Успокоительный алгоритм для безошибочных прогнозов

Хочу поделиться алгоритмом, который позволяет выявить ошибки при правке прогнозов модели машинного обучения. Конечно, в расчет берется ситуация, когда вы не можете просмотреть все записи ввиду их большого количества.
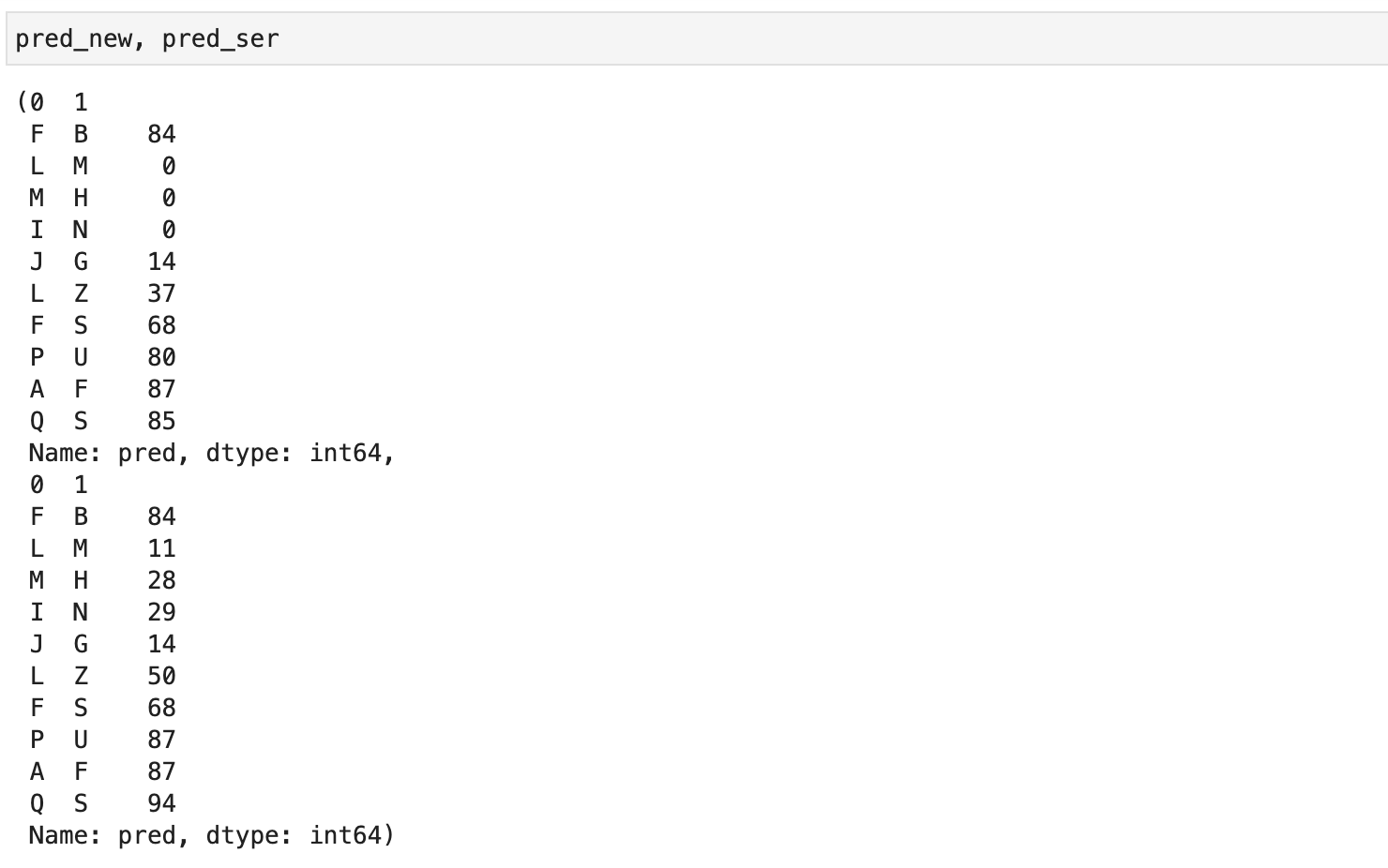
Для примера возьмем прогнозы потребности в товарах филиалов организации (pred) из предыдущей статьи и их скорректированные на величину резервов версии (pred_new). Как раз из соображений наглядности наши векторы маленькие, но алгоритм подходит для массивов любой величины:
pred_new, pred_ser
Для удобства сравнения я предварительно склеил два вектора прогнозов (функцией merge из библиотеки Pandas):
combo_df = pred_ser.reset_index().copy()
combo_df = combo_df.merge(pred_new.reset_index().rename(columns={'pred':'pred_new'}), how='outer')
combo_df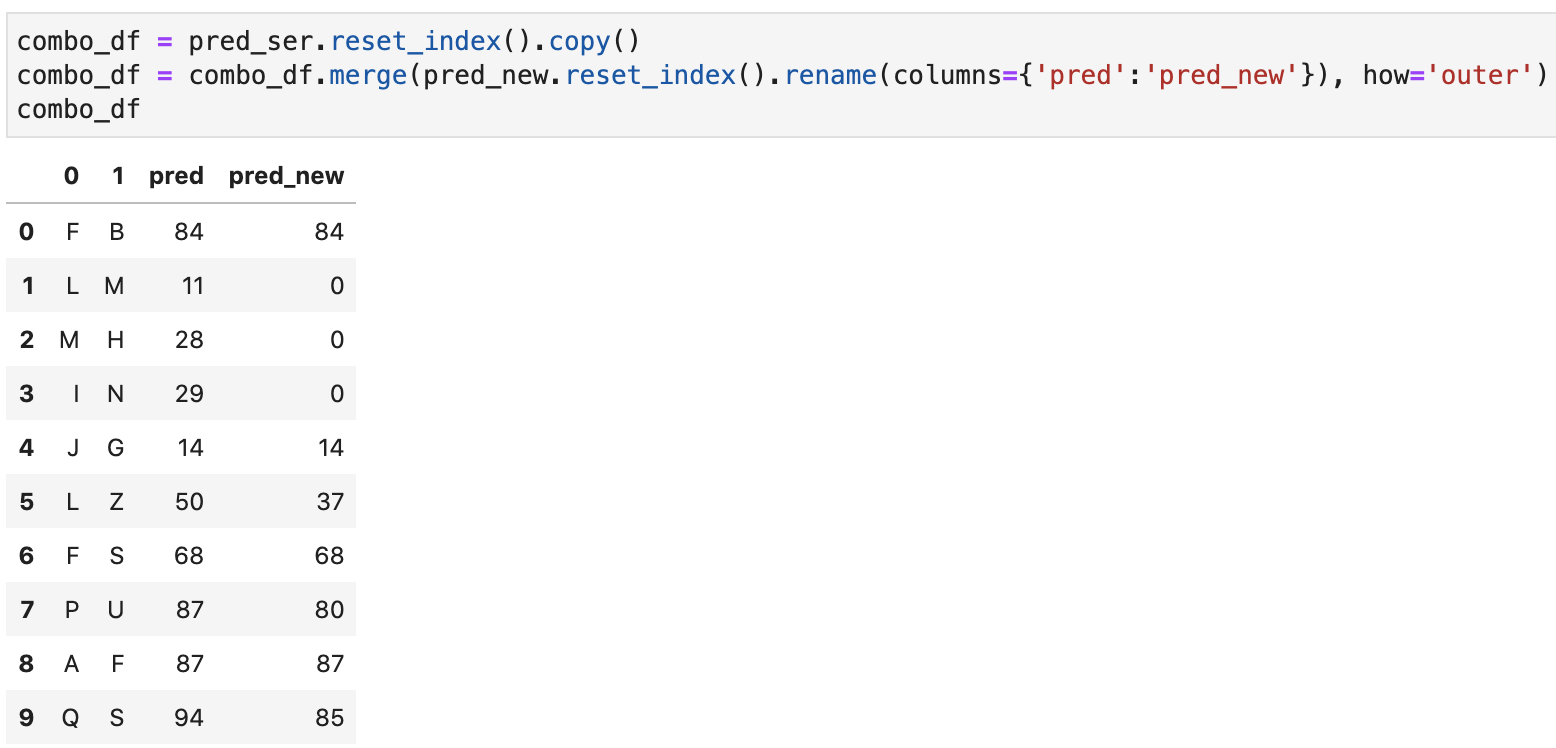
Затем осуществил следующую последовательность шагов:
1 Проверил, что новые предсказания не теряют значения (старые были, а новые не появились) и обратно (новые образованы, когда старых не было):
combo_df[(combo_df['pred_new'].isnull()) & (combo_df['pred'].notnull())] combo_df[(combo_df['pred'].isnull()) & (combo_df['pred_new'].notnull())]
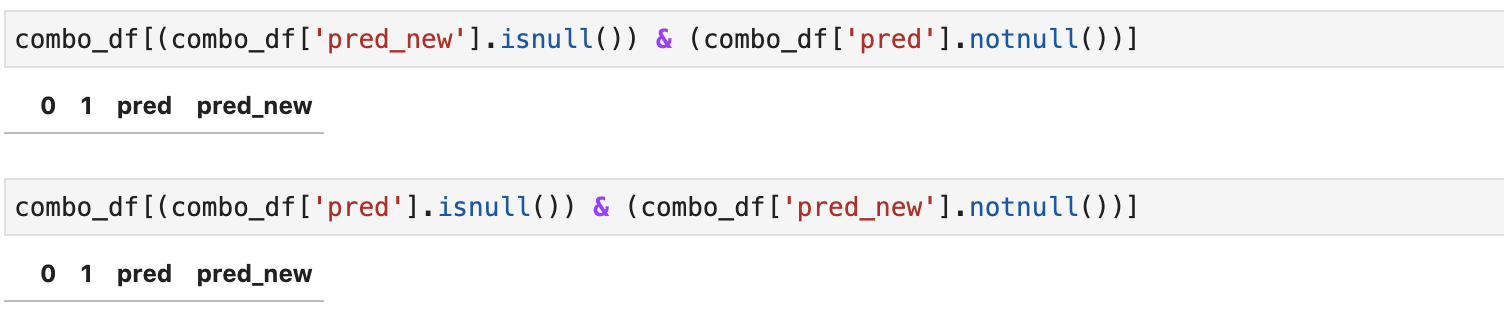
Следует отметить, что в зависимости от задачи данные ситуации не обязательно ошибочны. В данном случае они, прежде всего, должны привлечь ваше внимание.
2 Исключил ситуацию одновременных null значений и удостоверился, что в части данных значения совпадают, а в части - нет:
combo_df = combo_df[~((combo_df['pred_new'].isnull()) & (combo_df['pred'].isnull()))] combo_df[combo_df['pred_new'] != combo_df['pred']] combo_df[combo_df['pred_new'] == combo_df['pred']]
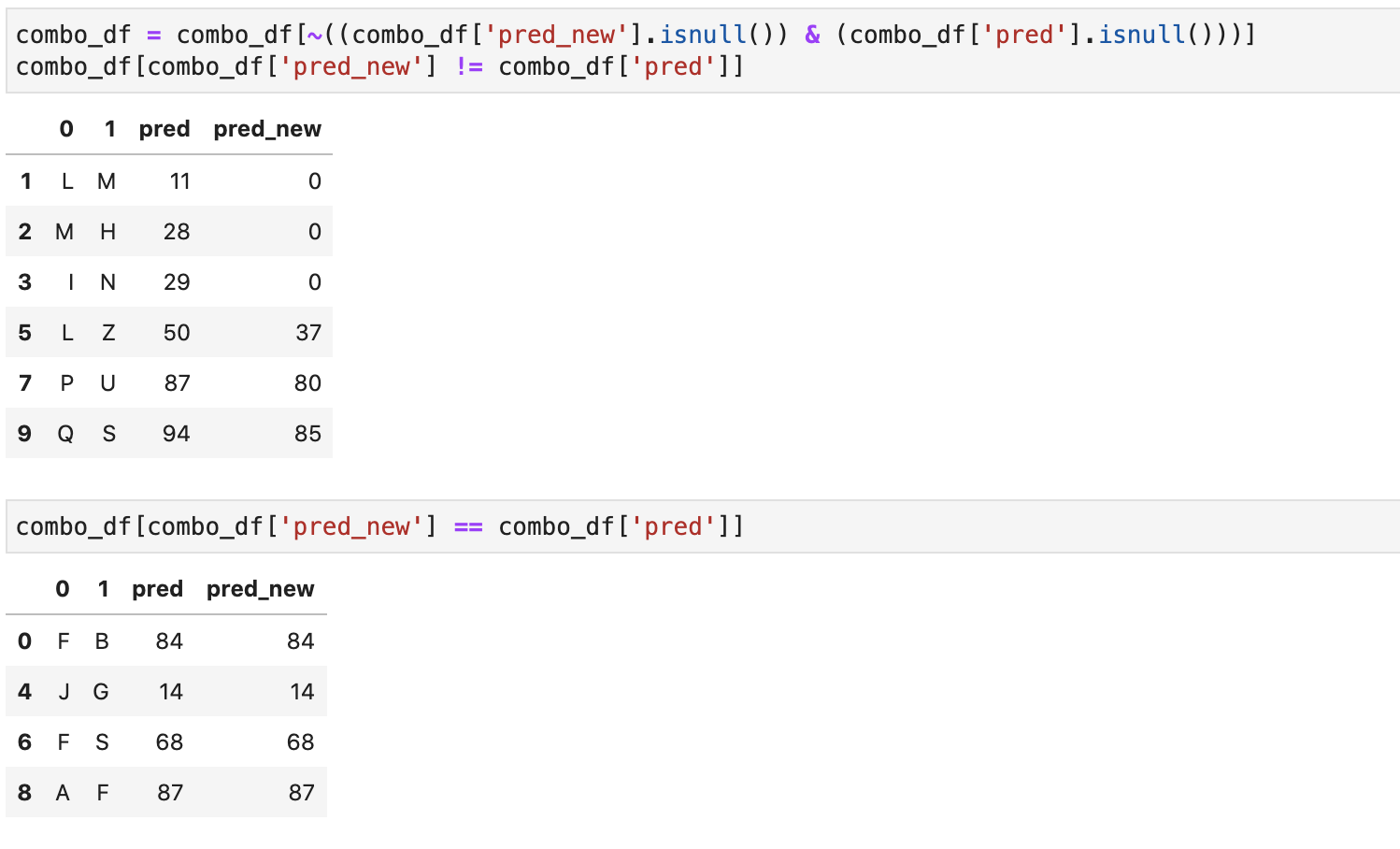
3 Дальше разбираемся в причинах именно таких значений.
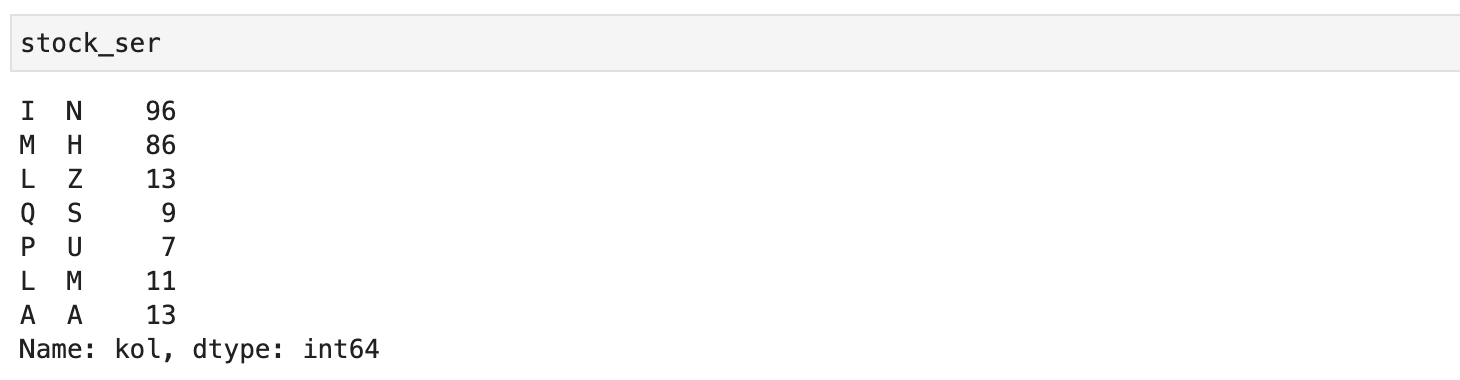
В данном случае значения должны были корректироваться при наличии резервов соответствующей позиции (хранятся в столбце stock_ser):
stock_ser
Склеиваем наш датафрейм с остатками для тех позиций, идентификаторы которых присутствуют в таблице прогнозов (остальные не нужны, так как не влияли на прогноз; по этой причине и используем левое объединение):
combo_df = combo_df.merge(stock_ser.reset_index().rename(columns={'kol': 'stock',
'level_0':0, 'level_1':1}), how='left')
combo_df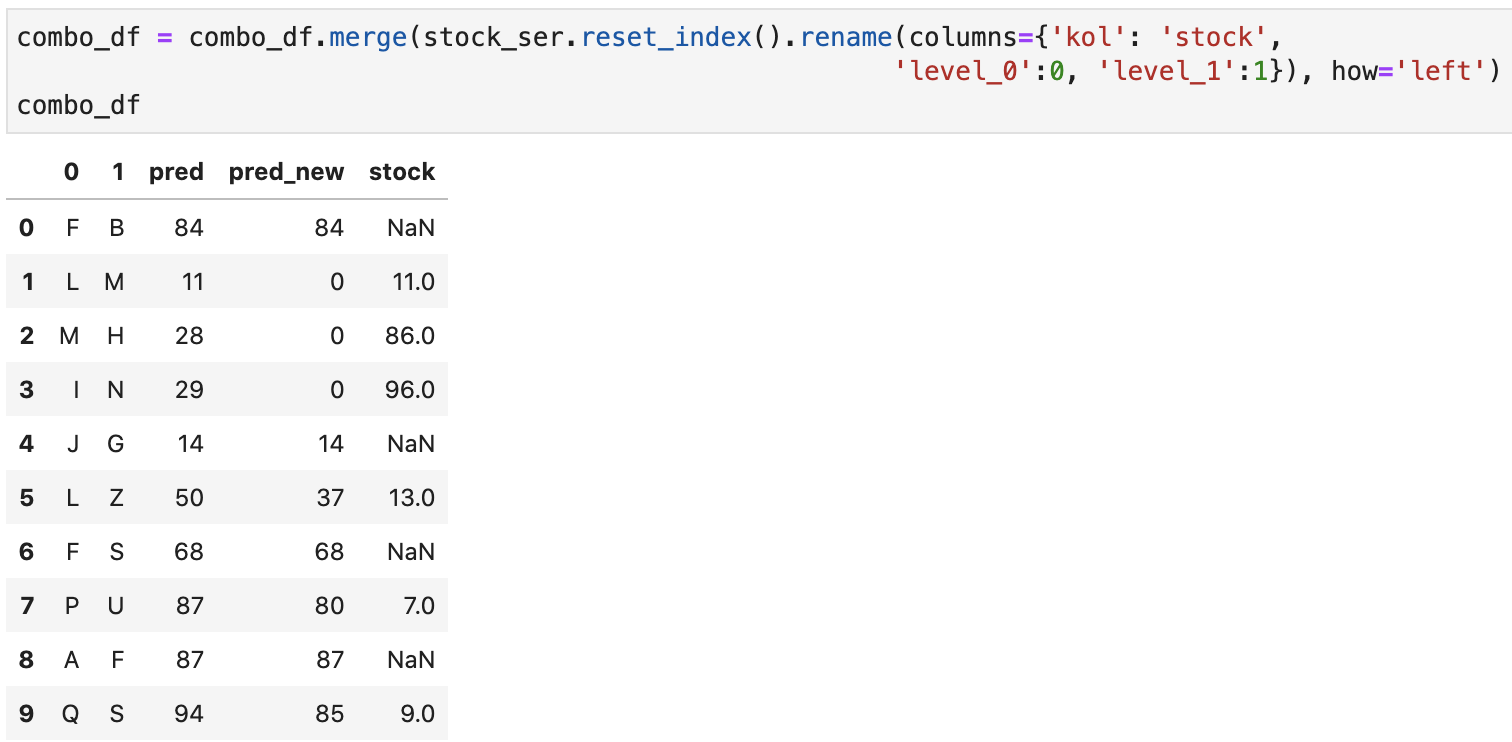
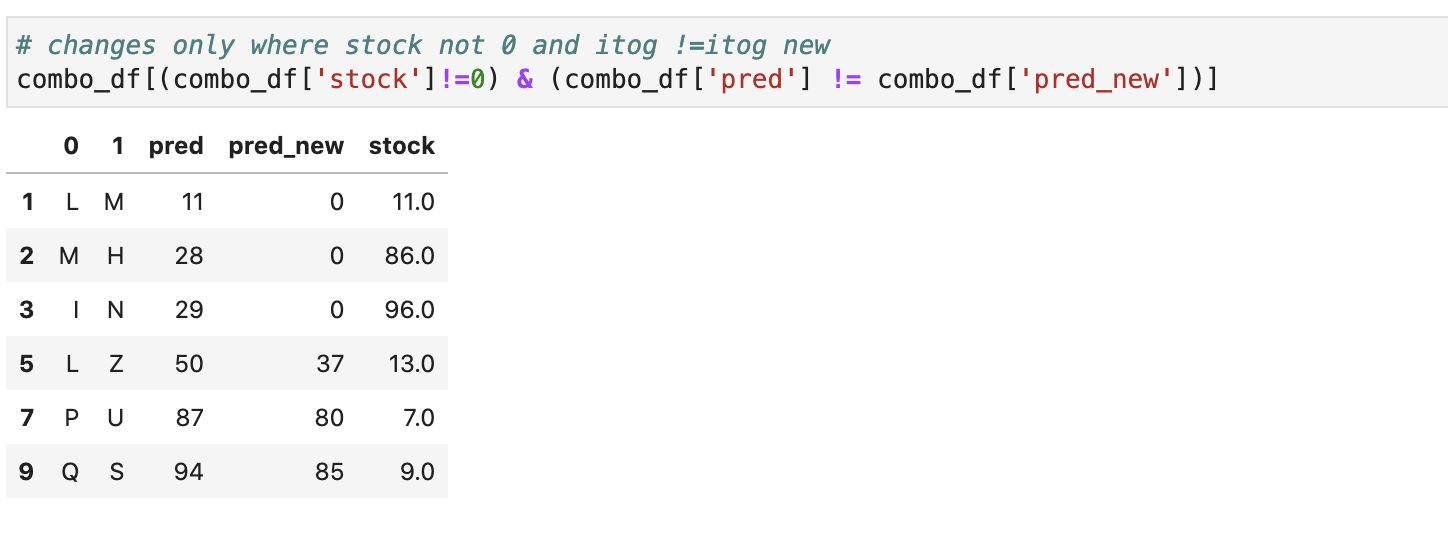
Убедимся, что изменения только в тех позициях, где есть остатки и их количество совпадает с численностью из вывода выше:
# changes only where stock not 0 and itog !=itog new combo_df[(combo_df['stock']!=0) & (combo_df['pred'] != combo_df['pred_new'])]
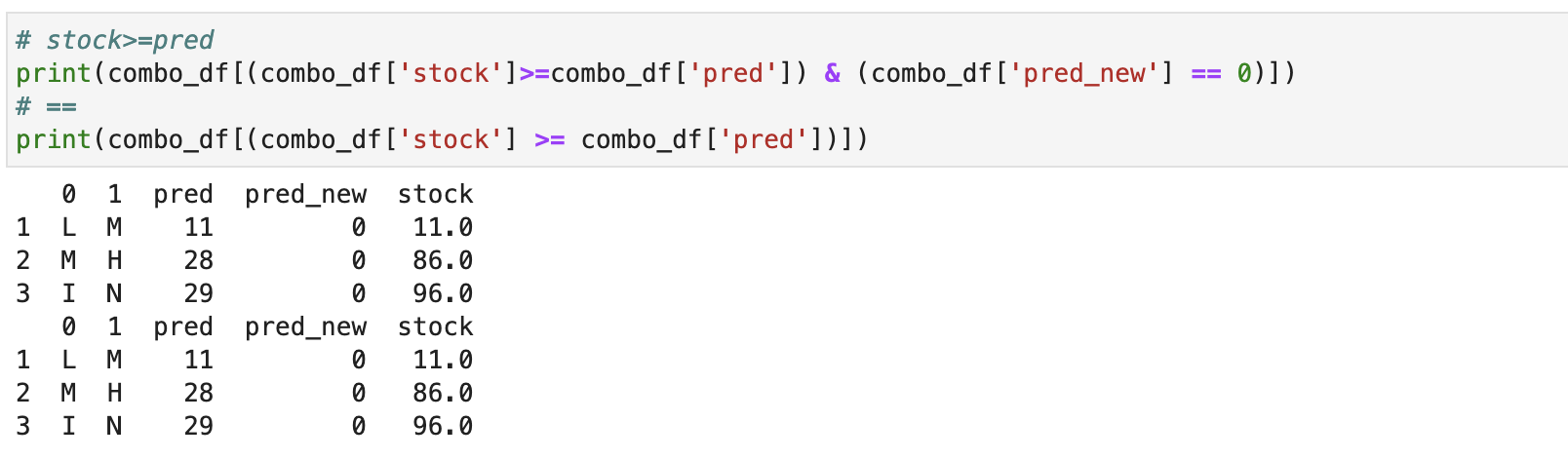
Дальше проверяем логику изменений:
где остатков больше чем прогноз, новый обнуляется (если данные большие, сравниваем таблицы по количеству записей):
print(combo_df[(combo_df['stock']>=combo_df['pred']) & (combo_df['pred_new'] == 0)]) # == print(combo_df[(combo_df['stock'] >= combo_df['pred'])])
где остатков меньше, новый прогноз равен разности:
# stock<pred print(combo_df[(combo_df['stock'] < combo_df['pred'])]) # == print(combo_df[(combo_df['stock'] < combo_df['pred']) & (combo_df['pred_new'] == combo_df['pred']-combo_df['stock'])])

Аналогичные стадии проверки осуществляются и в других ситуациях. Просто от случая к случаю логика может меняться, но в целом привлекать внимание должны присутствия где-то nan, равенства/неравенства значений.