CASE, CTE, рекурсия
CASE: два варианта синтаксиса
CASE - это по сути тот же самый IF - ELSE в других языках программирования.
То есть если в Python это синтаксис:
if <условие 1>:
<действие 1>
elif <условие 2>:
<действие 2>
else <условие 2>:
<действие 2>То в SQL это CASE. И синтаксис у него следующий:
CASE WHEN <условие 1> THEN <значение 1>
WHEN <условие 2> THEN <значение 2>
WHEN <условие 3> THEN <значение 3>
ELSE <значение 4>
END;Пример использования CASE
Допустим, у нас есть таблица album. И мы хотим сформировать таблицу, чтобы для band_id = 93 в отдельной колонке стояла 1, а для остальных строк 0. И тоже самое для band_id = 192. Запрос тогда будет выглядеть так:
SELECT album_id, name, band_id,
CASE WHEN band_id = 93 THEN 1 ELSE 0 END as b_93,
CASE WHEN band_id = 192 THEN 1 ELSE 0 END as b_193
FROM album_small as a;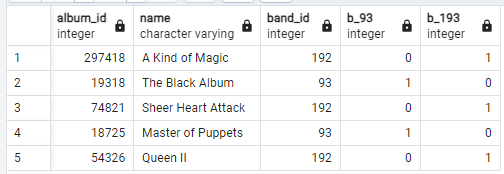
Разные формы CASE
Синтаксис 1 (который мы только видели):
CASE WHEN условие_1 THEN значение_1
WHEN условие_2 THEN значение_2
WHEN условие_3 THEN значение_3
ELSE значение_4
END
CASE колонка_или_выражение
WHEN тестируемое_значение_1 THEN возвращаемое_значение_1
WHEN тестируемое_значение_2 THEN возвращаемое_значение_2
WHEN тестируемое_значение_3 THEN возвращаемое_значение_3
ELSE возвращаемое_значение_4
ENDПример, который привели выше, можно переписать с тем синтаксисом, который был указан в Синтаксис 2
SELECT album_id, name, band_id,
CASE WHEN band_id = 93 THEN 1 ELSE 0 END as b_93,
CASE WHEN band_id = 192 THEN 1 ELSE 0 END as b_193
FROM album_small as a;SELECT album_id, name, band_id,
CASE band_id WHEN 93 THEN 1 ELSE 0 END as b_93,
CASE band_id WHEN 192 THEN 1 ELSE 0 END as b_192
FROM album_small as a;
CASE: полезные примеры
Пример 1 - Выбираем данные из таблицы person
SELECT person_id, name, position(' ' IN name) as space_position,
substring(name, 1, position(' ' IN name) - 1) as first_name
FROM person
WHERE name LIKE '% %'
UNION ALL
SELECT person_id, name, position(' ' IN name) as space_position,
name as first_name
FROM person
WHERE NOT (name LIKE '% %') OR name IS NULLМожно этот запрос написать короче с помощью CASE
SELECT person_id, name, position(' ' IN name) as space_position,
CASE WHEN name LIKE '% %'
THEN substring(name, 1, position(' ' IN name) - 1)
ELSE name
END
as first_name
FROM person
Пример 2 - Выберем из таблицы album альбомы для музыкальных групп 93 и 192.
SELECT * FROM album WHERE band_id = 93 OR band_id = 192; --25 SELECT band_id, COUNT(*) FROM album WHERE band_id IN (192, 93) GROUP BY 1; -- 93:11 и 192:14

А если нужно получить такую удобную таблицу?

SELECT SUM(b_93) as b_93, SUM(b_192) as b_192, SUM(total) as total FROM ( SELECT COUNT(*) as b_93, cast(NULL as bigint) as b_192, cast(NULL as bigint) as total FROM album WHERE band_id IN (93) UNION ALL SELECT NULL as b_93, COUNT(*) as b_192, NULL as total FROM album WHERE band_id IN (192) UNION ALL SELECT NULL as b_93, NULL as b_192, COUNT(*) as total FROM album WHERE band_id IN (93, 192))

А теперь переработаем запрос с помощью CASE
SELECT SUM(CASE WHEN band_id = 93 THEN 1 ELSE 0 END) as b_93,
SUM(CASE WHEN band_id = 192 THEN 1 ELSE 0 END) as b_192,
COUNT(*) as total
FROM album
WHERE band_id in(93, 192)
Пример 3 - Использование CASE внутри GROUP BY
SELECT band_category, COUNT(*) FROM ( SELECT CASE WHEN band_id = 93 THEN '1.band_id_93' WHEN band_id = 192 THEN '2.band_id_192' ELSE '3.all other bands' END as band_category, a.* FROM album as a) as table_1 GROUP BY 1 ORDER BY 1

Пример 4 - Сравниваем 2 колонки

SELECT a, b,
CASE WHEN a = b THEN 'a = b'
WHEN a > b THEN 'a > b'
WHEN a < b THEN 'a < b'
ELSE 'UNKNOWN'
END as res
FROM mytable_int
Пример 5 - Выводим большее значение
Действия с той же таблицей, что и в примере 4
SELECT a, b,
CASE WHEN a = b THEN a
WHEN a > b THEN a
WHEN a < b THEN b
WHEN a IS NOT NULL AND b IS NULL THEN a
WHEN a IS NULL AND b IS NOT NULL THEN b
ELSE NULL
END as greater
FROM mytable_int
SELECT a, b,
CASE WHEN a = b THEN 'a = b'
WHEN a > b THEN 'a > b'
WHEN a < b THEN 'a < b'
ELSE 'UNKNOWN'
END as res,
CASE WHEN a = b THEN a
WHEN a > b THEN a
WHEN a < b THEN b
WHEN a IS NOT NULL AND b IS NULL THEN a
WHEN a IS NULL AND b IS NOT NULL THEN b
ELSE NULL
END as greater
FROM mytable_int
Как можно переписать IN / NOT IN на OUTER JOIN + CASE
Этот запрос можно переписать следующим образом:
SELECT COUNT(*) FROM album WHERE name IN (SELECT name FROM band);
SELECT COUNT(*), SUM(band_found_flag), SUM(name_flag)
FROM (
SELECT a.*,
CASE WHEN b.name IS NOT NULL THEN 1 ELSE 0 END as band_found_flag,
CASE WHEN a.name = b2.name THEN 1 ELSE 0 END as name_flag
FROM album as a
INNER JOIN band as b2 ON b2.band_id = a.band_id
LEFT OUTER JOIN (
SELECT DISTINCT name
FROM band
) as b ON a.name = b.name
) as table_1;
Вот подробное объяснение построчно:
- Вложенный запрос:
- Внутренний запрос
SELECT DISTINCT name FROM bandизвлекает уникальные имена групп из таблицыbandи создает подзапросb - Основной запрос:
INNER JOINсоединяет таблицуalbumс таблицейbandпод именемb2по столбцуband_id.LEFT OUTER JOINсвязывает таблицуalbumс подзапросомbпо столбцуname.- Для каждой записи в
albumвычисляются два флага:band_found_flag, устанавливается в 1, если значениеnameтаблицыbandне являетсяNULL, иname_flag, устанавливается в 1, если значениеnameиз таблицыalbumсовпадает с значениемnameиз таблицыband. - Наконец, осуществляется подсчет количества строк
COUNT(*)и суммирование значений столбцовband_found_flagиname_flag
Таким образом, запрос сначала объединяет данные из нескольких таблиц, вычисляет флаги наличия группы и совпадения имен, а затем производит агрегирование данных по количеству строк и суммированию флагов.
Зачем мы вообще переписываем IN/NOT IN на LEFT OUTER JOIN
Основная идея в том, чтобы выбирать не только строки из album, которые соответствуют IN и NOT IN, а выбирать все строки из таблицы album и для них проставить 1 или 0.
Это бывает очень полезно, если рассматривать все альбомы и музыкальные группы.
Альтернативный синтаксис:
SELECT a.*,
CASE WHEN
a.name IN (
SELECT DISTINCT name
FROM band
) THEN 1 ELSE 0 END as band_found_FLAG
FROM album as a
CTE - Common Table Expression (WITH ...)
Можно ли упростить подзапросы?
SELECT SUM (album_count), COUNT(*)
FROM (
SELECT band_id,
COUNT(*) as album_count
FROM album as a
GROUP BY 1) as subquery
Этот запрос выглядит очень громоздко, потому что тут 2 SELECT, один внутри другого. Такие запросы проще читать, начиная с вложенного SELECT. Назовем его Запрос 1. А внешний SELECT назовем Запрос 2.

Возникает вопрос: Можно ли реализовать такой сложный запрос проще, чтобы он был более читаем?
1 вариант упрощения сложного запроса - Создание промежуточной таблицы
-- создаем новую таблицу с необходимыми свойствами
CREATE TABLE table_1 as
--- ЗАПРОС 1 ---
SELECT band_id,
COUNT(*) as album_count
FROM album as a
GROUP BY 1;
--- ЗАПРОС 1 ---
-- используем созданную таблицу
--- ЗАПРОС 2 ---
SELECT SUM(album_count),
COUNT(*)
FROM table_1;
--- ЗАПРОС 2 ---
-- удаляем созданную таблицу
DROP TABLE table_1;2 вариант упрощения сложного запроса - CTE
Common Table Expression (CTE) - это временный набор данных, который определяется внутри SQL запроса и может быть использован в последующих частях этого запроса. CTE предоставляет удобный способ организации сложных запросов, делая их более читаемыми и легко поддерживаемыми.
- Читаемость: CTE позволяет определить временный набор данных перед использованием его в основном запросе, что делает код более понятным для разработчиков.
- Рекурсивные запросы: CTE может использоваться для создания рекурсивных запросов, которые могут быть полезны при работе с иерархическими данными, такими как деревья или графы.
- Многократное использование: Определенный CTE можно использовать несколько раз в рамках одного запроса, избегая повторения одних и тех же подзапросов.
-- создаем временную таблицу (которая никуда не сохраняется,
-- а существует только в памяти)
WITH table_1 as (
--- ЗАПРОС 1 ---
SELECT band_id,
COUNT(*) as album_count
FROM album as a
GROUP BY 1
--- ЗАПРОС 1 ---
)
--- ЗАПРОС 2 ---
SELECT SUM(album_count), COUNT(*) FROM table_1;
--- ЗАПРОС 2 ---С помощью WITH можно оформить не один, а два и даже больше подзапросов.
ПРИМЕР CTE #1
WITH table_1 as (
SELECT band_id,
COUNT(*) as album_count
FROM album as a
GROUP BY 1),
table_2 as (
SELECT SUM(album_count) as a_c,
COUNT(*) as counter
FROM table_1)
SELECT * FROM table_1;

Если есть несколько запросов WITH, то они разделяются запятыми и WITH для нового запроса вводить не нужно.

Рекурсивные Запросы
Рекурсивные запросы в SQL позволяют выполнять итеративную обработку данных в виде древовидной или иерархической структуры. Они полезны для работы с данными, которые содержат иерархическую информацию, такую как деревья или графы.
Простой пример использования рекурсивных запросов - это работа с иерархической структурой сотрудников в организации, представленной в виде таблицы с полями id, name и manager_id, где manager_id указывает на id непосредственного руководителя. Рекурсивный запрос может использоваться для построения полной иерархии отдельного сотрудника до вершинной должности.
Вспомним таблицу music_instrument. Это таблица, которая ссылается сама на себя. В этой таблице хранятся иерархические данные.
SELECT a.id, a.name, b.id as child_id, b.name as child_name,
c.id as grandchild_id, c.name as grandchild_name
FROM music_instrument as a
LEFT JOIN music_instrument as b ON a.id = b.parent_id
LEFT JOIN music_instrument as c ON b.id = c.parent_id
WHERE a.id = 1
ORDER BY a.name, b.name, c.name;
В задании 7 мы делали SELF JOIN через LEFT OUTER JOIN. Но минус такого подхода в том, что:
Для этого используется рекурсивные запросы.
Синтаксис рекурсивного запроса:
WITH RECURSIVE recursive_table AS ( -- recursive_table - алиас для рекурсивной таблицы, которую создаем --НАЧИНАЕМ ПИСАТЬ РЕКУРСИЮ SELECT -- начало рекурсии UNION ALL SELECT -- очередной шаг рекурсии --ЗАКОНЧИЛИ ПИСАТЬ РЕКУРСИЮ ) SELECT * FROM recursive_table
А теперь сделаем задание 7, только с помощью рекурсии:
WITH RECURSIVE recursive_table AS (
SELECT l_1.parent_id, cast(null as character varying) as parent_name,
--cast(null as character varying) as parent_name
--присваивает значение NULL столбцу parent_name и указывает,
--что тип данных должен быть character varying.
l_1.id, l_1.name, 1 as depth
-- 1 as depth - уровень иерархии или глубина рекурсии
FROM music_instrument as l_1
WHERE l_1.id = 1
UNION ALL
SELECT recursive_alias.id as parent_id, recursive_alias.name as parent_name,
l_next.id, l_next.name, recursive_alias.depth + 1 as depth
FROM recursive_table as recursive_alias
-- recursive_table - те результаты, которые были
-- на предыдущем шаге рекурсии
LEFT JOIN music_instrument as l_next ON l_next.parent_id = recursive_alias.id
WHERE depth <= 100
AND l_next.id IS NOT NULL
) SELECT * FROM recursive_table
ORDER BY depth, parent_name, nameЭтот запрос выполняет выборку древовидной структуры данных из таблицы "music_instrument" с использованием рекурсивного запроса. Давайте разберем запрос по шагам:
1. WITH RECURSIVE: Этот оператор позволяет создать временную рекурсивную таблицу, которая будет использоваться во всем запросе.
2. Первая часть запроса (Initial Query):
SELECT l_1.parent_id, cast(null as character varying) as parent_name,
l_1.id, l_1.name, 1 as depth
FROM music_instrument as l_1
WHERE l_1.id = 1Здесь мы выбираем данные из таблицы music_instrument с псевдонимом l_1. Мы выбираем столбцы parent_id, id и name из таблицы l_1 и присваиваем им значение 1 для столбца depth. Также устанавливаем значение parent_name в NULL с помощью функции CAST.
3. Рекурсивная часть запроса (Recursive Query):
SELECT recursive_alias.id as parent_id,
recursive_alias.name as parent_name,
l_next.id, l_next.name,
recursive_alias.depth + 1 as depth
FROM recursive_table as recursive_alias
LEFT JOIN music_instrument as l_next
ON l_next.parent_id = recursive_alias.id
WHERE depth <= 100 AND l_next.id IS NOT NULLЗдесь мы объявляем рекурсивную часть запроса с использованием ключевого слова UNION ALL. Мы ссылаемся на временную таблицу recursive_table с псевдонимом recursive_alias. Затем мы присоединяем таблицу music_instrument с псевдонимом l_next с использованием оператора LEFT JOIN. Мы также добавляем условия на глубину (depth) и проверяем, что l_next.id не равно NULL.
4. Итоговая часть запроса (Final Query):
SELECT * FROM recursive_table ORDER BY depth, parent_name, name
Здесь мы выбираем все столбцы из временной таблицы recursive_table и сортируем результаты по столбцам depth, parent_name и name.
Таким образом, этот запрос выполняет итеративную обработку данных из таблицы music_instrument, создавая рекурсивную структуру, и выводит ее в отсортированном порядке.


Теперь добавим еще одну колонку и в этой колонке укажем весь путь от начала иерархии до конкретного элемента.
Для этого немного изменим код запроса:
WITH RECURSIVE recursive_table AS (
SELECT l_1.parent_id, cast(null as character varying) as parent_name,
l_1.name as chained_name,
/*добавили колонку выше*/
l_1.id, l_1.name, 1 as depth
FROM music_instrument as l_1
WHERE l_1.id = 1
UNION ALL
SELECT recursive_alias.id as parent_id, recursive_alias.name as parent_name,
recursive_alias.chained_name || ' — >'
|| coalesce(l_next.name, '') as chaied_name,
/*добавили колонку выше*/
/*coalesce(l_next.name, '') - если "l_next.name" имеет значение,
функция вернет это значение, иначе вернет пустую строку*/
l_next.id, l_next.name, recursive_alias.depth + 1 as depth
FROM recursive_table as recursive_alias
LEFT JOIN music_instrument as l_next ON l_next.parent_id = recursive_alias.id
WHERE depth <= 100
AND l_next.id IS NOT NULL
) SELECT * FROM recursive_table
ORDER BY depth, parent_name, name