Фундаментальные основы хакерства. Боремся с дизассемблерами и затрудняем реверс программ
Каждый разработчик программ стремится защитить результат своего труда от взлома. Сегодня нам предстоит исследовать способы противостояния самому популярному виду хакерского инструментария — дизассемблерам. Нашей целью будет запутать хакера, отвадить его от взлома нашей программы, всевозможными способами затруднить ее анализ.
Фундаментальные основы хакерства
Пятнадцать лет назад эпический труд Криса Касперски «Фундаментальные основы хакерства» был настольной книгой каждого начинающего исследователя в области компьютерной безопасности. Однако время идет, и знания, опубликованные Крисом, теряют актуальность. Редакторы «Хакера» попытались обновить этот объемный труд и перенести его из времен Windows 2000 и Visual Studio 6.0 во времена Windows 10 и Visual Studio 2019.
Продолжаем держать оборону нашего приложения от атак злобных хакеров — от их попыток «за просто так» воспользоваться плодами нашего труда, от их подозрительного интереса к нашим программам и скрываемым в них секретам. Для этого мы продолжим создавать изощренные системы защиты, на сей раз — от дизассемблирования.
Чтобы справиться с задачей, нам необходимо узнать о внутренних механизмах операционной системы, о средствах работы с памятью. Также придется разобраться в работе компиляторов, понять, как они генерируют код, вычислить плюсы и минусы оптимизации. И наконец, погрузиться в шифрование, научиться расшифровывать программный код на лету непосредственно перед выполнением.
САМОМОДИФИЦИРУЮЩИЙСЯ КОД В СОВРЕМЕННЫХ ОПЕРАЦИОННЫХ СИСТЕМАХ
В эпоху расцвета MS-DOS программисты широко использовали самомодифицирующийся код, без которого не обходилась практически ни одна мало‑мальски серьезная защита. Да и не только защита — он встречался в компиляторах, компилирующих код непосредственно в память, в распаковщиках исполняемых файлов, в полиморфных генераторах и так далее.
Когда началась массовая миграция пользователей на Windows, разработчикам пришлось задуматься о переносе накопленного опыта и приемов программирования на новую платформу. От бесконтрольного доступа к железу, памяти, компонентам операционной системы и связанных с ними хитроумных трюков программирования пришлось отвыкать. В частности, стала невозможна непосредственная модификация исполняемого кода приложений, поскольку Windows защищает его от непреднамеренных изменений. Это привело к рождению нелепого убеждения, будто под Windows создание самомодифицирующегося кода вообще невозможно, по крайней мере без использования недокументированных возможностей операционной системы.
На самом деле существует как минимум два документированных способа изменить код приложений, хорошо работающих под Windows NT и вполне удовлетворяющихся привилегиями гостевого пользователя.
Во‑первых, kernel32.dll экспортирует функцию WriteProcessMemory, предназначенную, как и следует из ее названия, для модификации памяти процесса. Во‑вторых, практически все операционные системы, включая Windows и Linux, разрешают выполнение и модификацию кода, размещенного в стеке. Между тем современные версии указанных операционных систем накладывают на стек ограничения, мы подробно поговорим об этом чуть позднее.
В принципе, задача создания самомодифицирующегося кода может быть решена исключительно средствами языков высокого уровня, таких, например, как C/C++ и Delphi, без применения ассемблера.
Архитектура памяти Windows
Создание самомодифицирующегося кода требует знания некоторых тонкостей архитектуры Windows, не очень‑то хорошо освещенных в документации. Точнее, совсем не освещенных, но от этого отнюдь не приобретающих статус «недокументированных особенностей», поскольку, во‑первых, они одинаково реализованы на всех Windows-платформах, а во‑вторых, их активно использует компилятор Visual C++ от Microsoft. Отсюда следует, что никаких изменений даже в отдаленном будущем компания не планирует; в противном случае код, сгенерированный этим компилятором, откажет в работе, а на это Microsoft не пойдет (вернее, не должна пойти, если верить здравому смыслу).
В режиме обратной совместимости для адресации четырех гигабайт виртуальной памяти, выделенной в распоряжение процесса, Windows использует два селектора, один из которых загружается в сегментный регистр CS, а другой — в регистры DS, ES и SS. Оба селектора ссылаются на один и тот же базовый адрес памяти, равный нулю, и имеют идентичные лимиты, равные четырем гигабайтам. Помимо перечисленных сегментных регистров, Windows еще использует регистр FS, в который загружает селектор сегмента, содержащего информационный блок потока — TIB.
Фактически существует всего один сегмент, вмещающий в себя и код, и данные, и стек процесса. Благодаря этому управление коду, расположенному в стеке, передается близким (near) вызовом или переходом, и для доступа к содержимому стека использование префикса SS совершенно необязательно. Несмотря на то что значение регистра CS не равно значению регистров DS, ES и SS, команды
• MOV dest,CS:[src]
• MOV dest,DS:[src]
• MOV dest,SS:[src]
в действительности обращаются к одной и той же ячейке памяти.
Это точный прообраз реализованной в процессорах на архитектуре x86-64 RIP-относительной адресации памяти, в которой не используются сегменты.
Отличия между регионами кода, стека и данных заключаются в атрибутах принадлежащих им страниц: страницы кода допускают чтение и исполнение, страницы данных — чтение и запись, а стека — чтение, запись и исполнение одновременно.
Помимо этого, каждая страница имеет специальный флаг, определяющий уровень привилегий, которые необходимы для доступа к этой странице. Некоторые страницы, например те, что принадлежат операционной системе, требуют наличия прав супервизора, которыми обладает только код нулевого кольца. Прикладные программы, исполняющиеся в кольце 3, таких прав не имеют и при попытке обращения к защищенной странице порождают исключение. Манипулировать атрибутами страниц, равно как и ассоциировать страницы с линейными адресами, может только операционная система или код, исполняющийся в нулевом кольце.
Среди начинающих программистов ходит совершенно нелепая байка о том, что, если обратиться к коду программы командой, предваренной префиксом DS, Windows якобы беспрепятственно позволит его изменить. На самом деле это в корне неверно — обратиться‑то она позволит, а вот изменить — нет, каким бы способом ни происходило обращение, так как защита работает на уровне физических страниц, а не логических адресов.
Использование функции WriteProcessMemory
Если требуется изменить некоторое количество байтов своего (или чужого) процесса, самый простой способ сделать это — вызвать функцию WriteProcessMemory. Она позволяет модифицировать существующие страницы памяти, чей флаг супервизора не взведен, то есть все страницы, доступные из кольца 3, в котором выполняются прикладные приложения. Совершенно бесполезно с помощью WriteProcessMemory пытаться изменить критические структуры данных операционной системы (например, page directory или page table) — они доступны лишь из нулевого кольца. Поэтому указанная функция не представляет никакой угрозы для безопасности системы и успешно вызывается независимо от уровня привилегий пользователя.
Процесс, в память которого происходит запись, должен быть предварительно открыт функцией OpenProcess с атрибутами доступа PROCESS_VM_OPERATION и PROCESS_VM_WRITE. Часто программисты, ленивые от природы, идут более коротким путем, устанавливая все атрибуты — PROCESS_ALL_ACCESS. И это вполне законно, хотя справедливо считается дурным стилем программирования.
Далее приведен простой пример self-modifying_code, иллюстрирующий использование функции WriteProcessMemory для создания самомодифицирующегося кода:
#include <iostream>
#include <Windows.h>
using namespace std;
int WriteMe(void* addr, int wb)
{HANDLE h = OpenProcess(PROCESS_VM_OPERATION | PROCESS_VM_WRITE, true, GetCurrentProcessId());
return WriteProcessMemory(h, addr, &wb, 1, NULL);
}
int main(int argc, char* argv[])
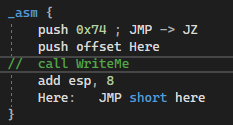
{_asm {push 0x74 ; JMP -> JZ
push offset Here
call WriteMe
add esp, 8
Here: JMP short here
}
cout << "#JMP SHORT $-2 was changed to JZ $-2\n";
return 0;
}
Функция WriteProcessMemory в рассматриваемой программе заменяет инструкцию бесконечного цикла JMP short $-2 условным переходом JZ $-2, который продолжает нормальное выполнение программы. Неплохой способ затруднить взломщику изучение приложения, не правда ли? Особенно если вызов WriteMe не расположен возле изменяемого кода, а помещен в отдельный поток. Будет еще лучше, если модифицируемый код вполне естественен сам по себе и внешне не вызывает никаких подозрений. В этом случае хакер может долго блуждать в той ветке кода, которая при выполнении программы вообще не получает управления.
Для компиляции этого примера установи 32-битный режим результирующего кода.

Если из ассемблерной вставки убрать вызов функции WriteMe, которая перезаписывает инструкцию JMP на JZ, программа выпадет в бесконечный цикл.
Об устройстве Windows: исторический нюанс
Поскольку Windows для экономии оперативной памяти разделяет код между процессами, возникает вопрос: а что произойдет, если запустить вторую копию самомодифицирующейся программы? Создаст ли операционная система новые страницы или отошлет приложение к уже модифицируемому коду? В документации на Windows NT сказано, что она поддерживает копирование при записи (copy on write), то есть автоматически дублирует страницы кода при попытке их модифицировать. Напротив, Windows 9x не поддерживает такую возможность. Означает ли это, что все копии самомодифицирующегося приложения будут вынуждены работать с одними и теми же страницами кода (а это неизбежно приведет к конфликтам и сбоям)?
Нет, и вот почему: несмотря на то что копирование при записи в Windows 9x не реализовано, эту заботу берет на себя сама функция WriteProcessMemory, создавая копии всех модифицируемых страниц, распределенных между процессами. Благодаря этому самомодифицирующийся код одинаково хорошо работает как под Windows 9x, так и под Windows NT. Однако следует учитывать, что все копии приложения, модифицируемые любым иным путем (например, командой mov нулевого кольца), если их запустить под Windows 9x, будут разделять одни и те же страницы кода со всеми вытекающими отсюда последствиями.
Теперь об ограничениях. Во‑первых, использовать WriteProcessMemory разумно только в компилирующих в память компиляторах или распаковщиках исполняемых файлов, а в защитах — несколько наивно. Мало‑мальски опытный взломщик быстро обнаружит подвох, увидев эту функцию в таблице импорта. Затем он установит точку останова на вызов WriteProcessMemory и будет контролировать каждую операцию записи в память. А это никак не входит в планы разработчика защиты!
Другое ограничение WriteProcessMemory заключается в невозможности создания новых страниц, ей доступны лишь существующие страницы. А как быть, если требуется выделить некоторое количество памяти, например для кода, динамически генерируемого на лету? Вызов функций управления кучей, таких как malloc или new, не поможет, поскольку в куче выполнение кода запрещено. И вот тогда‑то на помощь приходит возможность выполнения кода в стеке...
ВЫПОЛНЕНИЕ КОДА В СТЕКЕ
Разрешение на выполнение кода в стеке объясняется тем, что исполняемый стек необходим многим программам, в том числе и самой операционной системе для выполнения некоторых системных функций. Благодаря этому компиляторам и компилирующим интерпретаторам проще генерировать код.
Однако вместе с этим увеличивается и потенциальная угроза атаки. Если выполнение кода в стеке разрешено и при определенных обстоятельствах из‑за ошибок реализации управление передается на введенные пользователем данные, злоумышленник получает возможность передать и выполнить на удаленной машине свой собственный зловредный код. Для операционных систем Solaris и Linux можно установить «заплатки», которые запретят исполнение кода в стеке, но они не имеют большого распространения, поскольку делают невозможной работу множества программ. Большинству пользователей легче смириться с угрозой атаки, чем остаться без необходимых приложений.
Не все гладко с исполнением кода в стеке в ОС Windows. Начиная со второго пакета обновления для Windows XP, в системе появилась функция безопасности DEP (Data Execution Prevention). Во включенном состоянии она запрещает выполнение кода на определенных страницах памяти, в том числе и в стеке. Но, как в случае с *.nix-системами, ее часто отключают, чтобы пользоваться компьютером по полной.
Поэтому использование стека для выполнения самомодифицирующегося кода вполне законно и системно‑независимо, то есть универсально. Помимо этого, такое решение устраняет оба недостатка функции WriteProcessMemory:
- Во‑первых, выявлять и отслеживать модифицирующие заранее неизвестную ячейку памяти команды чрезвычайно трудно, и взломщику придется провести кропотливый анализ кода защиты без надежды на скорый успех (при условии, что сам защитный механизм реализован без грубых ошибок, облегчающих задачу хакера).
- Во‑вторых, приложение в любой момент может выделить столько стековой памяти, сколько ему заблагорассудится, а затем, при исчезновении потребности, ее освободить. По умолчанию система резервирует один мегабайт стекового пространства, а если этого для решения поставленной задачи недостаточно, нужное количество можно указать при компоновке программы.
Замечательно, что для выполняющихся в стеке программ справедлив принцип фон Неймана — в один момент времени текст программы может рассматриваться как данные, а в другой — как исполняемый код. Именно это необходимо для нормальной работы всех распаковщиков и расшифровщиков исполняемого кода.
Однако программирование кода, выполняющегося в стеке, имеет ряд специфических особенностей.
«Подводные камни» перемещаемого кода
При разработке выполняющегося в стеке кода следует учитывать, что в разных версиях Windows местоположение стека может различаться и, чтобы сохранить работоспособность при переходе от одной системы к другой, код должен быть безразличен к адресу, по которому он будет загружен. Такой код называют перемещаемым, и в его создании нет ничего сложного: достаточно следовать нескольким простым соглашениям.
Замечательно, что у микропроцессоров серии Intel 80x86 все короткие переходы (short jump) и близкие вызовы (near call) относительны, то есть содержат не линейный целевой адрес, а разницу целевого адреса и адреса следующей выполняемой инструкции. Это значительно упрощает создание перемещаемого кода, но вместе с этим накладывает на него некоторые ограничения.
Что произойдет, если вот такую функцию скопировать в стек и передать ей управление?
void Demo()
{
printf("Demo\n");
}Поскольку инструкция call, вызывающая функцию printf, «переехала» на новое место, разница адресов вызываемой функции и следующей за call инструкции станет совсем иной и управление получит отнюдь не printf, а не имеющий к ней никакого отношения код! Вероятнее всего, им окажется «мусор», порождающий исключение с последующим аварийным закрытием приложения.
Программируя на ассемблере, такое ограничение можно легко обойти, используя регистровую адресацию. Перемещаемый вызов функции printf упрощенно может выглядеть, например, так:
lea eax, printfcall eax
В регистр EAX (или любой другой регистр общего назначения) заносится абсолютный линейный, а не относительный адрес, и независимо от положения инструкции call управление будет передано функции printf, а не чему‑то еще.
Однако такой подход требует знания ассемблера, поддержки компилятором ассемблерных вставок и не очень‑то нравится прикладным программистам, не интересующимся командами и устройством процессора.
Для решения этой задачи исключительно средствами языка высокого уровня необходимо передать стековой функции указатели на вызываемые ею функции в виде аргументов. Это несколько неудобно, но более короткого пути, по‑видимому, не существует. Далее приведен текст программы stack_execute, иллюстрирующей копирование и выполнение функции в стеке:
#include <stdio.h>
void Demo(int (*_printf) (const char*, ...))
{_printf("Hello, World!\n");return;
}
int main(int argc, char* argv[])
{char buff[1000];
int (*_printf) (const char*, ...);
int(*_main) (int, char**);
void (*_Demo) (int (*) (const char*, ...));
_printf = printf;
_main = main;
_Demo = Demo;
int func_len = (unsigned int)_main - (unsigned int)_Demo;
for (int a = 0; a < func_len; a++)
buff[a] = ((char*)_Demo)[a];
_Demo = (void (*) (int (*) (const char*, ...))) &buff[0];
_Demo(_printf);
return 0;
}
Но не спеши компилировать и запускать приложение. Для построения программы надо выбрать платформу x86 и режим выпуска Release. В противном случае, хотя приложение будет успешно построено, оно не выведет приветственную строку на экран, так как при установке режима Release автоматически отключаются отладочные механизмы компиляции, которые в данном случае могут испортить картину.
Вдобавок надо отключить DEP. Когда он включен, как мы знаем, Windows накладывает запрет на исполнение кода в стеке, следовательно, программа stack_execute ничего не выведет на экран и сразу завершит свой процесс, потому что, произведя определенные манипуляции, она копирует функцию Demo в стек и запускает ее уже оттуда. И только последняя выводит строку на консоль.
В нашем случае включение программы в список исключений DEP не увенчалось успехом, stack_execute в таком случаем по‑прежнему не выводила строку.
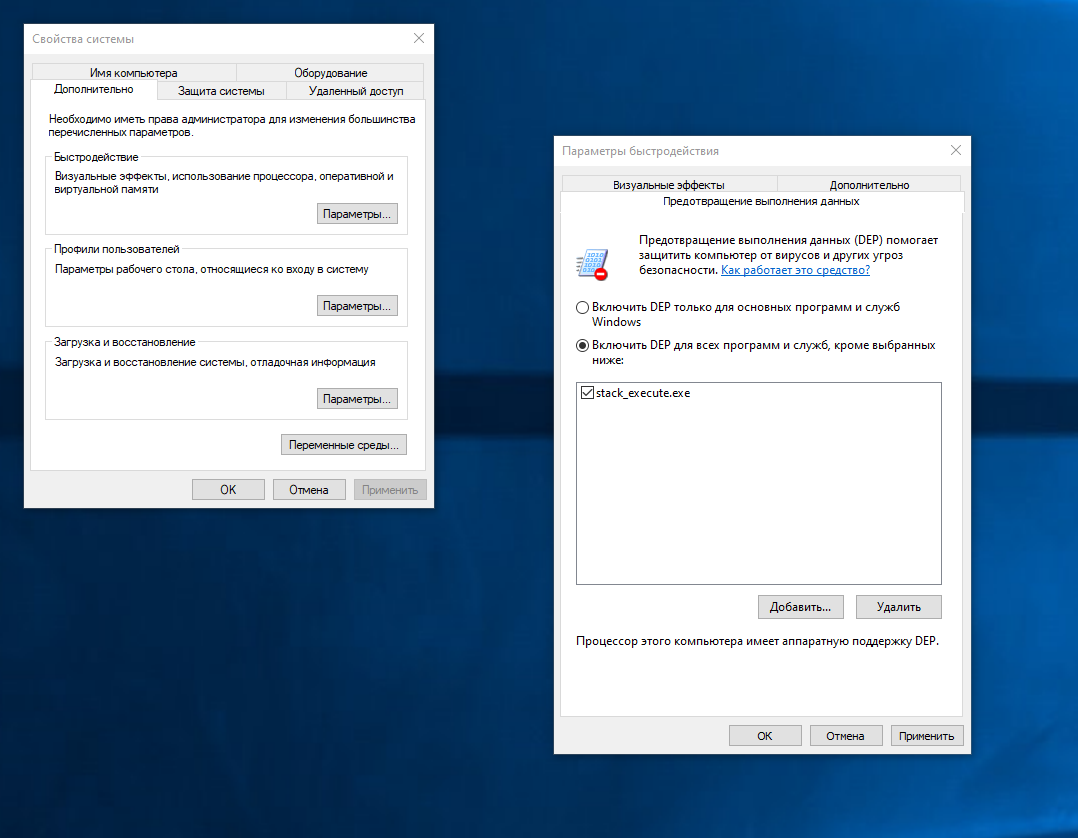
Поэтому пришлось отключить DEP глобально, на уровне всей системы. В запущенной от имени администратора консоли надо ввести:
bcdedit.exe /set {current} nx AlwaysOff— чтобы выключить DEP;bcdedit.exe /set {current} nx AlwaysOn— чтобы включить DEP.
Совет
Дополнительно нелишним будет отключить оптимизацию: во‑первых, так удобнее отлаживать программу, поскольку оптимизатор «съедает» ненужные, на его взгляд, переменные; во‑вторых, они могут быть проинициализированы, но, по мнению компилятора, не использованы, из‑за чего они опять будут удалены из бинарника. А это, в свою очередь, может сказаться на правильной работе приложения. Да, бывает и такое. Поэтому надо следить за работой компилятора, чтобы он не удалил чего‑нибудь лишнего!
После перезагрузки операционной системы stack_execute будет работать как надо и выводить приветственную строку.

Кроме того, обрати внимание, как функция printf в предыдущем листинге выводит приветствие на экран. На первый взгляд, ничего необычного, но задумайся, где размещена строка «Hello, World!». Разумеется, не в сегменте кода — там ей не место (хотя некоторые компиляторы помещают ее именно туда). Выходит, в сегменте данных, там, где ей и положено быть? Но если так, то одного лишь копирования тела функции окажется явно недостаточно, придется скопировать и саму строковую константу. А это утомительно. Но существует и другой способ — создать локальный буфер и инициализировать его по ходу выполнения программы, например так:
...buf[666]; buff[0] = 'H'; buff[1] = 'e'; buff[2] = 'l'; buff[3]= 'l'; buff[4]= 'o';
Не самый короткий, но из‑за его простоты широко распространенный путь.
Плюсы и минусы оптимизирующих компиляторов
Применяя языки высокого уровня для разработки выполняемого в стеке кода, следует учитывать особенности реализаций используемых компиляторов и, прежде чем останавливать свой выбор на каком‑то одном из них, основательно изучить прилагаемую документацию. В большинстве случаев код функции, скопированный в стек, с первой попытки запустить не получится, особенно если включена оптимизированная компиляция.
Так происходит потому, что на чистом языке высокого уровня, таком как C/C++ или Delphi, скопировать код функции в стек (или куда‑то еще) принципиально невозможно, поскольку стандарты языка не оговаривают, каким именно образом должна выполняться компиляция. Программист может получить указатель на функцию, но в стандарте не описано, как следует ее интерпретировать. С точки зрения программиста, она представляет «магическое число», в назначение которого посвящен один лишь компилятор.
К счастью, логика кодогенерации большинства компиляторов более или менее одинакова, и это позволяет прикладной программе сделать некоторые предположения об организации откомпилированного кода.
В частности, программа, рассмотренная ранее, молчаливо полагает, что указатель на функцию совпадает с точкой входа в эту функцию, а все тело функции расположено непосредственно за точкой входа. Именно такой код (наиболее очевидный с точки зрения здравого смысла) и генерирует подавляющее большинство компиляторов. Большинство, но не все! Тот же Microsoft Visual C++ в режиме отладки вместо функций вставляет «переходники», а сами функции размешает совсем в другом месте. В результате в стек копируется содержимое «переходника», но не само тело функции! Из‑за этого при компиляции нашего примера был выбран режим Release.
У других компиляторов способ переключения этой опции может значительно отличаться, а в худшем случае — вообще отсутствовать. Если это так, придется отказаться либо от самомодифицирующегося кода, либо от данного компилятора.
Еще одна проблема: как достоверно определить длину тела функции? Язык C/C++ не дает никакой возможности узнать значение этой величины, а оператор sizeof возвращает размер указателя на функцию, но не размер самой функции. Одно из возможных решений опирается на тот факт, что компиляторы, как правило, располагают функции в памяти согласно порядку их объявления в исходной программе. Следовательно, длина тела функции равна разности указателя на следующую за ней функцию и указателя на данную функцию.
Поскольку Windows-компиляторы в режиме x86 представляют указатели 32-разрядными целыми числами, их можно безболезненно преобразовывать в тип unsigned int и выполнять над ними различные математические операции. К сожалению, оптимизирующие компиляторы не всегда располагают функции в таком простом порядке, а в некоторых случаях даже «разворачивают» их, подставляя содержимое функции на место ее вызова. Поэтому соответствующие режимы оптимизации (если они есть) придется отключить.
Другое коварство оптимизирующих компиляторов (как мы видели выше, когда настраивали компилятор) заключается в том, что они выкидывают ими все не используемые (с их точки зрения) переменные. Например, в приведенной выше программе в буфер buff что‑то пишется, но ничего оттуда не читается! А передачу управления на буфер большинство компиляторов (в том числе и Microsoft Visual C++) распознать не в силах, вот они и опускают копирующий код, отчего управление передается на неинициализированный буфер с очевидными последствиями. Если возникнут подобные проблемы, попробуй отключить оптимизацию вообще (плохо, конечно, но надо).
Откомпилированная программа по‑прежнему не работает? Вероятнее всего, причина в том, что компилятор вставляет в конец каждой функции вызов процедуры, контролирующей состояние стека. Именно так ведет себя Microsoft Visual C++, помещая в отладочные проекты вызов функции chkesp (не ищи ее описания в документации — его там нет). А вызов этот, как нетрудно догадаться, относительный! К сожалению, никакого документированного способа это запретить, по‑видимому, не существует, но в финальных (Release) проектах Microsoft Visual C++ не контролирует состояние стека при выходе из функции, и все работает нормально.
САМОМОДИФИЦИРУЮЩИЙСЯ КОД КАК СРЕДСТВО ЗАЩИТЫ ПРИЛОЖЕНИЙ
И вот после стольких мытарств и ухищрений злополучный пример запущен и победно выводит на экран «Hello, World!». Резонный вопрос: а зачем, собственно, все это нужно? Какая выгода от того, что функция будет исполнена в стеке? Ответ: код функции, исполняющейся в стеке, можно прямо на лету изменять, например расшифровать ее.
Шифрованный код чрезвычайно затрудняет дизассемблирование и усиливает стойкость защиты, а какой разработчик не хочет уберечь свою программу от хакеров? Разумеется, одна лишь шифровка кода не очень‑то серьезное препятствие для взломщика, снабженного отладчиком или продвинутым дизассемблером наподобие IDA Pro.
Простейший алгоритм шифрования заключается в последовательной обработке каждого элемента исходного текста операцией «исключающее ИЛИ» (XOR). Повторное применение XOR к зашифрованному тексту позволяет вновь получить исходный текст.
Следующий пример save_demo_to_file читает содержимое функции Demo, зашифровывает его и записывает полученный результат в файл, после чего открывает файл с диска, загружает данные, расшифровывает последовательность байтов и исполняет их, как ни в чем не бывало:
#include <stdio.h>
#include <memory.h>
void Demo(int (*_printf) (const char*, ...))
{_printf("Hello, World!\n");return;
}
int write_file(const char* filename, unsigned char* buff, const int func_len)
{FILE* f;
if (fopen_s(&f, filename, "wb") == 0) {for (int a = 0; a < func_len; a++) {unsigned char c = buff[a] ^ 0x77;
buff[a] = c;
fputc(c, f);
}
fclose(f);
}
else return -1;
return 0;
}
int read_file(const char* filename, unsigned char* buff, const int func_len)
{FILE* f;
if (fopen_s(&f, "Data.bin", "rb") == 0) {int bc = 0;
while (!feof(f)) {unsigned char c = fgetc(f);
buff[bc] = c ^ 0x77;
bc++;
}
fclose(f);
}
else return -1;
return 0;
}
int main(int argc, char* argv[])
{unsigned char buff[1000];
void (*_Demo) (int (*) (const char*, ...));
int(*_main) (int, char**);
int (*_printf) (const char*, ...);
_Demo = Demo;
_main = main;
_printf = printf;
int func_len = (unsigned int)_main - (unsigned int)_Demo;
for (int a = 0; a < func_len; a++)
buff[a] = ((unsigned char*)_Demo)[a];
const char* fname = "Data.bin";
// Выводим последовательность байтов на экран
printf("%s\n", buff);// Зашифровываем последовательность байтов и пишем в файл
write_file(fname, buff, func_len);
// Выводим измененную последовательность байтов на экран
printf("%s\n", buff);// Очищаем массив байтов
memset(buff, 0, 1000);
// Выводим обнуленную последовательность байтов на экран
printf("%s\n", buff);// Читаем байты из файла, одновременно расшифровывая их
read_file(fname, buff, func_len);
// Выводим итоговую последовательность байтов на экран
printf("%s\n", buff);_Demo = (void (*) (int (*) (const char*, ...))) &buff[0];
_Demo(_printf);
return 0;
}
Чтобы скомпилировать программу, установи для среды разработки те же параметры, что были в прошлом проекте: платформа — x86, режим — Release. Также можешь отключить оптимизацию.
Для наглядности выполняемые программой операции помещены в отдельные функции. Как уже было сказано выше, функция Demo выступает объектом эксперимента: сначала она читается из основной функции main, тем самым ее тело сохраняется в массиве байтов buff. Затем имя файла для сохранения, этот буфер и его длина передаются функции write_file, которая побайтно записывает содержимое буфера в файл, одновременно шифруя каждый байт. При этом в буфере зашифрованный байт заменяет исходный. Закончив свое выполнение, функция write_file возвращает в полученном параметре указатель на модифицированный буфер.
После вывода содержимого буфера на консоль программа очищает его и вызывает функцию read_file, передавая ей имя файла, который надо прочесть, обнуленный буфер и его длину. Открыв заданный двоичный файл, read_file читает его до конца, перебирая, расшифровывая и сохраняя в буфере каждый байт. Когда весь файл расшифрован, а буфер заполнен, указатель на него в полученном параметре возвращается в основную функцию, где происходит присвоение содержимого массива байтов ранее объявленному указателю _Demo на функцию, имеющую прототип функции Demo.
Наконец, с помощью указывающего в стек указателя программа вызывает функцию Demo, только что загруженную из файла.
Обрати внимание: после каждой операции программа выводит содержимое буфера на экран. Таким образом, завершив свое выполнение, программа оставляет в консоли следующий вывод.

Плюс в папке с программой появляется файл Data.bin, содержащий двоичный зашифрованный код функции Demo.
Зашифрованный код — следующий уровень защиты приложений
Хотя теперь прежде, чем выполнять код, программа проворачивает с ним каверзные манипуляции, для хакера с дизассемблером и пятью минутами лишнего времени не составит большого труда разобраться в хитросплетениях кода.
А что, если из исходного текста программы напрочь удалить функцию Demo, а взамен поместить ее зашифрованное содержимое в строковой переменной (впрочем, необязательно именно строковой)? Затем в нужный момент это содержимое может быть расшифровано, скопировано в локальный буфер и вызвано для выполнения. Один из вариантов реализации зашифрованной программы приведен в следующем листинге — cipher_program:
#include <stdio.h>
#include <string.h>
#include <cstdlib>
int main(int argc, char* argv[])
{
char buff[1000] = "";
int (*_printf) (const char*, ...);
void (*_Demo) (int (*) (const char*, ...));
// Эта последовательность байтов должна быть записана в одну строку
char code[] = "\x22\xFC\x9B\xF4\x9B\x67\xB1\x32\x87\x3F\xB1\x32\x86\x12\xB1\x32\x85\x1B\xB1\x32\x84\x1B\xB1\x32\x83\x18\xB1\x32\x82\x5B\xB1\x32\x81\x57\xB1\x32\x80\x20\xB1\x32\x8F\x18\xB1\x32\x8E\x05\xB1\x32\x8D\x1B\xB1\x32\x8C\x13\xB1\x32\x8B\x56\xB1\x32\x8A\x7D\xB1\x32\x89\x77\xFA\x32\x87\x27\x88\x22\x7F\xF4\xB3\x73\xFC\x92\x2A\xB4";
_printf = printf;
int code_size = _countof(code);
if (strcpy_s(buff, code_size, code) == 0) {
for (int a = 0; a < code_size; a++)
buff[a] = buff[a] ^ 0x77;
_Demo = (void (*) (int (*) (const char*, ...))) &buff[0];
_Demo(_printf);
}
return 0;
}Чтобы построить программу, нужно, как в прошлый раз, выбрать платформу x86, режим — Release. И, возможно, отключить оптимизацию.

Теперь даже при наличии исходных текстов алгоритм работы функции Demo будет представлять загадку! Этим обстоятельством можно воспользоваться, чтобы скрыть некоторую критическую информацию, например процедуру генерации ключа или проверку серийного номера.
Проверку серийного номера желательно организовать так, чтобы даже после расшифровки кода ее алгоритм представлял бы головоломку для хакера.
ЗАКЛЮЧЕНИЕ
Многие считают использование самомодифицирующегося кода «дурным» примером программирования и обвиняют его в том, что он не переносим, плохо совместим с разными операционными системами, требует обязательно обращаться к ассемблеру и так далее. С появлением Windows NT этот список пополнился еще одним умозаключением, дескать, самомодифицирующийся код — только для MS-DOS, в нормальных же операционных системах он невозможен.
Как показывает статья, все эти предположения, мягко выражаясь, неверны. Другой вопрос: так ли необходим самомодифицирующийся код и можно ли без него обойтись? Низкая эффективность существующих защит (обычно программы ломаются быстрее, чем успевают дойти до легального потребителя) и огромное количество программистов, стремящихся «топтанием клавиш» заработать себе на хлеб, свидетельствует, что необходимо усиливать защитные механизмы любыми доступными средствами, в том числе и рассмотренным выше самомодифицирующимся кодом.
В противостоянии разработчиков легального софта и взломщиков с их изощренным инструментарием самомодифицирующийся код выступает на стороне первых. Хотя в текущих условиях он предоставляет не настолько изящные механизмы, которые были доступны в эпоху MS-DOS, даже сейчас в руках опытного программиста они позволяют реализовать достойную защиту только с использованием языков высокого уровня.