Интеллектуальная выборка колонок датафрейма

Хватит тратить время на ручное извлечение столбцов по их именам или индексам, пора пользоваться более продвинутыми механизмами, о которых и пойдет речь в этой статье. В качестве критериев для интеллектуальной выборки возьмем соответствие их имен и типов неким правилам.
В демонстрационных целях будем использовать следующий датафрейм:

Для селекции по типам рассмотрим два способа. Первый - использование функции NumPy where:
idx = np.where(df.dtypes==np.float64) df.columns[idx]

np.where выбирает кортеж индексов (по всем измерениям) ненулевых элементов массива. Аналогичное поведение с помощью метода nonzero:
np.asarray(df.dtypes=='float64').nonzero()

Однако это не самый оптимальный способ выборки колонок по типам, так как для этого можно использовать метод датафрейма select_dtypes:
df_float = df.select_dtypes(include=[np.float64, np.int64]) df_float
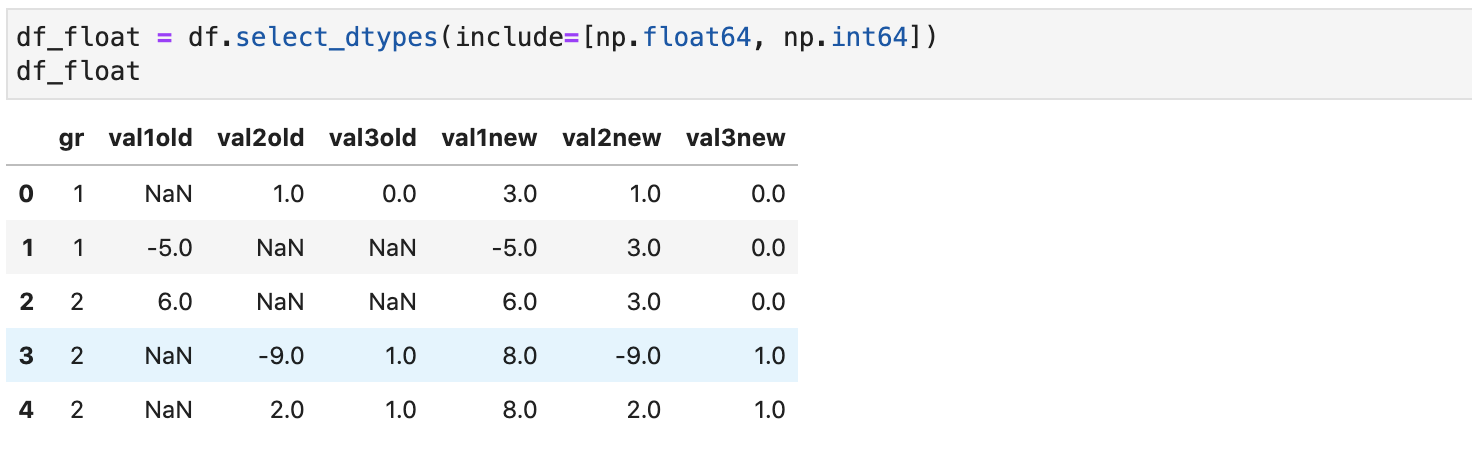
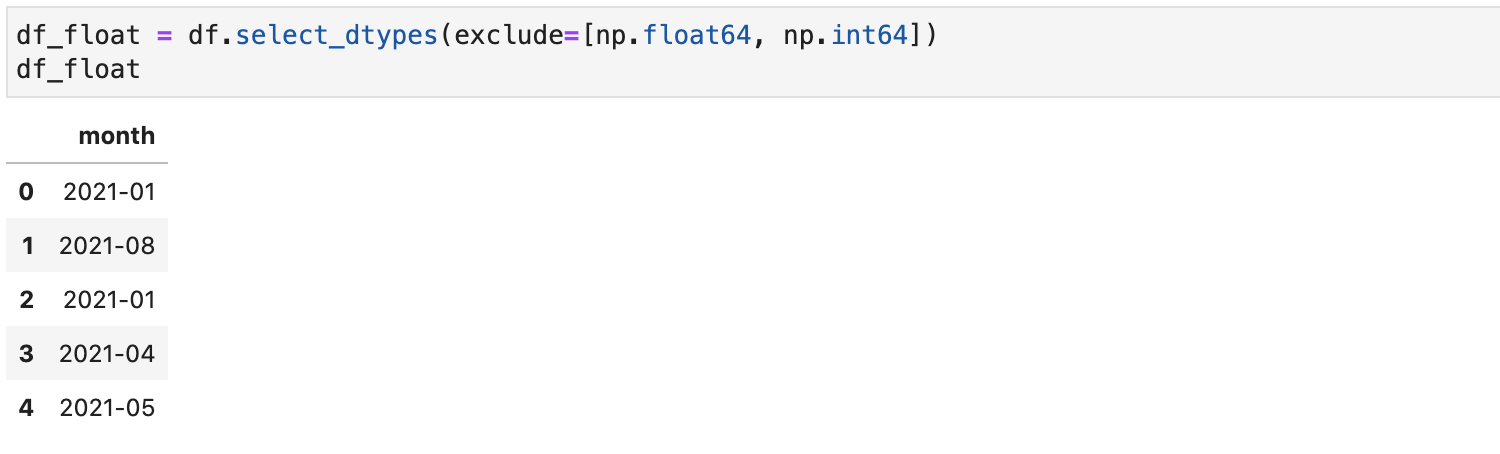
При этом можно, как включать определенные типы с параметром include, так и исключать через exclude:
df_float = df.select_dtypes(exclude=[np.float64, np.int64]) df_float
Для выборки столбцов по именам рассмотрим опять же два способа. Первый - это включение элементов атрибута columns, которые удовлетворяют некому условию (например, имеют подстроку "old"):
cols = [it for it in df.columns if it.count('old')>0]
cols
Однако есть и более простой способ - метод filter:
df_old = df.filter(regex=r'(old)|(month)') df_old
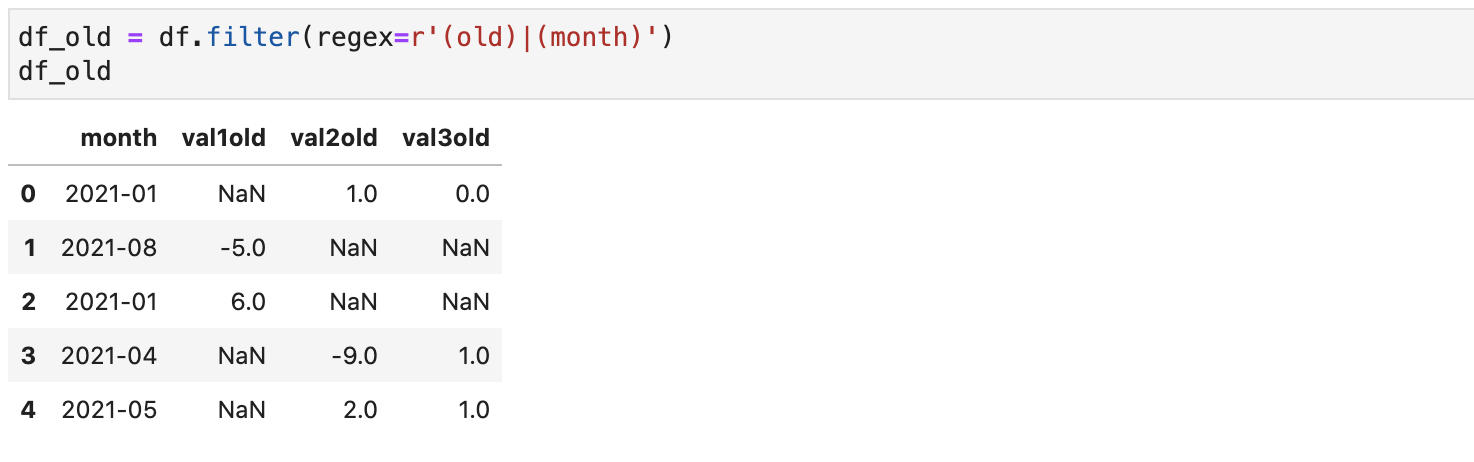
Как можно заметить, с использованием параметра regex можно задать регулярное выражение, которому должны удовлетворять имена колонок.