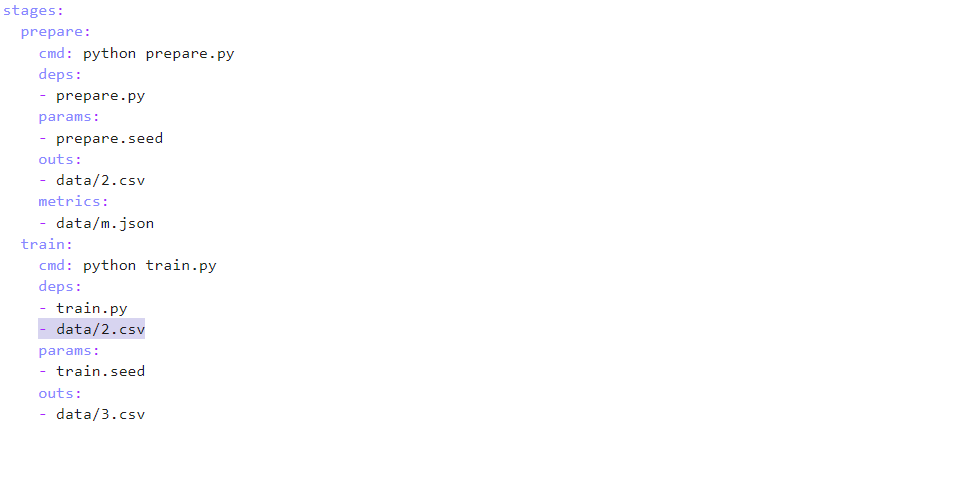Систематизация сценария с dvc пайплайнами

В этой статье я расскажу, как систематизировать ваш сценарий, сделать код и данные воспроизводимыми с dvc пайплайнами.
Сначала проведем предварительную работу. Настроим конфигурацию dvc и укажем путь к удаленному хранилищу версий данных:
git init dvc init dvc remote add -d data_storage arch
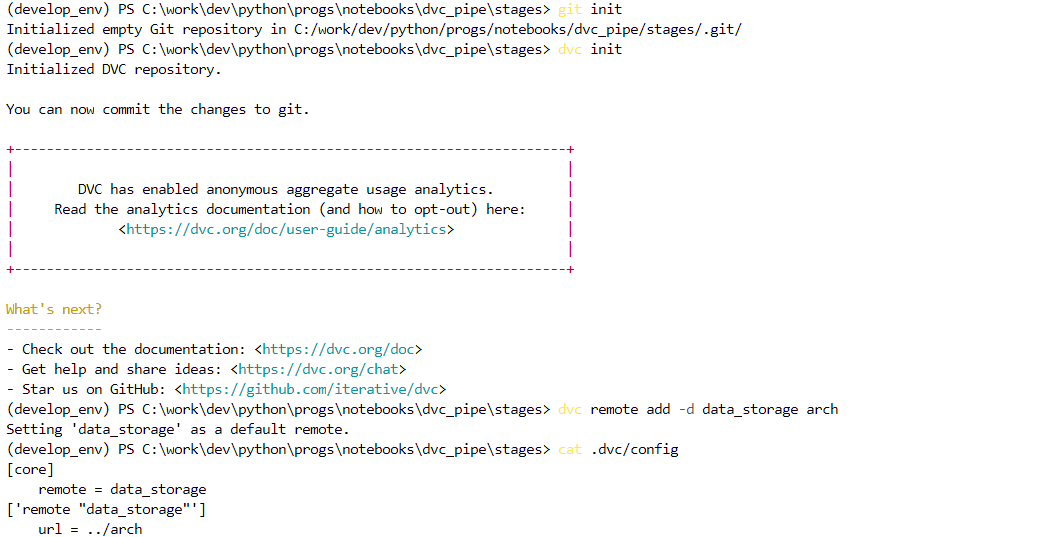
dvc add data/1.csv

А после по подсказке добавляем файлы в Git и убедимся, что dvc стал отслеживать данные:
git add 'data\.gitignore' 'data\1.csv.dvc' dvc list . -R --dvc-only
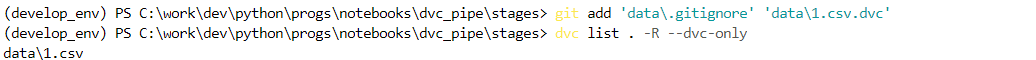
Это общие методы работы с dvc, о которых я рассказывал ранее. С пайплайнами работа происходит немного по-другому. Вы разбиваете скрипт на логические этапы (стадии), затем запускаете их, а dvc автоматически определяет, что отслеживать и что считать изменением.
