Эффективная модификация значений датафрейма, чтобы избежать капризов Pandas

В этой статье рассмотрим ключевые походы к изменению значений в ячейках датафрейма Pandas - наиболее популярного формата первичной обработки данных для любителей Python. Оценку способов будем производить исходя из их результативности, скорости и трудозатратности.
Рассмотрим вопрос на примере конкретной задачи. Пусть имеется датафрейм, содержащий предсказания для пары object, item (например, размер поставки в филиал организации/object определенного материала/item) следующего вида:
import pandas as pd
import numpy as np
np.random.seed(0)
# предсказания количества item-ов для объектов
items = ['item1','item2','item3','item4','item5']
all_df = pd.MultiIndex.from_product([np.arange(5), items]).to_frame()\
.reset_index(drop=True).rename(columns={0:'objs', 1:'items'})
preds_df = pd.concat([all_df.sample(10).reset_index(drop=True),
pd.Series(np.random.randint(100, size=10), name='preds')], axis=1)
preds_df.sort_values(by='objs')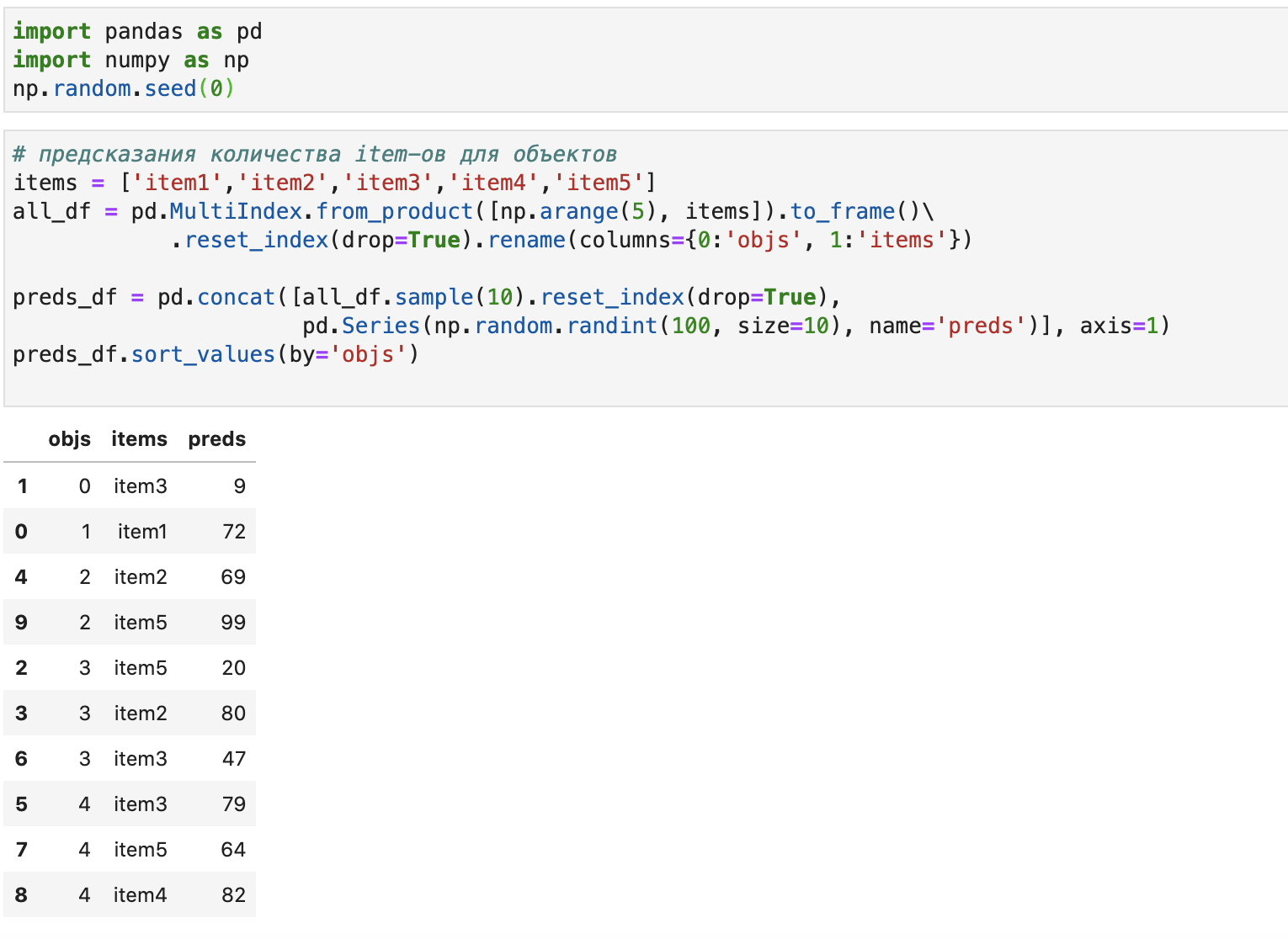
Для генерации набора сначала с помощью функции from_product объекта MultiIndex получили декартово произведение item-ов и объектов, а потом выбрали из них 10 случайных с помощью метода sample объекта DataFrame. Нашей задачей является замена item-ов в датафрейме предсказаний при условии, что он отсутствует в некотором перечне возможных item-ов для каждого объекта (задаем в obj_items_df, допустим, в филиале организации уже не используются гелевые ручки, а только шариковые). При этом правила замены одного item-а на другой (задаются в словаре maps_d):
obj_items_df = preds_df.copy()[['objs', 'items']]
obj_items_df.drop([4,9], inplace=True)
obj_items_df.sort_values(by='objs')
# словарь замены
maps_d = {'item1':'item2', 'item2':'item1', 'item3':'item5', 'item5':'item3'}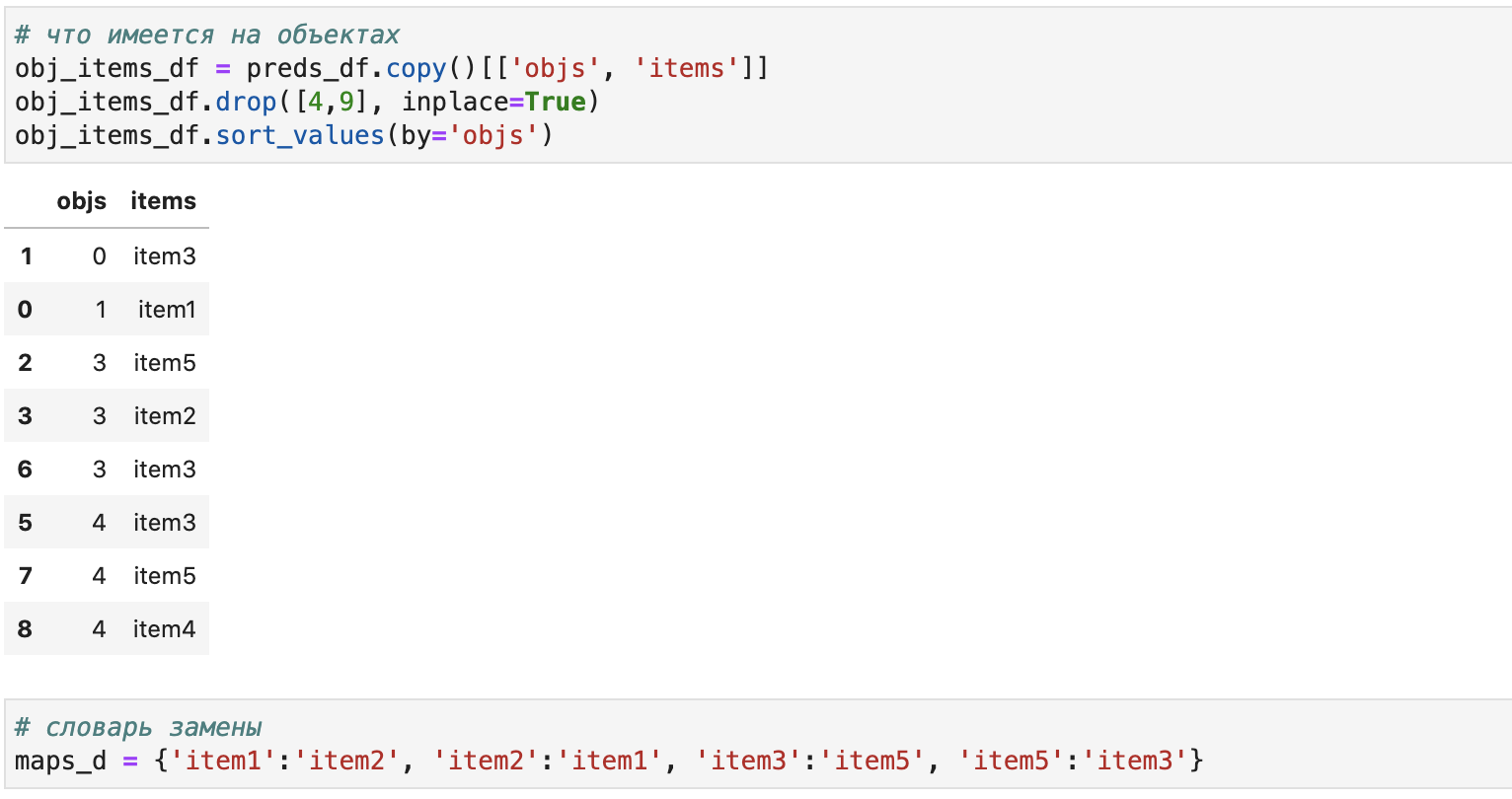
Как видно, в демонстрационных целях мы сформировали obj_items_df из значений самих предсказаний за вычетом двух строк (они и будут заменены).
Рассмотрим теперь несколько подходов для решения задачи:
- Задаем цикл по матрице предсказаний и в строках, где пара объект, item не попадает в список пар из obj_items_df осуществляем замену.
- То же, но сравнение присутствия объект, item происходит методом прихотливой индексации на уровне датафреймов.
- Оба датафрейма индексируются парами объект, item и операции наличия значений осуществляются на уровне индексов.
Преимуществом первых двух подходов является простота реализации:
pairs = obj_items_df.apply(lambda x:tuple(x), axis=1).to_list()
match1_df = preds_df.copy()
for i, row in enumerate(match1_df.itertuples()):
if not (row.objs, row.items) in pairs:
match1_df.at[row.Index, 'items_new'] = maps_d[row.items]
else:
match1_df.at[row.Index, 'items_new'] = row.items
match1_df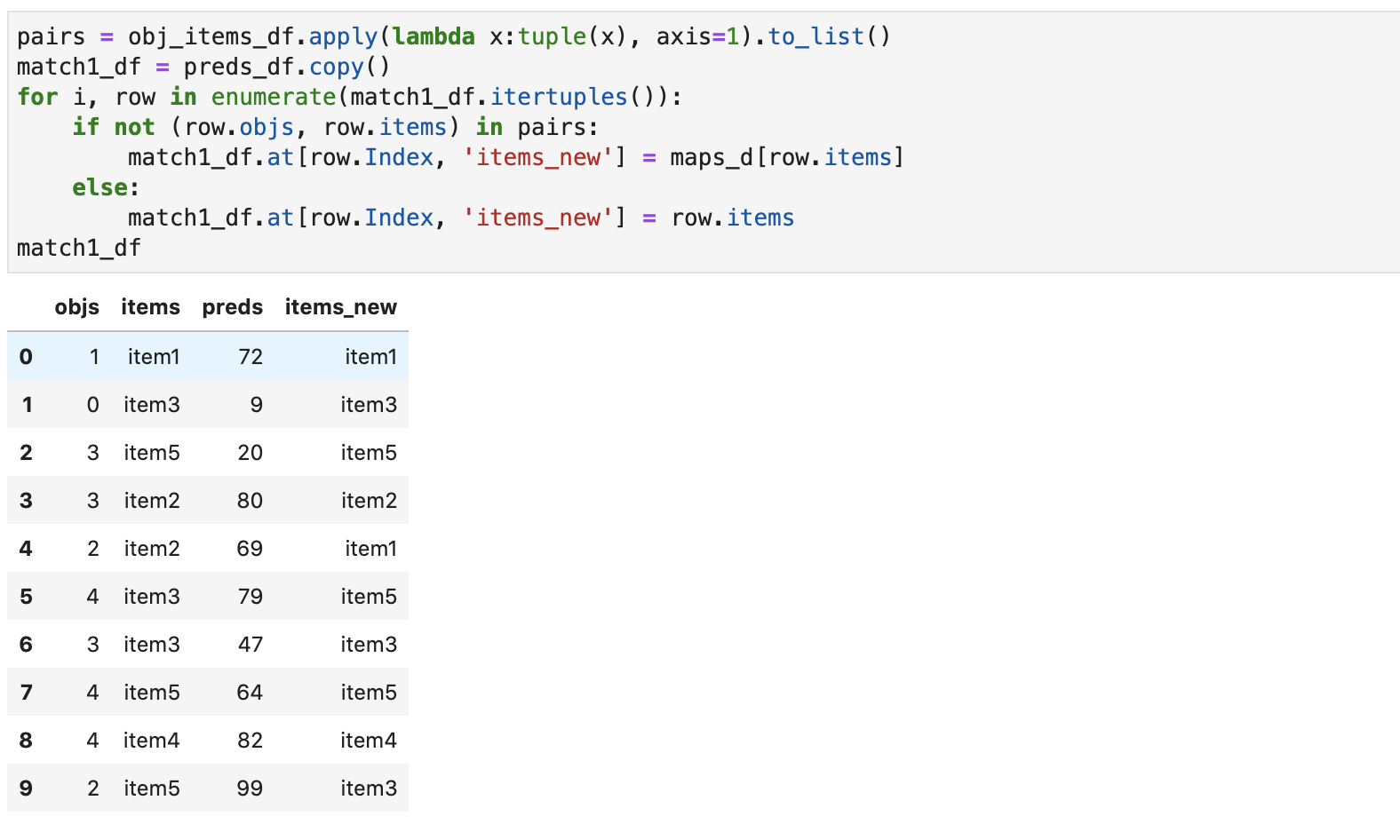
Видим, что строки, где objs ==2 имеют item_new отличающийся от item в соответствии с нашим правилом. Обратите внимание, что при попытке внесения изменений путем выбора сначала строки i, а потом столбца item_new Pandas вернет предупреждение и не даст внести изменения:
