April 21, 2022
Сводные агрегации c Pandas

Рассмотрим, какие агрегирующие функции можно задавать в pivot_table и как определять собственные методы. Для примера будем работать со следующим датафреймом:
import pandas as pd
import numpy as np
df = pd.DataFrame([['Иванов ИИ', 1, 12], ['Федоров АК', 2, np.nan],
['Арсентьева ВБ', 1, 13],['Черкасова АА', 1, 13],
['Чувашов ВК', 1, None], ['Галанова ББ', 2, 14]],
columns=['fio', 'gr_id', 'revenue'])
df
Для создания сводных статистик можно использовать функцию pivot_table, в параметр aggfunc которой передаются функции агрегации (поддерживаются как строчные наименования, так и ссылки). Например, сгруппируем по полю gr_id и посчитаем метрики для revenue:
df.pivot_table(index='gr_id', values='revenue', aggfunc=['count', np.mean])

К числу наиболее часто используемых статистик относятся count, nunique, min, max, std, sum, mean, median, var, quantile:
df.pivot_table(index='gr_id', values='revenue',
aggfunc=['count', 'nunique', 'min', 'max', 'std', 'sum',
'mean', 'median', 'var', 'quantile'])
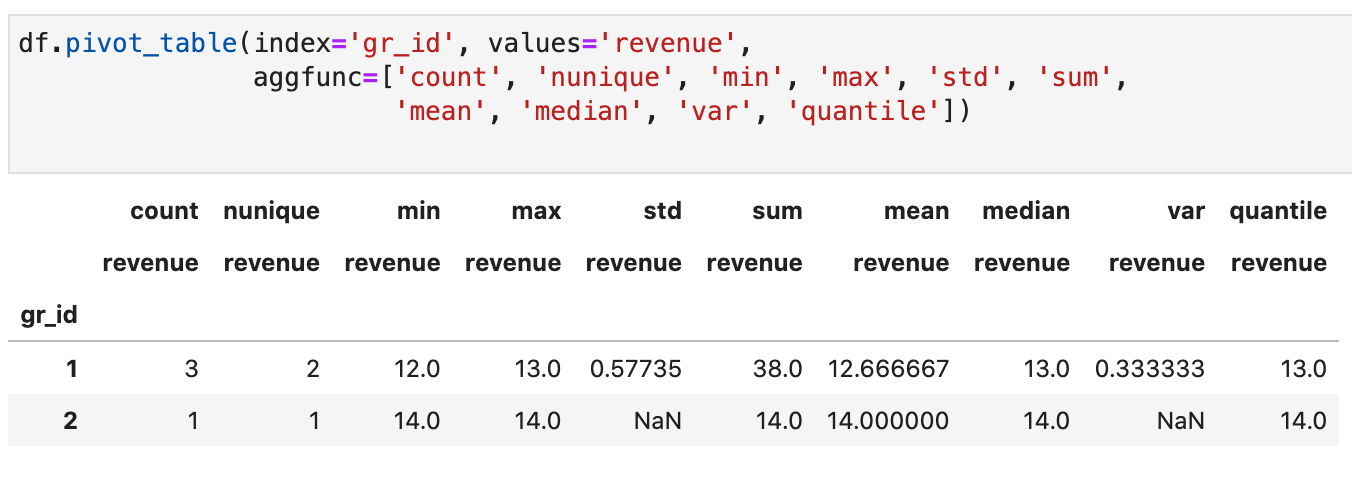
Обратите внимание, что quantile по умолчанию возвращает медиану, чтобы передать значение квантили можно воспользоваться partial и передать в pivot_table ссылку:
from functools import partial
q_25 = partial(pd.Series.quantile, q=0.25)
df.pivot_table(index='gr_id', values='revenue',
aggfunc=[q_25])
Также в pivot_table можно передавать собственные функции:
def num_vals(col):
return col.shape[0]
df.pivot_table(index='gr_id', values='revenue', aggfunc=['count', 'mean', num_vals])

df.pivot_table(index='gr_id', values='revenue', aggfunc=['count', 'mean',
lambda x: x.shape[0]])