Неочевидные способы подбора количества групп для агломеративной кластеризации

В этой задаче библиотека scikit-learn нам не поможет, поэтому обратимся к SciPy. Для начала следует воспользоваться функцией linkage из scipy.cluster.hierarchy, которая и проведет процесс кластеризации (ранее я разбирал ее работу). В третьей колонке она возвращает дистанцию между объединяемыми кластерами (из первого и второго столбцов). На ее основании можно и задать предельный порог, после которого дистанция считается существенной и кластера перестают объединяться:
from scipy.cluster.hierarchy import linkage
import pandas as pd
import numpy as np
X = np.array([[i] for i in [2, 8, 0, 4, 1, 9, 9, 0]])
cluster_ar = linkage(X, method='ward', metric='euclidean')
link_df = pd.DataFrame(cluster_ar, index=[f'clust {i+1}' for i,_ in enumerate(cluster_ar, start=cluster_ar.shape[0])],
columns=['cluster1', 'cluster2', 'dist', 'number elements'])
display(link_df)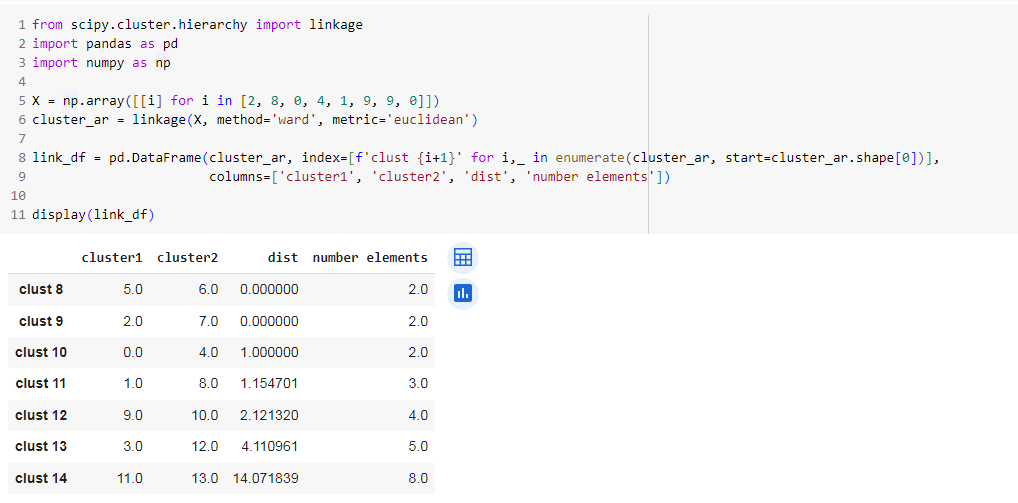
Мера дистанции
Имея результат linkage, можно применить функцию fcluster того же модуля для присвоения меток кластеров. Однако до этого под капотом она подбирает их количество в соответствии с пороговым значением t для дистанции при заданном параметре criterion='distance' (с дистанцией больше, чем порог, кластера не объединяются):
from scipy.cluster.hierarchy import fcluster labels = fcluster(link_df, t=1.5, criterion='distance') labels

Отмечу, что для подбора подходящего t удобно вывести гистограмму дистанций и квантили различного уровня с методами hist и quantile (например, link_df['dist'].quantile(.8)).
Мера "непоследовательности"
Ее можно использовать как альтернативу метрике дистанции между кластерами. Для подсчета используйте функцию inconsistent все того же модуля scipy.cluster.hierarchy. Она возвращает матрицу, в i-ой строке которой расположены средние и стандартные отклонения дистанций между кластерами (первые 2 колонки), начиная от заданного на d уровней вниз, количество связей (3 колонка) и сам коэффициент (4 столбец):
from scipy.cluster.hierarchy import inconsistent
inconsistency_df = pd.DataFrame(inconsistent(cluster_ar), index=[f'clust {i+1}' for i,_ in enumerate(cluster_ar, start=cluster_ar.shape[0])],
columns=['mean', 'std', 'num_links', 'coef'])
display(inconsistency_df)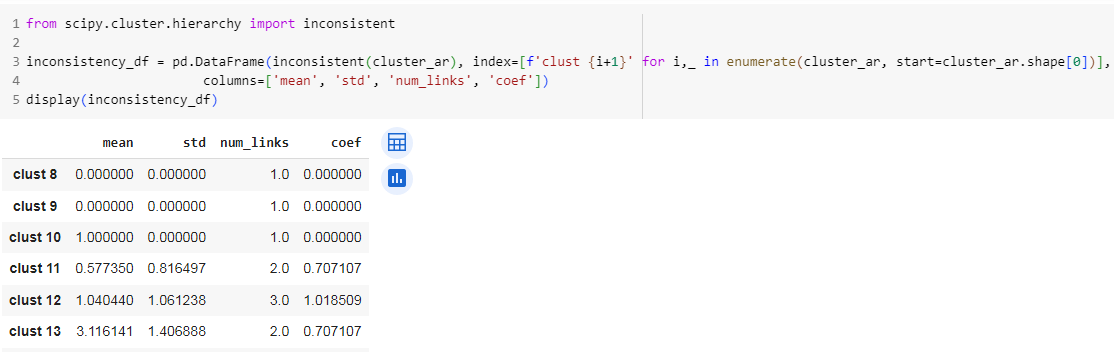
Коэффициенты считаются как разность дистанции для i-го кластера (Zi) и среднего, деленная на стандартное отклонение:

clust 11
Получен объединением кластеров 1 и 8 (из точек с индексами 5 и 6). Дистанция для clust 11 - 1.154701, у clust 8 - 0:

clust 12
получен объединением 9([2,7]) и 10 ([0,4])
z = 2.121320 mean_l = [z, 0, 1] np.mean(mean_l), np.std(mean_l, ddof=1), (z - np.mean(mean_l))/np.std(mean_l, ddof=1)

clust 14
Давайте пересчитаем меру с глубиной 3:
inconsistency_df = pd.DataFrame(inconsistent(cluster_ar, d=3), index=[f'clust {i+1}'
for i,_ in enumerate(cluster_ar, start=cluster_ar.shape[0])],
columns=['mean', 'std', 'num_links', 'coef'])
display(inconsistency_df)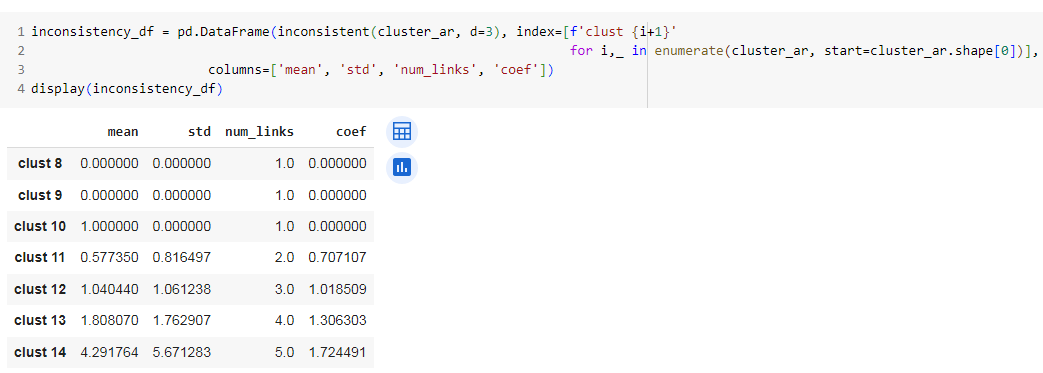
z = 14.071839 mean_l = [z, 4.110961, 1.154701, 0, 2.121320] np.mean(mean_l), np.std(mean_l, ddof=1), (z - np.mean(mean_l))/np.std(mean_l, ddof=1)

Теперь можно аналогично кластеризации с заданным порогом для дистанции, провести разбиение по мере "непоследовательности":
labels = fcluster(link_df, t=1.3, depth=3, criterion='inconsistent') labels