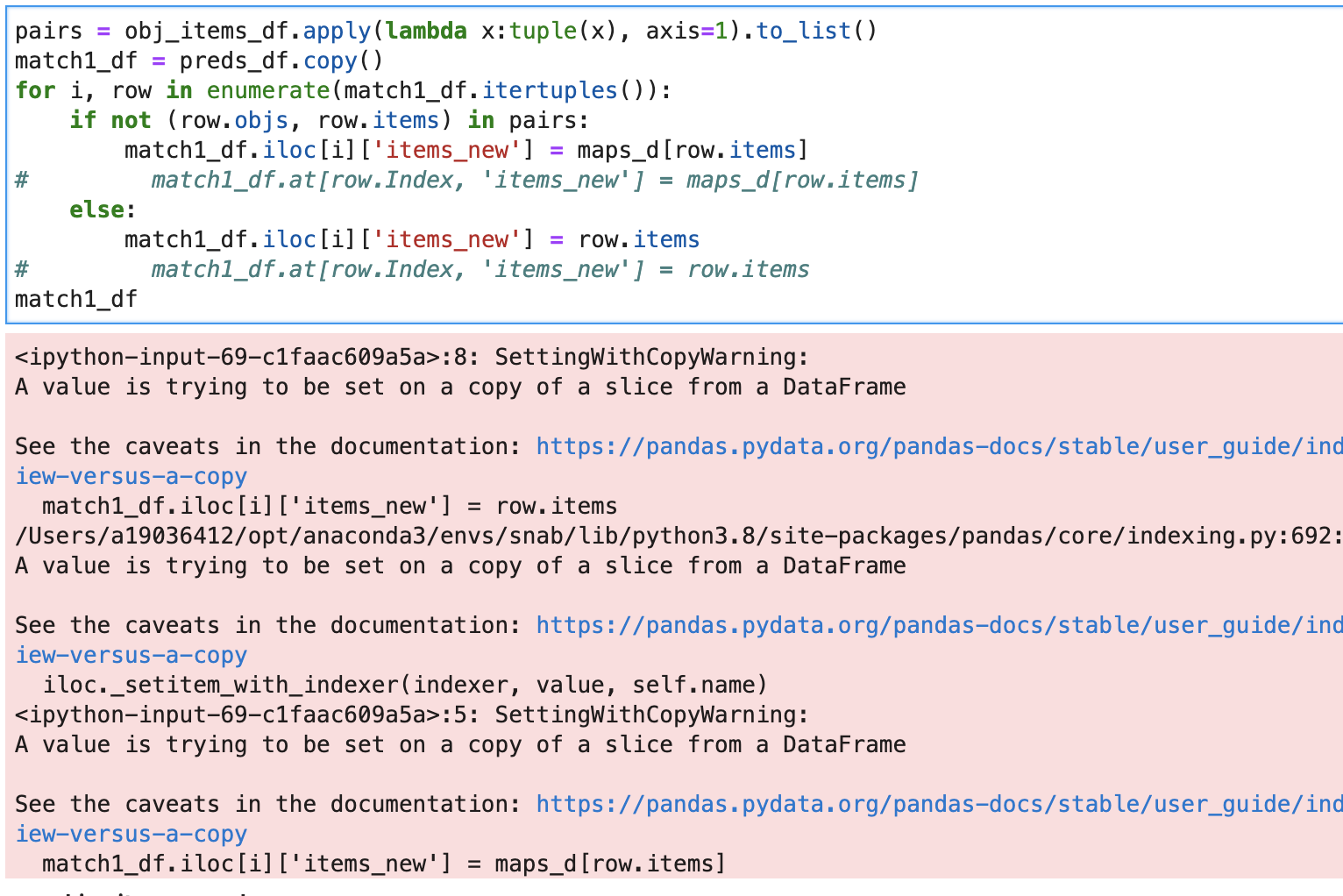

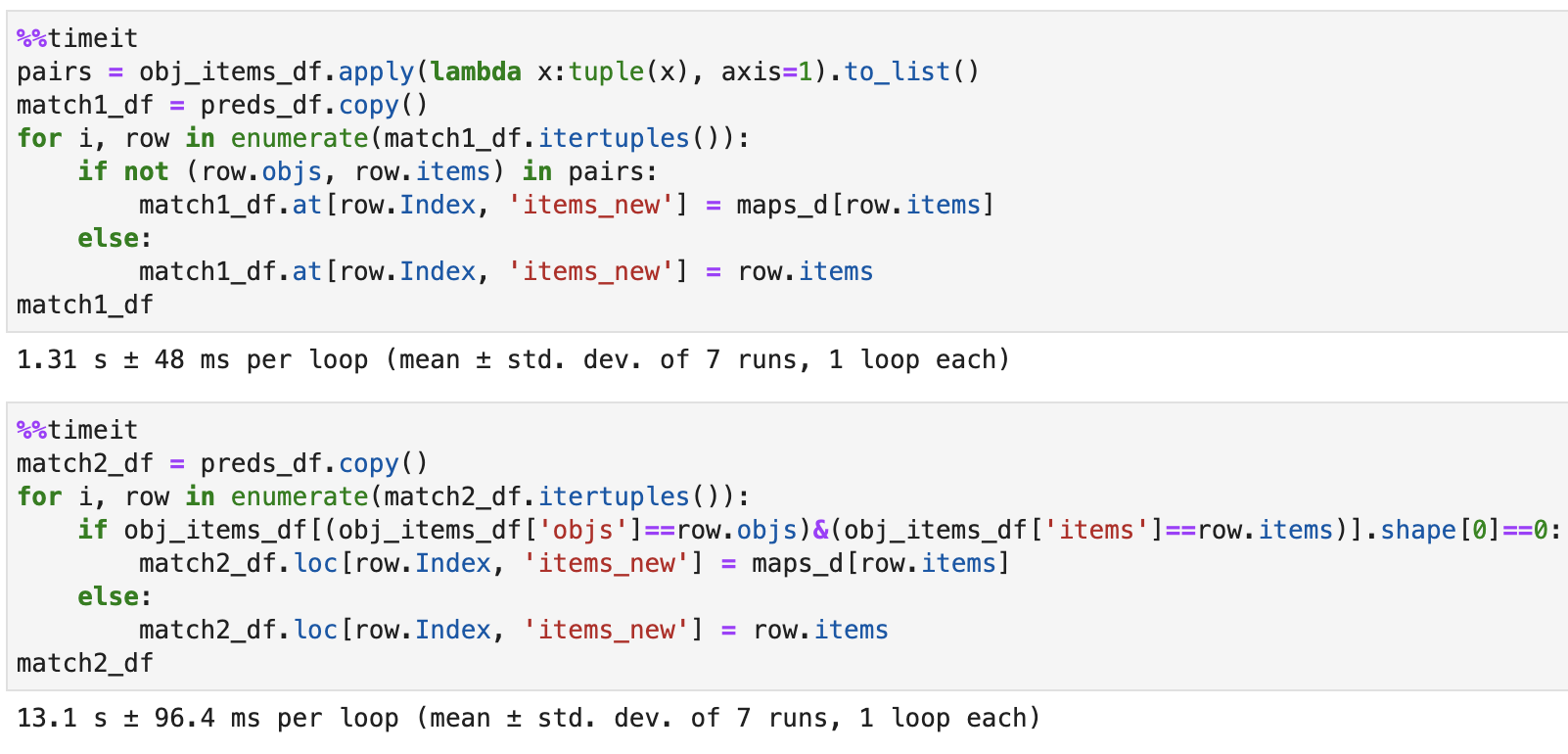
Теперь проверим скорость метода:
%%timeit
pairs = obj_items_df.apply(lambda x:tuple(x), axis=1).to_list()
match1_df = preds_df.copy()
for i, row in enumerate(match1_df.itertuples()):
if not (row.objs, row.items) in pairs:
match1_df.at[row.Index, 'items_new'] = maps_d[row.items]
else:
match1_df.at[row.Index, 'items_new'] = row.items
match1_df
Второй метод также выдает правильный результат:
# %%timeit
match2_df = preds_df.copy()
