, можно увидеть, что только протокол TCP столкнулся с потерей пакетов и повторными передачами, а именно:
- 11 неудачных попыток подключения
- 4 сегмента ретранслированы
- Получено 11 сбросов для embryonic-сокетов SYN_RECV
- 4 SYN-ретрансляции
- 7 тайм-аутов
Этот результат говорит о том, что в протоколе TCP было несколько тайм-аутов и неудачных попыток соединения, при этом основной ошибкой были сбросы, полученные для embryonic-сокетов SYN_RECV. Другими словами, основные сбои связаны с неудачными трехсторонними рукопожатиями.
Однако, хотя здесь видно много сбоев, конкретная первопричина этих сбоев все еще неизвестна. Поэтому нужно продолжить анализ по стеку протоколов.
iptables
Во-первых, нужно знать, что помимо различных протоколов на сетевом и транспортном уровнях, iptables и механизм отслеживания соединений ядра также могут вызывать потерю пакетов. Поэтому при устранении проблем с потерей пакетов это также является фактором, который нужно исследовать.
Давайте начнем с рассмотрения отслеживания подключений. Чтобы подтвердить, является ли отслеживание подключений причиной проблемы, нужно сравнить текущее количество отслеживаемых подключений с максимальным количеством подключений, которые можно отслеживать.
Однако, поскольку отслеживание соединений в ядре Linux является глобальным (не привязанным к сетевому пространству имен), необходимо выйти из терминала контейнера и вернуться на хост для проверки.
# Запрос конфигурации ядра $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 262144 $ sysctl net.netfilter.nf_conntrack_count net.netfilter.nf_conntrack_count = 182
Отсюда видно, что количество отслеживаемых соединений составляет всего 182, тогда как максимальное количество отслеживаемых соединений — 262144. Очевидно, что потеря пакетов не может быть вызвана отслеживанием соединений.
Далее рассмотрим iptables. В качестве обзора, iptables основан на фреймворке Netfilter и фильтрует (например, брандмауэр) и изменяет (например, NAT) сетевые пакеты с помощью ряда правил.
Эти правила iptables управляются в серии таблиц, включая filter (для фильтрации), nat (для NAT), mangle (для изменения данных пакетов) и raw (для сырых пакетов). Каждая таблица может содержать серию цепочек для группировки и управления правилами iptables.
Для проблем с потерей пакетов наиболее вероятной причиной является то, что пакеты отбрасываются правилами в таблице фильтров. Чтобы определить это, нам нужно подтвердить, выполняются ли правила с действиями типа DROP и REJECT.
Вы можете перечислить все правила iptables и сопоставить их с характеристиками отправляемых и получаемых пакетов. Однако, если правил iptables много, этот метод может быть неэффективным.
Более простой метод — напрямую проверить статистику правил с действиями вроде DROP и REJECT, чтобы увидеть, не равны ли они нулю. Если статистика не равна нулю, можно проанализировать соответствующие правила.
Для просмотра статистики по каждому правилу можно выполнить следующую команду в контейнере:
root@nginx: iptables -t filter -nvL
Chain INPUT (policy ACCEPT 25 packets, 1000 bytes)
pkts bytes target prot opt in out source destination
6 240 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 statistic mode random probability 0.29999999981
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 15 packets, 660 bytes)
pkts bytes target prot opt in out source destination
6 264 DROP all -- * * 0.0.0.0/0 0.0.0.0/0Из вывода iptables видно, что два правила DROP имеют ненулевую статистику. Эти правила находятся в цепочках INPUT и OUTPUT и идентичны. Они используют модуль статистики для случайного отбрасывания 30% пакетов.
Если посмотреть на их критерии соответствия, то 0.0.0.0/0 соответствует всем исходным и конечным IP-адресам, что означает, что эти правила вызывают случайную потерю 30% пакетов для всех пакетов. Это, по-видимому, является основной причиной проблемы потери пакетов.
Теперь, когда мы определили причину, оптимизация относительно проста. Например, удаление этих двух правил решит проблему. Вы можете выполнить следующие две команды iptables в терминале контейнера, чтобы удалить эти правила DROP:
root@nginx: iptables -t filter -D INPUT -m statistic --mode random --probability 0.30 -j DROP root@nginx: iptables -t filter -D OUTPUT -m statistic --mode random --probability 0.30 -j DROP
Была ли решена проблема после удаления правил? Давайте повторно выполним предыдущую команду hping3, чтобы проверить, работает ли она теперь правильно:
$ hping3 -c 10 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=11.9 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.8 ms ... len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=9 win=5120 rtt=15.0 ms --- 192.168.0.30 hping statistic --- 10 packets transmitted, 10 packets received, 0% packet loss round-trip min/avg/max = 3.3/7.9/15.0 ms
На этот раз видно, что потери пакетов отсутствуют, а колебания задержки минимальны. Похоже, проблема потери пакетов решена.
Однако до сих пор мы использовали только инструмент hping3 для проверки того, что сервер Nginx прослушивает порт 80, и еще не обращались к HTTP-сервису Nginx. Поэтому не будем спешить с завершением этой оптимизации. Нам все еще нужно дополнительно подтвердить, может ли Nginx отвечать на HTTP-запросы.
Давайте продолжим и выполним следующую команду curl, чтобы проверить ответ Nginx на HTTP-запросы:
$ curl --max-time 3 http://192.168.0.30 curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received
Из вывода curl видно, что на этот раз соединение истекло по тайм-ауту. Однако мы только что проверили с помощью hping3, что порт открыт. Может ли быть, что Nginx внезапно завершил работу ненормально?
Давайте запустим hping3 еще раз для подтверждения:
$ hping3 -c 3 -S -p 80 192.168.0.30 HPING 192.168.0.30 (eth0 192.168.0.30): S set, 40 headers + 0 data bytes len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=0 win=5120 rtt=7.8 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=1 win=5120 rtt=7.7 ms len=44 ip=192.168.0.30 ttl=63 DF id=0 sport=80 flags=SA seq=2 win=5120 rtt=3.6 ms --- 192.168.0.30 hping statistic --- 3 packets transmitted, 3 packets received, 0% packet loss round-trip min/avg/max = 3.6/6.4/7.8 ms
Странно, результаты hping3 показывают, что порт 80 Nginx действительно открыт. Что нам теперь делать? Давайте не забудем наш козырь — захват пакетов. Кажется, необходимо захватить несколько пакетов для дальнейшей диагностики проблемы.
tcpdump
Далее вернемся к терминалу контейнера Nginx и выполним следующую команду tcpdump для захвата пакетов на порту 80:
root@nginx: tcpdump -i eth0 -nn port 80 tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
Затем снова выполним предыдущую команду curl:
$ curl --max-time 3 http://192.168.0.30/ curl: (28) Operation timed out after 3000 milliseconds with 0 bytes received
После завершения команды curl давайте проверим вывод tcpdump:
14:40:00.589235 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [S], seq 332257715, win 29200, options [mss 1418,sackOK,TS val 486800541 ecr 0,nop,wscale 7], length 0
14:40:00.589277 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [S.], seq 1630206251, ack 332257716, win 4880, options [mss 256,sackOK,TS val 2509376001 ecr 486800541,nop,wscale 7], length 0
14:40:00.589894 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [.], ack 1, win 229, options [nop,nop,TS val 486800541 ecr 2509376001], length 0
14:40:03.589352 IP 10.255.255.5.39058 > 172.17.0.2.80: Flags [F.], seq 76, ack 1, win 229, options [nop,nop,TS val 486803541 ecr 2509376001], length 0
14:40:03.589417 IP 172.17.0.2.80 > 10.255.255.5.39058: Flags [.], ack 1, win 40, options [nop,nop,TS val 2509379001 ecr 486800541,nop,nop,sack 1 {76:77}], length 0После выполнения серии операций из вывода tcpdump мы видим, что:
- Первые три пакета являются частью обычного трехстороннего TCP-рукопожатия, что вполне нормально.
- Однако четвертый пакет появляется на 3 секунды позже и представляет собой пакет FIN, отправленный клиентом (VM2), указывающий на то, что клиент закрыл соединение.
Я полагаю, основываясь на установленном в curl параметре тайм-аута в 3 секунды, вы, вероятно, догадались, что это произошло из-за того, что команда curl истекла по тайм-ауту и была завершена.
Ниже этот процесс изображен с помощью диаграммы потока взаимодействия TCP (на самом деле из Flow Graph Wireshark), чтобы вы могли увидеть проблему более наглядно:

Странно то, что мы не перехватили HTTP GET-запрос, отправленный curl. Так сетевая карта сбросила пакет или клиент вообще его не отправлял?
Мы можем повторно выполнить команду netstat -i, чтобы проверить, есть ли проблемы с потерей пакетов на сетевой карте:
root@nginx: netstat -i Kernel Interface table Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 100 157 0 344 0 94 0 0 0 BMRU lo 65536 0 0 0 0 0 0 0 0 LRU
Из вывода netstat видно, что количество полученных отброшенных пакетов (RX-DRP) составляет 344, что указывает на потерю пакетов на уровне сетевой карты. Однако возникает новый вопрос: почему мы не столкнулись с потерей пакетов при использовании hping3, но теперь не можем получить запрос GET?
Как говорится, когда сталкиваешься с явлениями, которые трудно понять, полезно сначала изучить принципы, лежащие в основе инструментов и методов. Давайте сравним эти два инструмента:
- hping3 на самом деле отправляет только SYN-пакет.
- curl после отправки SYN-пакета также отправляет HTTP-запрос GET.
Запрос HTTP GET по сути является пакетом TCP, но в отличие от пакета SYN он переносит данные HTTP GET.
Имея это сравнение в виду, вы, возможно, уже подумали о проблеме: это может быть связано с неправильной конфигурацией MTU. Почему так?
Если внимательно посмотреть на вывод netstat, то во втором столбце показано значение MTU для каждой сетевой карты. MTU для eth0 составляет всего 100, тогда как MTU по умолчанию для Ethernet составляет 1500, что слишком мало.
Решение проблемы MTU простое. Давайте продолжим в терминале контейнера и выполним следующую команду, чтобы изменить MTU eth0 на 1500:
root@nginx: ifconfig eth0 mtu 1500
После внесения изменений давайте снова выполним команду curl, чтобы убедиться, что проблема решена:
$ curl --max-time 3 http://192.168.0.30/ <!DOCTYPE html> <html> ... <p><em>Thank you for using nginx.</em></p> </body> </html>
Это было нелегко, но на этот раз виден знакомый ответ Nginx, указывающий на то, что проблема потери пакетов полностью решена.
На этом все! Спасибо за внимание! Если статья была интересна, подпишитесь на телеграм-канал usr_bin, где будет еще больше полезной информации.