Раскрываем суть регрессии через смысл коэффициентов

Рассмотрим, как получить коэффициенты парной линейной регрессии, чтобы понять логику этой модели. Пусть наша формула предсказания цели через неизвестный x имеет следующий вид:

Коэффициенты находятся путем решения задачи минимизации ошибки:
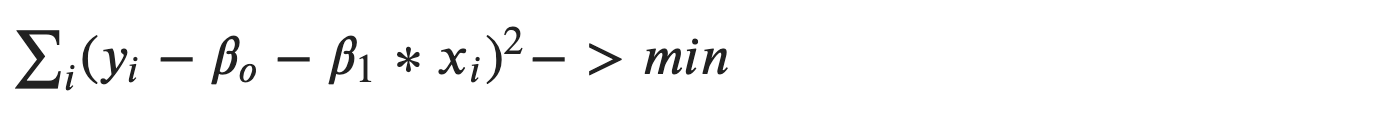
Для поиска минимума найдем производные по 𝛽𝑜 и 𝛽1:
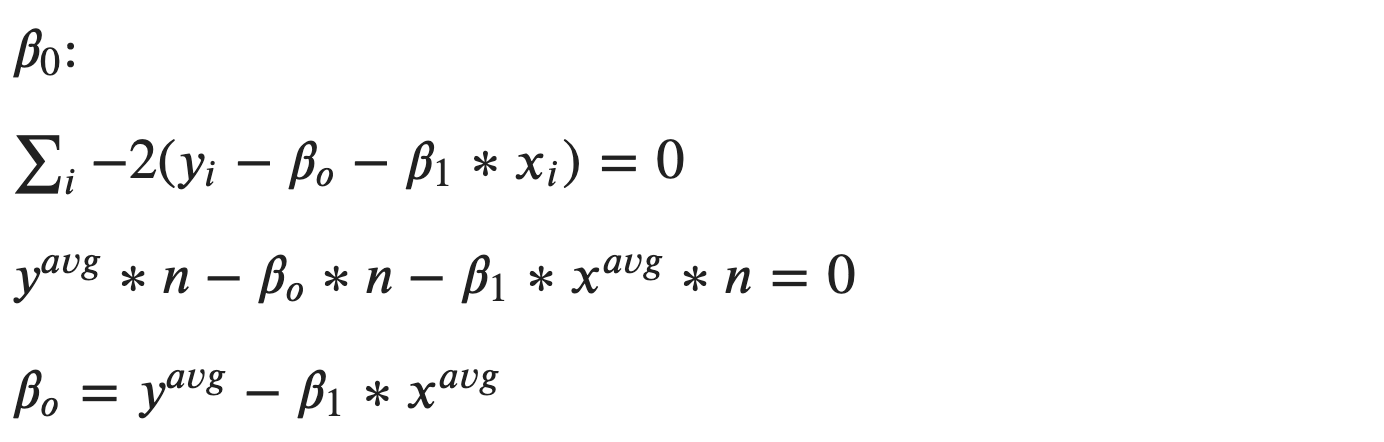
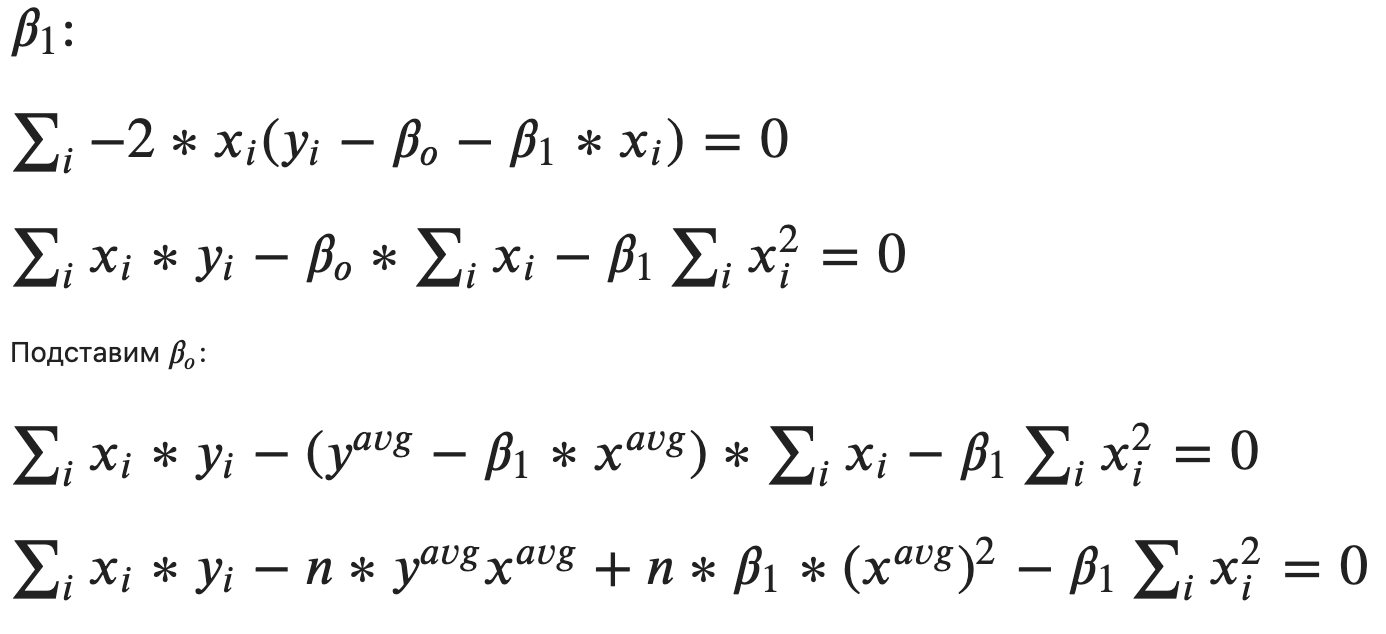
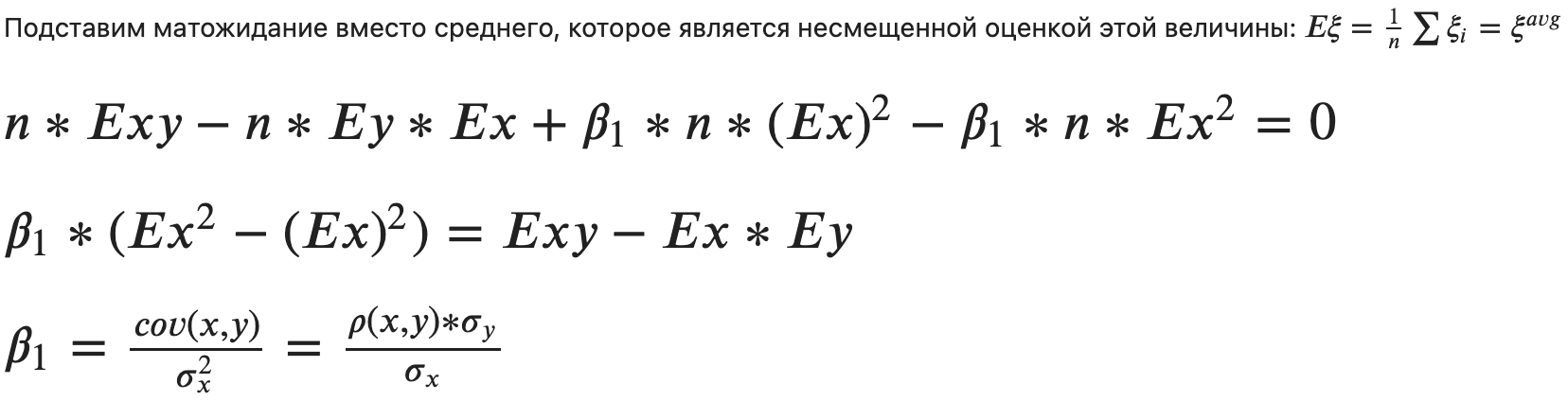
То есть, 𝛽1 отражает линейную связь между зависимой и независимой переменной. Если ее нет, то cov = 0 и 𝛽1==0, а регрессия будет предсказывать среднее цели, что тоже не лишено смысла.
Из формулы 𝛽1 через корреляцию видно, что увеличение x на одно стандартное отклонение x влечет увеличение прогноза на одно стандартное отклонение y, умноженное на величину корреляции. В случае идеальной связи (𝜌(𝑥,𝑦)=1), увеличение x на одно стандартное отклонение влечет увеличение прогноза на одно стандартное отклонение.
Теперь сгенерируем демонстрационные данные и убедимся в том, что формула для вычисления коэффициентов верная:
import numpy as np x = np.arange(1, 6) y = 22*x+5

Представим, что мы не знаем коэффициенты регрессии y по x и пытаемся их найти, имея только x и y:
import pandas as pd
df = pd.DataFrame({'x':x, 'y':y})
beta1 = df.cov().iloc[0,1]/df['x'].var()
beta0 = df['y'].mean() - beta1*df['x'].mean()
beta0, beta1