for i, row in enumerate(match2_df.itertuples()):
if obj_items_df[(obj_items_df['objs']==row.objs)&(obj_items_df['items']==row.items)].shape[0]==0:
match2_df.loc[row.Index, 'items_new'] = maps_d[row.items]
else:
match2_df.loc[row.Index, 'items_new'] = row.items
match2_df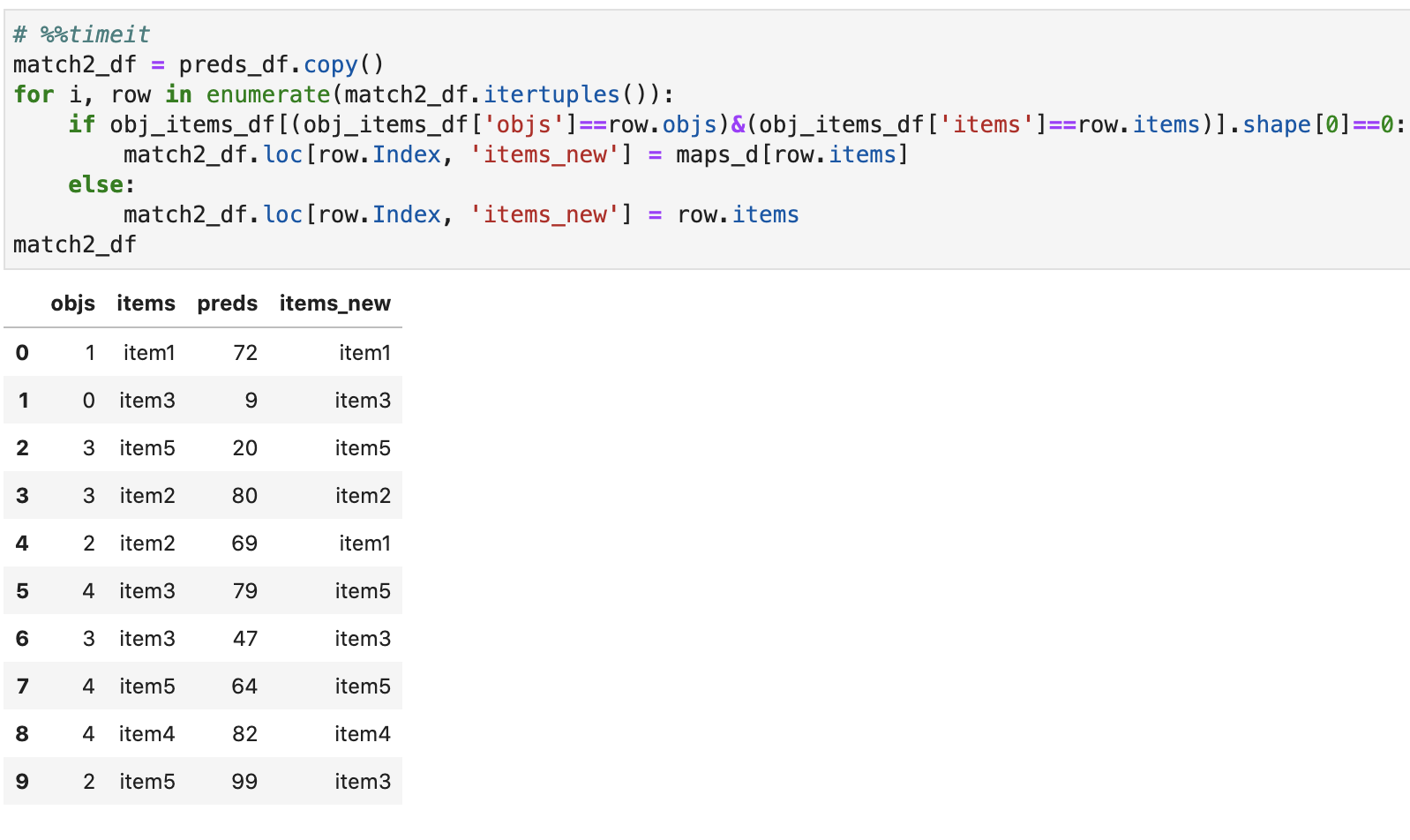
но работает значительно медленнее:

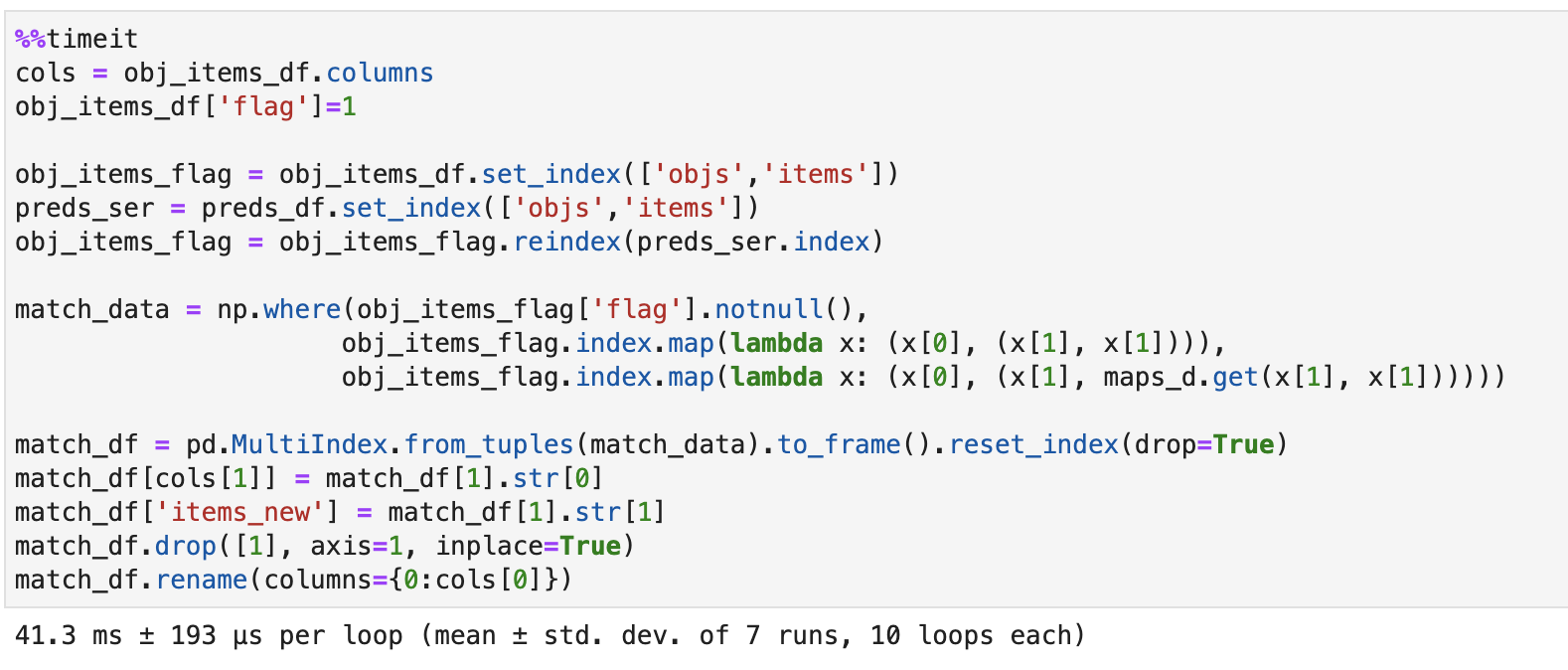
А теперь перейдем к третьему способу. Он немного сложнее предыдущих, так как требует работы на уровне индексов. На основе обоих датафреймов (preds_df, obj_items_df) создаются структуры