Машинное обучение на основе правил

Методы машинного обучения известны своей таинственностью, волшебством и сложной интерпретируемостью. Вместе с тем это не всегда так - существуют алгоритмы достаточно мощные и одновременно обладающие простым объяснением.
Одним из таких является классификатор на основе правил. Готовая реализация продвинутых алгоритмов (IREP и RIPPER) имеется в библиотеке wittgenstein, чтобы установить которую достаточно воспользоваться менеджером пакетов (pip install wittgenstein).
В качестве примера возьмем набор для классификации грибов по (съедобен/ядовит) в зависимости от ряда внешних параметров:
import pandas as pd
import wittgenstein as lw
mush_df = pd.read_csv('data/mushrooms.csv')
mush_df.info()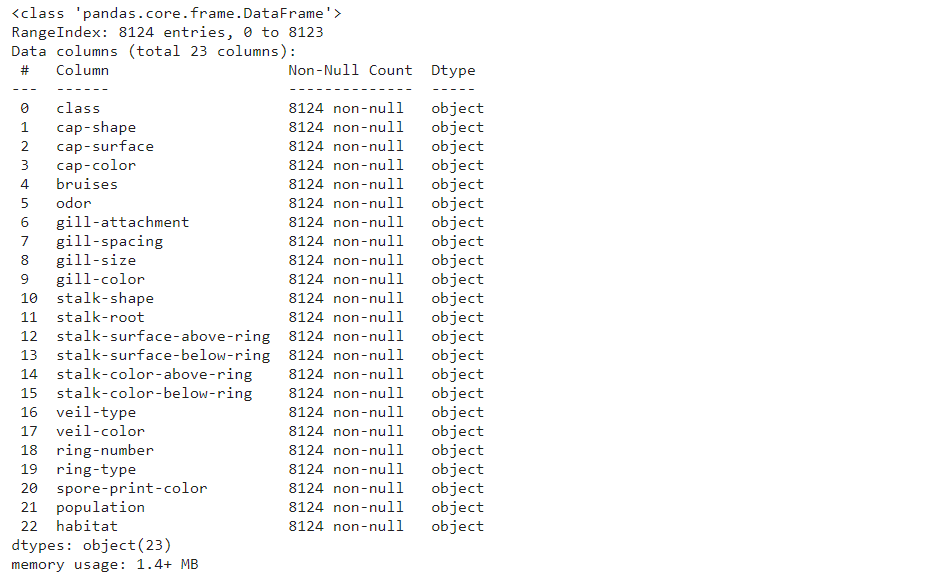
Колонки содержат категориальные данные и в целях оптимизации могут быть преобразованы к этому типу:
for col in mush_df.columns:
mush_df[col] = mush_df[col].astype('category')
print(f'столбец {col}, уникальных - {len(mush_df[col].unique())}')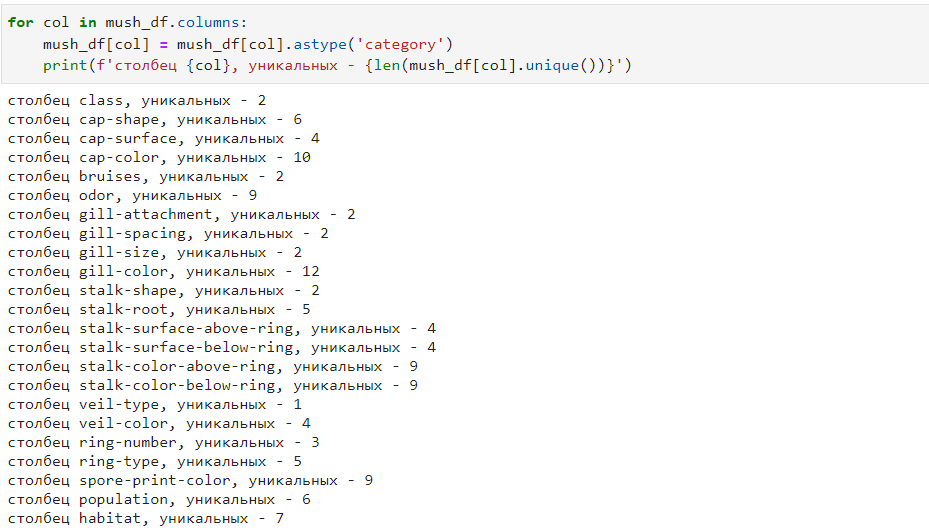
Теперь датафрейм занимает почти в 10 раз меньше места:
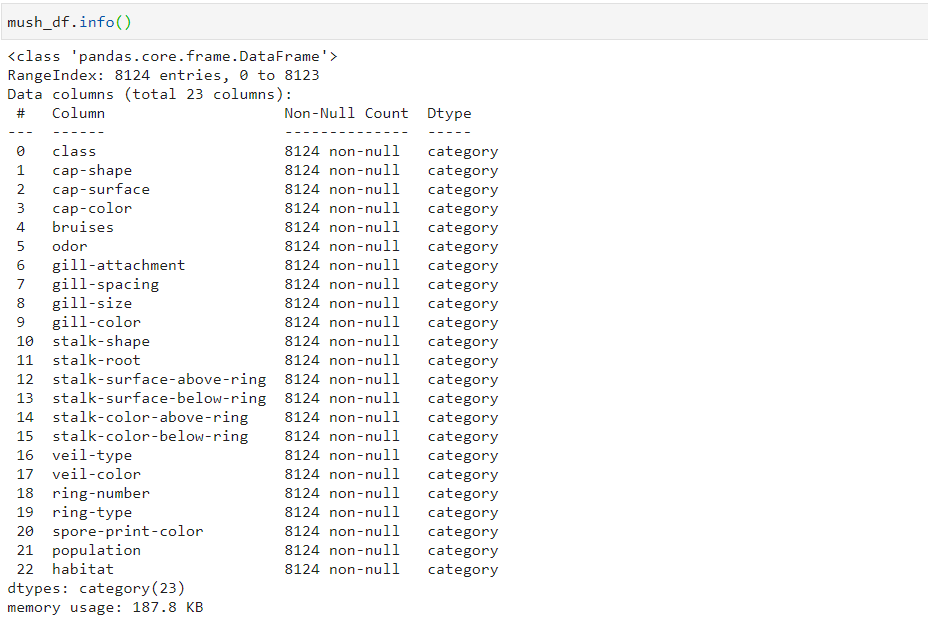
Перейдем обучению. В пакете wittgenstein реализованы классы IREP и RIPPER которые представляют одноименные алгоритмы. В качестве параметров в конструктор можно передать:
- prune_size - доля тренировочного набора, которая участвует в стадии сокращения (корректировки) правила, полученного с помощью других образцов тренировочного набора (по примеру перекрестной проверки);
- max_rules - максимальное количество правил;
- max_rule_conds - максимальное количество условий в одном правиле;
- random_state - инициализатор случайных значений.
Создадим объект классификатора и разделим данные на обучающую и тестовую выборки:
# clf = lw.IREP() clf = lw.RIPPER()
from sklearn.model_selection import train_test_split mush_tr, mush_ts = train_test_split(mush_df, test_size=0.2)
Обучение осуществляется путем вызова метода fit. Передать признаки и target в него можно двумя способами:
clf.fit(mush_tr, class_feat='class', pos_class='p')
# clf.fit(mush_tr.drop('class', axis=1), mush_tr['class'].map({'p':1, 'e':0}).astype(int))В первой форме указывается датафрейм, а затем имя столбца target-а в нем, также если цель строчная (в нашем случае значения p и e), то нужно указать наименование класса 1. Во втором привычный синтаксис sklearn - датафрейм с признаками и отдельно колонка цели (однако ее надо будет дополнительно закодировать).
Предсказания осуществляются методом predict, который содержит опцию возврата не только предсказаний, но и правил для точек с положительным классом (параметр give_reasons=True):
y_pr = clf.predict(mush_ts) clf.predict(mush_ts, give_reasons=True)[1][:5]

Для оценки классификатора можно воспользоваться стандартными метриками scikit-learn или встроенным методом score:
from sklearn.metrics import classification_report print(clf.score(mush_ts, y_pr, score_function=classification_report))
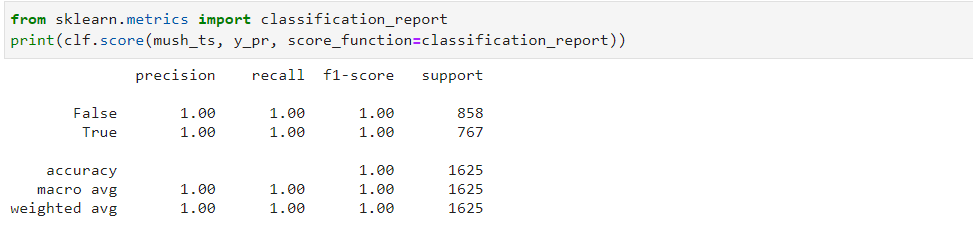
print(classification_report(mush_ts['class'].map({'p':True, 'e':False}).astype(bool), y_pr))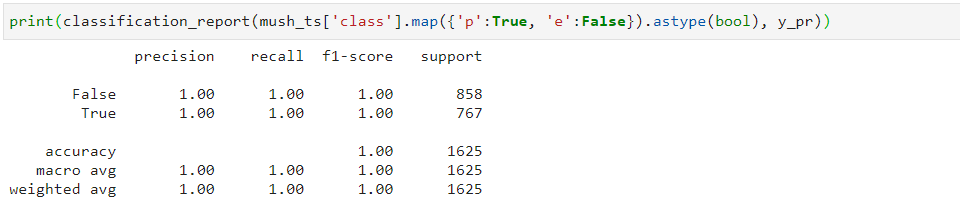
У классификатора имеется опция вывода вероятности прогноза с методом predict_proba.
Также для получения списка правил, на основании которых прогнозируется положительный класс (если ни одно не сработало - отрицательный) предусмотрен метод out_model или свойство ruleset_:
# clf.ruleset_ clf.out_model()

V - означает ИЛИ (фактически разделяет правила), а ^ - И (формирует набор условий в рамках одного правила). В нашем случае классификатор со 100% точностью формирует 8 правил для определения ядовитых грибов, остальные - съедобные. Теперь можно идти в лес собирать грибы без опаски!
Не пропустите ничего интересного и подписывайтесь на страницы канала в других социальных сетях: