Ошибки в формулах Google Таблиц
Благодарим Михаила Смирнова за помощь в подготовке статьи
А-а-а! Формула не работает! Что делать (кроме как сходить к коллеге, у которого больший опыт в Таблицах)? Давайте рассмотрим, какие ошибки существуют в Таблицах и что можно сделать, чтобы разобраться с ошибкой в формулах.
Типы ошибок
#ИМЯ! / #NAME! — ошибка в имени функции, именованном диапазоне, ссылке на диапазон. Пробегитесь по всем этим пунктам в вашей формуле. Кроме того, не забывайте, что текстовые значения указываются внутри формул в кавычках.

Помните, что ошибки в формулах могут быть и в том случае, если эти ошибки есть в ячейках, на которые формулы ссылаются. Надо разматывать всю цепочку. На следующем скриншоте в формуле нет ничего криминального: к ячейке A4 прибавляем число 10. Но в ячейке A4 ошибка #ИМЯ? — она и отображается в результате расчета новой формулы:
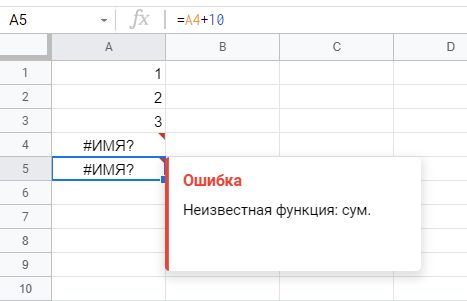
Еще эта ошибка может всплывать (редко — можно не беспокоиться) при использовании недокументированных функций:

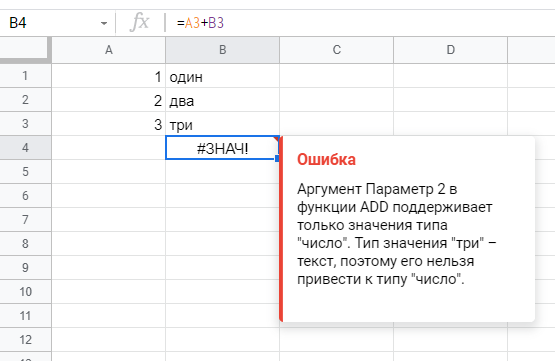
#ЗНАЧ! / #VALUE! — неправильные значения аргументов (например, в функции СМЕЩ / OFFSET высота или ширина диапазона задана как ноль, что невозможно) или же арифметические операции с разными типами данных — сложение текста и чисел. А еще бывает, если дата задана как текстовое значение. Ошибки в запросе функции QUERY тоже будут выглядеть так.
Типовые:
- не тот порядок кляуз (а порядок такой: SELECT - WHERE - GROUP BY - PIVOT - ORDER BY - SKIPPING - LIMIT - OFFSET - LABEL - FORMAT - OPTIONS)
- номера столбцов маленькими буквами (их нужно писать строго латинскими заглавными — при работе с одним диапазоном того же файла или ColN в других случаях - см следующий пункт). Кляузы, кстати, можно писать и строчными и как угодно — select или SELect тоже будут работать.
- номера столбцов буквами, когда нужно Col1, Col2 и т.д. (в тех случаях, когда диапазоном выступает массив из нескольких диапазонов или из внешнего файла через IMPORTRANGE)
- запятые вместо пробелов там, где нужно отделить кляузу от ее параметров
- попытка ссылаться на столбец, которого нет в диапазоне (первом аргументе QUERY)
- условие на число в кляузе WHERE с условием, взятым в апострофы — или , наоборот, условие на текст без апострофов.
Если попытаться сформировать формулой виртуальный диапазон размерностью более 10 000 000 ячеек - тоже будет ошибка #VALUE!:

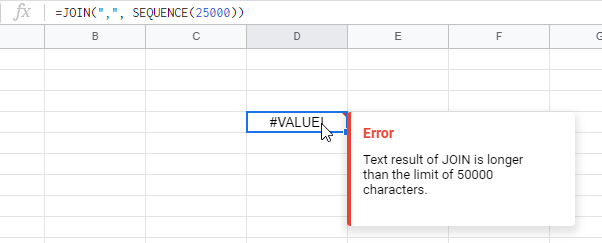
Ещё две причины — из-за ограничения на длину текстовой строки.
Нельзя, чтоб получались строки длиннее 50 000 символов:
А для функции ПОВТОР / REPT ограничение — 32 000:

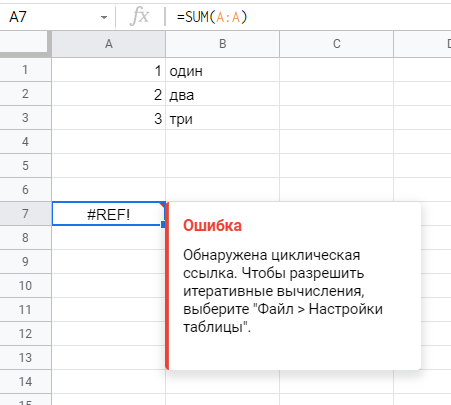
#ССЫЛ! / #REF — ссылка на несуществующий диапазон. Появляется, когда ячейка, на которую ссылалась формула, была удалена (вместе со строкой или столбцом, например), или когда вы пытаетесь, протягивая формулу, сослаться на ячейку A0, например (за пределами листа).

Циклическая ссылка (выглядит как #ССЫЛ! / #REF!). Возникает, если формула ссылается на собственное значение. При возникновении смотрите на диапазоны в формуле (бывает, что вы ссылаетесь на весь столбец, а формула стоит в нем же под таблицей, и т.д.)
Еще одна частая причина, которую бывает непросто побороть: несоответствие размеров диапазонов, которые надо соединить.

Ещё она возникает, если импортировать несуществующую таблицу:
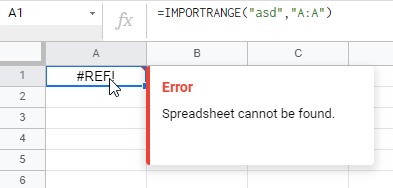
Или не открыть / не иметь доступа на импорт:

#ЧИСЛО! / #NUM! — ошибка с параметром функции. Как правило, возникает, когда вводится (или формируется в ходе промежуточных расчетов) отрицательное число там, где ожидается положительное.

#Н/Д / #N/A — значение не найдено. Обычно случается с ВПР, ПОИСКПОЗ. Либо значения действительно нет в таблице и тогда это “нормальная” ошибка, либо оно введено по-разному в исходной таблице и в таблице, откуда оно берется для поиска.
#ДЕЛ/0! / #DIV/0! — деление на ноль. Вроде бы понятно — надо смотреть, на что делим, чтобы понять, откуда взялся ноль. Но также случается и с функцией СРЗНАЧЕСЛИ(МН) / COUNTIF(S) — допустим, по вашим критериям не найдено ни одного условия — а в логике расчета среднего арифметического есть деление, и в такой ситуации деление будет именно на ноль (найденных по критериям значений).

Синтаксическая ошибка и другие виды ошибок (тип #ОШИБКА! / #ERROR! — в Excel, например, такого вообще нет, в отличие от остальных перечисленных). Может возникнуть просто из-за случайно введенного символа, который Таблицы не смогут интерпретировать (точка с запятой перед формулой или точка после, например). Еще зачастую это могут быть незакрытые фигурные скобки массива. Забытый амперсанд между соединяемыми текстовыми строками тоже вызовет такую ошибку.

Еще одна причина: слишком большой диапазон попытались передать в пользовательскую функцию (Этот случай обсуждался в нашем чате).
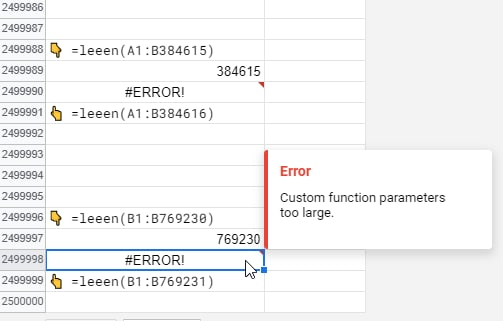
Некоторые типовые ошибки в формулах
Системная ошибка (из перечисленных выше) — это еще ладно, во всяком случае Таблицы вам о ней сигнализируют. Бывают в сложных формулах и не такие явные ошибки. В результате расчета нет ошибок, но есть ноль или неправдоподобное / явно ошибочное число / текст / синтаксическая ошибка. Как искать причины, на что обращать внимание?
Функции ВПР / VLOOKUP, ПОИСКПОЗ / MATCH — если есть сомнения, что функция тянет все корректно, проверяйте, точно ли вы указали последний аргумент как ЛОЖЬ (ноль, 0)? Если нет, будет по умолчанию 1, ИСТИНА (интервальный, а не точный поиск). И в случае с поиском текстовых значений возникнут ошибки.
Сравнение данных, поиск данных (те же ВПР и прочие) — если у вас ошибка Н/Д, может быть проблема в разных форматах данных. Например, в исходнике, который вы импортируете, артикулы текстового формата, а у вас в вашей таблице числового. Проверить можно с помощью функций ISTEXT / ЕТЕКСТ, ISNUMBER / ЕЧИСЛО.
Кроме того, всегда есть риск банальных ошибок ввода данных — лишние пробелы, перепутанные кириллица/латиница, сокращения. Для предотвращения таких ошибок используйте проверку данных. А для отлавливания — функцию UNIQUE (выводите список уникальных значений и смотрите, есть ли там разные варианты написания одного и того же значения).
Если вдруг ВПР или другая функция в упор не находит значение, а визуально они кажутся одинаковыми, не забывайте, что всегда можно сравнить две ячейки формулой (=A1=A2) или посмотреть, одинаковой ли они длины по количеству символов (с помощью функции ДЛСТР / LEN).
Убрать лишние пробелы (до и после текстовой строки и все, что свыше одного пробела между слов) помогает функция СЖПРОБЕЛЫ / TRIM.
Забыли протянуть формулу / изменить диапазон. Это классика :) По возможности используйте формулу массива с открытым диапазоном. Так вы настроите ее раз и навсегда и не нужно будет беспокоиться о появлении новых столбцов. Допустим, вы пишете формулу, которая будет отправлять адресату по его емейлу из текущей строки письмо:
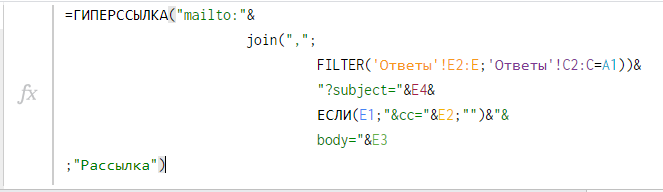
=HYPERLINK("mailto:"&E2&"?subject=Тема письма";"Письмо")Вместо такой формулы сделайте ее по открытому диапазону E2:E, и она будет работать бесконечно для любого количества строк. Чтобы в пустых строках ничего не отображалось, добавьте проверку на пустоту ячейки с емейлом (с помощью ЕСЛИ / IF):
=ArrayFormula(IF(F2:F="";""; HYPERLINK("mailto:"&E2:E&"?subject=Подключение тарифа";"Письмо")))
Проблемы со сложностью формулы. Иногда полностью правильно написанная формула не вернёт ничего или вернёт неправильное значение — к сожалению, мы иногда сталкивались с такой проблемой.
Такое случается, когда:
– вы ссылаетесь на большое количество строк с данными;
– и при этом написали слишком сложную формулу.
Что такое сложная формула для Таблиц? К примеру, функция FILTER, в условии которой – отбор большим регулярным выражением, которое сформировано из значений, которые вы внутри этой же формулы отбираете из другого большого листа, потом функцию заворачиваете в QUERY, делаете группировку и всё это безобразие вдобавок протягиваете на каждую строку.
Подобное можно провернуть только на небольших диапазонах с данными, на больших – может не работать.
Поэтому не забывайте, что сложность лимитирована, за ней нужно следить и не все, даже абсолютно правильно написанные формулы Таблица сможет переварить.
Что поможет написать/разобрать/починить сложную формулу
Принцип луковицы
Так этот подход назвал эксперт по Таблицам Бен Коллинз. Идея в следующем: вместо того, чтобы с ходу прописывать сложную формулу, сначала прописываем часть, смотрим, как она работает и правильно ли вычисляет промежуточное значение, затем ссылаемся на эту формулу из другой формулы, в которой она будет выступать одним из аргументов, и если все заработает, удаляем столбец с промежуточной формулой, а ее переносим в итоговую формулу (на то место, где мы на нее ссылались).
Иначе говоря, формируем отдельные части формулы в отдельных ячейках, ссылаясь из следующей на предыдущий этап, а потом уже соединяем в одну.
В приведенном выше примере с гиперссылкой можно сначала сформировать текстовую формулу, которая будет соединять mailto и адрес е-почты из ячейки, и сослаться на ячейку с этой формулой из ГИПЕРССЫЛКИ. И если все заработает, уже потом скопировать первую формулу и вставить вместо ссылки на ячейку с ней.
Переход на следующую строку в формуле
В строке формул можно переходить на следующую строку с помощью Alt+Enter. Это позволяет визуально разделить отдельные фрагменты/функции — тогда формулу будет проще воспринимать (вашим коллегам и вам самим в будущем, когда вы уже забудете ее логику).

Эта история может помочь, если у вас уже лютая многоэтажная формула, а в ней возникает синтаксическая ошибка.
Выделение фрагмента формулы
Напоминаем: выделяете ячейку в формуле — видите всплывающую подсказку с ее значением. Выделяете фрагмент формулы или одну функцию в рамках формулы — видите вычисляемое значение этого фрагмента / функции. Помогает понять, что на каких шагах вычисляется для конкретных данных.

Функция ЕСЛИОШИБКА / IFERROR и другие для “отлавливания” ошибок
Функция ЕСЛИОШИБКА / IFERROR позволяет отображать любое заданное вами значение (ее второй аргумент) вместо ошибки в формуле (которая указывается в первом аргументе). Это удобно — например, если значение не найдено, то вы показываете не #Н/Д, а пусто; если в сравнении с прошлым годом в конкретной строке возникает #ДЕЛ/0, так как по конкретному продукту не было продаж, а мы на них делим — то мы тоже показываем пустоту (по умолчанию, если будет пропущен второй аргумент, ЕСЛИОШИБКА выведет пустоту) или ноль (тогда придется указать его во втором аргументе) вместо ошибки.
Но ее стоит использовать осторожно: сначала отладьте формулу, убедитесь, что ошибок не возникает, а если они возникают - что вы их разобрали и исправили, а те, что не исправляются — “нормальные” ошибки (как упомянутое деление на ноль, когда базисное значение в формуле прироста нулевое) и только потом используйте ЕСЛИОШИБКА. Иначе рискуете не отловить определенные ошибки в будущем.
Если хотите "отлавливать" только #Н/Д (например, при применении ВПР'а) — используйте IFNA — у нее такой же синтаксис, но среагирует она только на ненайденное ВПР-ом значение (и вернет вместо ошибки #Н/Д пустоту либо явно указанное во втором аргументе значение), а остальные ошибки (допустим, если у вас будет что-то с синтаксисом) отобразит.
Помимо этих двух функций, которые оставляют первый аргумент на месте, если ошибок нет, и заменяют вторым, если они есть, существует еще несколько функций для поиска специфичных ошибок.
Функция ТИП.ОШИБКИ / ERROR.TYPE будет выдавать код ошибки (смотрим в справку):
1 для ошибки #NULL! (такой ошибки пока на практике нет, тот же Бен Коллинз пишет, что ни разу с ней не сталкивался и просил подписчиков прислать примеры, но никто пока не прислал)
2 для ошибки #DIV/0!
3 для ошибки #VALUE!
4 для ошибки #REF!
5 для ошибки #NAME?
6 для ошибки #NUM!
7 для ошибки #N/A
8 для всех других ошибок.
Соответственно, вы можете проверять формулу только на определенный тип ошибок.
Кроме того, есть функция ЕНД / ISNA для проверки конкретной ошибки Н/Д — только для нее будет возвращать ИСТИНА. Отличается от IFNA тем, что выводит ИСТИНА / ЛОЖЬ — это индикатор, она в любом случае не будет возвращать исходную формулу, даже если в ней нет ошибки.
Функция ЕОШ / ISERR обратная — возвращает ИСТИНА для всех типов ошибок, кроме Н/Д.
А ЕОШИБКА / ISERROR возвращает ИСТИНА для любого типа ошибок.