с индексами из пар объект, item (preds_ser, obj_items_flag), затем вызывается переиндексация obj_items_flag и flag для новых значений становится равным null, что инициирует правило замены. Код представлен ниже:
# %%timeit
cols = obj_items_df.columns
obj_items_df['flag']=0
obj_items_flag = obj_items_df.set_index(['objs','items'])
preds_ser = preds_df.set_index(['objs','items'])
obj_items_flag = obj_items_flag.reindex(preds_ser.index)
match_data = np.where(obj_items_flag['flag'].notnull(), obj_items_flag.index.map(lambda x: (x[0], (x[1], x[1]))),
obj_items_flag.index.map(lambda x: (x[0], (x[1], maps_d.get(x[1], x[1])))))
match_df = pd.MultiIndex.from_tuples(match_data).to_frame().reset_index(drop=True)
match_df[cols[1]] = match_df[1].str[0]
match_df['items_new'] = match_df[1].str[1]
match_df.drop([1], axis=1, inplace=True)
match_df.rename(columns={0:cols[0]})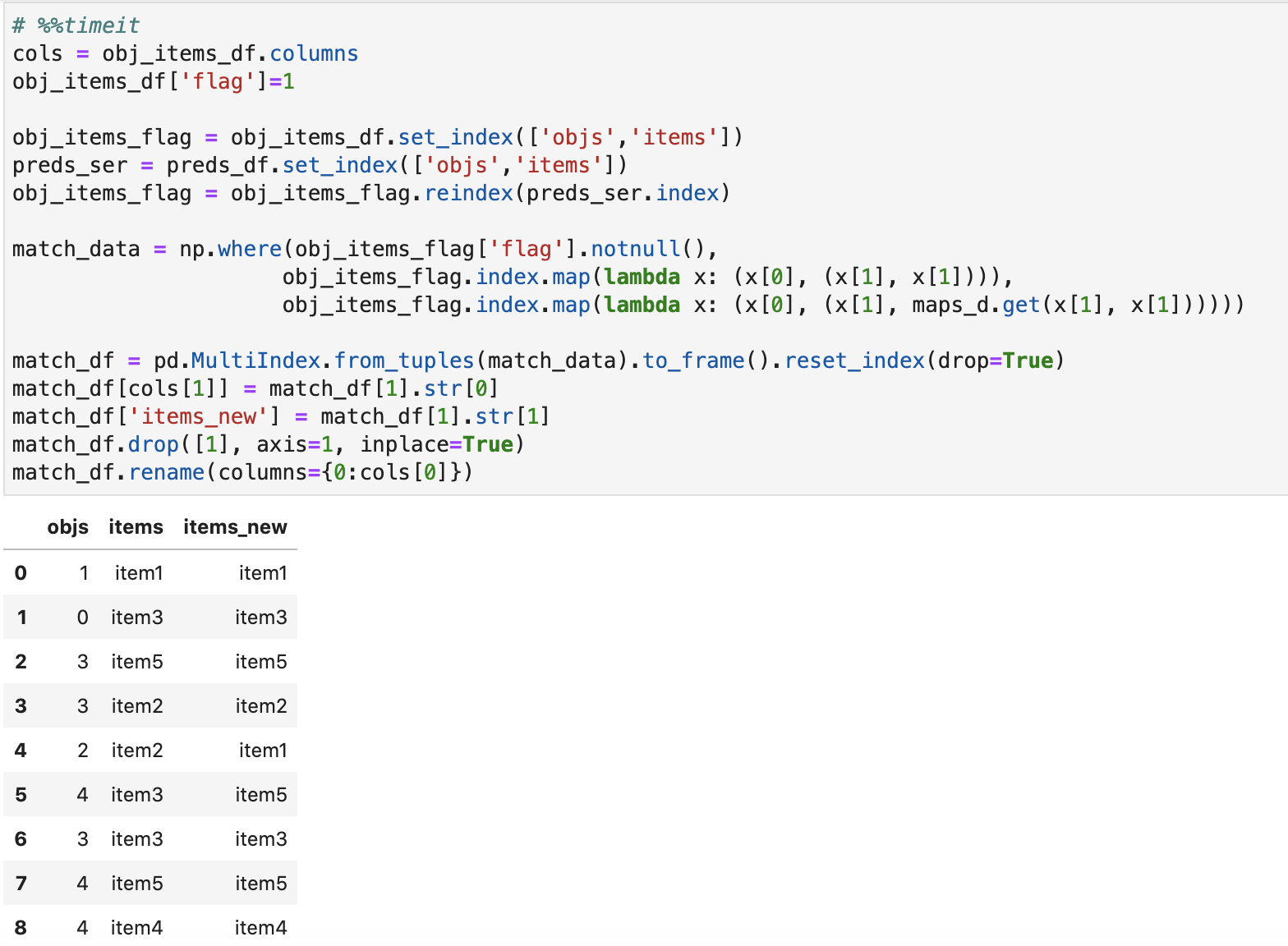
На заданных данных несмотря на трудоемкость время метода не очень впечатляет:
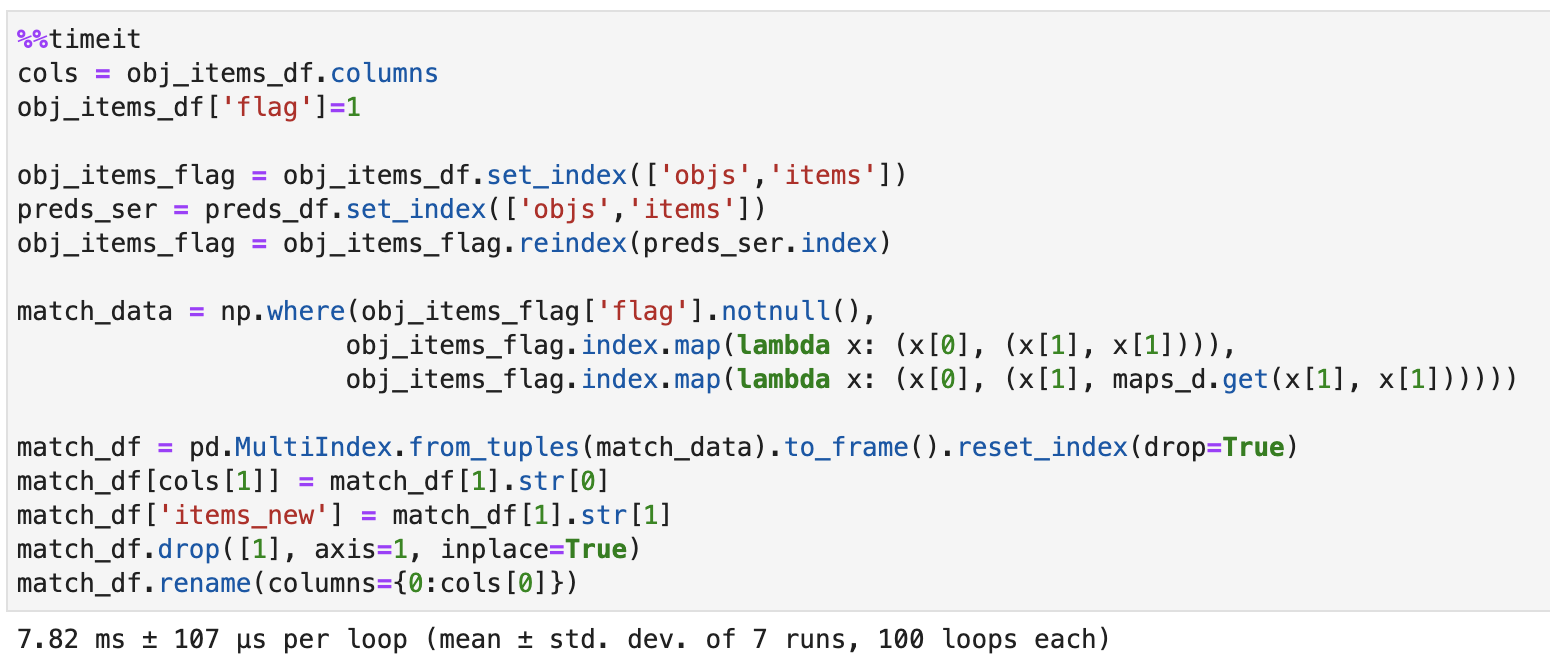
Если же увеличить объем данных, то соотношение скорости сильно поменяется:
# предсказания количества item-ов для объектов
items = ['item1','item2','item3','item4','item5']
all_df = pd.MultiIndex.from_product([np.arange(5000), items]).to_frame()\
.reset_index(drop=True).rename(columns={0:'objs', 1:'items'})
preds_df = pd.concat([all_df.sample(10000).reset_index(drop=True),
pd.Series(np.random.randint(100, size=10000), name='preds')], axis=1)
preds_df.sort_values(by='objs')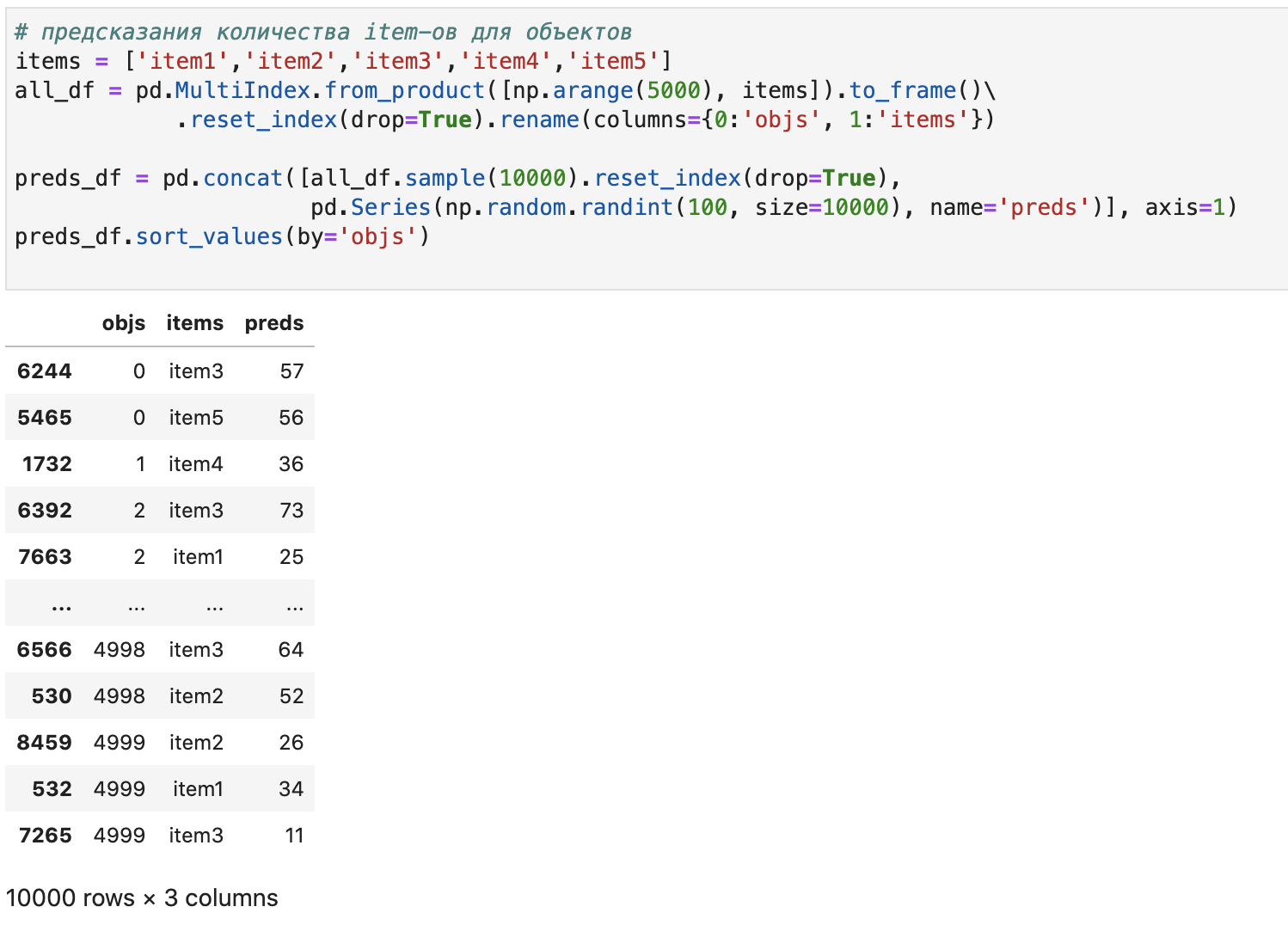
Вывод - логику многочисленных операций сравнения в датафреймах лучше реализовать на уровне индексов. А вы что бы добавили?
Не пропустите ничего интересного и подписывайтесь на страницы канала в других социальных сетях: