Ищем значения скрытых свойств по советам соседей

Как узнать неизвестную стоимость квартиры или спрогнозировать расход электроэнергии в населенном пункте? Использовать модель машинного обучения скажете вы.. Но зачастую ваша крутая модель не сработает на части примеров ввиду отсутствия достаточного количества признаков для них.
Конечно можно построить еще одну, но целесообразно ли это? Не лучше пойти другим путем и распространить влияние текущей модели на новые объекты, используя признаки их сходства с соседями.
Напишем класс KnnNeighbors, который делает это, под капотом проводя кодирование категориальных признаков и стандартизацию числовых и используя класс NearestNeighbors из пакета scikit-learn для поиска ближайших точек. Принцип его применения следующий - сначала он настраивается на признаках общих для точек, с которыми основная модель справляется и "проблемных". Затем вычисляется метрика по основной модели и впоследствии распространяется на "проблемные точки", используя класс KnnNeighbors.
Полный код класса представлен ниже:
import pandas as pd
from sklearn.neighbors import NearestNeighbors
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
import numpy as np
class KnnNeighbors():
def __init__(self, obj_id_name, cat_col_l, dig_col_l, k=5):
self.k = k
self.obj_id_name = obj_id_name
self.cat_col_l = cat_col_l
self.dig_col_l = dig_col_l
self.sc = StandardScaler()
self.enc = OneHotEncoder(sparse=False)
self.knn = NearestNeighbors(n_neighbors=self.k)
def fit(self, X):
self.X = X
self.sc.fit(X[self.dig_col_l])
self.enc.fit(X[self.cat_col_l])
self.X_tr = self.transform(X)
self.knn.fit(self.X_tr)
def transform(self, X):
dig_feat = pd.DataFrame(self.sc.transform(X[self.dig_col_l]),columns=self.dig_col_l)
cat_feat = pd.DataFrame(self.enc.transform(X[self.cat_col_l]),
columns=self.enc.get_feature_names(self.cat_col_l))
return dig_feat.join(cat_feat)
def kneighbors(self, X):
X_tr = self.transform(X)
return self.knn.kneighbors(X_tr)
def k_objs_near(self, objs_df, objs_search):
dists, inds = self.kneighbors(objs_search)
return dists, pd.DataFrame(inds).applymap(lambda x: objs_df.iloc[x][self.obj_id_name])
def approximate_metrics(self, known_metrics_df, evaluate_df):
evaluate_df_metrics = evaluate_df.copy()
_, vsp_near = self.k_objs_near(known_metrics_df, evaluate_df)
evaluate_df_metrics['metrics'] = vsp_near.apply(lambda x: known_metrics_df.loc[
known_metrics_df[self.obj_id_name].isin(x),'metrics'].mean(), axis=1)
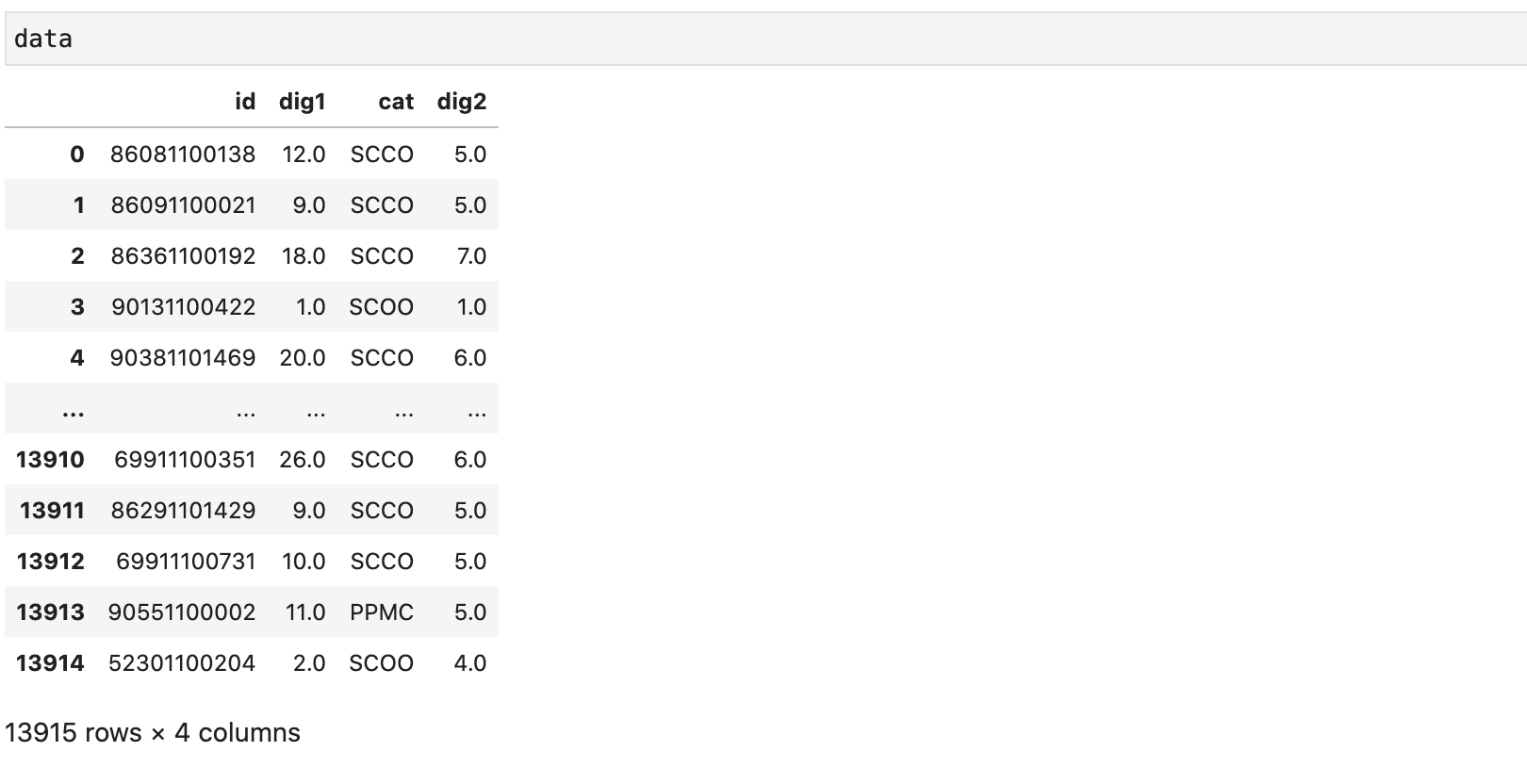
return evaluate_df_metricsДанные, с которыми будем работать для демонстрации имеют следующий вид:
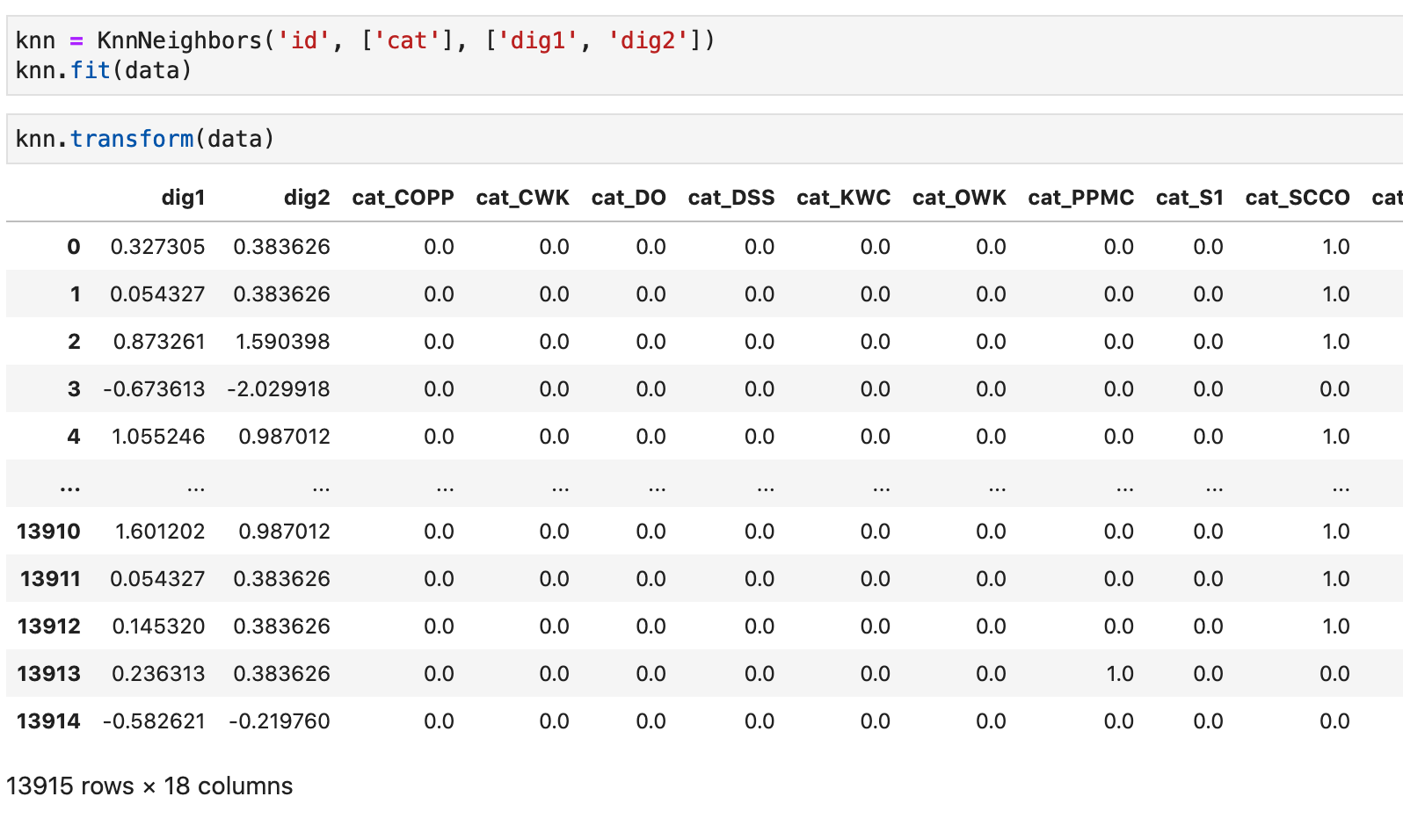
Теперь разберем методы по порядку. Конструктору задаем названия столбцов с идентификатором объектов и категориальными и числовыми признаками. Методы fit и transform отвечают за настройку и преобразование данных (ранее писал, как и почему необходимо преобразовывать категориальные и числовые признаки):
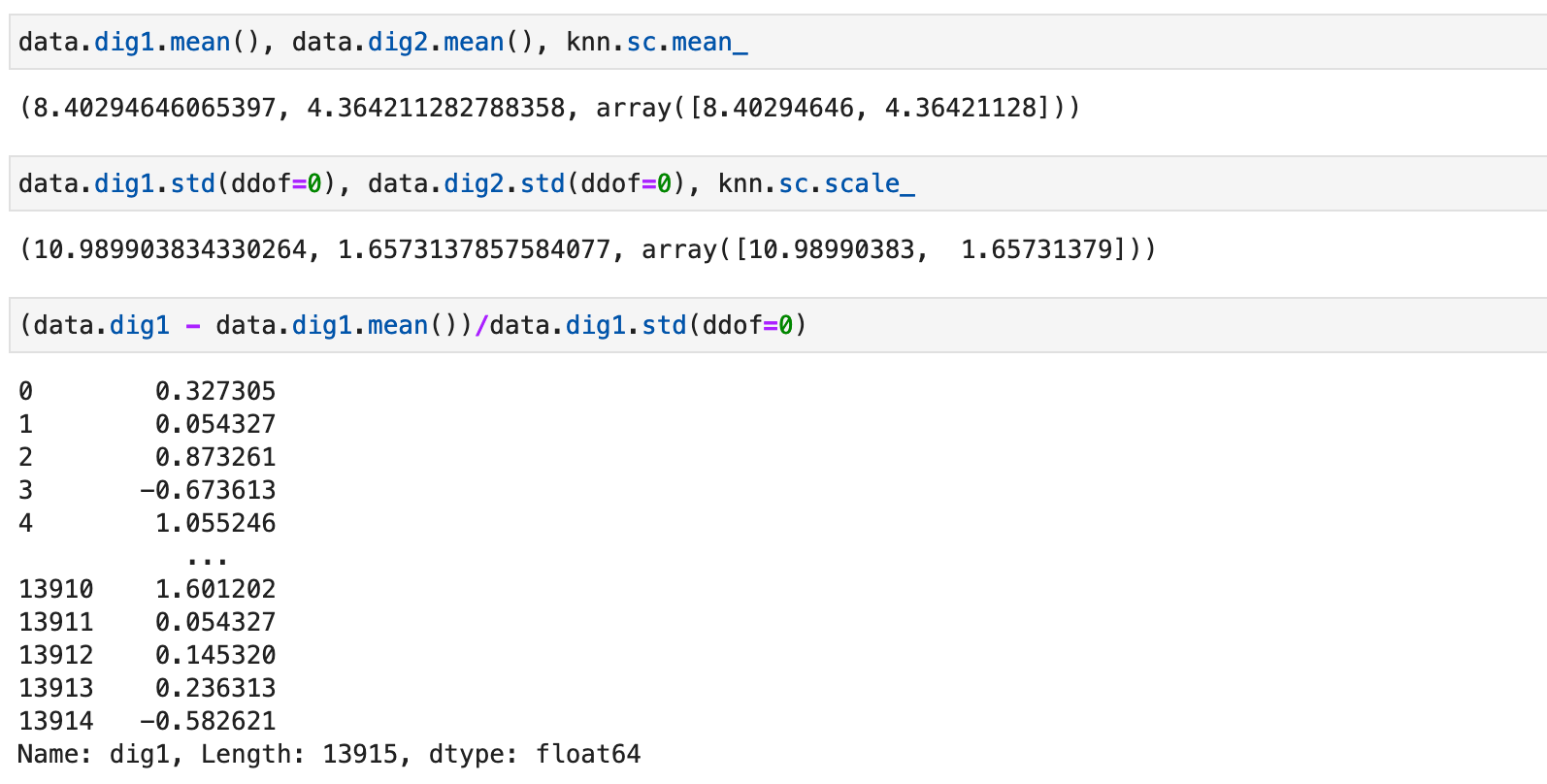
Убедимся в корректности стандартизации, сравнив внутреннее состояние объекта StandardScaler класса (имя sc) и выполнив ручную стандартизацию:
Аналогично убедимся в корректности настройки энкодера (enc) путем вывода всех категорий данных и просмотра атрибутов, а также вывода значения для произвольной категории (сравните выводы для записи с индексом 13910):
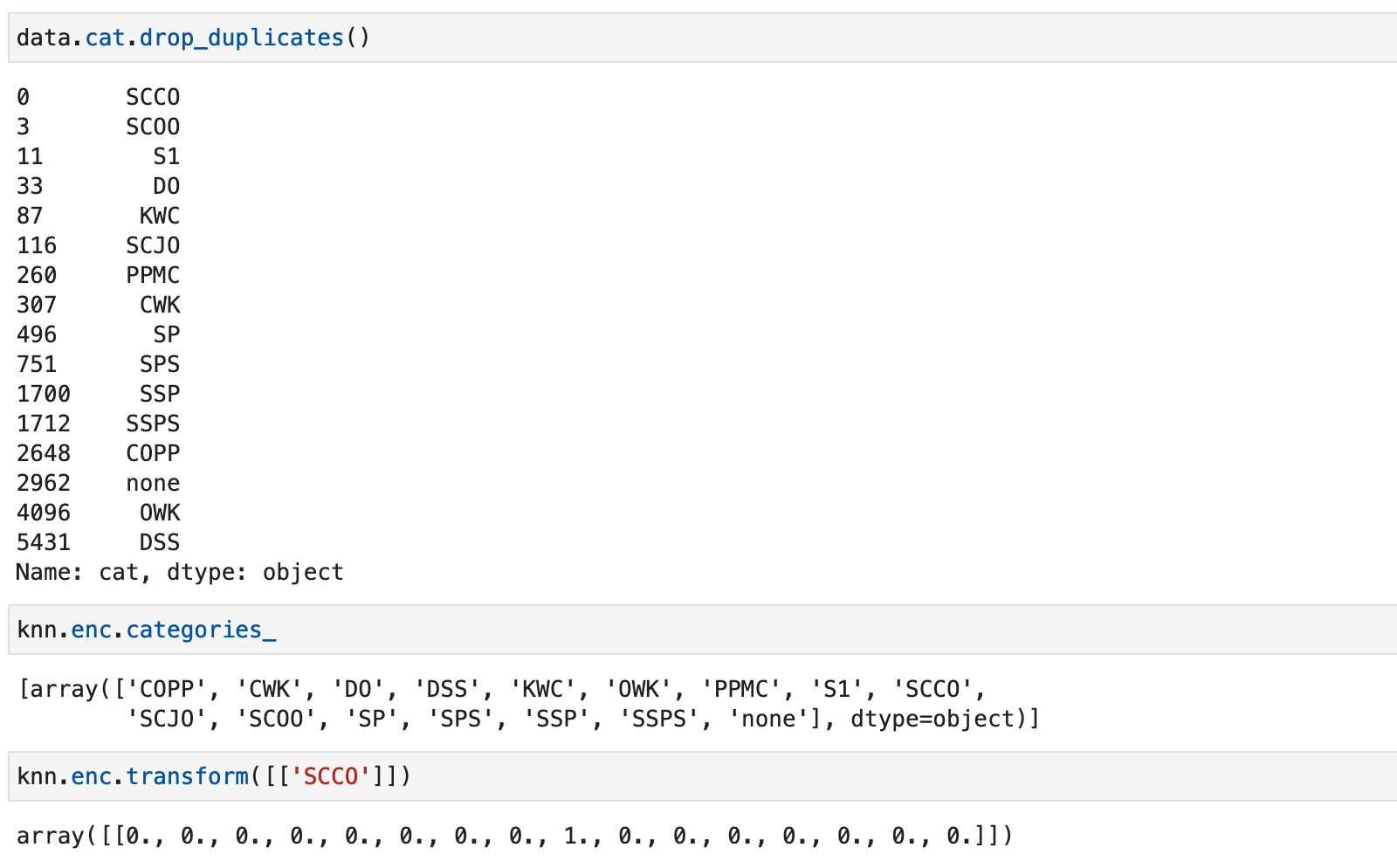
Зададим новые записи и выведем их соседей, используя метод kneighbours (ранее подробно писал об этом):
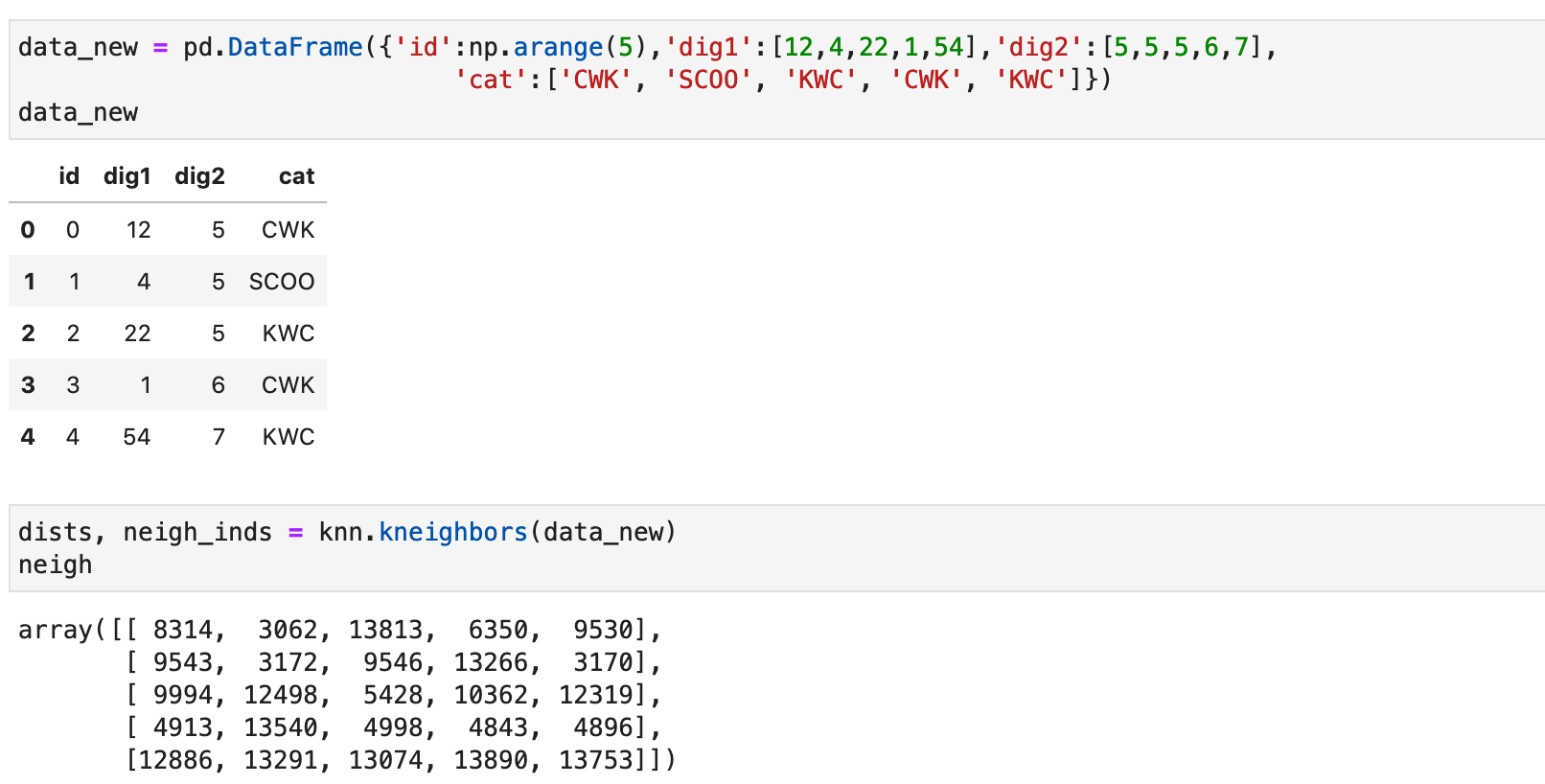
Проверим, что свойства соседей действительно похожи на заданный объект под номером 4:
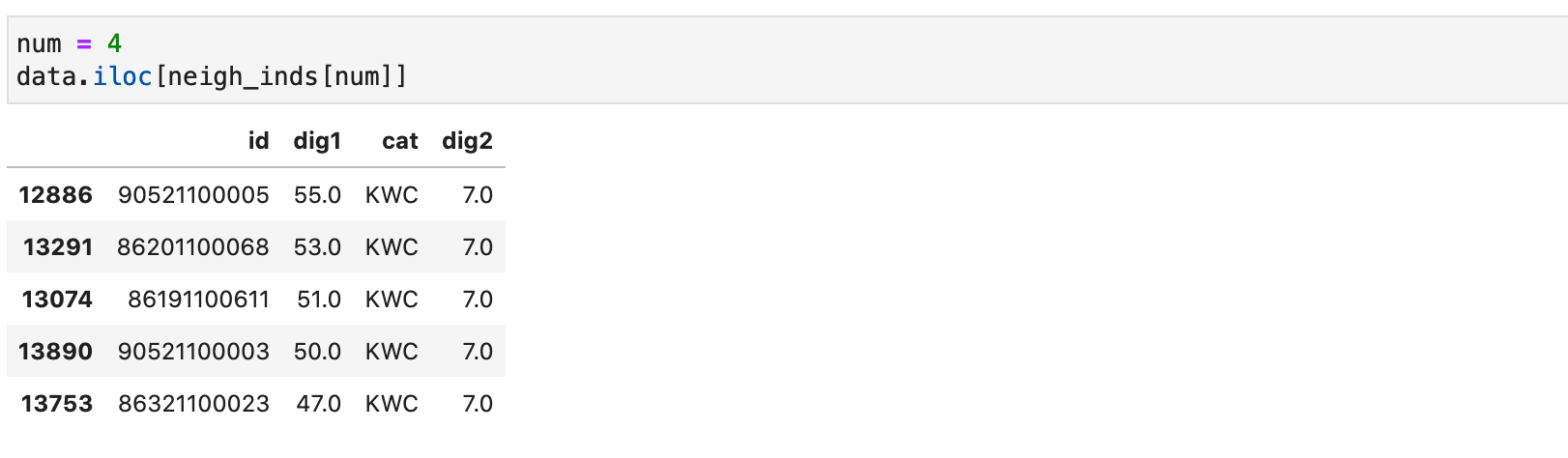
Метод нашего класса k_objs_near делает аналогичную работу, но выводит не индексы похожих соседей, а их id-шники:
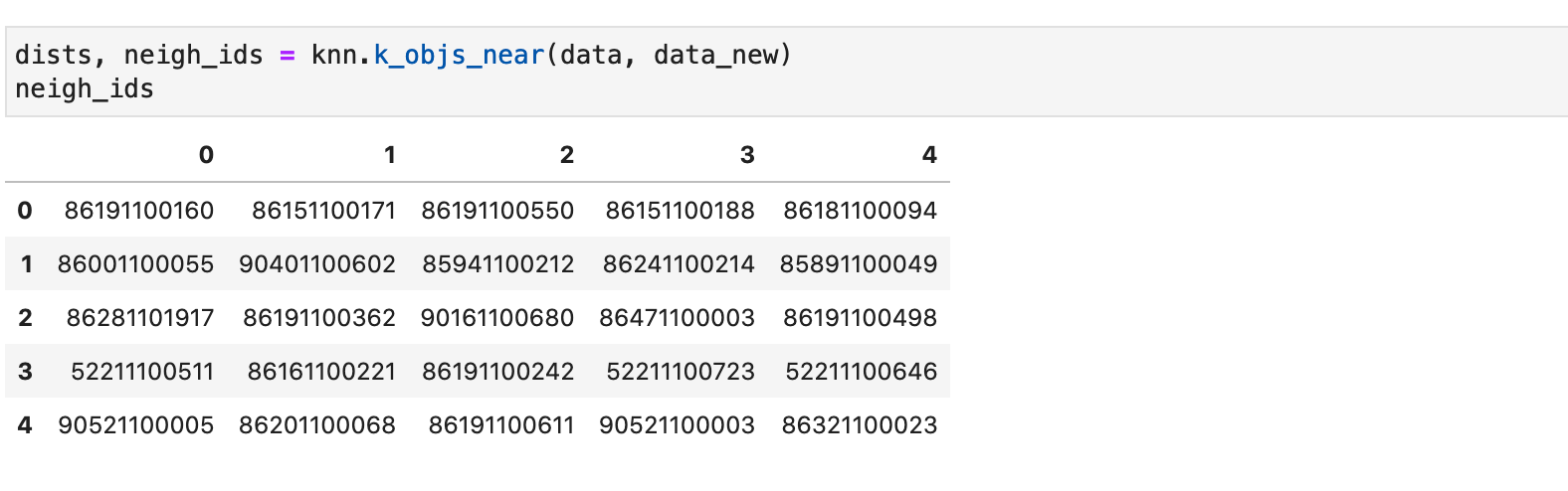
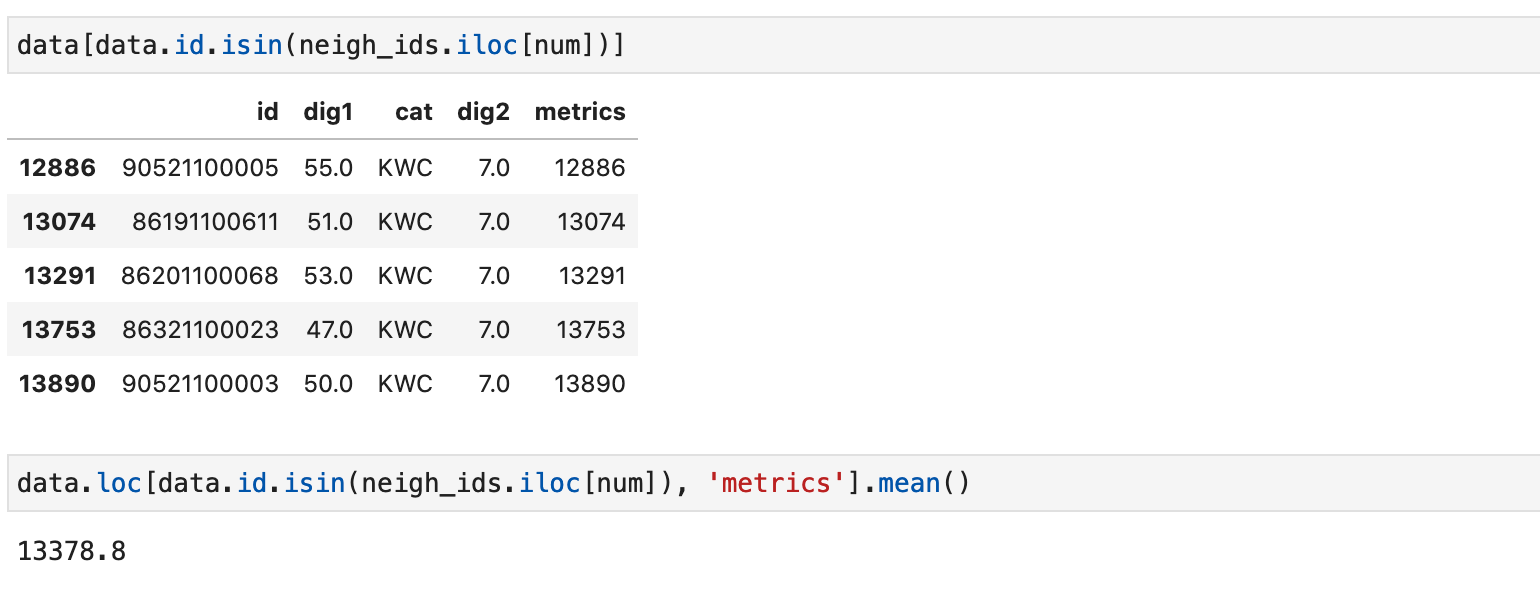
Теперь заполним данные метрикой и распространим ее на новые значение (среднее по всем соседям):
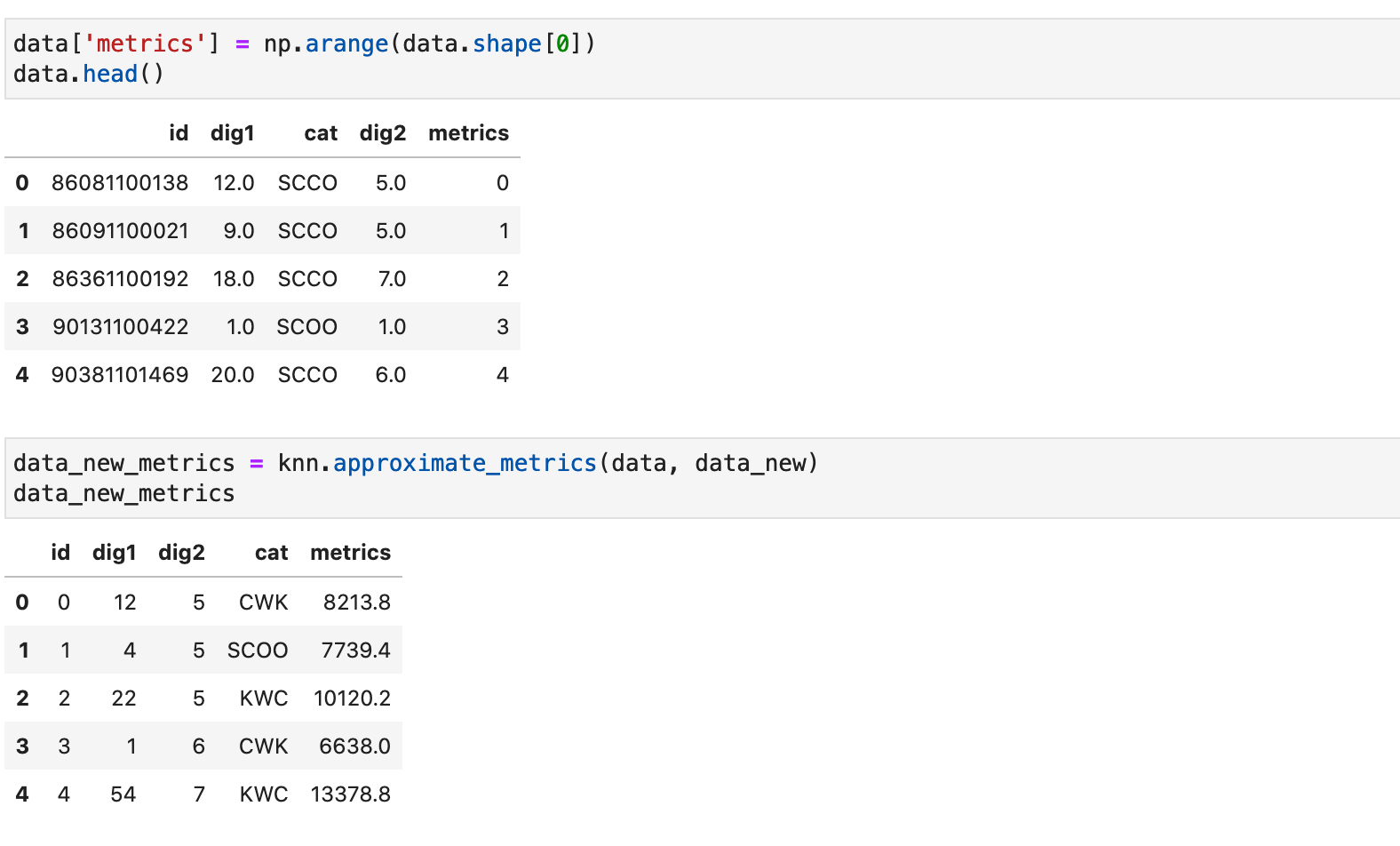
Вычислим вручную метрику для произвольного объекта (4) вручную и сравним с полученным значением: