Основы API
Вводная часть
Введение
API (application programming interfaces, интерфейсы прикладного программирования). Понимание принципов работы API становится всё более актуальным для карьеры в индустрии разработки программного обеспечения. С помощью этого курса мы надеемся дать вам все необходимые знания для начала работы с API. В этой главе мы рассмотрим некоторые фундаментальные концепции API. Мы определим, что такое API, где он находится, и определим общую модель того, как он используется.
Определение контекста
Когда мы говорим об API, большая часть разговоров сосредоточена на абстрактных концепциях. Чтобы внести ясность, давайте начнем с чего-то физического: с сервера. Сервер — это не что иное, как большой компьютер. Он состоит из тех же частей, что и ноутбук или настольный компьютер, который вы используете для работы, только он быстрее и мощнее. Обычно на серверах нет монитора, клавиатуры или мыши, из-за чего они выглядят недоступными. В реальности же ИТ-специалисты для работы с ними подключаются к ним дистанционно — как к удаленному рабочему столу.
Серверы используются для самых разных вещей. Некоторые хранят данные; другие отправляют электронную почту. Чаще всего люди взаимодействуют с веб-серверами. Это серверы, которые предоставляют вам веб-страницу при посещении веб-сайта. Чтобы лучше понять, как это работает, приведем простую аналогию:
Точно так же, как программа, подобная пасьянсу «Косынка» (Solitaire), ждет, пока вы щёлкнете по карте, чтобы что-то сделать, веб-сервер исполняет программу, которая ждёт, пока человек запросит веб-страницу.
В этом нет ничего волшебного или захватывающего. Разработчик программного обеспечения пишет программу, копирует её на сервер, и сервер выполняет её.
Что такое API и почему он ценен
Веб-сайты созданы с учетом сильных сторон людей. Люди обладают невероятной способностью воспринимать визуальную информацию, комбинировать ее с нашим опытом для извлечения смысла, а затем действовать в соответствии с этим значением. Вот почему вы можете взглянуть на форму веб-сайта и понять, что небольшое поле с надписью «Имя» над ним означает, что вы должны ввести слово, которое вы используете для идентификации себя.
Но что происходит, когда вы сталкиваетесь с очень трудоемкой задачей, например копированием контактной информации тысячи клиентов с одного сайта на другой? Уверен, вы бы предпочли передать эту работу компьютеру, чтобы её можно было выполнить быстро и точно. К сожалению, характеристики, которые делают веб-сайты удобным для использования людьми, делают их трудными для использования компьютерами.
И тут решением выступает API. API — это инструмент, который делает данные веб-сайта удобными для использования компьютером. С его помощью компьютер может просматривать и редактировать данные, точно так же, как человек может загружать страницы и отправлять формы.
Упростить работу с данными — это хорошо, потому что это означает, что люди могут писать программное обеспечение для автоматизации утомительных и трудоемких задач. То, на что у человека может уйти несколько часов, может занять у компьютера секунды посредством использования API.
Как используется API
Когда две системы (веб-сайты, настольные компьютеры, смартфоны) соединяются через API, мы говорим, что они «интегрированы». В интеграции у вас есть две стороны, каждая из которых имеет особое имя. Одна сторона, о которой мы уже говорили: сервер. Это сторона, которая фактически предоставляет API. Помните, что API — это просто другая программа, работающая на сервере. API может быть частью той же программы, которая обрабатывает веб-трафик, или API может быть совершенно другой программой. В любом случае он просто ожидает, когда другая сторона запросит у нее данные.
Другая сторона — это «клиент». Это отдельная программа, которая знает, какие данные доступны через API, и может манипулировать ими, обычно по запросу от пользователя. Отличный пример — приложение для смартфона, которое синхронизируется с веб-сайтом. Когда вы нажимаете кнопку обновления, ваше приложение начинает общаться с сервером через API и от него получает самую свежую информацию.
Тот же принцип применяется при интеграции веб-сайтов. Когда один сайт получает данные от другого, сайт, предоставляющий данные, действует как сервер, а сайт, получающий данные, является клиентом.
Итоги урока:
Ключевые термины, которые мы узнали:
• Сервер: мощный компьютер, на котором работает API.
• API: «Скрытая» часть веб-сайта, предназначенная для использования компьютером.
• Клиент: программа, которая обменивается данными с сервером через API
Протоколы
Знание правил
Люди создают правила этикета, чтобы регламентировать взаимодействия между собой. Один из примеров — то, как мы разговариваем друг с другом по телефону. Представьте, что вы болтаете с подругой. Пока она говорит, вы знаете, что нужно молчать. Если она задаёт вопрос, а затем молчит, вы знаете, что она ждёт ответа и теперь ваша очередь говорить.
Компьютеры придерживаются аналогичного этикета, хотя и называется он термином «протокол». Компьютерный протокол — это принятый набор правил, которые определяют, как два компьютера могут общаться друг с другом. Однако по сравнению с нашими стандартами компьютерный протокол чрезвычайно строгий. Подумайте на минуту о двух предложениях: «Мой любимый цвет — синий» и «Синий — мой любимый цвет». Люди могут определить каждое предложение и понять, что они означают одно и то же, несмотря на то, что слова расположены в разном порядке. К сожалению, компьютеры не настолько умны.
Чтобы два компьютера могли эффективно взаимодействовать, сервер должен точно знать, как клиент будет структурировать свои сообщения. Представьте, что сервер — это человек, который просит почтовый адрес. Когда вы спрашиваете как определить место назначения, вы предполагаете, что первое, что вам скажут — это город, за которым следуют почтовый индекс, улица, и, наконец, дом. У вас также есть определенные ожидания в отношении каждой части адреса, например, тот факт, что почтовый индекс должен состоять только из цифр. Похожий уровень точности нужен и для правильной работы компьютерного протокола.
Протокол интернета
В мире технологий практически для всего существует протокол, и каждый из них заточен для выполнения своих задач. Возможно, вы уже слышали о некоторых из них: Bluetooth для подключения устройств и POP или IMAP для получения электронной почты.
В интернете основным протоколом является протокол передачи гипертекста, более известный под аббревиатурой HTTP (HyperText Transfer Protocol, протокол передачи гипертекста). Когда вы вводите адрес вроде http://example.com в веб-браузере, «http» указывает браузеру использовать правила HTTP-протокола при разговоре с сервером.
С повсеместным распространением HTTP в интернете многие компании предпочитают адаптировать его для использования в качестве протокола, лежащего в основе своих API-интерфейсов. Одним из преимуществ использования этого протокола является то, что он прост в изучении разработчиками. Еще одним преимуществом является то, что HTTP имеет несколько свойств, полезных для создания хорошего API, которые мы увидим позже. А сейчас давайте нырнём глубже и посмотрим, как работает HTTP!
HTTP-запросы
Взаимодействие в HTTP основано на концепции, называемой Циклом «Запрос-Ответ». Клиент отправляет серверу запрос на выполнение каких-либо действий. Сервер, в свою очередь, отправляет клиенту ответ, в котором говорит, может ли он сделать то, что просил клиент.
Чтобы сделать правильный запрос, клиент должен указать четыре вещи:
- URL (Uniform Resource Locator, единый указатель ресурсов)
- Метод (Method)
- Список Заголовков (Headers)
- Тело (Body)
Может показаться, что тут слишком много всего чтобы просто передать сообщение, но помните, что компьютеры должны быть очень точными, чтобы общаться друг с другом.
Структура HTTP-запроса приведена на картинке ниже.
URL
URL-адреса знакомы нам в повседневном использовании интернета, но задумывались ли вы когда-нибудь об их структуре? В HTTP URL — это уникальный адрес какого-либо объекта. Каким объектам давать адреса — полностью решает организация, которая управляет сервером. Компании могут создавать URL-адреса для веб-страниц, изображений или даже видео с котиками.
API развивают эту идею, добавляя в контекст URL такие объекты, как, например, клиенты, продукты и твиты. В результате URL-адреса становятся для клиента простым способом сообщить серверу, с каким объектом он хочет взаимодействовать. Конечно, API не называют их «объектами», им дают техническое название «ресурсы».
Методы (methods)
Метод запроса сообщает серверу, какое действие клиент хочет, чтобы сервер предпринял. Фактически, метод обычно называют «глаголом» запроса.
В API-интерфейсах чаще всего встречаются четыре метода:
- GET — просит сервер получить ресурс
- POST — просит сервер создать новый ресурс
- PUT — просит сервер отредактировать/обновить существующий ресурс
- DELETE — просит сервер удалить ресурс
Но существуют ещё методы CONNECT, OPTIONS, PATCH, TRACE, LIST. Механизмы их работы описаны тут: https://developer.mozilla.org/ru/docs/Web/HTTP/Methods
Вот пример, который поможет проиллюстрировать эти методы. Допустим, есть пиццерия с API, который можно использовать для размещения заказов. Вы размещаете заказ, отправляя POST-запрос на сервер ресторана с перечнем вашего заказа с просьбой создать вашу пиццу по этим ингридиентам. Однако после того как вы отправили запрос, вы понимаете, что выбрали неправильные ингредиенты, поэтому вы делаете запрос PUT, чтобы изменить его.
Ожидая своего заказа, вы делаете кучу запросов GET для проверки статуса. После часа ожидания вы решаете, что не готовы больше ждать, и делаете DELETE-запрос, чтобы отменить свой заказ.
Заголовки (Headers)
Заголовки предоставляют метаинформацию о запросе. Это простой список элементов, таких как время отправки запроса клиентом и размер тела запроса.
Помните, как вы заходили со своего смартфона на веб-сайт, специально отформатированный для мобильных устройств? Это стало возможным благодаря HTTP-заголовку под названием «User-Agent». Клиент использует этот заголовок, чтобы сообщить серверу, какой тип устройства вы используете, и если веб-сайт достаточно умён чтобы прочесть его, то в результате отправит вам данные в наиболее удобном для вашего типа устройства формате.
В целом существуют довольно много разных заголовков HTTP, с которыми имеют дело клиенты и серверы, но давайте рассмотрим их позже, в следующих главах.
Тело (Body)
В теле запроса содержатся данные, которые клиент хочет отправить серверу. Продолжая наш пример с заказом пиццы выше, тело — это место, где размещаются ингредиенты заказа.
Уникальной чертой тела является то, что клиент полностью контролирует эту часть запроса. В отличие от метода, URL-адреса или заголовков, где протокол HTTP требует жёсткой структуры, тело позволяет клиенту отправлять всё, что ему нужно.
Эти четыре части: URL, метод, заголовки и тело и составляют полный HTTP-запрос.
HTTP-ответы и Коды состояний.
После того, как сервер получает запрос от клиента, он пытается выполнить запрос и отправить клиенту ответ. HTTP-ответы имеют очень похожую на запросы структуру. Основное отличие состоит в том, что вместо метода и URL-адреса ответ включает код состояния. А в остальном заголовки и тело ответа имеют тот же формат, что и запросы.
Коды состояний
Коды состояний — это трехзначные номера, каждый из которых подразумевает под собой уникальное значение состояния, обработанного сервером запроса. Если в API они используются корректно, эти три цифры могут сообщить очень много информации клиенту. Например, вы могли видеть эту страницу в период ваших интернет-странствий:
Код состояния, связанный с этим ответом — 404, что означает «Не найдено». Всякий раз, когда клиент делает запрос на ресурс, который не существует, сервер отвечает кодом состояния 404, чтобы сообщить клиенту: «этот ресурс не существует, поэтому, пожалуйста, не запрашивайте его снова!»
Код ответа (состояния) HTTP показывает, был ли успешно выполнен определённый HTTP запрос. Коды сгруппированы в 5 классов:
- Информационные 100 - 199
- Успешные 200 - 299
- Перенаправления 300 - 399
- Клиентские ошибки 400 - 499
- Серверные ошибки 500 - 599
В протоколе HTTP есть множество других статусов, от 200 («успешно! этот запрос был выполнен») до 503 («наш веб-сайт/API в настоящее время не работает»). Мы изучим некоторые из них по мере их появления в следующих главах.
После того, как ответ доставлен клиенту, Цикл Запрос-Ответ завершается, и этот раунд связи завершается. Теперь клиент должен инициировать дальнейшее взаимодействие. Сервер не будет отправлять клиенту больше данных, пока он не получит новый запрос.
Итоги урока
Целью урока было дать вам базовое понимание HTTP. Ключевой концепцией был Цикл Запрос-Ответ, который мы разделили на следующие части:
- Запрос — состоит из URL-адреса (http://...), метода (GET, POST, PUT, DELETE), списка заголовков (User-Agent...) и тела (данных).
- Ответ — состоит из кода состояния (200, 404...), списка заголовков и тела.
На протяжении оставшихся частей курса мы будем возвращаться к этим частям, по мере знакомства с тем, как API-интерфейсы реализуются на их основе, обеспечивая мощность и гибкость интеграции.
Форматы данных
В этой главе мы исследуем, какие данные предоставляют API, как они форматируются и как HTTP делает это возможным.
Представление данных
При обмене данными с людьми возможности отображения информации ограничиваются только человеческой фантазией. Вспомните пиццерию из предыдущей главы — как она может оформить своё меню? Например, как текстовый список или маркированный список, может быть серией фотографий с подписями или только набором фотографий, на которые показывают посетители, чтобы оформить заказ.
Хорошо продуманный формат помогает целевой аудитории понимать информацию.
Тот же принцип применяется при обмене данными между компьютерами. Один компьютер должен поместить данные в формат, понятный для другого. Обычно это какой-то текстовый формат.
Наиболее распространёнными форматами, встречающимися в современных API, являются JSON (JavaScript Object Notation, нотация объектов JavaScript) и XML (Extensible Markup Language, расширяемый язык разметки) .
JSON
Многие новые API-интерфейсы приняли JSON в качестве формата, потому что он построен на популярном языке программирования Javascript, который повсеместно используется в интернете и применим как на фронтенде, так и на бэкенде веб-приложения или сервиса. JSON — это очень простой формат, состоящий из двух частей: ключей (keys) и значений (values). Ключи представляют собой свойство, атрибут описываемого объекта. Заказ пиццы может быть объектом. У него есть атрибуты (ключи), такие как тип корочки, начинка и статус заказа. У этих атрибутов есть соответствующие значения (толстое тесто, пепперони и «доставляется»).
Посмотрим, как этот заказ пиццы может выглядеть в JSON:
Explain{
"crust": "original",
"toppings": ["cheese", "pepperoni", "garlic"],
"status": "cooking"
}В приведенном выше примере JSON ключевыми словами являются слова слева: начинка, корочка и статус. Они говорят нам, какие атрибуты содержит заказ пиццы. Значения указаны в частях справа. Это фактические детали заказа.

Если вы прочитаете строку слева направо, вы получите довольно естественное английское предложение. Взяв, к примеру, первую строчку, мы могли бы прочитать её как «корочка для этой пиццы оригинального стиля». Вторая строка также может быть прочитана — в JSON значение, которое начинается и заканчивается квадратными скобками ([]), представляет собой список значений. Итак, мы читаем вторую строку заказа как «начинки для этого заказа: сыр, пепперони и чеснок».
Иногда вы хотите использовать объект в качестве значения для ключа. Давайте расширим наш заказ пиццы подробностями о клиенте, чтобы вы могли увидеть, как это может выглядеть:
Explain{
"crust": "original",
"toppings": ["cheese", "pepperoni", "garlic"],
"status": "cooking",
"customer": {
"name": "Brian",
"phone": "573-111-1111"
}
}В этой обновленной версии мы видим, что добавлен новый ключ «клиент». Значение этого ключа — это еще один набор ключей и значений, которые предоставляют подробную информацию о клиенте, разместившем заказ. Классный трюк, а?! Это называется Ассоциативным Массивом. Но не пугайтесь технического языка, ведь ассоциативный массив — это просто вложенный объект.
XML
XML существует с 1996 года. С возрастом он стал очень зрелым и мощным форматом данных. Как и JSON, XML предоставляет несколько простых строительных блоков, которые создатели API используют для структурирования своих данных. Основной блок называется узлом (node).
Давайте посмотрим, как может выглядеть наш заказ пиццы в XML:
Explain<order>
<crust>original</crust>
<toppings>
<topping>cheese</topping>
<topping>pepperoni</topping>
<topping>garlic</topping>
</toppings>
<status>cooking</status>
</order>XML всегда начинается с корневого узла, которым в нашем примере с пиццей является «заказ». Внутри заказа находятся ещё несколько «дочерних» узлов. Имя каждого узла сообщает нам атрибут заказа (как и ключ в JSON), а данные внутри представляют собой фактические детали (как и значение в JSON).
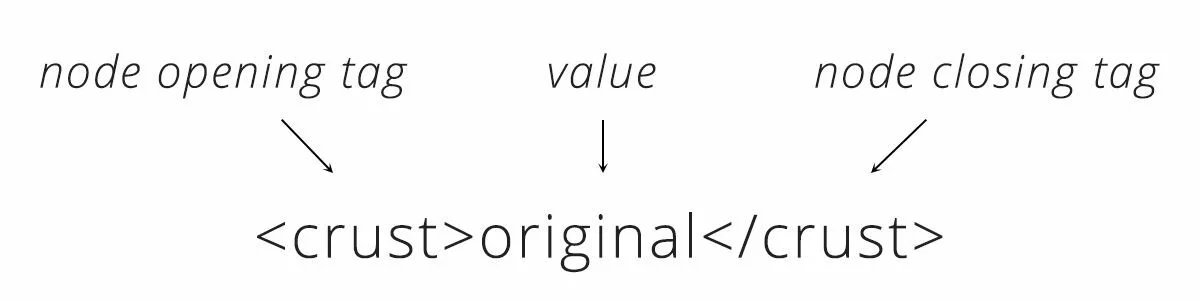
Вы также можете вывести предложения на английском языке, читая XML. Глядя на строчку с «корочкой», мы могли прочитать «корочка для пиццы оригинального стиля». Обратите внимание, как в XML каждый элемент в списке начинок обернут узлом. Как видите, формат XML требует гораздо больше текста для передачи, чем JSON.
Как форматы данных используются в HTTP
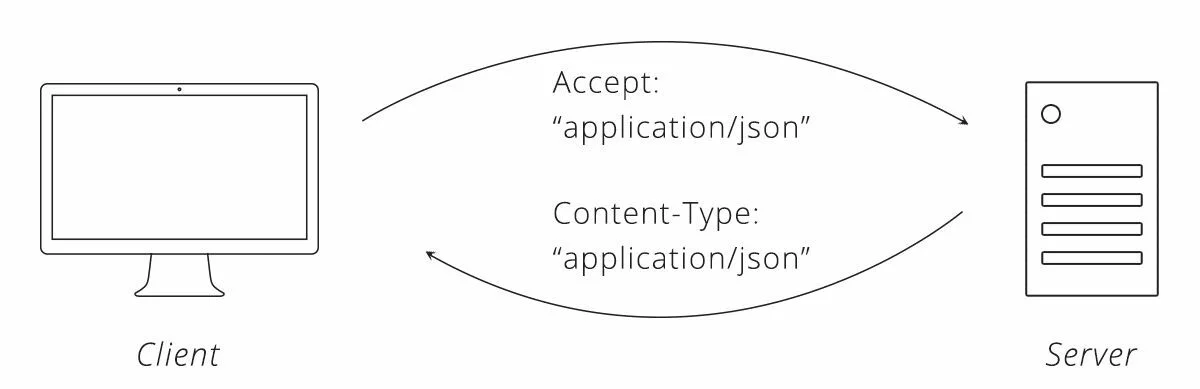
Теперь, когда мы изучили некоторые доступные форматы данных, нам нужно знать, как использовать их в HTTP. Для этого мы ещё раз вспомним одну из основ HTTP: заголовки. В предыдущем уроке 2 мы узнали, что заголовки — это список информации о запросе или ответе. Есть заголовок, указывающий, в каком формате находятся данные: Content-Type .
Когда клиент отправляет заголовок Content-Type в запросе, он сообщает серверу, что данные в теле запроса отформатированы
определённым способом. Если клиент хочет отправить серверу данные в формате JSON, он установит Content-Type на «application/json». Получив запрос и увидев этот Content-Type, сервер сначала проверит, понимает ли он этот формат, и, если да, он будет знать, как читать данные. Аналогичным образом, когда сервер отправляет клиенту ответ, он также устанавливает Content-Type, чтобы сообщить клиенту, как читать тело ответа.
Иногда клиент может общаться только в одном формате данных. Если сервер отправляет обратно что-либо, кроме этого формата, клиент откажется и выдаст ошибку. К счастью, на помощь приходит второй HTTP-заголовок. Клиент может установить заголовок Accept, чтобы сообщить серверу, какие форматы данных он может принимать. Если клиент может общаться только в формате JSON, он может установить для заголовка Accept значение «application/json». И тогда сервер будет отправлять ответы в формате JSON. Если сервер не поддерживает формат, запрашиваемый клиентом, он может отправить клиенту сообщение об ошибке, чтобы сообщить ему, что запрос не будет работать.
С помощью этих двух заголовков, Content-Type и Accept, клиент и сервер могут работать с форматами данных, которые они понимают и должны работать должным образом.
Итоги урока
В этом уроке мы узнали, что для того, чтобы два компьютера могли общаться, они должны понимать передаваемый им формат данных. Мы познакомились с двумя распространенными форматами данных, используемыми в API: JSON и XML. Мы также узнали, что HTTP-заголовок Content-Type — это полезный способ указать, какой формат данных отправляется в запросе, а заголовок Accept определяет запрошенный формат для ответа.
Ключевые термины, которые мы узнали, были:
- JSON: нотация объектов JavaScript
- Объект: вещь или существительное (человек, заказ пиццы ...)
- Ключ: атрибут объекта (цвет, начинка ...)
- Значение: значение атрибута (синий, пепперони ...)
- Ассоциативный массив: вложенный объект
- XML: расширяемый язык разметки
URI, URL и URN
В чем разница между URI и URL? Мы все используем много URL-адресов ежедневно. Иногда мы их набираем, иногда мы просто переходим на один URL из другого.
Для начала давайте расшифруем аббревиатуры:
- URI - Uniform Resource Identifier (унифицированный идентификатор ресурса)
- URL - Uniform Resource Locator (унифицированный определитель местонахождения ресурса)
- URN - Unifrorm Resource Name (унифицированное имя ресурса)
Многие считают, что http://google.com или http://yandex.ru - это просто URL-адреса, но, однако мы можем говорить о них как о URI. Фактически, URI представляет собой расширенный набор URL-адресов и нечто, называемое URN. Таким образом, мы можем с уверенностью заключить, что все URL являются URI. Однако обратное неверно.
ПОЧЕМУ? КАК ЭТО РАБОТАЕТ?
Твое имя, скажем, “Джон Доу” - это URN. Место, в котором вы живете, например, “Улица Вязов, 13” – это уже URL. Вы можете быть идентифицированы как уникальное лицо с вашим именем или вашим адресом. Эта уникальная личность – это уже URI. И хотя ваше имя может быть вашим уникальным идентификатором (URI), оно не может быть URL-адресом, поскольку ваше имя не помогает найти ваше местоположение. Другими словами, URI (которые являются URN) не являются URL-адресами.
- URI – имя и адрес ресурса в сети, включает в себя URL и URN
- URL – адрес ресурса в сети, определяет местонахождение и способ обращения к нему
- URN – имя ресурса в сети, определяет только название ресурса, но не говорит как к нему подключиться
- URI – https://wiki.merionet.ru/images/vse-chto-vam-nuzhno-znat-pro-devops/1.png
- URL - https://wiki.merionet.ru
- URN - images/vse-chto-vam-nuzhno-znat-pro-devops/1.png
Как вы видите – первые две строчки в вашем браузере отобразились как ссылки и по ним можно перейти, однако по третьей сточке нельзя, потому что непонятно как и куда.
Как это можно показать наглядно:
ЧТО ТАКОЕ URI?
URI обозначает Uniform Resource Identifier и по сути является последовательностью символов, которая идентифицирует какой-то ресурс. URI может содержать URL и URN.
URI содержит в себе следующие части:
- Схема (scheme) - показывает на то, как обращаться к ресурсу, чаще всего это сетевой протокол (http, ftp, ldap)
- Иерархическая часть (hier-part) - данные, необходимые для идентификации ресурса (например, адрес сайта)
- Запрос (query) - необязательные дополнительные данные ресурса (например, поисковой запрос)
- Фрагмент (fragment) – необязательный компонент для идентификации вторичного ресурса (например, место на странице)
Общий синтаксис URI выглядит так:
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
ЧТО ТАКОЕ URL?
Теперь, когда мы знаем, что такое URI, URL тоже должен быть достаточно понятным. Всегда помните - URI может содержать URL, но URL указывает только адрес ресурса.
URL содержит следующую информацию:
- Протокол, который используется для доступа к ресурсу – http, https, ftp
- Расположение сервера с использованием IP-адреса или имени домена - например, wiki.merionet.ru - это имя домена. https://192.168.1.17 - здесь ресурс расположен по указанному IP-адресу
- Номер порта на сервере. Например, http://localhost: 8080, где 8080 - это порт.
- Точное местоположение в структуре каталогов сервера. Например - https://wiki.merionet.ru/ip-telephoniya/ - это точное местоположение, если пользователь хочет перейти в раздел про телефонию на сайте.
- Необязательный идентификатор фрагмента. Например, https://www.google.com/search?ei=qw3eqwe12e1w&q=URL, где q = URL - это строка запроса, введенная пользователем.
[protocol]://www.[domain_name]:[port 80]/[path or exaction resource location]?[query]#[fragment]
Так как определить, является ли что-то URI или URL?
Что ж, если вы хотите знать, является ли это «что-то» URI или URL, вы всегда должны считать его как URI, потому что все URL являются URI.
СРАВНЕНИЕ ЛИЦОМ К ЛИЦУ: URI ПРОТИВ URL
Давайте сделаем некоторое параллельное сравнение, чтобы все, что мы обсуждали до сих пор, было подкреплено, и вы никогда не запутаетесь в неправильном использовании URI и URL.

Аутентификация
Как сервер узнает, что клиент является тем, кем он себя называет? В этом уроке мы исследуем два способа, с помощью которых клиент может подтвердить свою личность серверу.
Личности в виртуальном мире
Вам, вероятно, уже много раз приходилось регистрировать учетную запись на каких-либо веб-сайтах. В ходе этого процесса сайт запрашивает у вас некоторую личную информацию, в первую очередь имя пользователя и пароль. Эти две части информации становятся вашими опознавательными знаками. Мы называем их вашими полномочиями. При повторном посещении веб-сайта вы можете войти в него, указав эти учетные данные.
Вход в систему с использованием имени пользователя и пароля — один из примеров технического процесса, известного как аутентификация. Когда вы аутентифицируетесь на сервере, вы подтверждаете свою личность серверу, сообщая ему информацию, которую знаете только вы (по крайней мере, мы надеемся, что это знаете только вы). Как только сервер узнает, кто вы, он сможет вам доверять и предоставить личные данные вашей учетной записи.
API-интерфейсы используют несколько методов для аутентификации клиента. Это так называемые схемы аутентификации. Давайте теперь посмотрим на две из этих схем.
Обычная проверка подлинности.
Приведенный выше пример входа в систему является самой простой формой аутентификации. Фактически, его официальное название — Базовая аутентификация («Базовая аутентификация» для его друзей). Хотя это имя и не получило никаких наград за творческие достижения, эта схема является вполне приемлемым способом для сервера аутентифицировать клиента в API.
Для базовой аутентификации требуется только имя пользователя и пароль. Клиент берет эти учётные данные, смешивает их вместе, чтобы сформировать единое значение, и передает его в запросе в заголовке HTTP под названием «Авторизация» (Authorization).
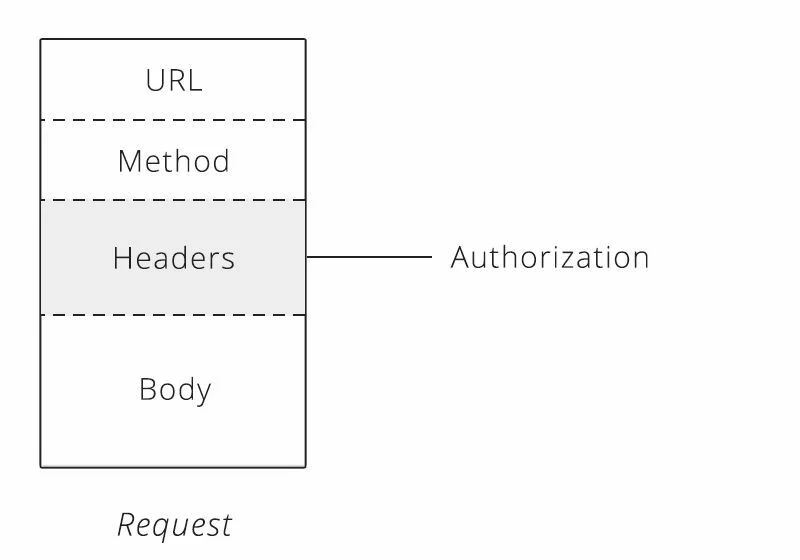
Когда сервер получает запрос, он просматривает заголовок Авторизации и сравнивает его с сохраненными учетными данными. Если имя пользователя и пароль совпадают с одним из пользователей в списке сервера, сервер выполняет запрос клиента от лица этого пользователя. Если совпадений нет, сервер возвращает специальный код состояния (401), чтобы клиент знал, что аутентификация не удалась и запрос отклонен.
Хотя базовая аутентификация является допустимой схемой аутентификации, то обстоятельство, что она использует одно и то же имя пользователя и пароль как для доступа к API так и для управления учетной записью, вызывает опасения. Это все равно что отель бы передавал гостю ключи от всего здания, а не от комнаты.
Точно так же с API могут быть случаи, когда клиент должен иметь другие разрешения, чем владелец учетной записи. Возьмем, к примеру, владельца бизнеса, который нанимает подрядчика для написания программы, использующей API от их имени. Передача подрядчику учетных данных подвергает владельца риску, поскольку недобросовестный подрядчик может изменить пароль, заблокировав владельцу бизнеса доступ к его собственной учетной записи. Понятно, что неплохо было бы иметь альтернативу.
Аутентификация с помощью ключа API
Аутентификация с помощью ключа API — это метод, который преодолевает слабость использования общих учетных данных, требуя доступа к API с помощью уникального ключа. В этой схеме ключ обычно представляет собой длинную последовательность букв и цифр, отличную от пароля для входа владельца учетной записи. Владелец дает ключ клиенту, так же как отель дает гостю ключ от одноместного номера.
Когда клиент аутентифицируется с помощью ключа API, сервер понимает, что можно разрешить клиенту доступ к данным, но теперь имеет возможность ограничить административные функции, такие как изменение паролей или удаление учетных записей. Иногда ключи используются просто, чтобы пользователю не приходилось выдавать свой пароль. Гибкость обеспечивается аутентификацией API Key для ограничения контроля, а также защиты паролей пользователей.
Итак, где же находится ключ API? Заголовок для него тоже есть, да? К сожалению, нет. В отличие от Basic Auth, который является установленным стандартом со строгими правилами, ключи API были разработаны в нескольких компаниях на заре интернета. В результате аутентификация с помощью ключа API немного похожа на дикий запад; у каждого свой способ делать это.
Однако со временем появилось несколько общих подходов. Один из них заключается в том, чтобы клиент поместил ключ в заголовок Авторизации вместо имени пользователя и пароля. Другой — добавить ключ в URL-адрес (http://example.com? api_key=my_secret_key ). Реже ключ закапывают где-нибудь в теле запроса рядом с данными. Куда бы ни пошел ключ, эффект будет одинаковым — он позволяет серверу аутентифицировать клиента.
Итог урока
В этом уроке мы узнали, как клиент может подтвердить свою личность серверу, процесс, называемый аутентификацией. Мы рассмотрели два метода или схемы, которые API используют для аутентификации. Ключевые термины, которые мы узнали, были:
- Аутентификация: процесс подтверждения клиентом своей личности серверу.
- Учетные данные: секретные данные, используемые для подтверждения личности клиента (имя пользователя, пароль ...).
- Базовая аутентификация: схема, использующая закодированные имя пользователя и пароль для учетных данных.
- API Key Auth: схема, использующая уникальный ключ для учетных данных.
- Заголовок авторизации: заголовок HTTP, используемый для хранения учетных данных.
В этом уроке мы рассмотрим другое решение — Открытую Авторизацию (Open Authorization, OAuth).
Делая жизнь проще для людей
Вам когда-нибудь приходилось заполнять регистрационную форму, подобную приведенной ниже?
Ввод длинного ключа в поле формы, подобное приведенному выше, создает посредственный опыт пользователя. Во-первых, вам нужно найти требуемый ключ. Конечно, он был прямо в вашем почтовом ящике, когда вы купили программное обеспечение, но год спустя вы пытаетесь его найти (с какого адреса электронной почты оно было отправлено? Какой адрес электронной почты я использовал для регистрации?!). Как только вы его найдете, вам нужно ввести чертову строку один в один как в почте — опечатка или пропуск одного символа приведет к сбою или даже может заблокировать вашу незарегистрированную программу!
Принуждение пользователей к работе с ключами API — тоже плохой опыт. Опечатки — обычная проблема, и она требует, чтобы пользователь вручную выполнял часть настройки между клиентом и сервером. Пользователь должен получить ключ от сервера, а затем передать его клиенту. Для инструментов, предназначенных для автоматизации работы, безусловно, есть лучшее решение.
И тут появляется OAuth. Автоматизация обмена ключами — одна из основных проблем, которую решает OAuth. Он предоставляет клиенту стандартный способ получить ключ от сервера, проведя пользователя через простой набор шагов. С точки зрения пользователя, все, что требуется для OAuth — это ввод учетных данных. За кулисами клиент и сервер общаются туда-сюда, чтобы добиться работающего ключа для клиента.
В настоящее время существует две версии OAuth, метко названные OAuth 1 и OAuth 2 . Понимание шагов в каждом из них необходимо, чтобы иметь возможность взаимодействовать с API, которые используют их для аутентификации. Поскольку у них общий сценарий, мы пройдемся по этапам OAuth 2, а затем укажем, чем отличается OAuth 1.
OAuth 2
Для начала нам нужно знать набор персонажей, участвующих в обмене OAuth:
- Пользователь — человек, который хочет связать два веб-сайта.
- Клиент — веб-сайт, которому будет предоставлен доступ к данным пользователя.
- Сервер — веб-сайт, на котором хранятся данные пользователя.
Затем нам нужно сделать краткое объявление. Одна из целей OAuth 2 — позволить организациям адаптировать процесс аутентификации к своим потребностям. Из-за такой расширяемой природы у API могут быть несколько разные шаги. Показанный ниже сценарий является обычным для веб-приложений. В мобильных и настольных приложениях этот процесс может немного отличаться.
Шаг 1 — Пользователь сообщает клиенту о необходимости подключения к серверу
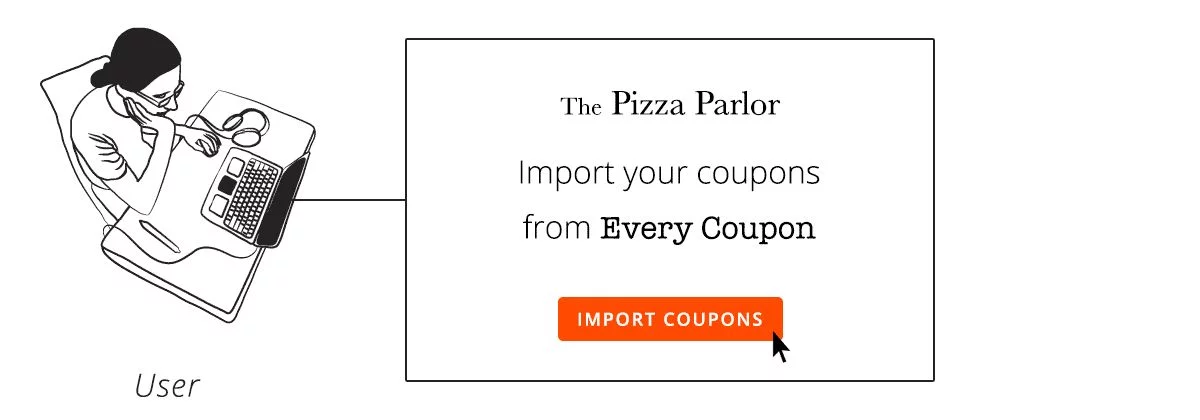
Пользователь запускает процесс, давая понять клиенту, что он хочет, чтобы он подключился к серверу. Обычно это делается нажатием кнопки.
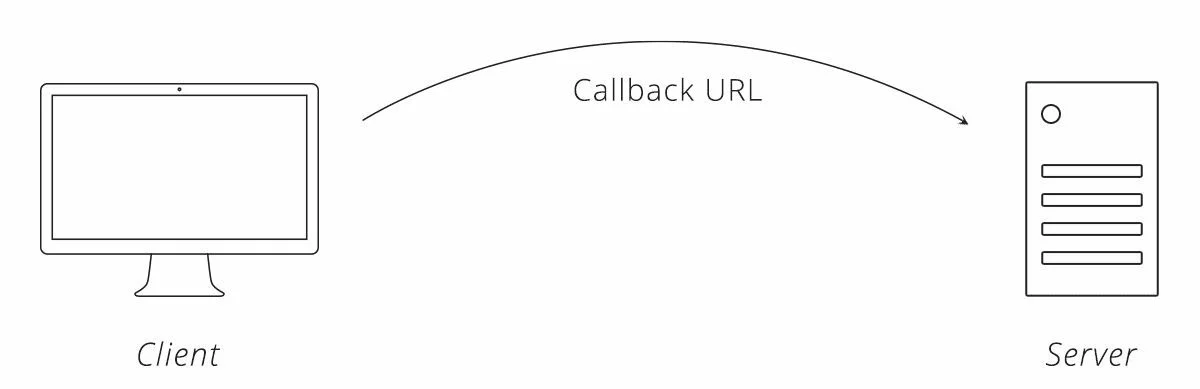
Шаг 2 — Клиент направляет пользователя на сервер
Клиент отправляет пользователя на веб-сайт сервера вместе с URL-адресом, на который сервер отправит пользователя обратно после аутентификации пользователя, называемого URL-адресом обратного вызова (callback URL).
Шаг 3 -— Пользователь входит на сервер и получает клиентский доступ
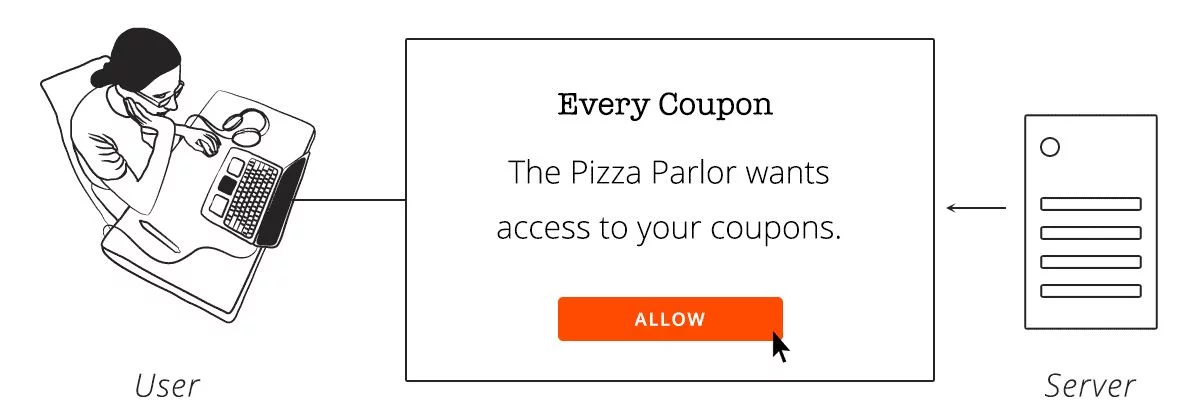
Используя свое обычное имя пользователя и пароль, пользователь аутентифицируется на сервере. Теперь сервер уверен, что один из его собственных пользователей запрашивает у клиента доступ к учетной записи пользователя и связанным данным.
Шаг 4 — Сервер отправляет пользователя обратно клиенту вместе с кодом
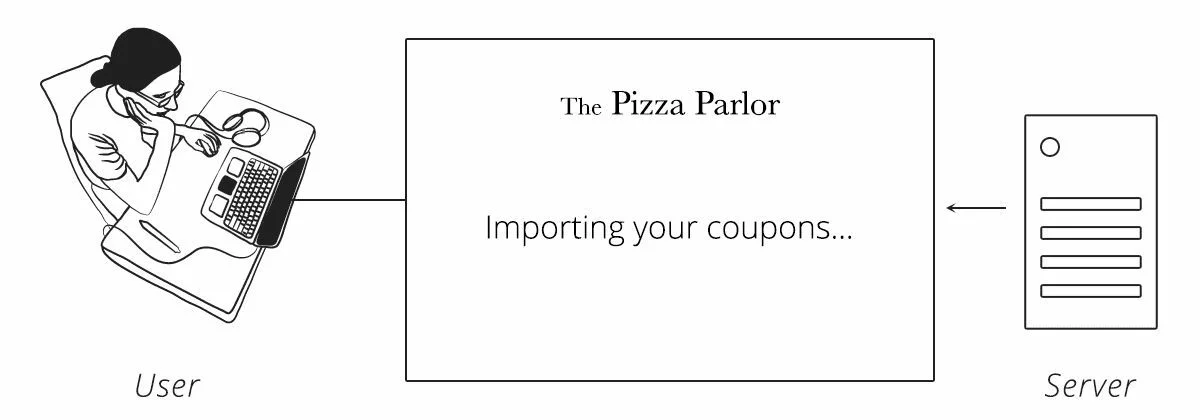
Сервер отправляет пользователя обратно клиенту (на URL-адрес обратного вызова из шага 2). В ответе скрыт уникальный код авторизации для клиента.
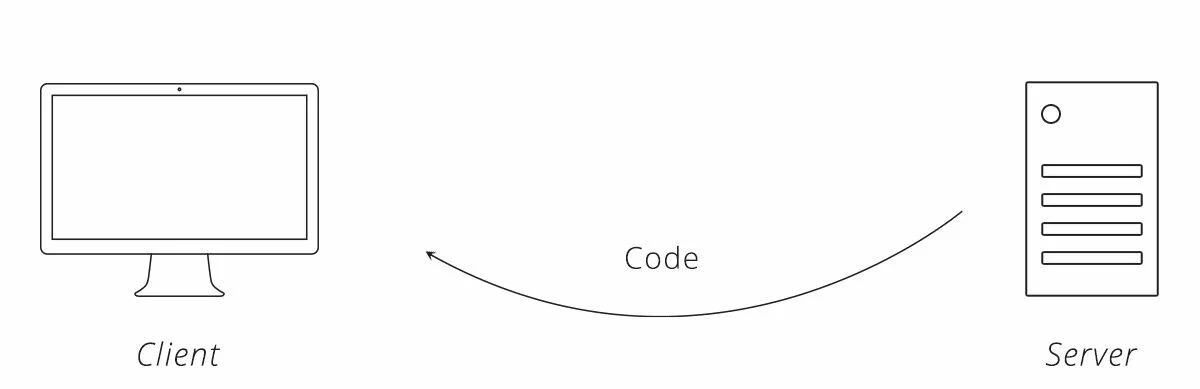
Шаг 5 — Клиент обменивает Код + секретный Ключ на Токен доступа
Клиент берет полученный код авторизации и делает еще один запрос к серверу. Этот запрос включает секретный ключ клиента. Когда сервер видит действительный код авторизации и секретный ключ доверенного клиента, он уверен, что клиент является тем, кем он себя называет, и что он действует от имени реального пользователя. Сервер отвечает токеном доступа.
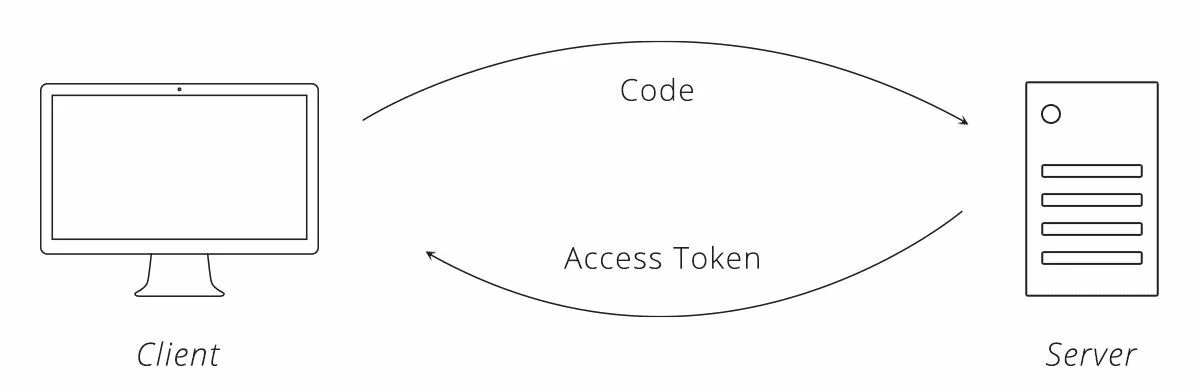
Шаг 6 — Клиент получает данные с сервера
На этом этапе клиент может получить доступ к серверу от имени пользователя. Маркер доступа из шага 6 — это, по сути, еще один пароль для учетной записи пользователя на сервере. Клиент включает токен доступа в каждый запрос, чтобы он мог аутентифицироваться напрямую с сервером.
Клиент обновляет токен (необязательно)
Функция, представленная в OAuth 2 — это возможность истечения срока действия токенов доступа. Это полезно для защиты учетных записей пользователей за счет усиления безопасности — чем быстрее истекает срок действия токена, тем меньше времени может быть злонамеренно использован украденный токен, подобно тому, как срок действия номера кредитной карты истекает через определенное время. Срок службы токена устанавливается сервером. API на практике могут использовать срок от часов до месяцев. По истечении срока службы клиент должен запросить у сервера новый токен.
Чем отличается OAuth 1
Между версиями OAuth существует несколько ключевых различий. Один мы уже упоминали; токены доступа не имеют срока действия.
Еще одно отличие состоит в том, что OAuth 1 включает дополнительный шаг. Между шагами 1 и 2, описанными выше, OAuth 1 требует, чтобы клиент запросил у сервера токен запроса. Этот токен действует как код авторизации в OAuth 2 и обменивается на токен доступа.
Третье отличие состоит в том, что OAuth 1 требует, чтобы запросы были подписаны цифровой подписью. Мы опустим детали того, как именно работает подписание (вы можете найти библиотеки кода, которые сделают это за вас), но стоит знать, почему оно есть в одной версии OAuth, но не в другой. Подписание запроса — это способ защитить данные от подделки при их передаче между клиентом и сервером. Подписи позволяют серверу проверять подлинность запросов.
Однако сегодня большая часть API-трафика происходит по уже защищенному каналу (HTTPS). Понимая это, OAuth 2 устраняет подписи, стараясь упростить использование второй версии. Дело заключается в том, что OAuth 2 полагается на другие меры для обеспечения безопасности передаваемых данных.
Авторизация
Элементом OAuth 2, заслуживающим особого внимания, является концепция ограничения доступа, официально известная как авторизация. Вернемся к шагу 2, когда пользователь нажимает кнопку, чтобы разрешить доступ клиенту, где-то глубоко внутри скрываются те самые разрешения, которые запрашивает клиент. Эти разрешения, называемые областью действия (scope), являются еще одной важной функцией OAuth 2. Они позволяют клиенту запрашивать ограниченный доступ к данным пользователя, тем самым облегчая пользователю доверие к клиенту.
Что делает область действия действительно мощным инструментом, так это то, что её ограничения связаны с конкретным клиентом. В отличие от ключа API, где ограничения, налагаемые на ключ, одинаково влияют на каждого клиента, область действия OAuth позволяет одному клиенту иметь разрешение X, а другому — разрешения X и Y. Это означает, что один веб-сайт может просматривать ваши контакты, а другой сайт может просматривать и редактировать их.
Итоги урока
В этом уроке мы узнали, как проходит процесс аутентификации по модели OAuth. Мы сравнили две версии, указав на существенное различие между ними.
Ключевые термины:
- OAuth: схема аутентификации, которая автоматизирует обмен ключами между клиентом и сервером.
- Токен доступа: кодовая строка, которую клиент получает после успешного завершения процесса OAuth.
- Область действия: разрешения, определяющие доступ клиента к данным пользователя.
Проектирование API
Мы закончили изучение основ и теперь готовы посмотреть, как предыдущие концепции объединяются в API. В этой главе мы обсуждаем компоненты API, разрабатывая его.
Организация данных
По оценкам National Geographic, в 2011 году американцы сделали 80 миллиардов фотографий. Имея такое количество фотографий, вы можете представить себе разные подходы людей к их упорядочению на своих компьютерах. Некоторые предпочитают сбрасывать все в одну папку. Другие тщательно выстраивают свои фотографии в иерархию папок по годам, месяцам и событиям.
Подобным образом и компании относятся к структурированию при создании своих API. Как мы упоминали ранее, цель API — облегчить компьютерам работу с данными компании. Имея в виду простоту использования, одна компания может решить создать единый URL-адрес для всех данных и сделать его доступным для поиска (что-то вроде одной папки для всех ваших фотографий). Другая может решить дать каждому фрагменту данных свой собственный URL-адрес, организованный в виде иерархии (как с папками и подпапками для фотографий). Каждая компания выбирает лучший способ структурировать свой API для своей конкретной ситуации, руководствуясь существующими лучшими отраслевыми практиками.
Начните с архитектурного стиля
Обсуждая API, вы можете услышать разговоры о «мыле» (SOAP) и «отдыхе» (REST) и задаться вопросом, работают ли разработчики программного обеспечения или планируют отпуск. На самом деле это названия двух наиболее распространенных архитектур для веб-API:
- SOAP (изначально бывший сокращением, Simple Object Access Protocol) — это схема взаимодействия на основе XML, которая имеет стандартизованные структуры для запросов и ответов.
- REST, что означает «передача репрезентативного состояния» (Representational State Transfer), представляет собой более открытый подход, предусматривающий множество соглашений, но оставляющий многие решения на усмотрение человека, разрабатывающего API.
На протяжении этого курса вы, возможно, заметили, что у нас есть склонность к REST API. Это предпочтение во многом связано с невероятной скоростью принятия REST. Это не означает, что SOAP — зло; у него есть свои сильные стороны. Однако в центре нашего обсуждения останется REST, так как это, скорее всего, именно тот API, с которым вы столкнетесь. В остальных разделах мы рассмотрим компоненты, составляющие REST API.
Наш первый ресурс
Напомним, что ресурсы — это существительные в API-интерфейсах (клиенты и пицца). Это то, с чем мы хотим, чтобы мир мог взаимодействовать через наш API.
Чтобы понять, как компания разрабатывает API, давайте попробуем это сделать в нашей пиццерии. Начнем с добавления возможности заказать пиццу.
Чтобы клиент мог поговорить с нами о пицце, нам нужно сделать несколько вещей:
- Решить, какие ресурсы должны быть доступны.
- Назначить URL-адреса этим ресурсам.
- Решить, какие действия клиенту следует разрешить выполнять с этими ресурсами.
- Выяснить, какие фрагменты данных требуются для каждого действия и в каком формате они должны быть.
Выбор ресурсов может оказаться непростой первой задачей. Один из способов подойти к проблеме — пройти через то, что включает в себя типичное взаимодействие. В нашей пиццерии наверняка есть меню. В этом меню — пицца. Когда клиент хочет, чтобы мы приготовили для него одну из пицц, он размещает заказ. В этом контексте меню, пицца, покупатель и заказ выглядят как хорошие кандидаты на ресурсы. Начнем с заказа.
Следующим шагом будет присвоение URL-адресов ресурсу. Есть много возможностей, но, к счастью, соглашения REST дают некоторые рекомендации. В типичном REST API ресурсу будут назначены два шаблона URL. Первый — это множественное число от имени ресурса, например /orders . Второй — это множественное число от имени ресурса плюс уникальный идентификатор для указания одного ресурса, например /orders/<order_id>, где <order_id> — уникальный идентификатор для заказа. Эти два шаблона URL составляют первые конечные точки (endpoints), которые будет поддерживать наш API. Они называются конечными точками просто потому, что они идут в конце URL-адреса, как в http://example.com/<endpoint_goes_here>.
Теперь, когда мы выбрали ресурс и присвоили ему URL-адреса, нам нужно решить, какие действия может выполнять клиент. Следуя соглашениям REST, мы говорим, что конечная точка множественного числа (/orders) предназначена для перечисления существующих заказов и создания новых. Множественное число с уникальным идентификатором конечной точки (/orders/<order_id>) предназначено для извлечения, обновления или отмены определенного заказа. Клиент сообщает серверу, какое действие следует выполнить, передавая в запросе соответствующую команду HTTP (GET, POST, PUT или DELETE).
В целом наш API теперь выглядит так:

После того как действия для конечных точек нашего заказа продуманы, последний шаг — решить, какими данными необходимо обмениваться между клиентом и сервером. Заимствуя пример с пиццерией из главы 3, мы можем сказать, что заказ требует корочки и начинки. Нам также необходимо выбрать формат данных, который клиент и сервер могут использовать для передачи этой информации туда и обратно. И XML и JSON — хорошие кандидаты, но для удобства чтения мы выберем JSON.
На этом этапе вы можем себя поздравить; мы разработали работающий API! Вот как может выглядеть взаимодействие между клиентом и сервером с использованием этого API:
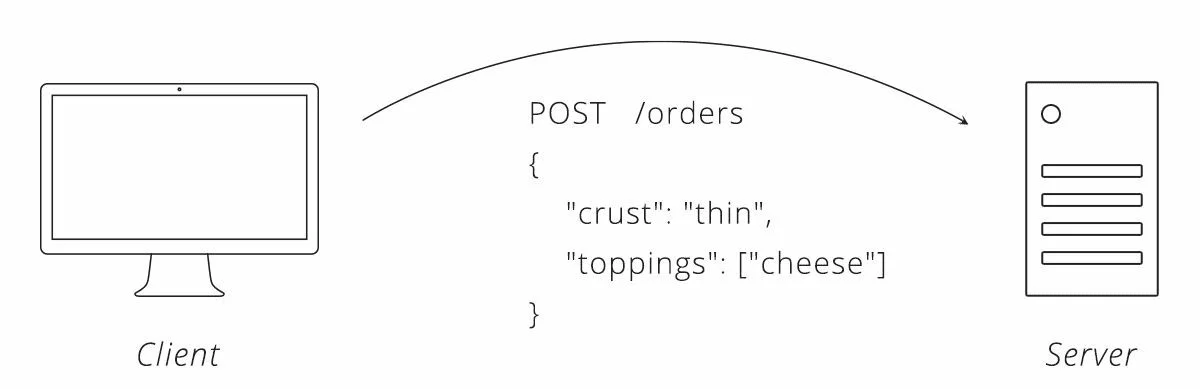
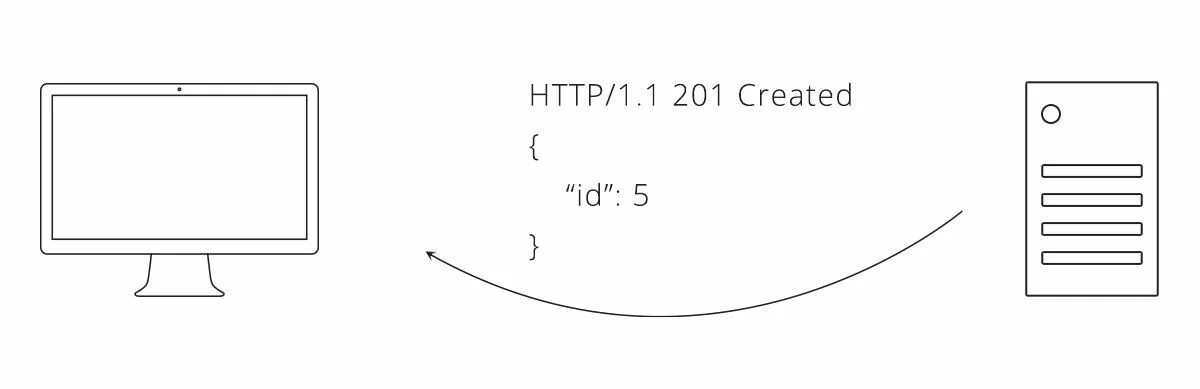
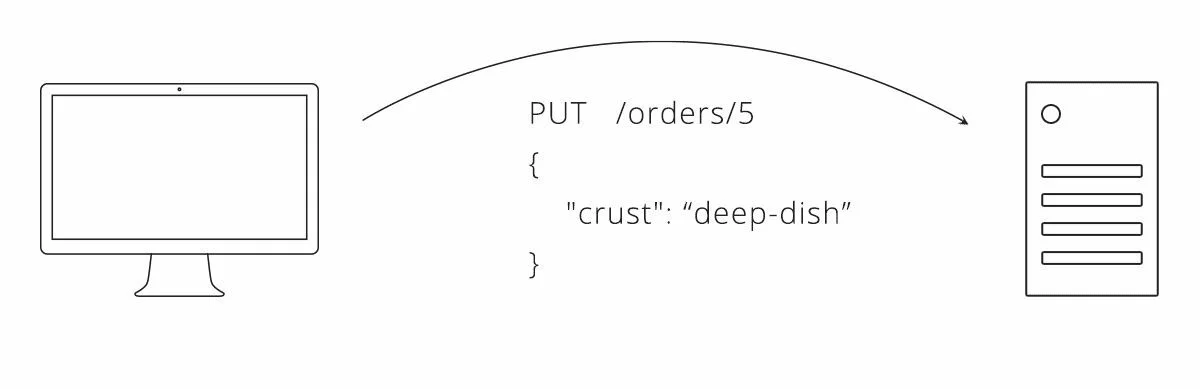
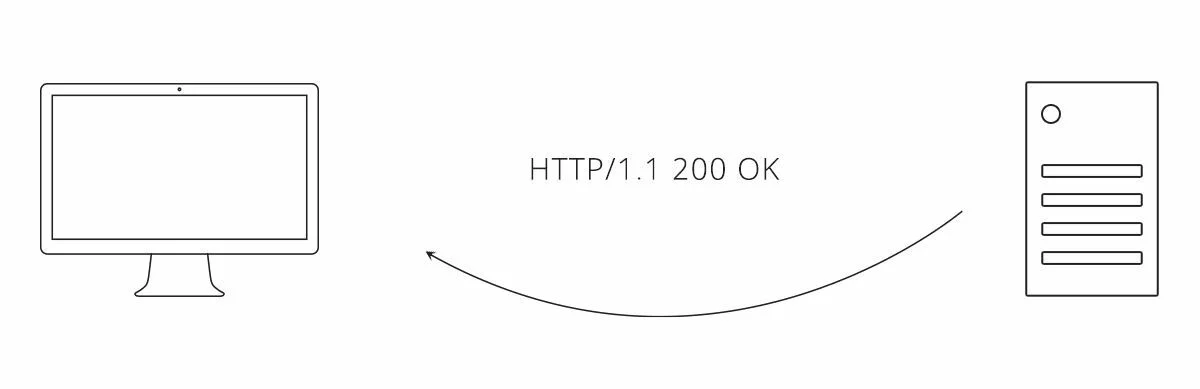
Рисунок 1. Пример взаимодействия между клиентом и сервером с использованием нашего API
Связывание ресурсов вместе
API нашей пиццерии выглядит отлично. Заказы поступают как никогда раньше. Бизнес идет настолько хорошо, что мы решили начать отслеживать клиентов заказов, чтобы оценивать их лояльность. Самый простой способ сделать это — добавить новый ресурс — клиента.
Как и в случае с заказами, нашему ресурсу Клиент нужны конечные точки. Следуя соглашению, /customers и /customers/<id> хорошо подходят. Опустим детали, но скажем, что нужно решить, какие действия имеют смысл для каждой конечной точки и какие данные представляют клиента. Предполагая, что мы все это сделаем, мы приходим к интересному вопросу: как связать заказы с покупателями?
Практики REST разделились во мнениях о том, как решить проблему связывания ресурсов. Некоторые говорят, что иерархия должна продолжать расти, давая конечные точки типа /customers/5/orders для всех заказов клиента №5. И /customers/5/orders/3 для третьего заказа клиента №5. Другие утверждают, что для упрощения ситуации необходимо включать связанные детали в данные для ресурса. Согласно этой парадигме, создание заказа требует отправки поля customer_id с деталями заказа. Оба решения широко используются в REST API, поэтому стоит знать о каждом.

Поиск данных
По мере роста объема данных в системе, конечные точки, которые выдают полный перечень записей, становятся непрактичными. Представьте себе, что в нашей пиццерии было три миллиона выполненных заказов, и вы хотели бы узнать, в скольких из них есть пепперони в качестве начинки. Отправка запроса GET на /orders и получение всех трех миллионов заказов не очень помогает. К счастью, в REST есть отличный способ поиска данных.
У URL есть еще один компонент, о котором мы еще не упомянули — строка запроса (query string). Запрос означает поиск, а строка означает текст. Строка запроса — это фрагмент текста, который идет в конец URL-адреса для передачи данных в API. Например, все, что находится после вопросительного знака, является строкой запроса в http://example.com/orders?key=value.
API REST используют строку запроса для указания деталей поиска. Эти сведения называются параметрами запроса. API определяет, какие параметры он будет принимать, и их точные имена должны использоваться, чтобы они могли влиять на поиск. Наш API пиццерии может позволить клиенту искать заказы по топпингам их по следующему URL-адресу: http://example.com/orders?topping=pepperoni . Клиент может включать несколько параметров запроса, перечисляя один за другим, разделяя их амперсандом ("&"). Например: http://example.com/orders?topping=pepperoni&crust=thin
Другое использование строки запроса — ограничение количества данных, возвращаемых в каждом запросе. Часто API-интерфейсы разделяют результаты на наборы (скажем, из 100 или 500 записей) и возвращают по одному набору за раз. Этот процесс разделения данных известен как разбиение на страницы (pagination, аналогия разбиения слов на страницы для книг). Чтобы позволить клиенту просматривать все данные, API будет поддерживать параметры запроса, которые позволяют клиенту указать, какую страницу данных он хочет. В нашем API пиццерии мы можем поддерживать разбиение на страницы, позволяя клиенту указывать два параметра: страницу и размер. Если клиент делает запрос типа GET /orders?page=2&size=200, мы знаем, что ему нужна вторая страница результатов с 200 результатами на страницу, а именно заказы 201-400.
Итог урока
В этом уроке мы узнали, как разработать REST API. Мы показали основные функции, поддерживаемые API, и показали, как организовать данные так, чтобы их можно было легко использовать компьютеру.
Ключевые термины, которые мы узнали, были:
- SOAP: протокол обмена структурированными сообщениями в распределённой вычислительной среде.
- REST: архитектура API, ориентированная на управление ресурсами.
- Ресурс: термин API для такого бизнес-объекта, как клиент или заказ.
- Конечная точка: URL-адрес, составляющий часть API. В REST каждый ресурс получает свои собственные конечные точки.
- Строка запроса: часть URL-адреса, которая используется для передачи данных на сервер.
- Параметры запроса: пара "ключ-значение", найденная в строке запроса (топпинг = сыр).
- Разбиение на страницы: процесс разделения результатов на управляемые части.
Связь в реальном времени
Давайте посмотрим, как заставить API работать на нас. В этом уроке мы узнаем четыре способа связи в реальном времени через API.
Интеграции
Чтобы подготовить почву для нашего обсуждения, давайте напомним себе, почему API-интерфейсы полезны. Еще в главе 1 мы говорили, что API-интерфейсы упрощают обмен данными между двумя системами (веб-сайтами, рабочими столами, смартфонами).
Прямое совместное использование позволяет нам связывать системы вместе, чтобы сформировать интеграцию. Людям нравятся интеграции, потому что они облегчают жизнь. Благодаря интеграции вы можете что-то делать в одной системе, а другая будет обновляться автоматически.
Для наших целей мы разделим интеграции на две большие категории. Первую мы назовем «управляемые клиентом», когда человек взаимодействует с клиентом и хочет, чтобы данные сервера обновлялись. Другую мы назовем «управляемые сервером», когда человек что-то делает на сервере и требует, чтобы клиент знал об изменении.
Причина такого разделения интеграций сводится к одному простому факту: клиент — единственный, кто может инициировать общение. Помните, что клиент делает запросы, а сервер просто отвечает. Следствием этого ограничения является то, что изменения легко отправить с клиента на сервер, но трудно — в обратном направлении.
Интеграция, управляемая клиентом
Чтобы продемонстрировать, почему интеграция, управляемая клиентом, проста, давайте обратимся к нашей надежной пиццерии и ее API для заказа пиццы. Допустим, мы выпускаем приложение для смартфона, использующее API. В этом сценарии API пиццерии является сервером, а приложение для смартфона — клиентом. Клиент использует приложение, чтобы выбрать пиццу, а затем нажимает кнопку, чтобы разместить заказ. Как только кнопка нажата, приложение знает, что ему нужно сделать запрос к API пиццерии.
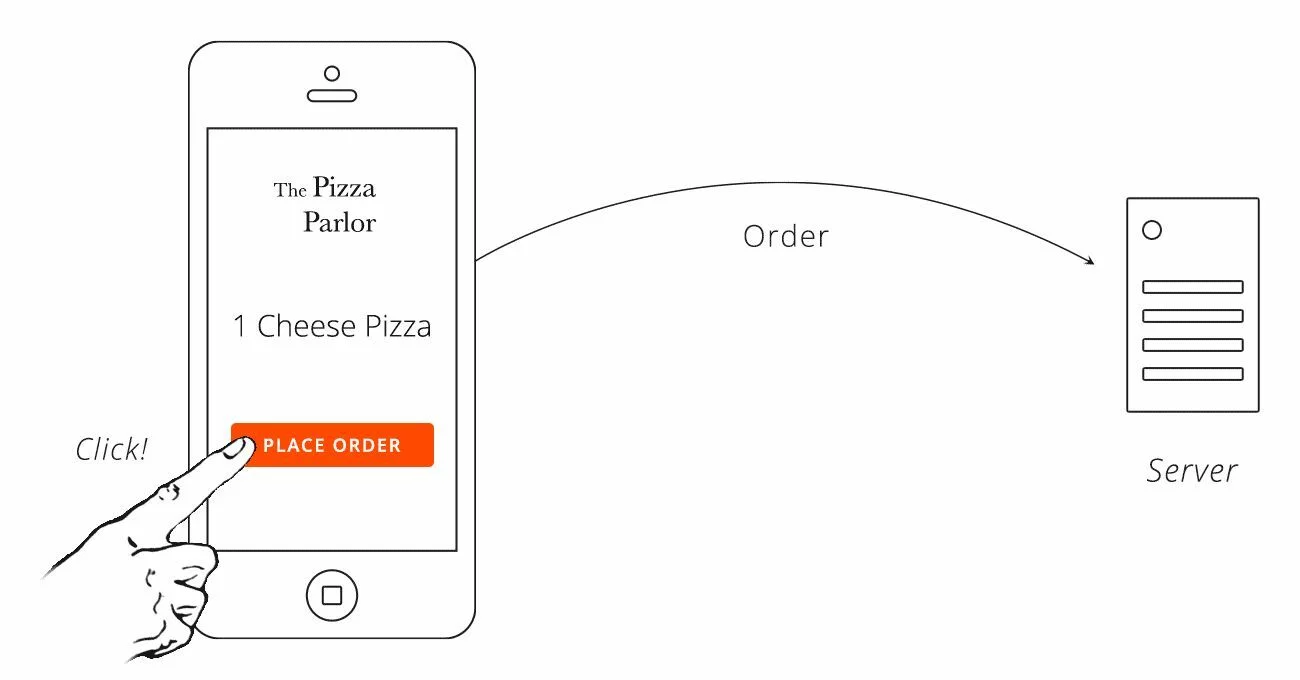
В более общем смысле, когда человек взаимодействует с клиентом, клиент точно знает, когда данные изменяются, поэтому он может немедленно вызвать API, чтобы сообщить серверу. Нет никакой задержки (следовательно, происходит в реальном времени), и процесс эффективен, потому что для каждого действия, предпринимаемого человеком, делается только один запрос.
Интеграция, управляемая сервером
После размещения заказа на пиццу покупатель может захотеть узнать, когда пицца будет готова. Как мы используем API, чтобы предоставлять им обновления? Что ж, это немного сложнее. Покупатель не имеет отношения к приготовлению пиццы. Он ждет, пока пиццерия приготовит пиццу и обновит статус заказа. Другими словами, данные на сервере меняются, и клиент должен знать об этом. Тем не менее, если сервер не может делать запросы, мы, кажется, застряли!
Для решения этого типа проблемы мы используем вторую категорию интеграций. Есть ряд решений, которые разработчики программного обеспечения используют, чтобы обойти ограничение, что только клиенты могут отправлять запросы. Давайте посмотрим на каждое из таких решений.
Опрос / Polling
Когда клиент — единственный, кто может делать запросы, самое простое решение для поддержания его в актуальном состоянии с сервером — это просто запросить у сервера обновления. Это может быть выполнено путем многократного запроса одного и того же ресурса, метод, известный как опрос (polling).
В нашей пиццерии опрос статуса заказа может выглядеть следующим образом.
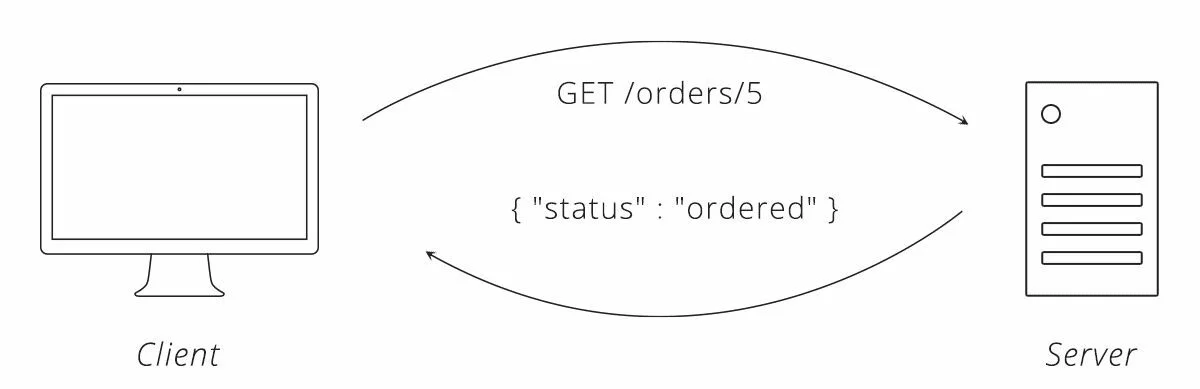
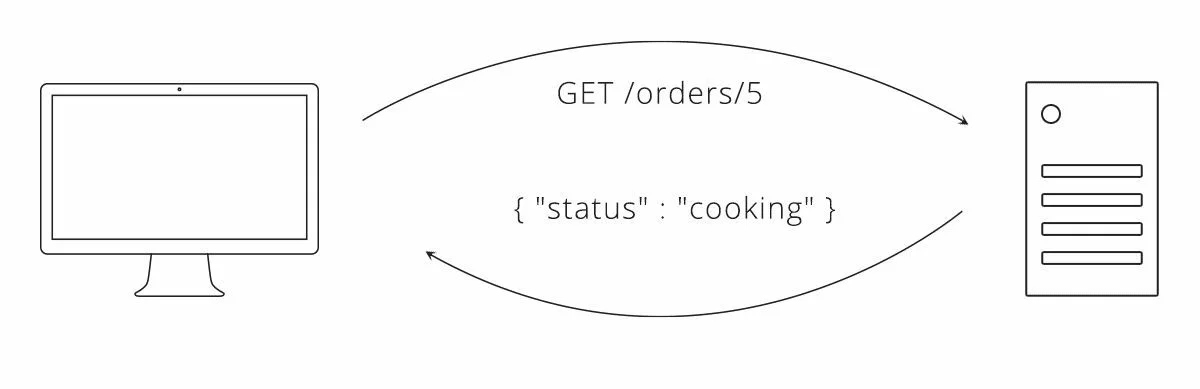
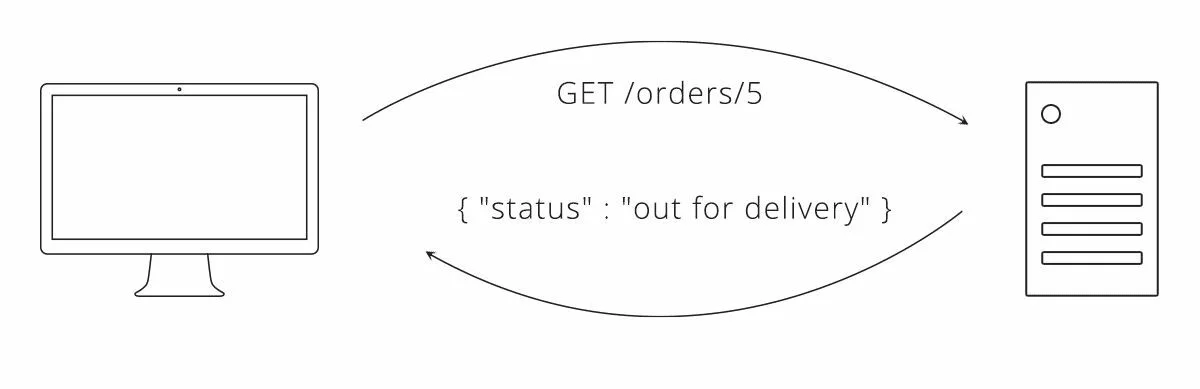
Рисунок 2. Пример опроса статуса заказа в нашей пиццерии
В этом подходе, чем чаще клиент делает запросы (опросы), тем ближе клиент к общению в реальном времени. Если клиент опрашивает каждый час, в худшем случае может быть часовая задержка между изменением, происходящим на сервере, и тем, что клиент узнает об этом. Вместо этого опрашивайте каждую минуту, и клиент и сервер эффективно синхронизируются.
Конечно, у этого решения есть одна большая проблема. Это ужасно неэффективно. Большинство запросов, которые делает клиент, теряются, потому что ничего не изменилось. Хуже того, чтобы получать обновления раньше, необходимо сократить интервал опроса, в результате чего клиент будет делать больше запросов и становится еще более неэффективным. Это решение плохо масштабируется.
Долгий опрос (long polling)
Если бы запросы были бесплатными, то никто не заботился бы об эффективности, и каждый мог бы просто использовать опрос. К сожалению, обработка запросов обходится дорого. Чтобы API мог обрабатывать больше запросов, ему необходимо использовать больше серверов, что стоит больше денег. Если масштабировать эту громоздкую ситуацию до размеров Google или Facebook, вы заплатите немало за неэффективность. Следовательно, было приложено много усилий для оптимизации способа получения клиентом обновлений с сервера.
Одна оптимизация, которая состоит из опроса, называется долгим опросом. При длительном опросе используется та же идея, что клиент неоднократно запрашивает у сервера обновления, но с одной изюминкой: сервер не отвечает немедленно. Вместо этого сервер ждет, пока что-то не изменится, а затем отвечает обновлением.
Давайте вернемся к приведенному выше примеру опроса, но на этот раз с сервером, который использует трюк с долгим опросом.
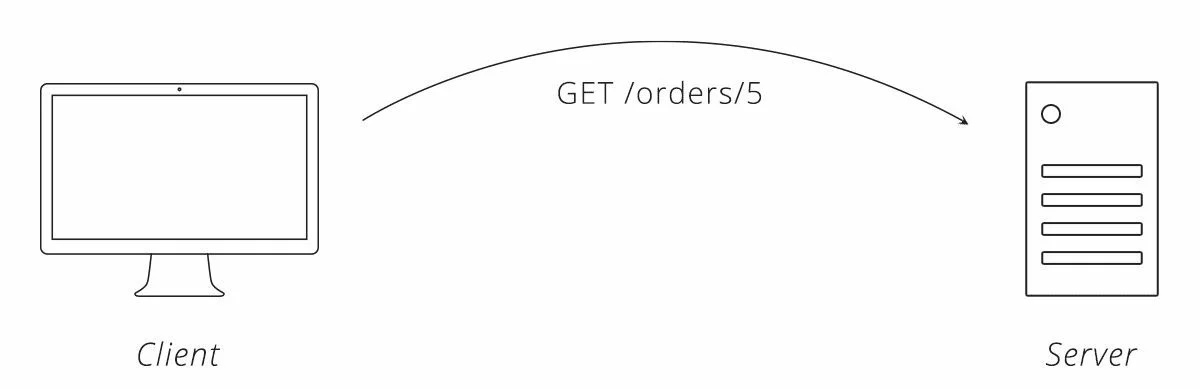


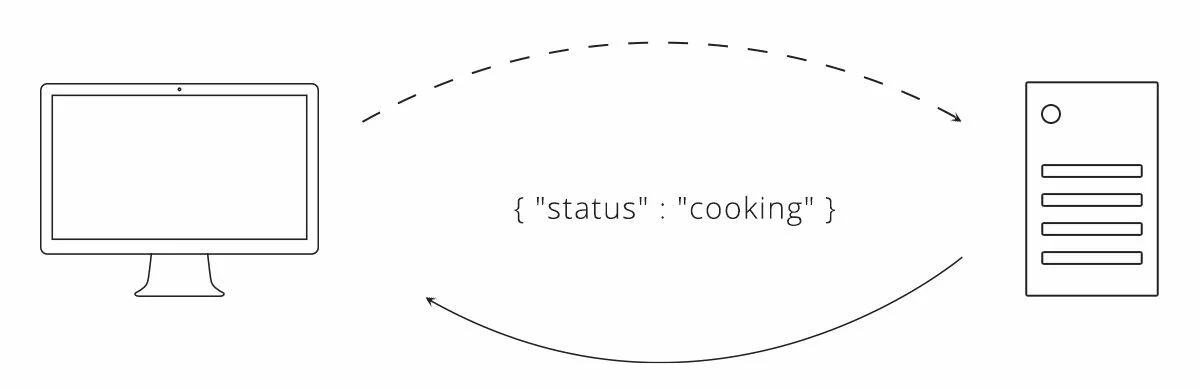
Рисунок 3. Пример долгого опроса
Это довольно умная техника. Он подчиняется правилу, что клиент отправляет первоначальный запрос, в то же время пользуясь тем фактом, что не существует правила, запрещающего серверу медленно отвечать. Пока и клиент, и сервер согласны с тем, что сервер будет удерживать запрос клиента, и клиент может поддерживать свое соединение с сервером открытым, он будет работать.
Каким бы изобретательным ни был долгий опрос, у него тоже есть некоторые недостатки. Мы пропустим технические детали, но есть проблемы, например, сколько запросов сервер может удерживать за раз или как восстановить, если клиент или сервер потеряют соединение. А пока мы скажем, что для некоторых сценариев ни одна из форм опроса не подходит.
Вебхуки(webhooks).
Некоторые продвинутые разработчики программного обеспечения думали: «если все наши проблемы в том, что клиент — единственный, кто делает запросы, почему бы не удалить это правило?» Так они и сделали. Результатом стали вебхуки (веб-перехватчики, webhooks) — техника, при которой клиент одновременно отправляет запросы и прослушивает их, позволяя серверу легко отправлять ему обновления.
Если это звучит как жульничество, потому что теперь у нас есть сервер, отправляющий запросы клиенту, не волнуйтесь, вам не сказали неправду. Вебхуки работают именно потому, что клиент тоже становится сервером! С технической точки зрения иногда очень легко расширить функциональность клиента, чтобы он также прослушивал запросы, обеспечивая двустороннюю связь.
Давайте посмотрим на суть вебхуков. В своей простейшей форме веб-перехватчики требуют, чтобы клиент предоставил URL-адрес обратного вызова, по которому он может получать события, а на сервере должно быть место для ввода этого URL-адреса обратного вызова. Затем, когда что-то изменяется на сервере, сервер может отправить запрос на URL-адрес обратного вызова клиента, чтобы сообщить клиенту об обновлении.
Для нашей пиццерии поток может выглядеть примерно так.





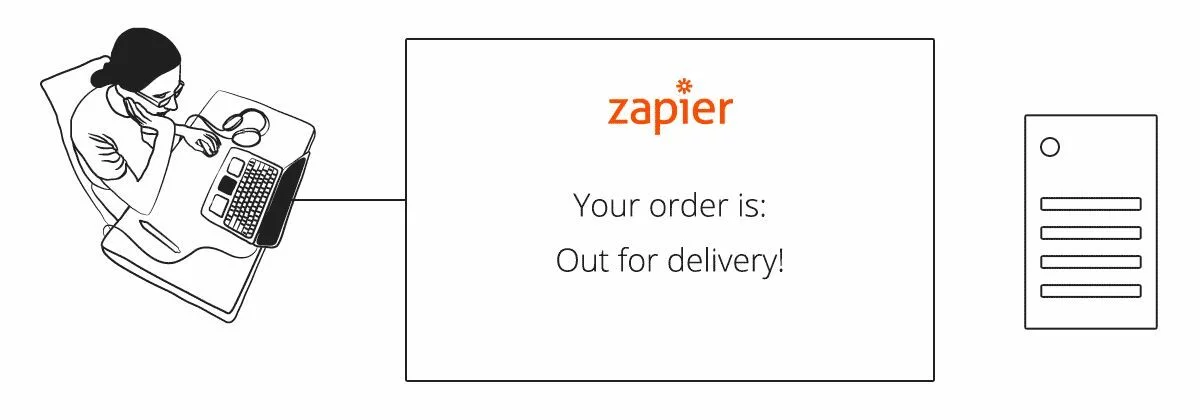
Рисунок 4. Использование вебхуков для получения обновлений (с Zapier в качестве клиента)
Это отличное решение. Изменения, происходящие на сервере, мгновенно отправляются клиенту, поэтому у вас есть настоящая связь в реальном времени. Кроме того, вебхуки эффективны, поскольку на одно обновление выполняется только один запрос.
Подписка на веб-перехватчики
Основываясь на идее вебхуков, было разработано множество решений, направленных на то, чтобы сделать процесс настройки динамичным и не требовать, чтобы человек вручную вводил URL-адрес обратного вызова на сервере. Вы можете услышать такие названия, как спецификация HTTP-подписок, Restful Webhooks, REST Hooks и PubSubHubbub . Все эти решения пытаются определить процесс подписки, в котором клиент может сообщить серверу, какие события ему интересны и по какому URL-адресу обратного вызова отправлять обновления.
Каждое решение имеет несколько иной подход к проблеме, но в целом поток выглядит следующим образом.
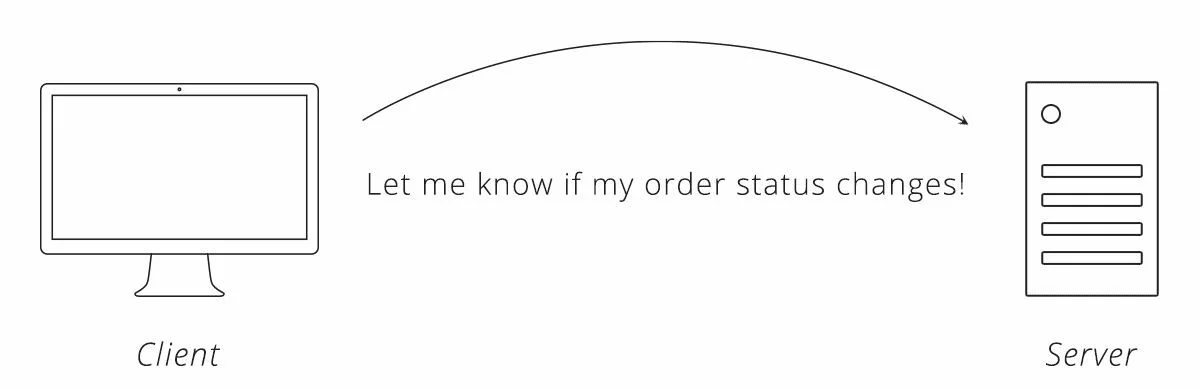
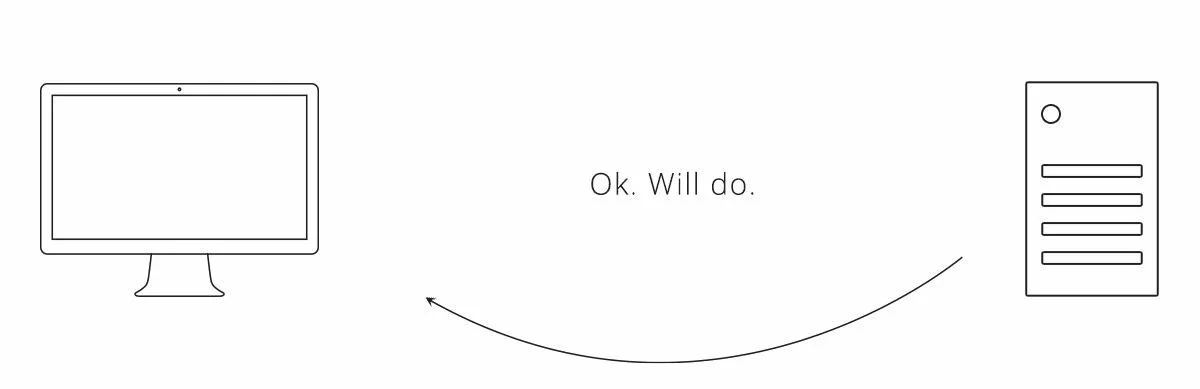

Рисунок 5. Запросы, необходимые для веб-перехватчиков подписок
Веб-перехватчики по подписке многообещающи. Они эффективны, работают в режиме реального времени и просты в использовании. Подобно взрывному распространению REST, это движение растет, и API все чаще поддерживают ту или иную форму веб-перехватчиков.
Тем не менее, в обозримом будущем, скорее всего, найдется место для опросов и длительных опросов. Не все клиенты могут также выступать в качестве серверов. Смартфоны — отличный пример, когда технические ограничения исключают возможность использования веб-перехватчиков. По мере развития технологий будут появляться новые идеи о том, как упростить обмен данными в реальном времени между всеми видами устройств.
Итог урока:
В этом уроке сгруппировали интеграции по двум широким категориям: управляемые клиентом и управляемые сервером. Мы увидели, как API-интерфейсы могут использоваться для предоставления обновлений в реальном времени между двумя системами, а также некоторые сложности, с этим связанные.
Ключевые термины, которые мы узнали:
- Опрос: многократный запрос ресурса с коротким интервалом.
- Долгий опрос: опрос, но с отложенным ответом; повышает эффективность.
- Вебхук(Webhook): когда клиент предоставляет серверу URL-адрес обратного вызова, чтобы сервер мог публиковать обновления в режиме реального времени.
- Подписка на вебхуки: неофициальное название для решений, которые делают автоматическую настройку веб-перехватчиков.
Реализация
От плана к продукту
Как мы видели в этом курсе, взаимодействие через API включает две стороны. Однако, когда мы говорим на уровне кода, на самом деле мы говорим о том, что нам нужны две программы, реализующие API. Программа реализует API, если следует правилам конкретного API. В нашем примере с пиццерией клиент, который может делать запросы к конечной точке /orders, используя правильные заголовки и формат данных, будет клиентом, который реализует API пиццерии.
За серверную программу отвечает компания, публикующая API. Ранее мы рассмотрели процесс проектирования API. После планирования следующий шаг для компании — реализовать свою сторону, написав программное обеспечение, соответствующее задуманному проекту. Последний шаг — разместить получившуюся программу на сервере.
Наряду с серверным программным обеспечением компания издает документацию для API. Документация — это один или несколько документов — обычно веб-страницы или PDF-файлы, объясняющие, как использовать API. Она включает в себя информацию, например, о том, какую схему аутентификации использовать, какие конечные точки доступны и как форматируются данные. Она также может включать примеры ответов, фрагменты кода и интерактивную консоль для игры с доступными конечными точками. Документация важна, потому что она действует как руководство для создания клиентов. Сюда кто-то, кто заинтересован в использовании API, идет, чтобы узнать, как он работает.
Имея под рукой документацию, вы можете начать использовать API в качестве клиента несколькими способами. Давайте теперь рассмотрим три из них.
HTTP-клиенты
Легкий способ начать использовать API — это использовать HTTP-клиент, общую программу, которая позволяет быстро создавать HTTP-запросы для тестирования. Вы указываете URL-адрес, заголовки и тело, и программа отправляет его на сервер в правильном формате. Эти типы программ бывают самых разных вкусов, включая веб-приложения, настольные приложения, расширения веб-браузера и многое другое.
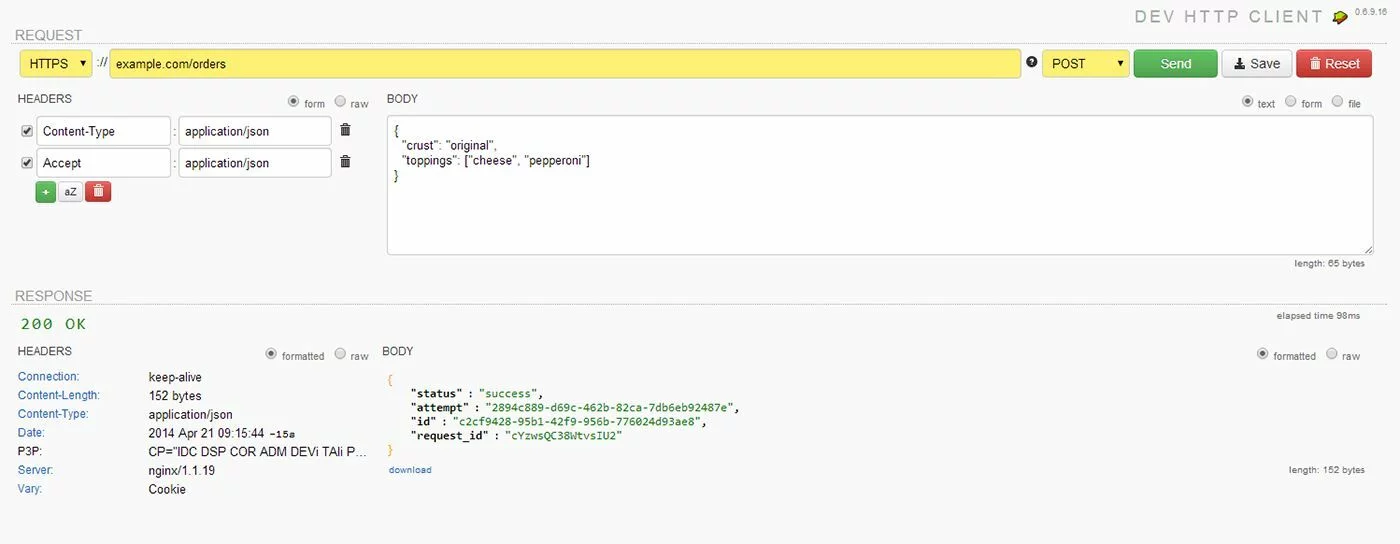
Хорошая вещь об общих HTTP-клиентах заключается в том, что вам не нужно знать, как их программировать. Благодаря навыкам, которые вы приобрели в ходе этого курса, теперь у вас есть возможность читать документацию по API, изданную конкретной компанией и придумывать запрос, который вам нужно сделать, чтобы получить нужные данные. Эта небольшой порог в освоении превращает обычных клиентов в отличный способ для исследования и быстрых одноразовых задач.
Однако у этого подхода есть несколько недостатков. Во-первых, обычно вы не можете сохранить свою работу. После того, как вы закроете программу, сделанные вами запросы будут забыты, и вам придется перестроить их в следующий раз, когда они вам понадобятся. Еще один недостаток заключается в том, что с возвращаемыми данными обычно мало что можно сделать, кроме как посмотреть на них. В лучшем случае у вас есть возможность сохранить данные в файл, и после этого уже вы можете сделать с ними что-нибудь интересное.
Написание кода
Чтобы по-настоящему использовать возможности API, вам в конечном итоге понадобится специальное программное обеспечение. Вот тут-то и приходит на помощь программирование. Поскольку программирование — это самостоятельная (отдельная от интеграций как таковых) дисциплина, мы не будем пытаться охватить все, что связано с разработкой программного обеспечения, но мы можем дать вам некоторые рекомендации относительно того, что включает в себя написание клиента API.
Первое требование — немного познакомиться с языком программирования. Их много, и у каждого есть свои сильные и слабые стороны. Для простоты, вероятно, вам для начала лучше придерживаться интерпретируемого языка (JavaScript, Python, PHP, Ruby или аналогичный) вместо компилируемого языка (C или C ++).
Если вы не уверены, какой язык выбрать, отличный способ сузить выбор — найти API, который вы хотите реализовать, и посмотреть, предоставляет ли компания клиентскую библиотеку. Библиотека — это код, который публикует владелец API, который уже реализует клиентскую сторону их API. Иногда библиотека бывает доступна для загрузки по отдельности или будет включена в SDK (Software Development Kit). Применение библиотеки экономит ваше время, потому что вместо чтения документации API и формирования сырых HTTP-запросов вы можете просто скопировать и вставить несколько строк кода и сразу получить рабочий клиент.
После того, как вы выберете язык, вам нужно решить, где будет запускаться код. Если вы автоматизируете свои собственные задачи, запуск программного обеспечения с рабочего компьютера может быть вполне подойдет. Однако чаще всего вы захотите запустить код на компьютере, который лучше подходит для работы в качестве веб-сервера. Доступно довольно много решений, в том числе запуск вашего кода в средах общего хостинга, облачных сервисах (например, Amazon Web Services) или даже на ваших собственных физических серверах в центре обработки данных.
Третье важное решение — выяснить, что вы будете делать с данными. Сохранить результаты в файл достаточно просто, но если вы хотите сохранить данные в базе данных или отправить их в другое приложение, все усложняется. Извлечение данных из базы данных для отправки в API также может быть сложной задачей.
На этом этапе мы можем сделать паузу и напомнить вам, что не стоит слишком пугаться всей этой новой информации. Не стоит ожидать, что вы узнаете все о реализации API с первой попытки. Утешайтесь, зная, что есть люди, которые могут помочь (сообщества с открытым исходным кодом, наемные разработчики и потенциальные участники проекта), и множество ресурсов, доступных в интернете для облегчения обучения.
После того, как вы овладеете основами, у вас появится множество других тем, которые нужно изучить в богатой сфере разработки программного обеспечения. На данный момент, если вам удалось выучить язык программирования и запустить библиотеку, вы должны праздновать. Вы уже порядком продвинулись к тому, чтобы максимально использовать API