Удобство заключается в том, что вы:
- систематизируете свой сценарий (выделяя отдельные скрипты, например, для загрузки, обработки данных, генерации признаков, обучения модели и отделяя код от внешних параметров);
- получаете возможность запустить все части одно командой;
- экономно расходуете время и ресурсы, так как стадии перезапускаются только при изменении зависимостей/параметров и только те, которые необходимо.
Вся цепочка скриптов запускается командой:
dvc repro
Добавление стадии происходит командой:
dvc stage add параметры команда_запуска_скрипта
-n/--name определяет имя стадии (фактически ваш python модуль);
-d/--deps задает зависимости в виде имен файлов и папок, при изменении которых dvc необходимо воспроизвести стадию. Например, к числу зависимостей относят код скрипта, соответственно, при его модификации и вызове dvc repro стадия и все последующие перезапустятся.
-p/--params указывает параметры. Это еще один тип зависимостей, инициирующий воспроизведение стадии. Однако параметры задаются в виде аргументов (например, размер тестовых данных при сплите, количество слоев в нейросети...) и могут быть использованы dvc для сопоставления результатов разных запусков (расскажу в очередной статье). Обычно параметры являются именами аргументов из файла конфигурации (по умолчанию используется файл с именем params.yaml).
-m/--metrics позволяет задавать пути к метрикам - отслеживаемым dvc файлам, в которые помещаются результаты работы (для отмены отслеживания используйте -M/--metrics-no-cache). Именно их следует сопоставлять с входными параметрами для выбора оптимальной конфигурации.
