Корректное использование сида при сравнении моделей на кросс-валидации

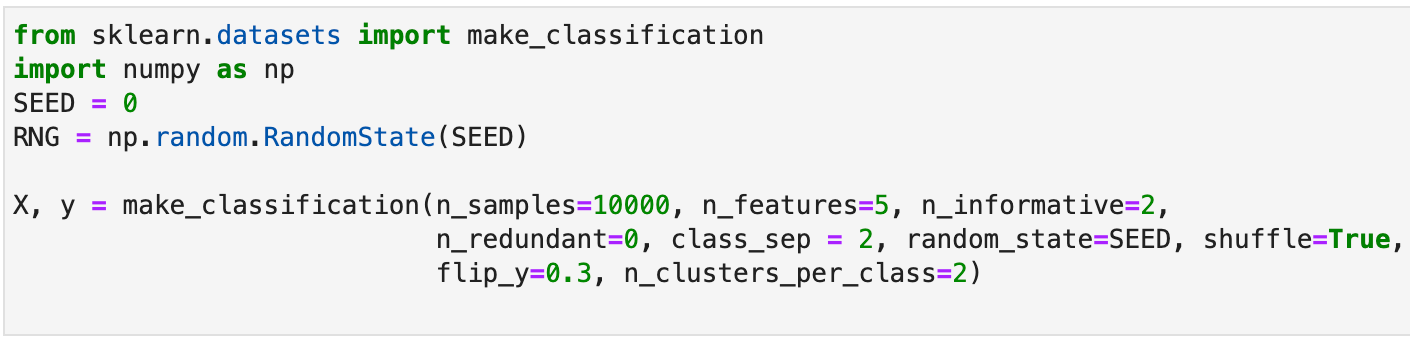
Как я рассказывал ранее, использование класса np.random.RandomState для инициализации счетчика случайных чисел в моделях является предпочтительным для оценки качества. В то же время при сравнении результатов кросс-валидации моделей в сплиттер лучше вместо данного объекта передавать целый сид, иначе наборы фолдов будут отличаться между собой, поэтому и модели сравнивать не совсем корректно. Сгенерируем демонстрационный набор данных:
from sklearn.datasets import make_classification
import numpy as np
SEED = 0
RNG = np.random.RandomState(SEED)
X, y = make_classification(n_samples=10000, n_features=5, n_informative=2,
n_redundant=0, class_sep = 2, random_state=SEED, shuffle=True,
flip_y=0.3, n_clusters_per_class=2)
В переменную SEED поместим целое значение сида, и инициализируем им объект np.random.RandomState. Теперь рассмотрим два случайных набора сплитов с заданным целым сидом и оценим качество классификаторов:
from sklearn.model_selection import ShuffleSplit
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
sp = ShuffleSplit(n_splits=3, random_state=SEED, test_size=0.25)
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y, cv=sp).mean())
print()
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y, cv=sp).mean())
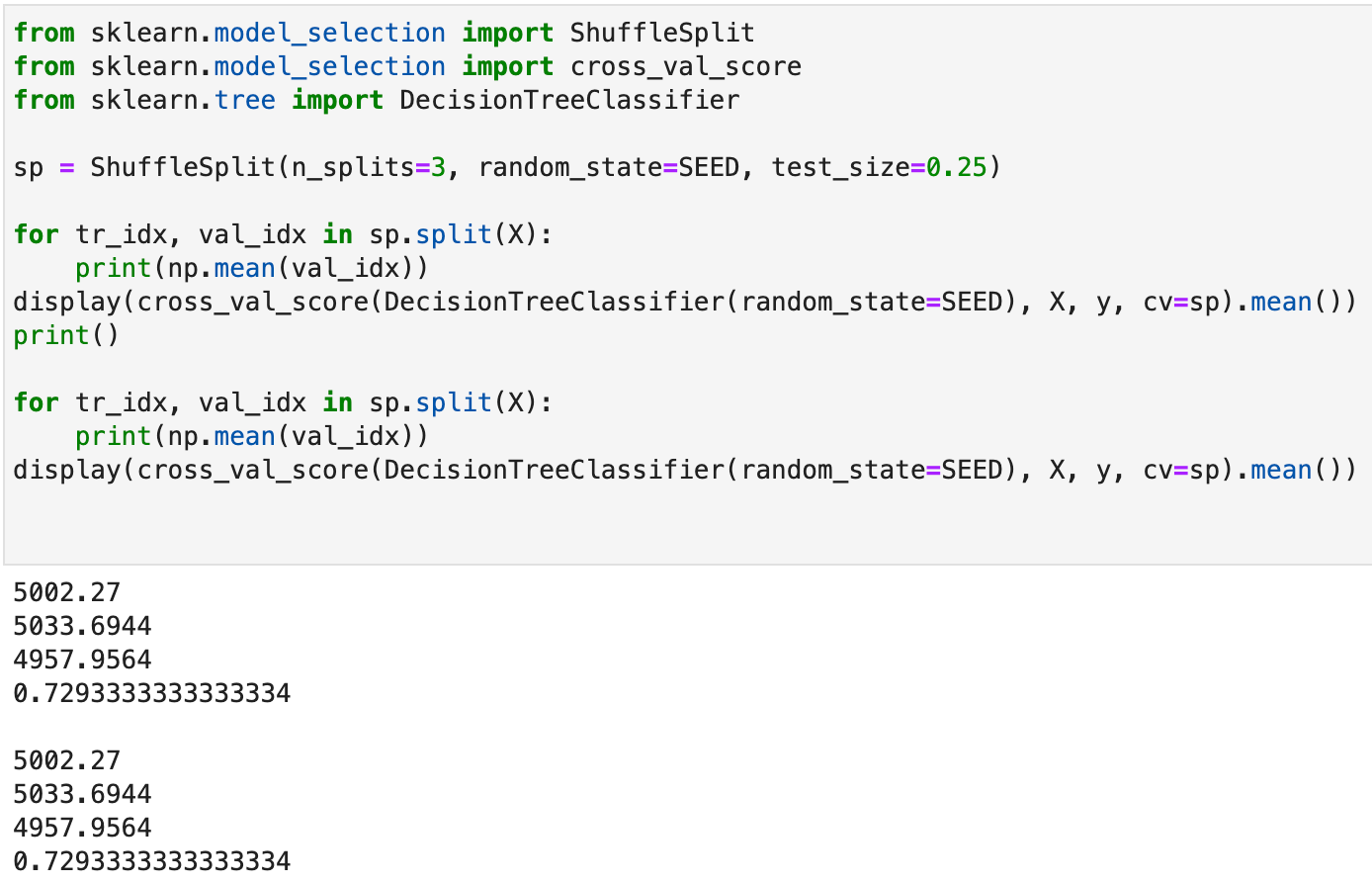
Чтобы убедиться в идентичности выборок, вывели среднее валидационных индексов в каждом сплите, а также результаты кросс-валидации одинаковых классификаторов.
Теперь проведем то же с сплиттером, инициализированным случайным генератором RNG, который меняет счетчик случайных чисел с каждым вызовом метода split в отличие от целого сида:
sp = ShuffleSplit(n_splits=3, random_state=RNG, test_size=0.25)
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y, cv=sp).mean())
print()
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y, cv=sp).mean())
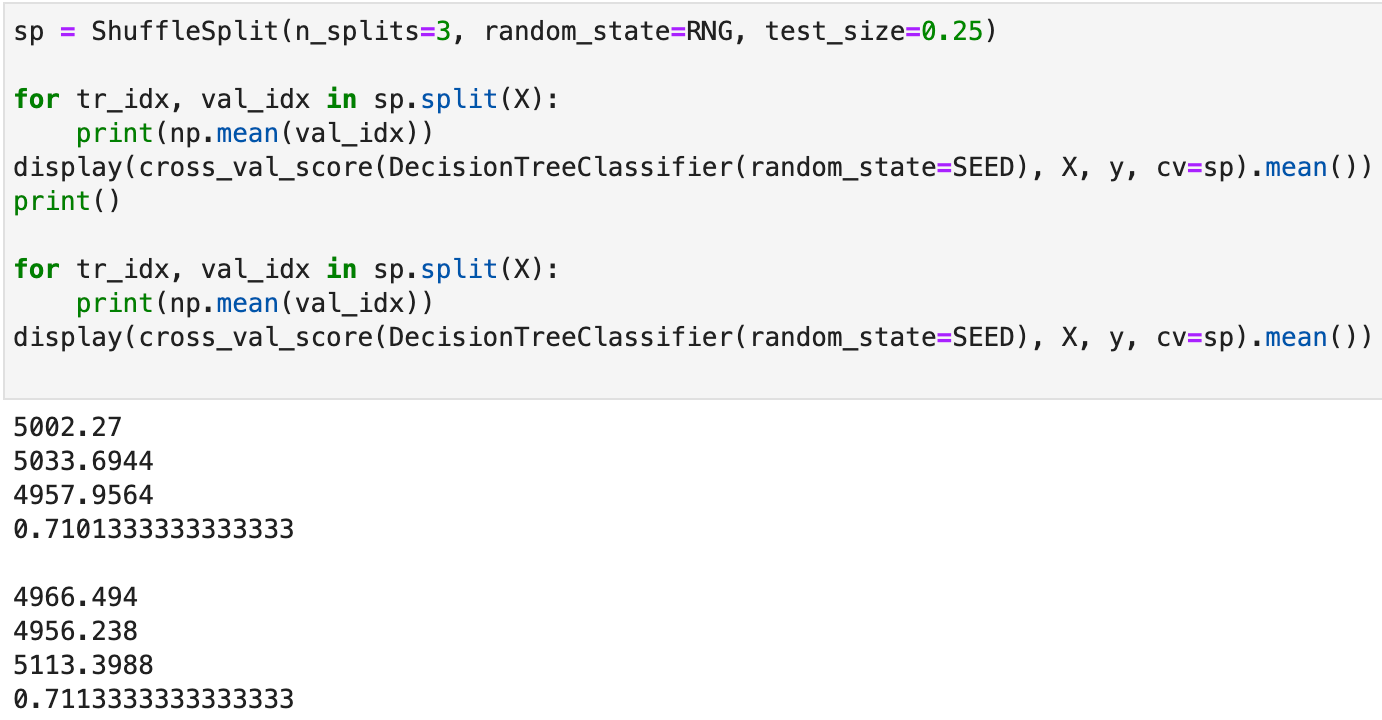
То есть наблюдается разница в сплитах и, несмотря на то, что модели абсолютно одинаковые, оценки кросс-валидации тоже разные.
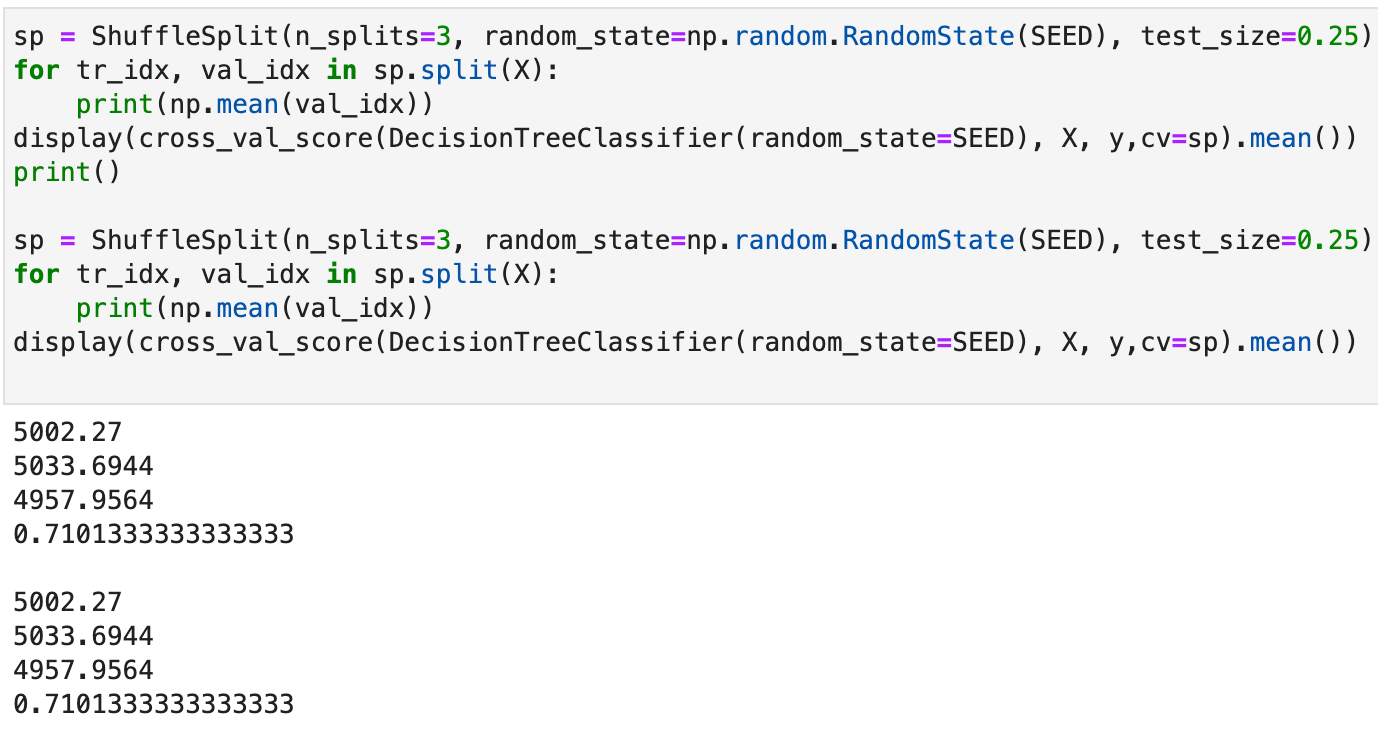
Замечу, если пересоздавать объект ShuffleSplit с np.random.RandomState с одним SEED, то результаты вновь станут одинаковые, так как эффект такой же, как при передаче целого (с пересозданием np.random.RandomState цепочка изменений счетчика случайных значений повторяется):
sp = ShuffleSplit(n_splits=3, random_state=np.random.RandomState(SEED), test_size=0.25)
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y,cv=sp).mean())
print()
sp = ShuffleSplit(n_splits=3, random_state=np.random.RandomState(SEED), test_size=0.25)
for tr_idx, val_idx in sp.split(X):
print(np.mean(val_idx))
display(cross_val_score(DecisionTreeClassifier(random_state=SEED), X, y,cv=sp).mean())