Агрегация - GROUP BY, HAVING, DISTINCT
1. Группировка данных GROUP BY
Функция COUNT
Как можно посчитать общее количество альбомов в таблице album? Для этого используется функция агрегации COUNT. То есть с помощью этой функции можно посчитать длину таблицы.
SELECT COUNT(*) FROM album; --Вывод: 121918
Этот запрос считает все строки в таблице, потому что нет условия WHERE.
Так же можно посчитать только те строки, которые удовлетворяют условиям:
SELECT COUNT(*) FROM album WHERE band_id = 93; --Вывод: 11
Для того, чтобы сделать таблицу вывода более читабельной, например, нужно вывести 2 столбца: band_id и количество альбомов у группы с band_id:
SELECT 93 as band_id, COUNT(*) FROM album WHERE band_id = 93; -- 93 as band_id создает новую колонку с названием band_id -- и вводит туда единственное значение 93
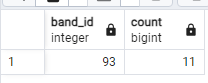
Тоже самое можно сделать для группы с band_id = 192
SELECT 192 as band_id, COUNT(*) FROM album WHERE band_id = 192;
Функция GROUP BY
А что делать, если нам нужно создать единую таблицу, где будут данные band_id и количество альбомов каждой музыкальной группы?
В таких ситуациях используется такая функция, как группировка строк (GROUP BY):
SELECT band_id, COUNT(*) FROM album GROUP BY band_id -- GROUP BY band_id говорит о том, -- что мы хотим группировку по колонке band_id
Это означает, что мы берем строки для каждого конкретного значения, считаем их отдельно, кладем в результат запроса.
Можно сделать по любой другой колонке. Например, по колонке year:
SELECT year, COUNT(*) FROM album GROUP BY year

Если нужна группировка по двум колонкам, когда используется следующий синтаксис:
SELECT band_id, year, COUNT(*) FROM album GROUP BY band_id, year

То есть это мы посчитали альбомы, выпущенные той или иной группой в каком либо году.
2. Фильтрация HAVING
В этой лекции обсудим фильтрацию строк до и после агрегации.
Посчитаем количество строк в таблице album
SELECT COUNT(*) FROM album

Далее выведем альбомы, где band_id 93 и 192:
SELECT * FROM album WHERE band_id IN (93, 192);

Теперь можно посчитать количество альбомов, у которых band_id 93 и 192
SELECT COUNT(*) FROM album WHERE band_id IN (93, 192);

А теперь сделаем группировку по band_id
SELECT band_id, COUNT(*) FROM album WHERE band_id IN (93, 192) GROUP BY band_id;

Так же можно вносить условия в поиск по количеству записей. Например, мы хотим увидеть только те группы, которые выпустили ровно 11 альбомов:
SELECT band_id, COUNT(*) FROM album WHERE band_id IN (93, 192) AND COUNT(*) = 11 GROUP BY band_id;
Но такой запрос вернет ошибку так как сначала выполняются условия после WHERE, а на этот момент значение COUNT(*) еще неизвестно. Поэтому принято, что агрегаторы не разрешены в условии WHERE.
Для таких ситуаций существует специальная функция HAVING:
SELECT band_id, COUNT(*)
FROM album
WHERE band_id IN (93, 192)
GROUP BY band_id
HAVING COUNT(*) = 11;
Работает это по следующему алгоритму: выбираем строки, которые соответствуют условию WHERE --> потом делаем группировку GROUP BY --> потом применяется фильтр HAVING
То есть в данном примере была такая последовательность действий:
- Изначально было 121 918 строк.
- Потом
WHEREотобрал из всех строк нам только 25, гдеband_idбыли равны 93 и 192. - Далее
GROUP BYсформировал из этих 25 строк всего 2 строки. - И
HAVINGотсортировал из двух строк одну!
Более реалистичный пример использования HAVING
Найдем все группы, которые выпустили только один альбом
SELECT band_id, COUNT(*) FROM album GROUP BY band_id HAVING COUNT(*) = 1;

3. Агрегация SUM и COUNT
Функция SUM
SUM - суммирование значений в числовой колонке.
Таблица band_extended содержит список музыкальных групп, количество их альбомов и количество песен.
Посчитаем количество музыкальных групп и количество записанных ими музыкальных альбомов.
SELECT COUNT(*), SUM(n_albums) FROM band_extended;

Дополнительно о функции COUNT
Если записать COUNT(*) - это подсчет количества строк. Если вместо звездочки написать конкретную колонку (например, COUNT(n_albums)) - функция COUNT посчитает количество строк, где эта колонка принимает значения, отличные от значения NULL.
Если к этой таблице применить код, написанный ниже:

SELECT
COUNT(*) as count1,
COUNT(n_albums) as count2,
SUM(n_albums)
FROM band_extended;
4. Другие функции агрегации
Список функций
COUNT(*) - подсчет количества строк.
COUNT(название_колонки) - количество строк, где значения колонки отличны от NULL
SUM(название_колонки) - суммирование значений колонки.
MIN(название_колонки) - поиск минимального значения.
SELECT MIN(year) FROM album; -- Вывод 201

МАХ(название_колонки) - поиск максимального значения.
SELECT MAX(year) FROM album; -- Вывод 2997

AVG(название_колонки) - среднее значение.
SELECT AVG(year) FROM album; -- Вывод 2000.0524160929787199
COUNT(DISTINCT название_колонки) - для подсчета количества различных значения в колонке.
SELECT COUNT(DISTINCT year) FROM album -- Вывод 79
Использование позиционных ссылок
В выражениях GROUP BY можно использовать не только название колонок, но и просто номера колонок в списке SELECT.
SELECT band_id, year, COUNT(*) FROM album GROUP BY band_id, year
SELECT band_id, year, COUNT(*) FROM album GROUP BY 1, 2
Это означает, что мы группируем по первой и второй колонке в списке SELECT.
ВАЖНО! Первая и вторая колонка не в исходной таблице, а в списке SELECT
Примеры использования методов агрегации
1. С помощью MIN и MAX можно проверять качество данных.
SELECT MIN(year), MAX(YEAR) FROM album

2. Проверяем минимальное и максимальное количество альбомов, записанных одной группой.
SELECT MIN(counter), MAX(counter)
FROM (
SELECT band_id, COUNT(*) as counter
FROM album GROUP BY 1)
as table_1
3. Проверяем уникальность значений в таблице:
SELECT COUNT(*), COUNT(DISTINCT band_id) FROM band -- создаем таблицу из двух колонок, в одной колонке -- количество строк COUNT(*) - 82928 -- а в другой - количество уникальных значений COUNT(DISTINCT band_id)

А теперь сделаем тоже самое для таблицы album
SELECT COUNT(*),
COUNT(DISTINCT album_id),
COUNT(DISTINCT band_id)
FROM album
Какие выводы можно сделать, глядя на эту таблицу?
- Длина таблицы совпадает с уникальными значениями album_id. Значит, заполнено без ошибок.
- Если сравнивать COUNT(DISTINCT band_id) в этом запросе с предыдущим запросом, можно сделать вывод, что у некоторых групп нет ни одного альбома.
Можем это проверить, введя такой запрос:
SELECT *
FROM band
WHERE band_id NOT IN (
SELECT band_id
FROM album
WHERE band_id IS NOT NULL)
Вот так получили список всех групп, которые не выпустили ни одного альбома.
5. Различные значения DISTINCT
SELECT COUNT(DISTINCT year) FROM album -- Выводит уникальные значения для таблицы album

Так же DISTINCT можно использовать отдельно от COUNT для того, чтобы вывести не количество уникальных значений, а сами уникальные значения:
SELECT DISTINCT year FROM album;

Так же можно SELECT DISTINCT указать и для нескольких колонок. Допустим, хотим найти различные пары колонок band_id и year
SELECT DISTINCT band_id, year FROM album

А чтобы найти количество уникальных значений для пары колонок, нужен такой запрос:
SELECT COUNT(*)
FROM (
SELECT DISTINCT band_id, year
FROM album
) as t
6. Сортировка данных ORDER BY
Если писать просто SELECT * FROM - строки могут вернуться в любом порядке.
Если нужно упорядочить данные, тогда нужно это указать: ORDER BY <колонка для упорядочивания> DESC, <колонка для упорядочивания>.
SELECT album_id, name, band_id, year FROM album ORDER BY year DESC, band_id -- в этом примере сортируем сначала по колонке year, а потом по band_id -- DESC - это сортировка по убыванию -- если DESC не указан, тогда идет сортировка по возрастанию

DESC - сортировка по убыванию.
Так же запрос выше можно заменить на аналогичный запрос, заменив название колонок на их номера по порядку после SELECT
SELECT album_id, name, band_id, year FROM album ORDER BY 4 DESC, 3

Загвоздка со значениями NULL при сортировке
Особо скажем про значение NULL
Когда мы делаем сортировку строк, мы сравниваем значения (какое больше, какое меньше). Однако для NULL непонятно, больше или меньше они других значений. Поэтому тут есть свой синтаксис. Можно с помощью команды NULLS FIRST указать, что значения NULL идут перед другими значениями. Либо указать с помощью команды NULLS LAST указать, что значения NULL идут после других значений.
SELECT album_id, name FROM album ORDER BY 1 NULLS FIRST SELECT album_id, name FROM album ORDER BY 1 NULLS LAST
Если NULLS FIRST или NULLS LAST не указаны, тогда значения NULL идут после других значений.
Все элементы SELECT в одном запросе
SELECT year, COUNT(*)
FROM album
WHERE band_id > 0
GROUP BY year
HAVING COUNT(*) >= 2
ORDER BY 1