-o/--outs - задает выходы, которые отслеживаются dvc (чтобы отключить эту опцию используйте -O/--outs-no-cache). Выход предыдущей стадии включают в зависимости последующей.
Теперь продемонстрируем работу с dvc пайплайнами. Добавим стадию и убедимся, что выходные файлы и метрики начали отслеживаться dvc:
dvc stage add -n prepare -d prepare.py -p prepare.seed -o 'data/2.csv' -m data/m.json python prepare.py dvc list . -R --dvc-only
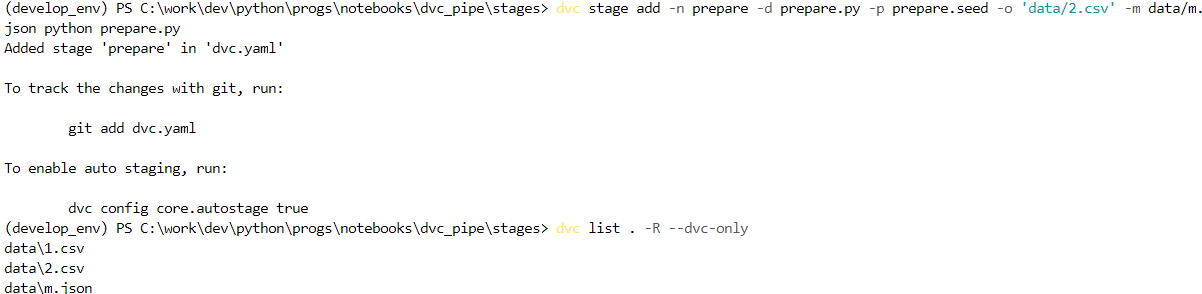
Теперь запустим пайплайн из нашей одной стадии:
dvc repro
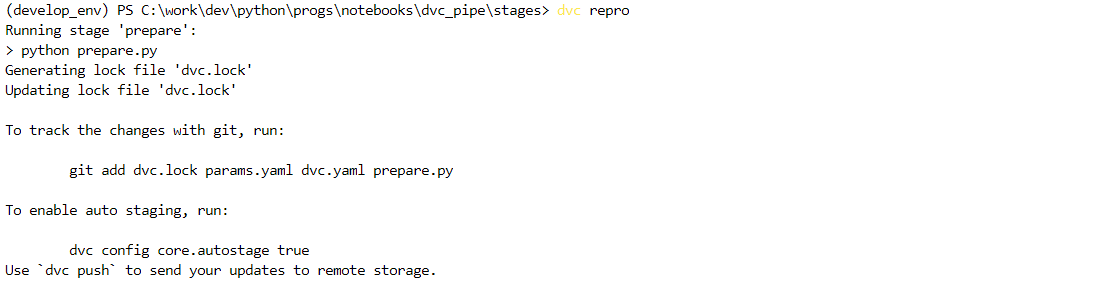
Для фиксации изменений с Git-ом воспользуйтесь подсказкой:
git add dvc.lock params.yaml dvc.yaml prepare.py
Запушим файлы (хотя это не обязательно, копии сохраняются локально после вызова dvc repro):

Теперь изменим все три наших файла и вызовем dvc repro (ниже версии до и после):
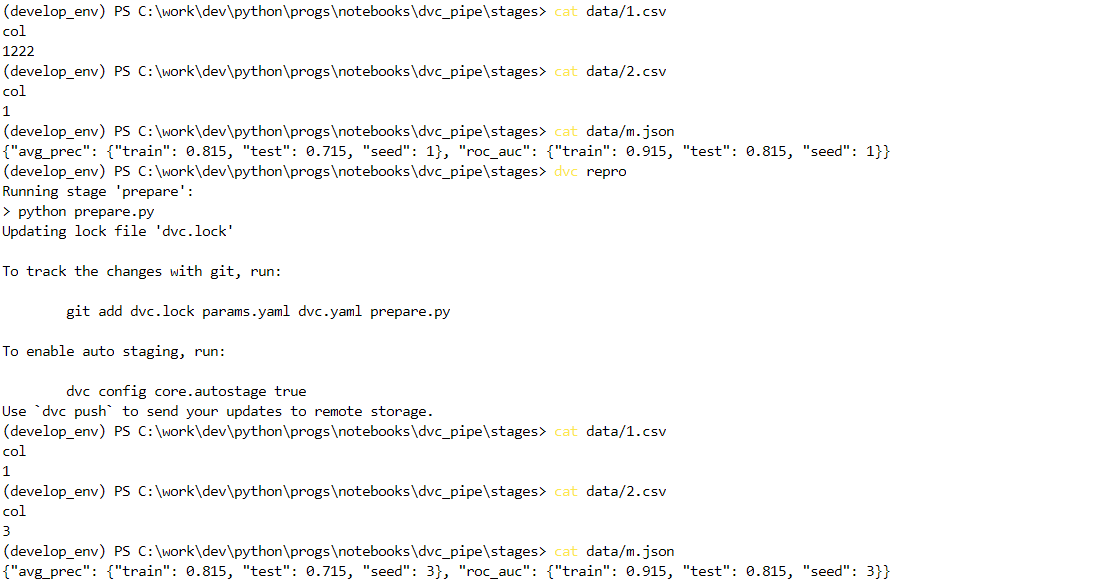
Зафиксируем изменения Git-ом и запушим файлы:

Теперь вернемся на прошлый коммит и выведем версии файлов:
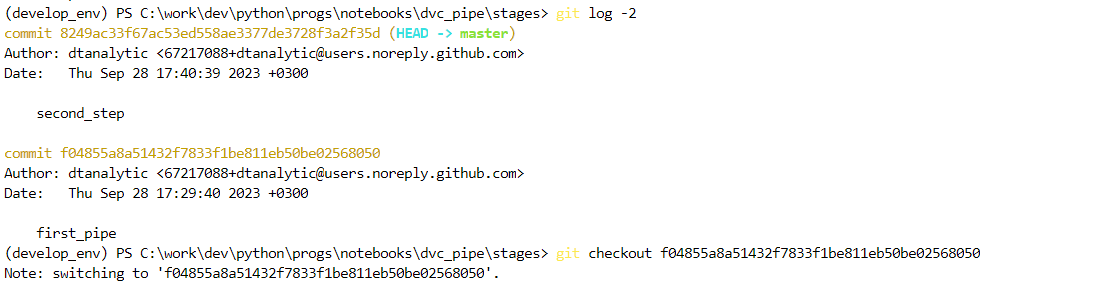
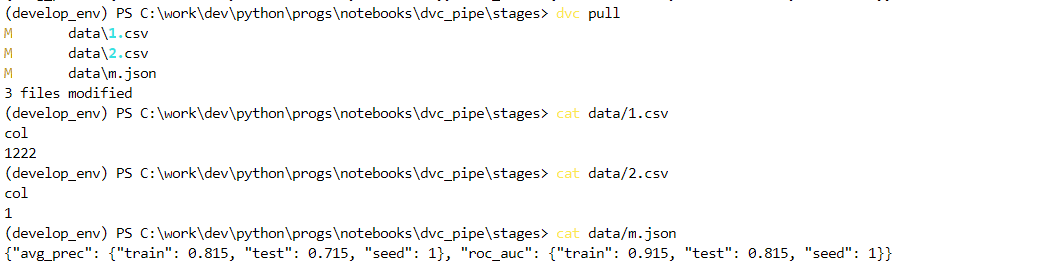
Видим, что так как мы не сделали dvc commit после изменения файлов с данными, у нас внесены модификации только в файлы, которые отслеживаются в рамках нашего пайплайна, поэтому 1.csv остался без изменений.
dvc stage add -n train -d train.py -p train.seed -o 'data/3.csv' python train.py
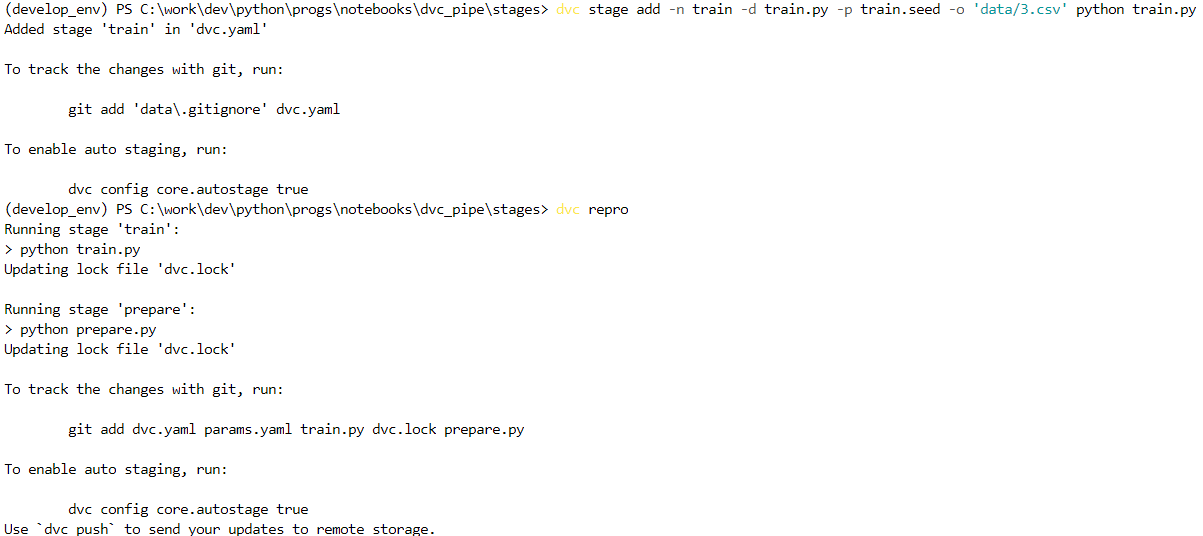
Выведем актуальные версии файлов и закоммитим изменения и в dvc, и в git-е:
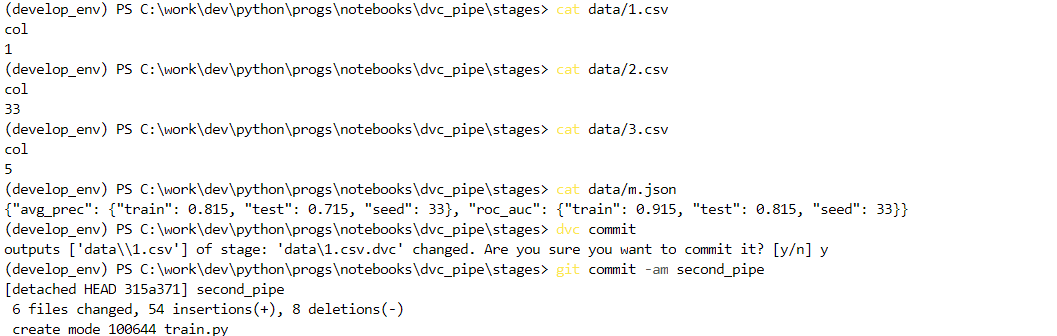
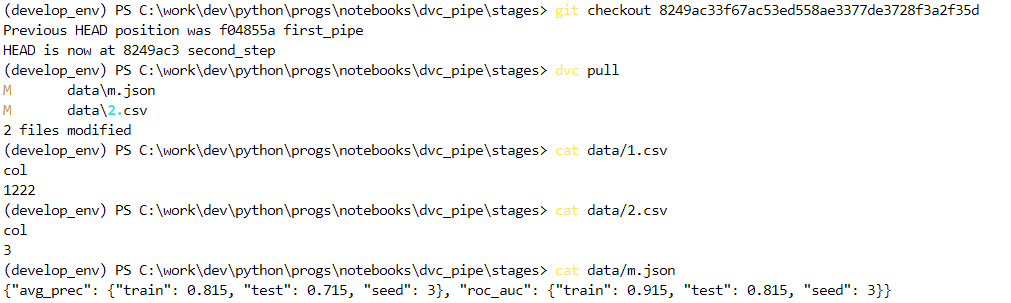
Теперь попробуем переключиться на прошлый коммит:
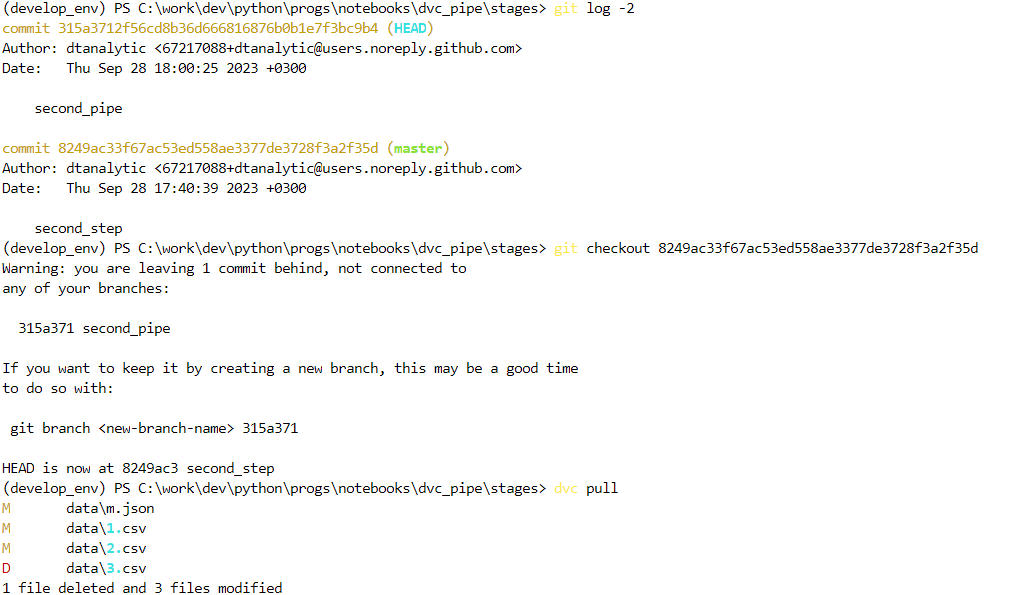
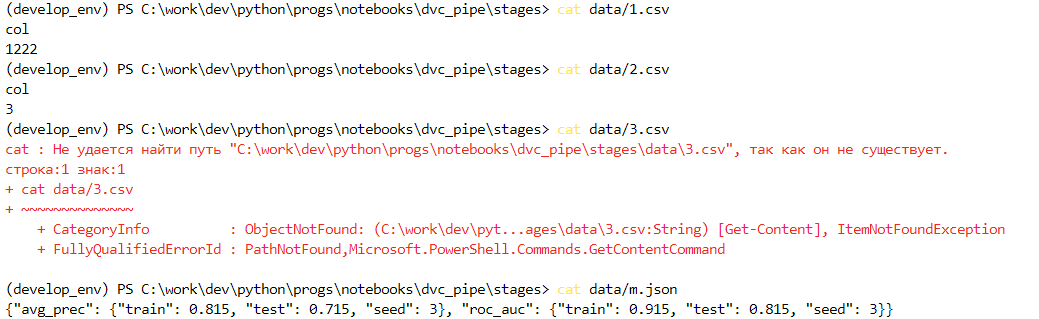
Теперь вернемся на последний коммит и увидим, что изменения восстановились и для файла 1.csv, так как мы сделали dvc commit:
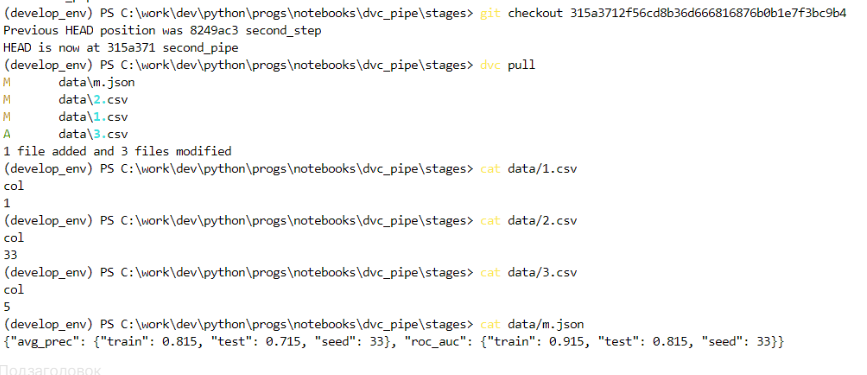
Таким образом, для сохранения версий файлов, отслеживаемых отдельно от пайплайнов, следует делать dvc commit, для остальных достаточно вызова dvc repro.
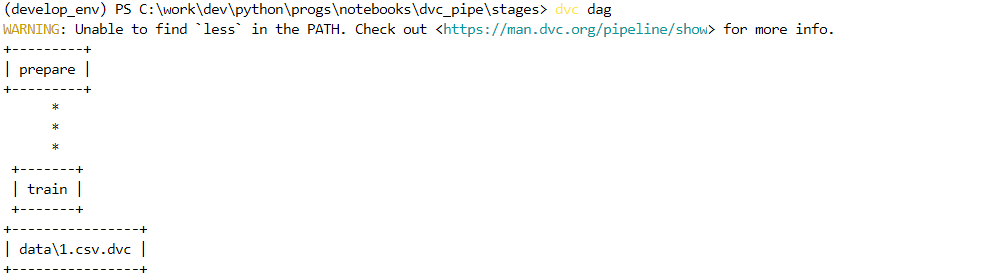
Вы можете отобразить отслеживаемые dvc структуры командой:
dvc dag
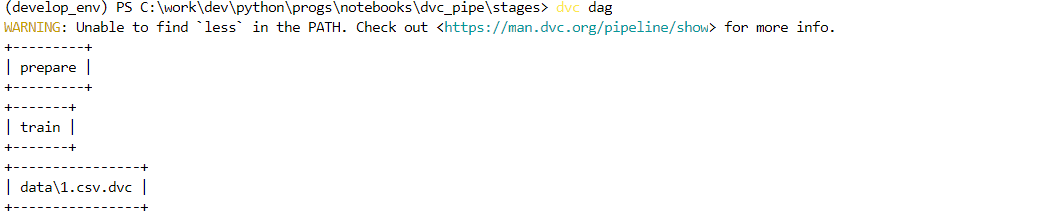
Следует отметить, что наши две стадии не связаны в один пайплайн. Чтобы исправить это, сделайте выходной файл первой - зависимостью второй. Как вариант, можно исправить файл dvc.yaml, который автоматически генерируется при добавлении стадии (поэтому можно вместо командного добавления стадий изменять этот файл). Его состав соответствует тому, что вы добавляли при создании стадии. Например, для коррекции нашего dag-а я добавил выделенную строку: