Лексическая предвзятость алгоритма Facebook

Теперь поговорим о том, что называется предвзятостью лексических настроений. Алгоритм Facebook знает контент, который нравится и не нравится людям. BigData Facebook содержит записи всех понравившихся и ненавистных постов и, разумеется, текст, содержащийся в них. Большинство людей не понимает этого. Facebook хранит в своих базах данных каждый пост, который когда-либо существовал, даже если он был удален, система его бережно сохранила.
По официальным данным, Facebook ежедневно обрабатывает 2,8 миллиарда единиц контента и более 600 терабайт данных. Ежедневно весь контент в соцсети получает 3,2 миллиарда лайков, и в сеть загружается более 450 миллионов фотографий в день. Алгоритм сканирует примерно 105 терабайт данных каждые полчаса.
Алгоритм может анализировать ваш пост и понимать, что тот был действительно негативно воспринят пользователями сети, вызвав большой резонанс, и при этом он содержал определённые словосочетания или слова. Но также был другой пост, и этот пост понравился — люди его очень хорошо приняли, и он содержал совсем другие слова. Таким образом, если вы создаете пост с порядком слов или словосочетаний, которые были у негативных, по мнению алгоритма, постов, это воспринимается им плохо. Совсем другое, когда ваши посты содержат слова, которые использовали ранее в позитивных, по мнению алгоритма, постах, это хороший знак. Здесь я довольно примитивно объяснил, как работает алгоритм, на самом деле все гораздо сложнее. Подробнее об анализе текста можете узнать на сайте Facebook Engineering.
Прежде чем показать вашу рекламу, алгоритм Facebook не ждёт, пока люди начнут взаимодействовать с ней и предоставят обратную связь: комментарий, лайки или что-то ещё. До того как начнутся показы, он будет моделировать, как это будет происходить, прежде чем аудитория увидит ваше объявление.
Это возможно благодаря огромному кластеру обработанных алгоритмом данных, которые позволяют ему определить, как будут работать ваши объявления, до того, как они запустятся на аудитории разных размеров, в зависимости от пола, возраста, интересов, с учётом его содержимого, в том числе текстового. Например, система может понимать, что на самом деле ваше объявление будет лучше воспринято в Московской области, поэтому она должна показать больше это объявление именно там, чтобы сделать его более успешным.
Рассматривая исторические данные, алгоритм можем построить и проверить модель, прежде чем запускать вашу рекламу. Он помещает данные в симуляцию и видит, «увеличит ли это CTR на X % или нет?».
Одна из ключевых вещей анализа объявления, на которую он обращает внимание, — его текст. Основываясь на содержании текста, алгоритм принимает решения. Есть определённые действия, которые мы можем произвести, чтобы убедиться, что текст нашей рекламы — это то, что нравится алгоритму. И мы не станем включать слова, которые не нравятся Facebook, чтобы получить преимущество для своего объявления.
Как алгоритм Facebook это делает? Он использует для этого лексический анализ настроений вашего текста.
Лексическое чувство — это точка зрения или позиция, которую человек, скорее всего, примет, исходя из сочетания слов. Поэтому когда человек читает рекламный текст, у него в голове будут возникать образы, определённые чувства, реакции. Как это работает?
Триггерные слова
Триггерные слова — это слова, которые воспринимаются алгоритмом как плохие, такие словосочетания как «зарабатывать деньги» или, например, что-либо направленное против религии. Вы можете вызвать возмущение у людей, если говорите о религии или используете такие слова как «ненавижу», «расизм». Все эти слова относятся к крайностям. Если вы попытаетесь разместить такую публикацию в интернете, это разожжёт войну в комментариях. Facebook следит за этими темами крайне пристально.
Вероятно, никто из нас не собирается создавать рекламу, которая провоцирует подобные вещи, но иногда мы можем случайно вызвать неправильную реакцию, использовав конкретные слова. Помните: алгоритм не идеален. Сегодня он не может понять, действительно ли текст содержит что-то плохое или нет. Знайте: он просто использует эвристику, чтобы делать окольные предположения, догадки и суждения, которые справедливы большую часть времени, но иногда он ошибается.
Использования этих триггерных слов вы должны избежать любой ценой. Если вы их употребляете, Facebook, скорее всего, отклонит рекламу. Но вместе с этим алгоритм имеет уклон на тексты с оттенком счастья. Алгоритм Facebook может определить, является ли сообщение или реклама негативной или положительной, основываясь на словах в тексте.
Итак, алгоритм имеет тенденцию разделять позитивный контент и негативный для положительного пользовательского опыта. Помните, чего жаждет Facebook? Ему необходимо, чтобы пользователи оставались на платформе и были максимально вовлечены во взаимодействие друг с другом и контентом.
Очевидно, что нейросеть, построенная на среднестатистических людских предпочтениях и относящая пользователей к основному ресурсу, будет доставлять контент «серых» и «чёрных» зон в крайне дозированных масштабах, распределяя его по наименее активной и платежеспособной ЦА. И соответственно, после получения откликов пользователей с негативным контекстом эта реклама будет остановлена, а в отношении всей цепочки рекламодателя будут наложены санкционные меры. Объявление — фан-страница — группа объявлений — кампания — аккаунт — бизнес-менеджер: связанные с этим бизнес-менеджером аккаунты также получат «чёрную метку».
Взлом счастья!

Как сделать рекламу более счастливой? Взломать счастье!
Возьмите свои самые успешные рекламные сообщения и скопируйте их текст в инструмент анализа лексических настроений, чтобы увидеть его оценку. Ставим цель — написать текст, который будет иметь смещение эмоционального оттенка в сторону позитива. Для этого достаточно изменить или добавить слова, усилив этим счастье, без изменения сути текста. Поразительно, это реально крутой инструмент. Я покажу вам, как он работает. Анализ лексического настроения доступен по ссылке: https://tools.adspro.pro/lexical-tool. Ниже приведён пример того, как это работает.
Инструмент выглядит довольно просто. Здесь вы можете ввести слова, выбрать язык и нажать «Анализ». Если я напишу слово «любовь», а затем проанализирую его, результат будет нейтральным, но если я прибавлю слово «смеяться», оно сразу добавит тексту позитивного настроения, что подтвердит инструмент.
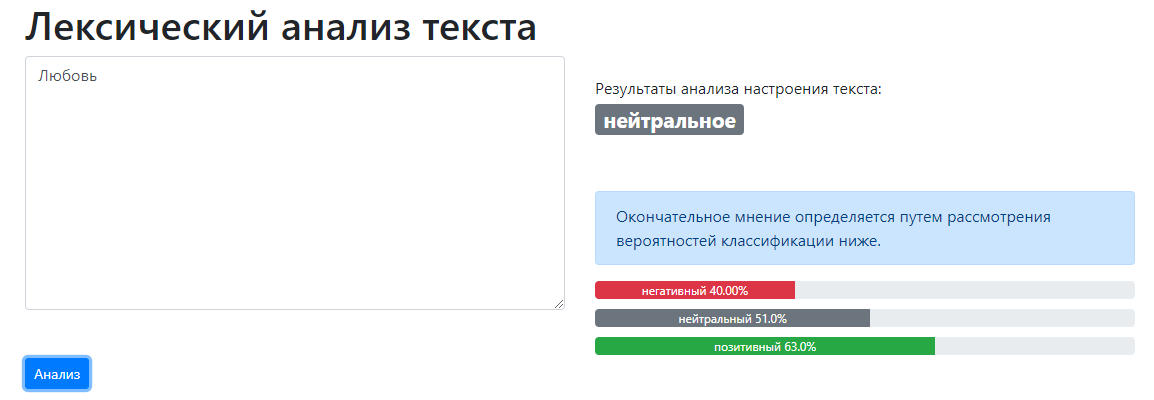
Очень интересно видеть, как он оценивает, является ли что-то счастливым или грустным, основываясь на словах или комбинации слов. Давайте посмотрим, что будет, если мы добавим слово «ненависть» или что-то в этом роде, очевидно, настроение станет негативное.
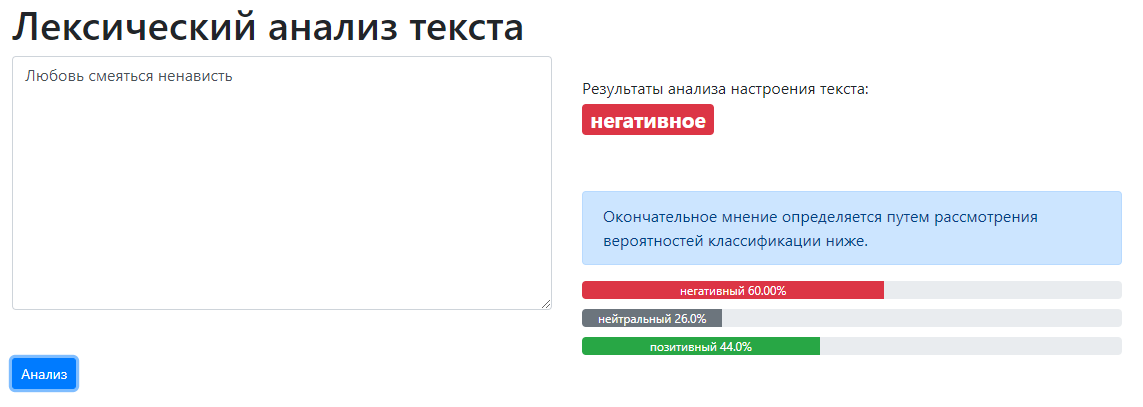
Я не использую этот инструмент для отдельных слов. В этом примере приведены отдельные слова, чтобы наглядно показать, как это работает. Вместо этого полезно анализировать комбинацию слов или полностью текст объявления.
Хорошо, теперь возьмите свой рекламный текст и прогоните его через этот инструмент. Супер, если текст вашего объявления получил позитивное настроение! Если настроение текста вашей рекламы нейтральное, всё в порядке, но вы можете потрудиться и сделать его позитивным.
Ваши тексты будут лучше, если они написаны в позитивном ключе. Людям больше нравится контент, наполненный счастьем. Поэтому если он вызывает в людях позитивные эмоции, алгоритм отдаёт такому посту лучшие позиции в рекламных аукционах, низкую цену и качественный трафик.
Теперь важно уяснить, что нужно не просто написать действительно что-то счастливое, необходимо сохранить призыв к действию, пост должен оставаться едва агрессивным, донося свою точку зрения и подталкивая людей быть достаточно мотивированными, чтобы действовать.
Я рекомендую просмотреть все свои объявления, которые не получили желательного результата, и провести их анализ. Важно найти и заменить слова или словосочетания, которые на самом деле не очень положительны. Придайте тексту больше позитива!
Алгоритм Facebook проводит похожий анализ, так как у него есть предпочтения к текстам, имеющим позитивное настроение.