Ныряем в тему: text-to-image generators

Все эти изображения созданы AI от Google. Разбираемся в новом горячем тренде - создание картинок при помощи искусственного интеллекта.
Оригинал: ALL THESE IMAGES WERE GENERATED BY GOOGLE’S LATEST TEXT-TO-IMAGE AI
Генераторы изображений из текста сейчас "в огне". Отправьте этим программам любой текст, который вам нравится, и они создадут удивительно точные изображения, соответствующие описанию. Они могут соответствовать различным стилям, от картин маслом до CGI-рендеров и даже фотографий, и - хотя это звучит банально - во многих отношениях единственным пределом является ваше воображение.
На сегодняшний день лидером в этой области является программа DALL-E, созданная коммерческой лабораторией OpenAI (и обновленная только в апреле). Однако вчера компания Google представила свой собственный вариант развития жанра - Imagen, и он просто превзошел DALL-E по качеству результатов.
Лучший способ понять удивительные возможности этих моделей - просто просмотреть некоторые изображения, которые они могут генерировать. Вот несколько изображений, созданных Imagen, выше, и еще больше ниже (вы можете увидеть больше примеров на специальной странице Google).
В каждом случае текст в нижней части изображения был подсказкой, поданной в программу, а картинка выше - результатом. Подчеркнем: это все, что требуется. Вы вводите то, что хотите увидеть, и программа генерирует это. Довольно фантастично, правда?
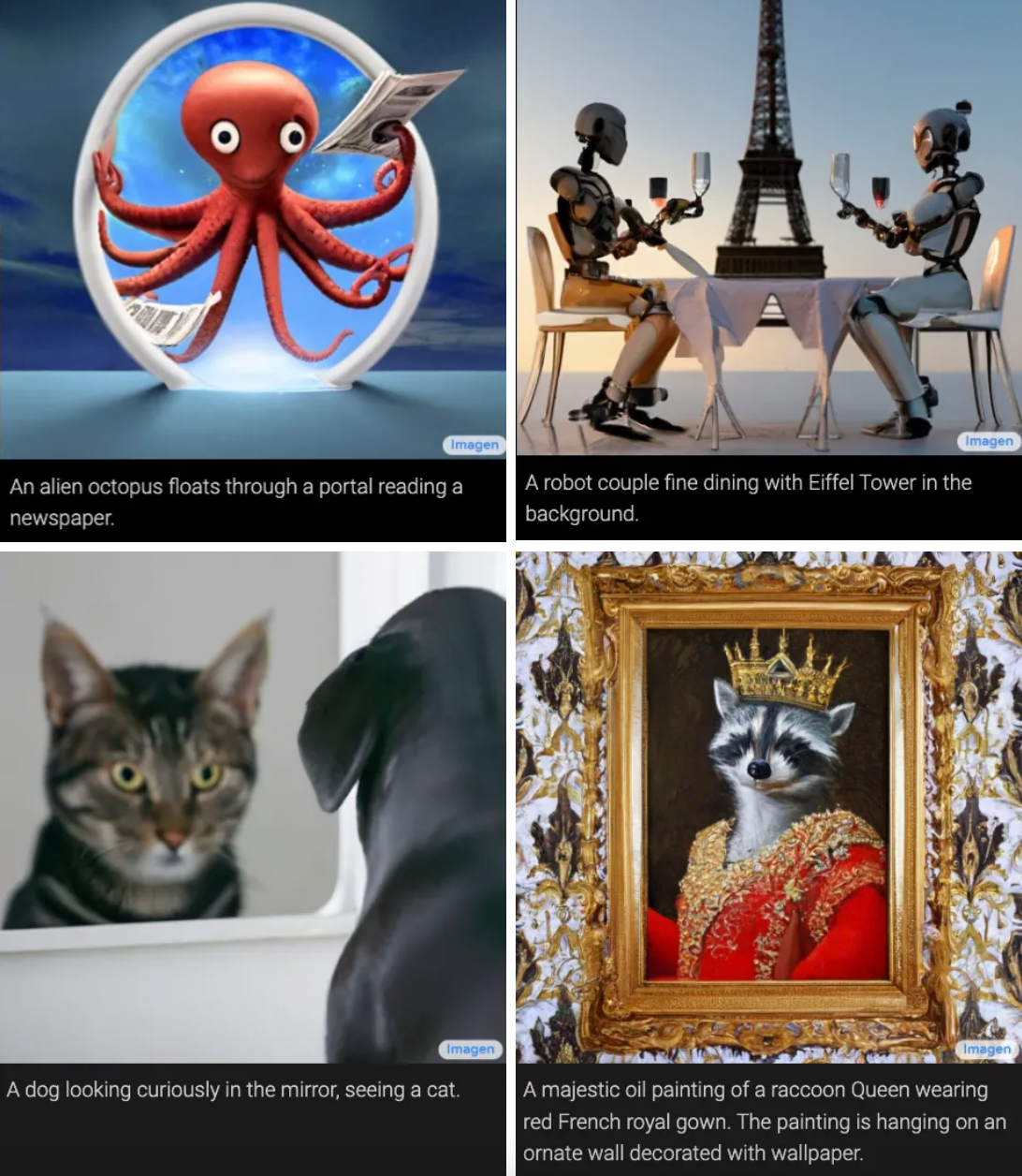
Но хотя эти картинки, бесспорно, впечатляют своей гладкостью и точностью, их также следует воспринимать с щепоткой скепсиса. Когда исследовательские группы, такие как Google Brain, выпускают новую модель ИИ, они, как правило, отбирают лучшие результаты. Поэтому, хотя все эти фотографии выглядят идеально отполированными, они могут не отражать средний результат работы системы Image.
ПОМНИТЕ: GOOGLE ДЕМОНСТРИРУЕТ ТОЛЬКО САМЫЕ ЛУЧШИЕ ИЗОБРАЖЕНИЯ
Часто изображения, созданные с помощью моделей преобразования текста, выглядят незаконченными, размазанными или нечеткими - проблемы, которые мы наблюдали на картинках, созданных программой DALL-E от OpenAI. (Чтобы узнать больше о проблемных местах для систем "текст-изображение", ознакомьтесь с этой интересной темой в Twitter, посвященной проблемам с DALL-E. В ней, среди прочего, подчеркивается склонность системы к неправильному пониманию подсказок и сложности при работе как с текстом, так и с лицами).
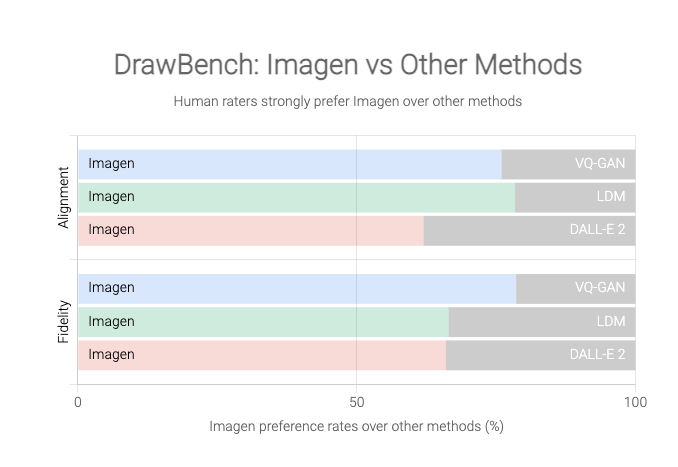
Google, однако, утверждает, что Imagen создает постоянно лучшие изображения, чем DALL-E 2, основываясь на новом эталоне, который он создал для этого проекта под названием DrawBench.
DrawBench не является особенно сложной метрикой: по сути, это список из 200 текстовых подсказок, которые команда Google подавала в Imagen и другие программы для преобразования текста в изображение, а затем результаты работы каждой программы оценивались человеческими экспертами. Как показано на графиках ниже, Google обнаружил, что люди в целом предпочитают результаты Imagen результатам конкурентов.
Однако нам самим будет трудно судить об этом, поскольку Google не предоставляет модель Imagen в открытый доступ. И на это есть веские причины. Хотя модели преобразования текста в изображение, безусловно, обладают фантастическим творческим потенциалом, они также имеют ряд проблемных применений. Представьте себе, что система, генерирующая практически любое изображение, которое вам нравится, используется, например, для фальшивых новостей, мистификаций или преследования. Как отмечает Google, эти системы также кодируют социальные предубеждения, и их результаты часто являются расистскими, сексистскими или токсичными в какой-либо другой изобретательной форме.
СТАРАЯ МУДРОСТЬ ВСЕ ЕЩЕ ПРИМЕНИМА К АИ: МУСОР ВНУТРЬ, МУСОР НАРУЖУ
Во многом это связано с тем, как программируются эти системы. По сути, они обучаются на огромных объемах данных (в данном случае: множество пар изображений и подписей), которые они изучают на предмет закономерностей и учатся их воспроизводить. Но этим моделям нужно чертовски много данных, и большинство исследователей - даже те, кто работает на таких финансируемых технологических гигантов, как Google, - решили, что всесторонняя фильтрация этих данных слишком обременительна. Поэтому они парсят огромное количество данных из Интернета, и, как следствие, их модели поглощают (и учатся воспроизводить) всю ненавистную желчь, которую можно найти в Интернете.
Как резюмируют эту проблему исследователи Google в своей статье: "Требования моделей преобразования текста в изображение к большим объемам данных [...] привели к тому, что исследователи стали в значительной степени полагаться на большие, в основном необработанные, веб-скраппированные наборы данных [...] Аудит показал, что эти наборы данных, как правило, отражают социальные стереотипы, угнетающие точки зрения и унизительные или иные вредные ассоциации с маргинализированными группами личности".
Другими словами, хорошо известная поговорка компьютерщиков все еще применима в мире искусственного интеллекта: мусор внутрь, мусор наружу.

Google не слишком подробно описывает тревожный контент, созданный Imagen, но отмечает, что модель "кодирует несколько социальных предубеждений и стереотипов, включая общее предубеждение к созданию изображений людей со светлым цветом кожи и тенденцию к тому, чтобы изображения, показывающие различные профессии, соответствовали западным гендерным стереотипам".
Это то, что исследователи также обнаружили при оценке DALL-E. Попросите DALL-E сгенерировать изображения, например, "стюардессы", и почти все испытуемые будут женщинами. Попросите создать изображения "генерального директора", и, сюрприз, сюрприз, вы получите кучу белых мужчин.
По этой причине OpenAI также решила не выпускать DALL-E в открытый доступ, но компания предоставляет доступ избранным бета-тестерам. Она также фильтрует определенные текстовые данные, пытаясь предотвратить использование модели для создания расистских, насильственных или порнографических изображений. Эти меры в какой-то мере ограничивают потенциально вредное применение этой технологии, но история ИИ говорит нам, что такие модели преобразования текста в изображение почти наверняка станут общедоступными в какой-то момент в будущем, со всеми тревожными последствиями, которые влечет за собой более широкий доступ.
Google пришел к выводу, что Imagen "не подходит для публичного использования в настоящее время", и компания заявляет, что планирует разработать новый способ оценки "социальной и культурной предвзятости в будущей работе" и протестировать будущие итерации. Однако пока нам придется довольствоваться тем, что компания подобрала изображения, поднимающие настроение: еноты королевской крови и кактусы в солнцезащитных очках. Однако это лишь верхушка айсберга. Айсберга, образованного из непредвиденных последствий технологических исследований, если Imagen захочет попробовать сгенерировать их.
Понравился пост? Подпишись на канал и/или ☕️ Buy me a crypto coffee.