Smote для борьбы с дисбалансом в классах

При предсказании редких явлений (например, природной катастрофы, орфанного заболевания) тренировочная выборка в большинстве случаев содержит перекос в сторону одного из классов. И правда, формируя датасет, найти людей небольных ВИЧ значительно проще. Соответственно, при обучении модели на таких "скошенных" данных редкие кейсы могут затеряться, а их особенности не получат достаточного внимания.
Для улучшения прогнозов на таких датасетах применяются разные техники, одной из которых является SMOTE. Его ключевая идея заключается в синтетическом дополнении тренировочного набора редкими наблюдениями с немного измененной признаковой базой в противовес распространенной практике простого дублирования примеров из класса с меньшим представительством.
Очередной синтетический пример получается из рассмотрения двух редких "соседей" - к признакам одного из них добавляется разность признаков, каждая координата которого умножается на случайное число от 0 до 1. В зависимости от доли увеличения (ресэмплинга) определяется количество редких экземпляров и их соседей, участвующих в генерации новых примеров. Если потребуется добавить 300%, то рассматривается каждый редкий пример и 3 его ближайших соседа, с каждым из которых генерируется объект с новыми признаками. Если доля увеличения меньше 100%, то рассматривается подмножество исходных точек и по одному соседу для каждого. По замыслу авторов, такой подход увеличивает признаковое пространство класса меньшинства, делает его менее специфическим и, как следствие, классификатор лучше обобщается. В Python SMOTE реализован в модуле imblearn.over_sampling библиотеки imbalanced-learn. Рассмотрим его применение на следующих данных:
import pandas as pd
df = pd.DataFrame([[1,2,3], [1,3,6], [0,8,9], [1,2,2], [0,12,14],
[1,4,6], [0, 13,15]], columns=['target', 'val1', 'val2'],
index=['one', 'two', 'three', 'four', 'five', 'six', 'seven'])
df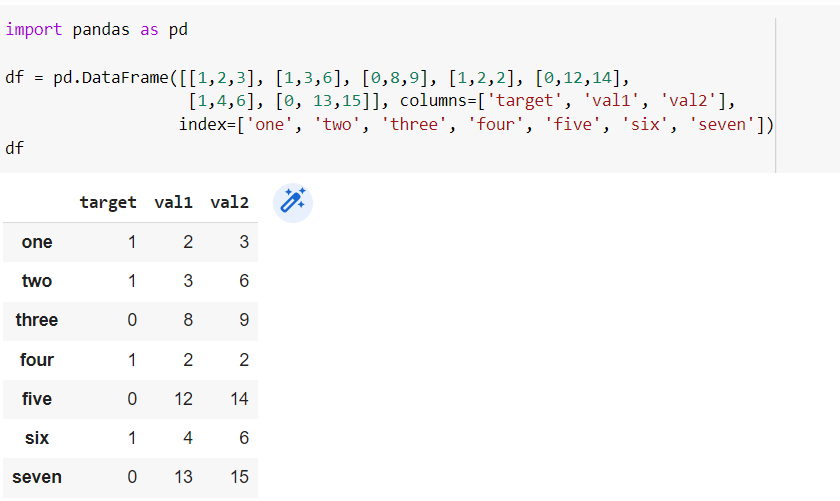
Визуализируем набор, чтобы понимать как отразятся изменения после применения SMOTE:
import seaborn as sns sns.scatterplot(data=df, x ='val1', y='val2', hue='target')
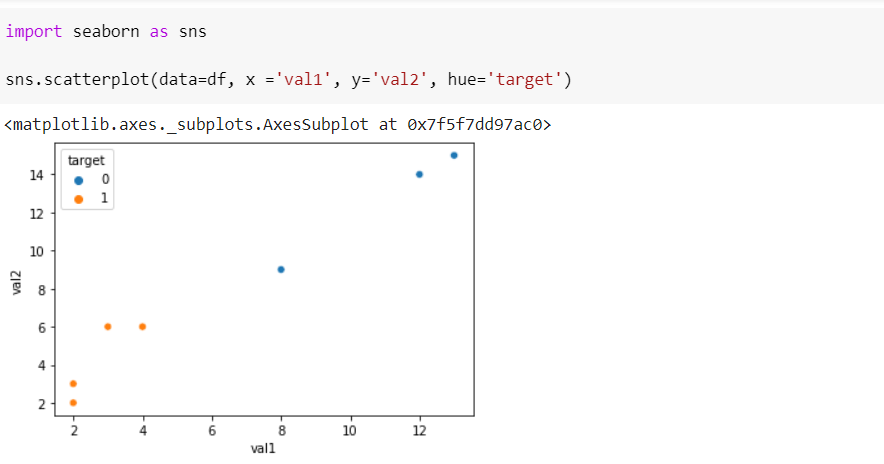
Теперь воспользуемся методом fit_resample класса SMOTE для генерации синтетических данных:
from imblearn.over_sampling import SMOTE X_res, y_res = SMOTE(random_state=10, k_neighbors = 2).fit_resample(df[['val1', 'val2']], df['target']) X_res.join(y_res)
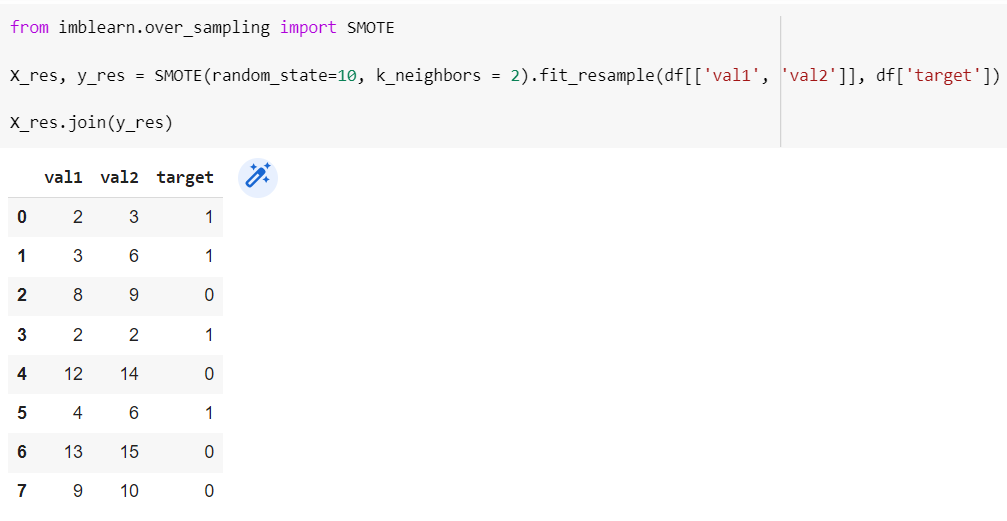
Параметры random_state и k_neighbors задают инициализатор случайных значений и количество ближайших соседей. Еще можно использовать sampling_strategy для задания пропорции минорного класса по отношению к мажорному. Вот визуализация изменений:
sns.scatterplot(data=X_res.join(y_res), x ='val1', y='val2', hue='target')
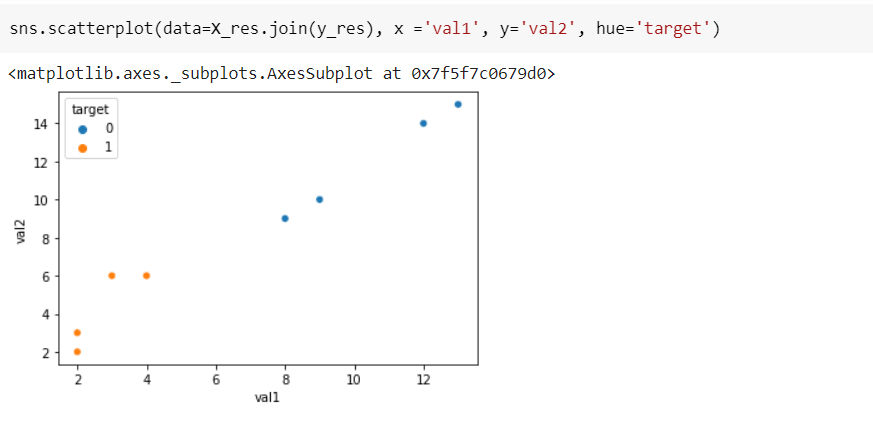
Как можно заметить, наш новый экземпляр находится между существующими из того же класса.