Групповые статистики с Python
Рассмотрим наиболее распространенные кейсы получения групповых статистик с помощью библиотеки Pandas. Разбирать вопрос будем на примере статистики о боях по смешанным единоборствам в рамках американской лиги UFC. (выберем данные только для заданных бойцов):
import pandas as pd
ufc_stat = pd.read_csv('ufc/ufc_datalens.csv')
f_l = ['Conor McGregor', 'Max Holloway', 'Dustin Poirier', 'Alexander Volkanovski', 'Fabricio Werdum', 'Cain Velasquez', 'Khabib Nurmagomedov']
ufc_stat = ufc_stat[ufc_stat.Fighter.isin(f_l)]Вывод одной агрегации по некоторому столбцу
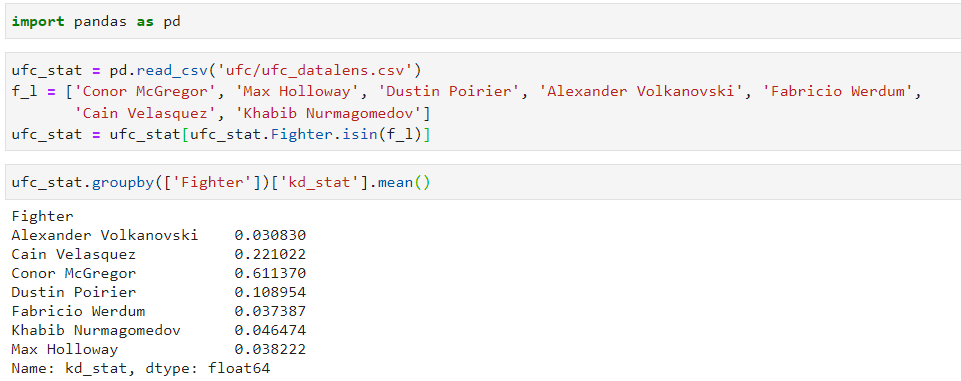
Операции группировки по некоторым колонкам проводятся с помощью метода groupby. Так, выводится среднее по количеству нокаутов в минуту (колонка kd_stat) для выбранных бойцов:
ufc_stat.groupby(['Fighter'])['kd_stat'].mean()
Вывод нескольких агрегаций по столбцам
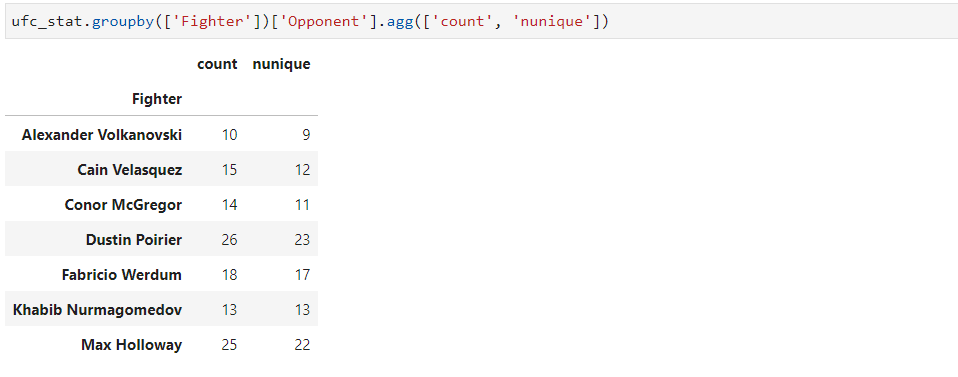
Для этих целей можно воспользоваться методом agg (или синонимом - aggregate), передав ему список функций. Выведем для бойцов общее число и количество разных оппонентов:
ufc_stat.groupby(['Fighter'])['Opponent'].agg(['count', 'nunique'])
Вывод выборочных агрегаций для выборочных столбцов
Реализуется посредством передачи методу agg словаря с указанием столбцов (ключи) и соответствующих каждому агрегаций (значения):
ufc_stat.groupby(['Fighter'])[['kd_stat', 'sub_att_stat', 'sig_str_stat', 'ctrl_stat']].agg(
{'kd_stat':['mean', 'max'], 'sub_att_stat':'mean', 'sig_str_stat':'min'})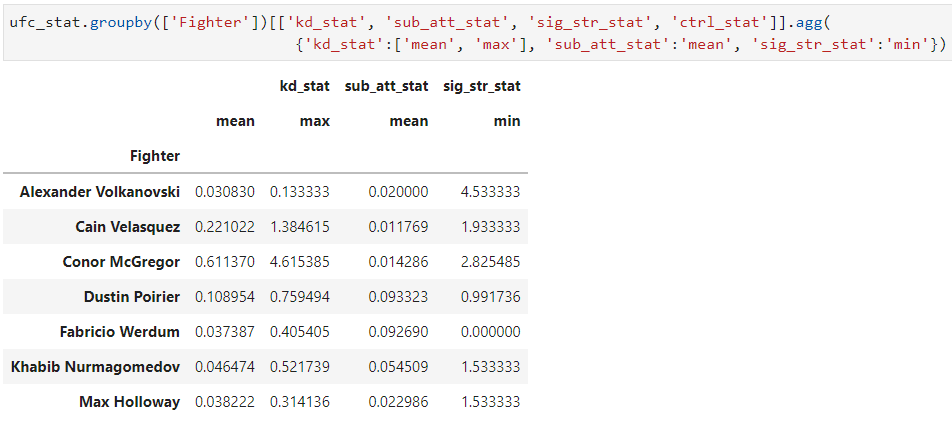
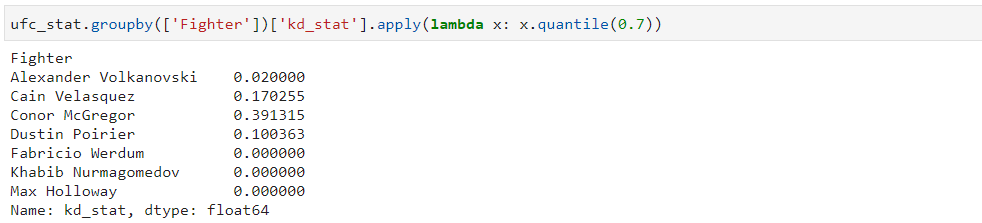
Задание кастомной функции агрегации
Осуществляется с помощью метода apply:
ufc_stat.groupby(['Fighter'])['kd_stat'].apply(lambda x: x.quantile(0.7))
Группировка по нескольким колонкам
Если группировка задается по нескольким колонкам (указываются списком в groupby), то агрегация работает аналогичным образом:
ufc_stat[ufc_stat.Fighter.isin(['Conor McGregor', 'Khabib Nurmagomedov'])].groupby(['Fighter','Opponent'])\
[['sig_str_stat', 'sub_att_stat']].agg(['mean', 'max'])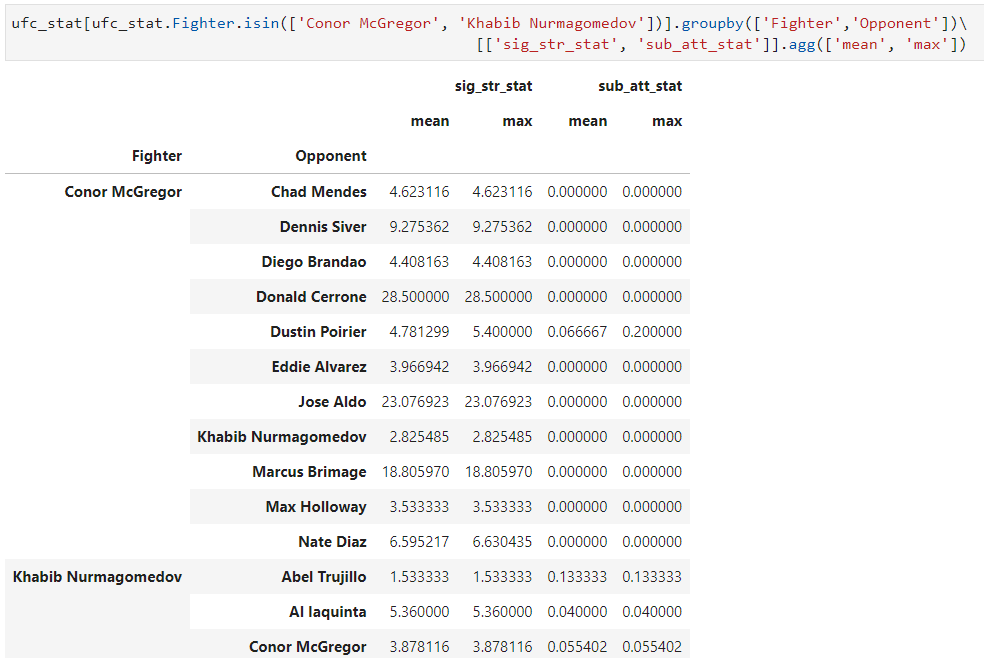
Не пропустите ничего интересного и подписывайтесь на страницы канала в других социальных сетях: