2 коварные особенности, которые вызовут ошибки при работе с датафреймом

Знатоков стандартных библиотек Python мир данных в Pandas может удивлять. Некоторые его особенности лучше знать, чтобы уберечь себя от ошибок. О двух вещах, на которых программисты часто оступаются, я расскажу в этой статье.
Так, одной из проблем является обманчивость типа object. Многие, считая его строчным заблуждаются, так как в действительности он означает, что столбец содержит значения со стандартными питоновскими типами. Для примера сравним две ситуации.
Сначала создадим серию с указанием, что данные имеют строчный тип:
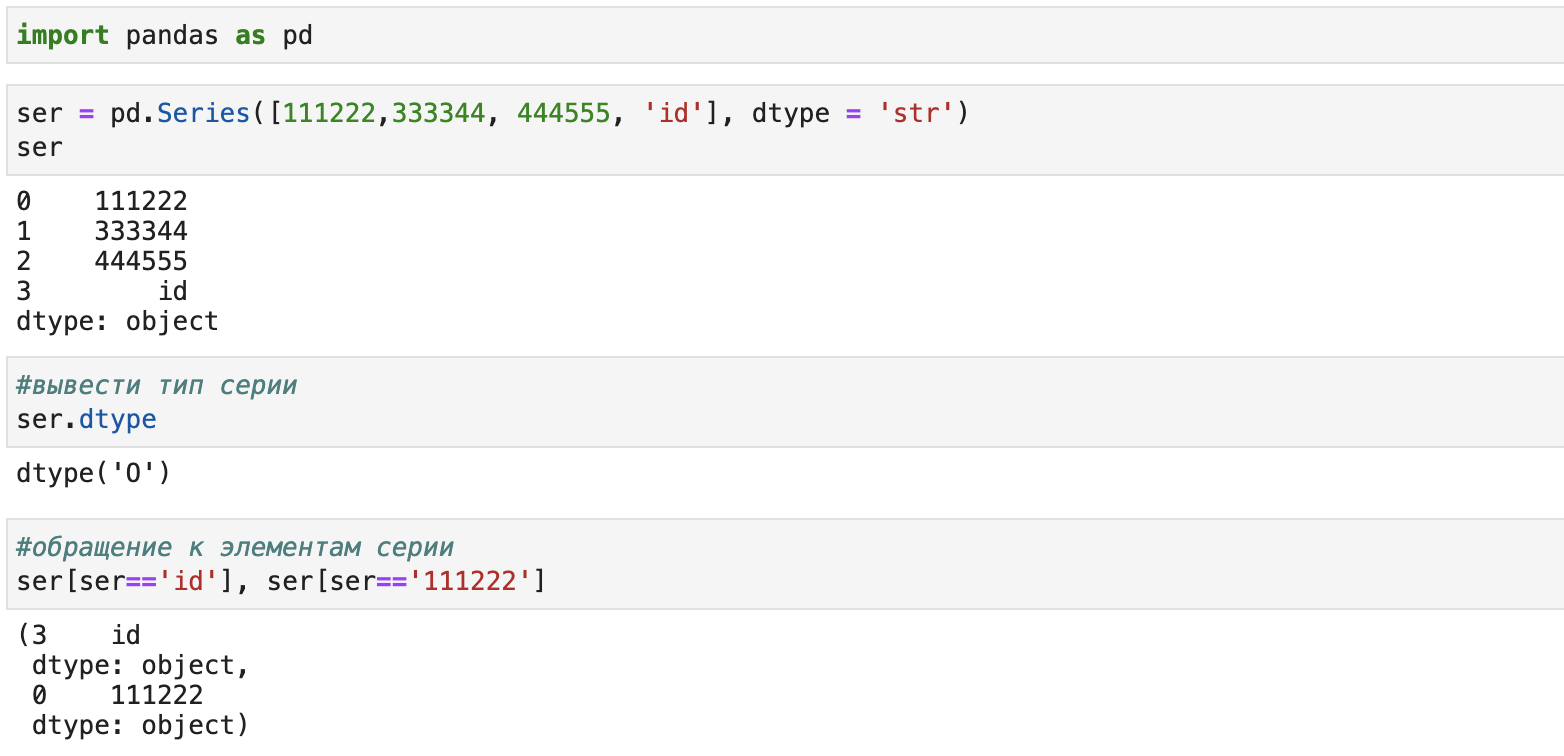
Как можно заметить, тип серии - object, данные распознаются как строчные. А теперь другая ситуация только содержимому серии не будем присваивать строчный тип:
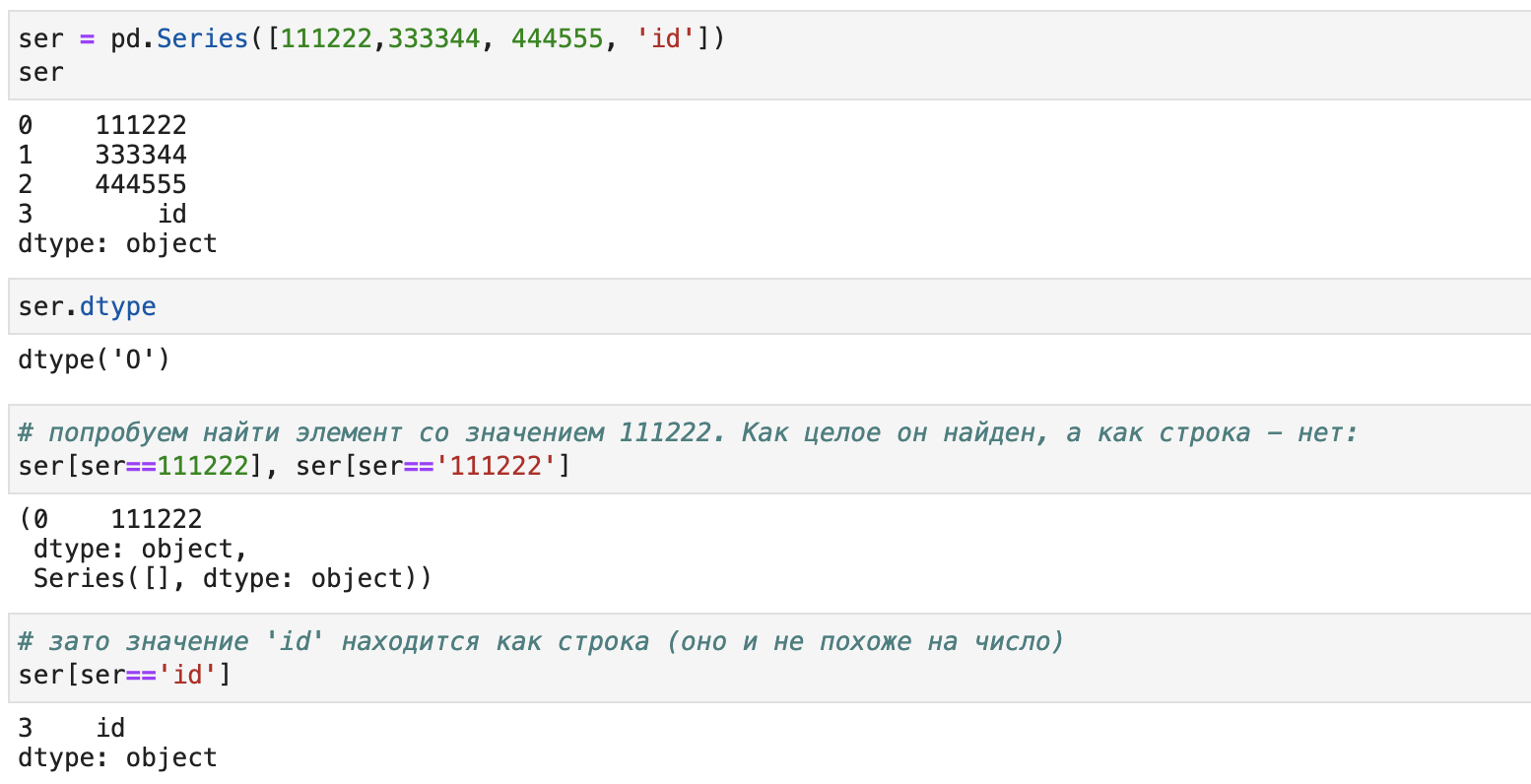
Как мы видим, к элементу 111222 можно обратиться только как к числовому. При этом к 'id', как и прежде - как к строчному. Несмотря на другое поведение тип серии - object.
Таким образом, объектный тип не означает, что в элементах серии будут присутствовать только строки (хотя может быть и так, если задать этот тип явно, как в первом примере).
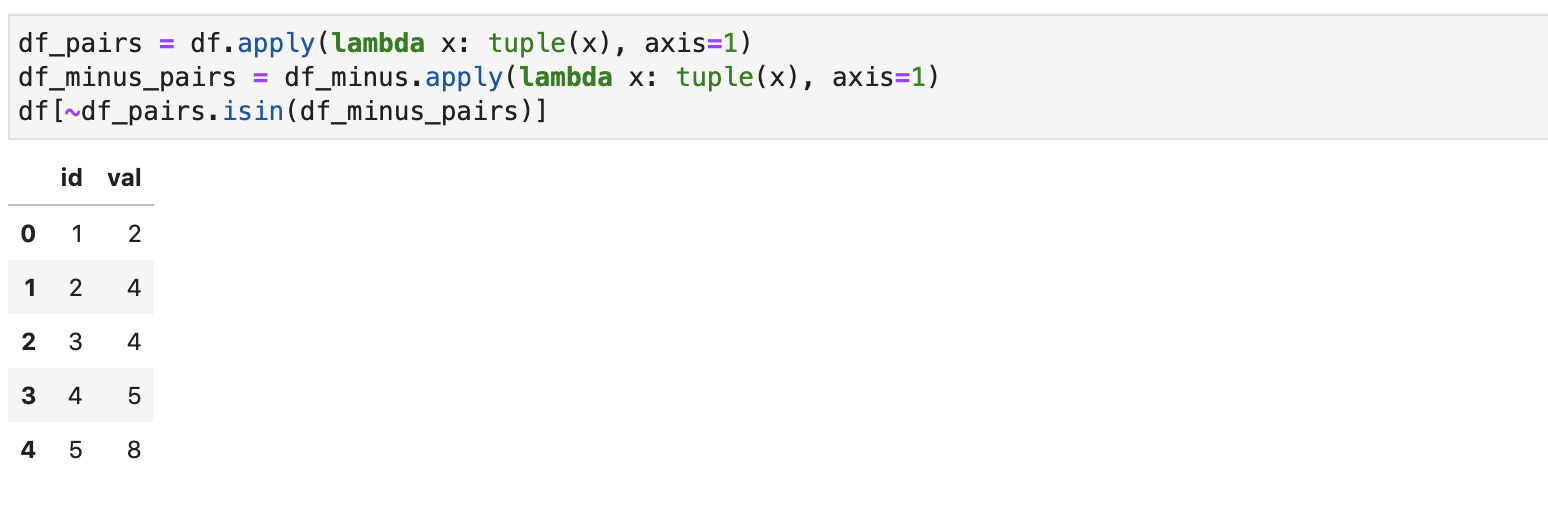
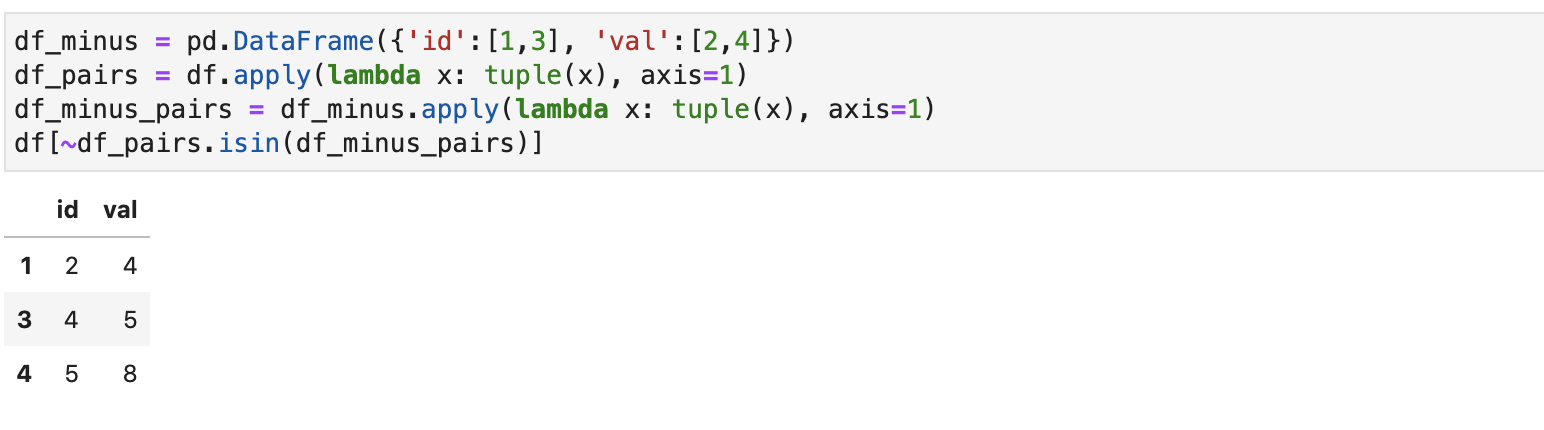
Другой проблемой является обманчивость оператора isin. Рассмотрим два датафрейма:
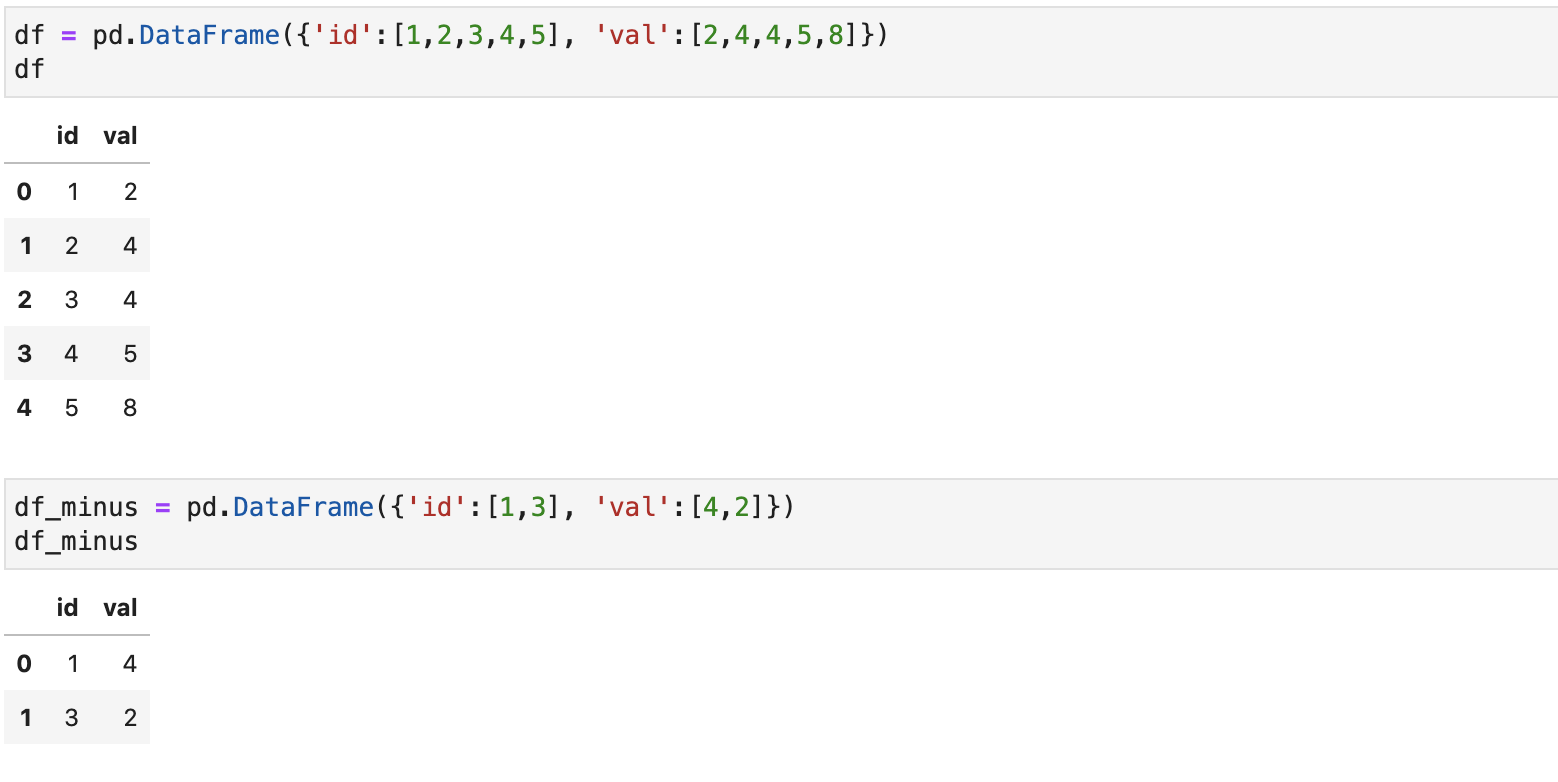
Попытаемся вычесть из первого второй, так чтобы строки второго не встречались в первом. Можно пойти неправильным способом и попытаться сделать это с помощью isin:
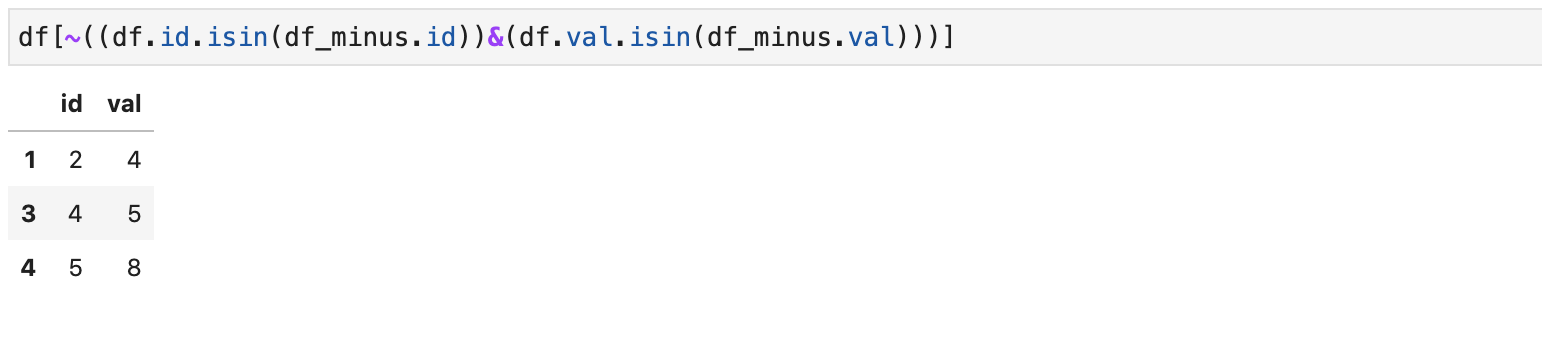
isin проверяет возвращает True, если хотя бы в какой-то ячейке столбца другого массива содержится элемент первого. Соответственно, два isin не равносильны проверке совпадения пары элементов в строке.
Правильнее сделать такую проверку получив пары элементов в обоих массивах и вызвав isin однажды: