Обзор Jamovi
При словосочетании «HR аналитика» чаще всего перед глазами людей возникают образы дашбордов, а большинство вакансий HR аналитиков изобилует требованиями к знаниям различных BI инструментов, впрочем, актуальность этих требований теперь не совсем ясна.
Дашборды, это конечно же не предел аналитики, некоторые эксперты могут сказать даже грубее – что это вовсе не аналитика. Не стану впадать в ту или иную крайность, но справедливости ради стоит заметить, что одних дашбордов и метрик явно недостаточно для аналитики.
Аналитика – это, прежде всего, выдвижение и проверка гипотез. И когда говорится проверка гипотез, имеется ввиду не только обзор информативных графиков, но и применение статистических инструментов.
Собственно, свой путь в профессию я могу начать отсчитывать ещё с психологического факультета, где мы выдвигали гипотезы, собирали данные, а потом применяли статистические критерии в программе StatSoft Statistica [1]. Кто-то знаком с более распространенным в российской академической среде пакетом IBM SPSS [2], с которым мне довелось поработать, будучи студентом экономического факультета.
Хочется сделать небольшое отступление и заметить, что на психфаке в моем родном ВУЗе, внимания статистике уделяли гораздо больше, чем на экономе и не один диплом не мог быть допущен до защиты без мат. статистического доказательства гипотезы. Этот факт всегда производит сильный эффект на людей, далеких от научной психологии, что она, в том числе, про математику и статистику, но могу сказать, что столь же сильный эффект этот факт производит на студентов психологов по всему миру, когда им становится об этом известно.
На вопрос с помощью какого инструмента все же лучше проверять гипотезы в корпоративной сфере я всегда уверенно отвечал, что лучше всего с помощью языка программирования R [3]. В этот момент может начаться холивар между сторонниками R и Python, но работая и с тем и с другим языком программирования, скажу, что каждый из них лучше подходит для разных задач, для статистики лучше и удобнее R.
Раньше главных доводов в пользу R против статистических пакетов было три:
- R, как и любой язык программирования - это крайне гибкая штука и не одно приложение, в котором существует только то, что создали разработчики, не сравнится по возможностям.
- У R есть большое сообщество энтузиастов по всему миру, которое расширяет и дополняет его день ото дня и для этого не нужно ждать релиза новой версии продукта.
- R бесплатен. В свое время, цена на IBM SPSS для корпоративного использования, добавила мне мотивации учить R.
Сейчас, конечно, главный довод в том, что иностранные вендоры покинули или покинут РФ.
Изучение R, как и любого другого языка программирования, требует времени, а если пользователь ранее не занимался никаким программированием, то потребуется ещё больше времени, усилий и преодоления фрустрации. Что, конечно не должно вас останавливать, ибо per aspera ad astra.
Беглый взгляд
Как-то раз в беседе с одним моим коллегой мы рассуждали на тему того, что было бы неплохо найти какой-то баланс между дорогостоящими (теперь или скоро недоступными) статистическими приложениями и таким хардкором как программирование. Признаю, что не всем пользователям стоит всё бросать и бежать погружаться с головой в программирование. Если вы не профессиональный аналитик и вам нужно проверять гипотезы с помощью статистики время от времени, то действительно стоить подыскать что-то промежуточное.
Таким промежуточным звеном может выступить пакет «Анализ данных» в Excel, который мы смотрели на примере корреляции в одном из моих предыдущих постов [4], но я давно планировал устроить краш-тест Jamovi [5], что мы с вами сегодня и сделаем.
Jamovi – это статистический пакет с открытым исходным кодом, который распространяется бесплатно. Приложение основано на языке R, но в отличие от него не требует навыков программирования, так как имеет графический интерфейс.
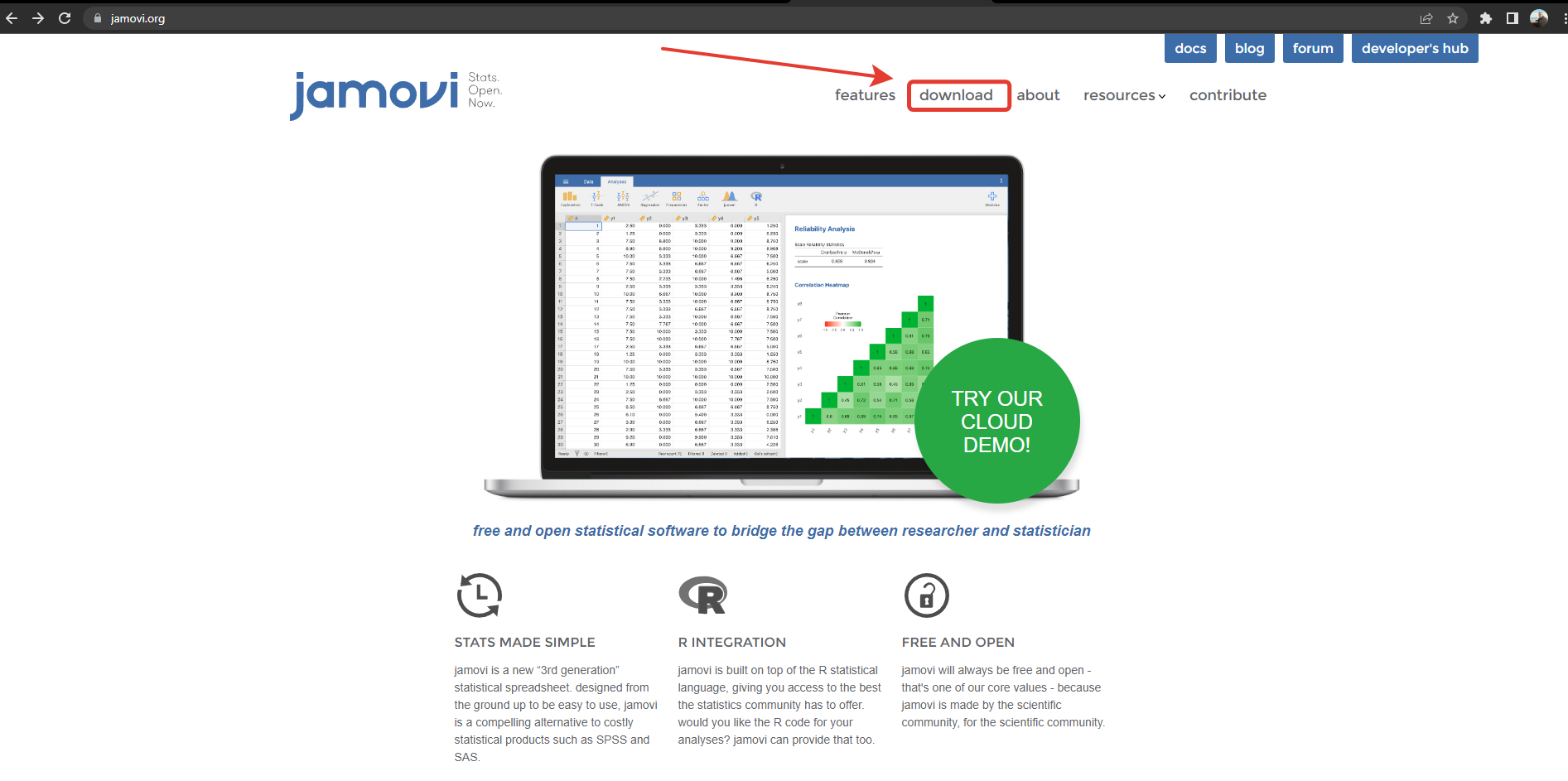
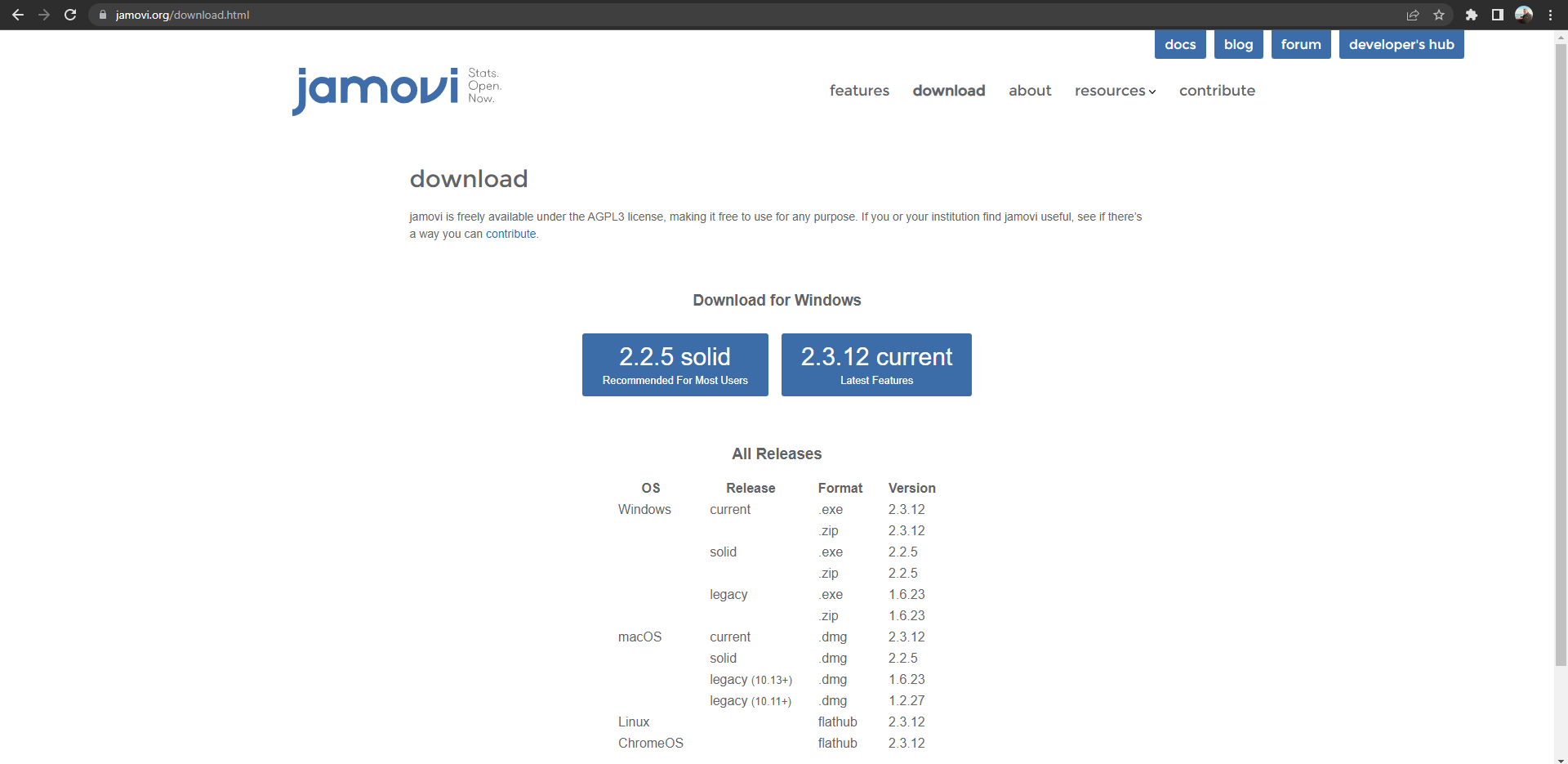
Первым делом скачиваем и устанавливаем Jamovi на свой компьютер с сайта https://www.jamovi.org/
Запуская приложение, сразу бросается в глаза схожесть иконок с IBM SPSS, что, возможно, сделано намерено, для плавного перехода пользователей.
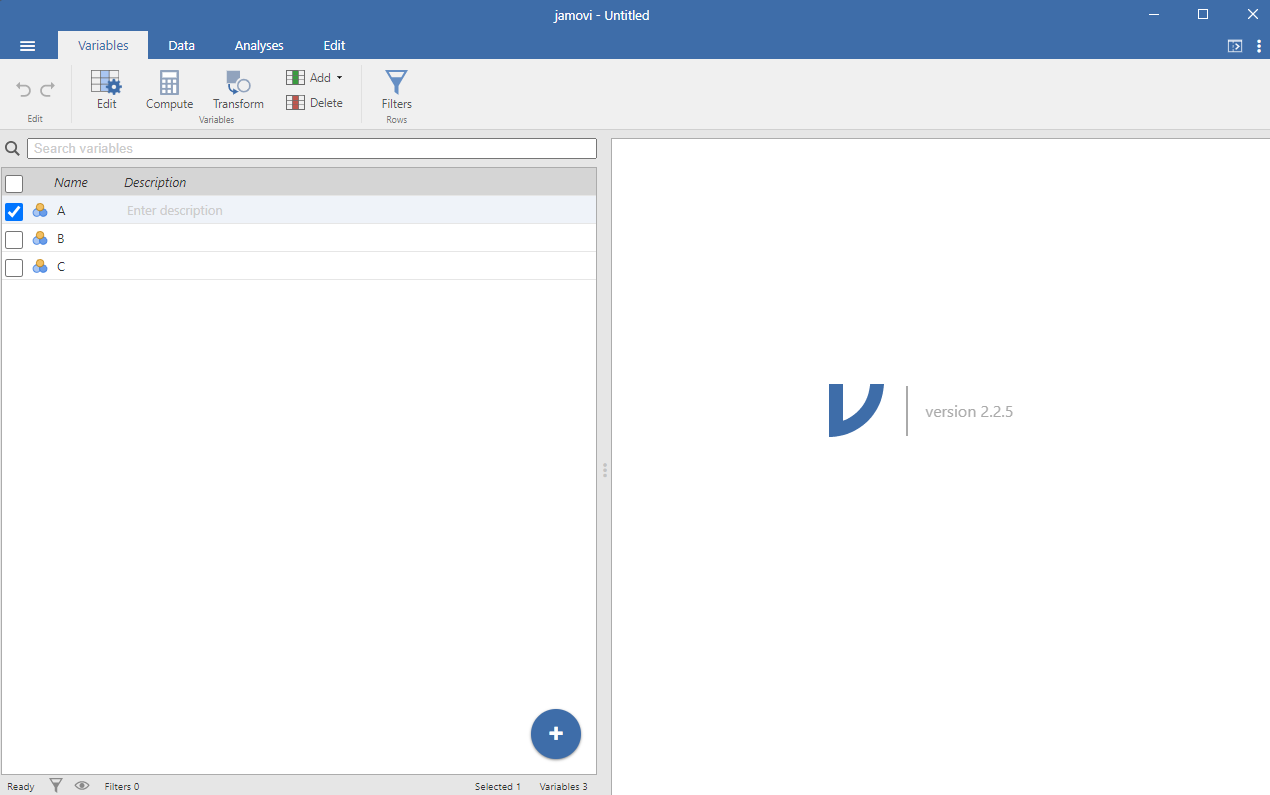
У приложения 4 основных вкладки на верхней панели:
1. Variables (переменные), где задаются названия, типы и форматы переменных, фильтры и прочее. Так, как мы это делали бы в IBM SPSS или StatSoft Statisitca.
2. Data (данные), здесь можно самим вводить данные в ячейки, прямо-таки как в Excel. Но мы загрузим наши данные далее в практической части другим способом.
3. Analyses (анализ), где нас ожидают: разведывательный анализ, T-тест, дисперсионный анализ, регрессия, анализ частот и факторный анализ.
Я поначалу удивился, неужели только параметрическая статистика доступна? Оказалось не совсем так: в Т-тесте мы можем обнаружить галки для теста Манна-Уитни, а раскрыв ANOVA (дисперсионный анализ) найдем его непараметрический аналог – критерий Крускала-Уоллиса.
4. Edit (редактирование) с помощью этой вкладки мы можем довести до ума подготовленный по результатам анализа отчёт.
Jamovi верен духу R, на котором создана программа – пользователь может установить дополнительные модули, которые расширяют возможности анализа, в частности, есть модули с анализом дожития, моделями пути и многим другим. Для нашего тестового заезда мы ограничимся стандартными возможностями.
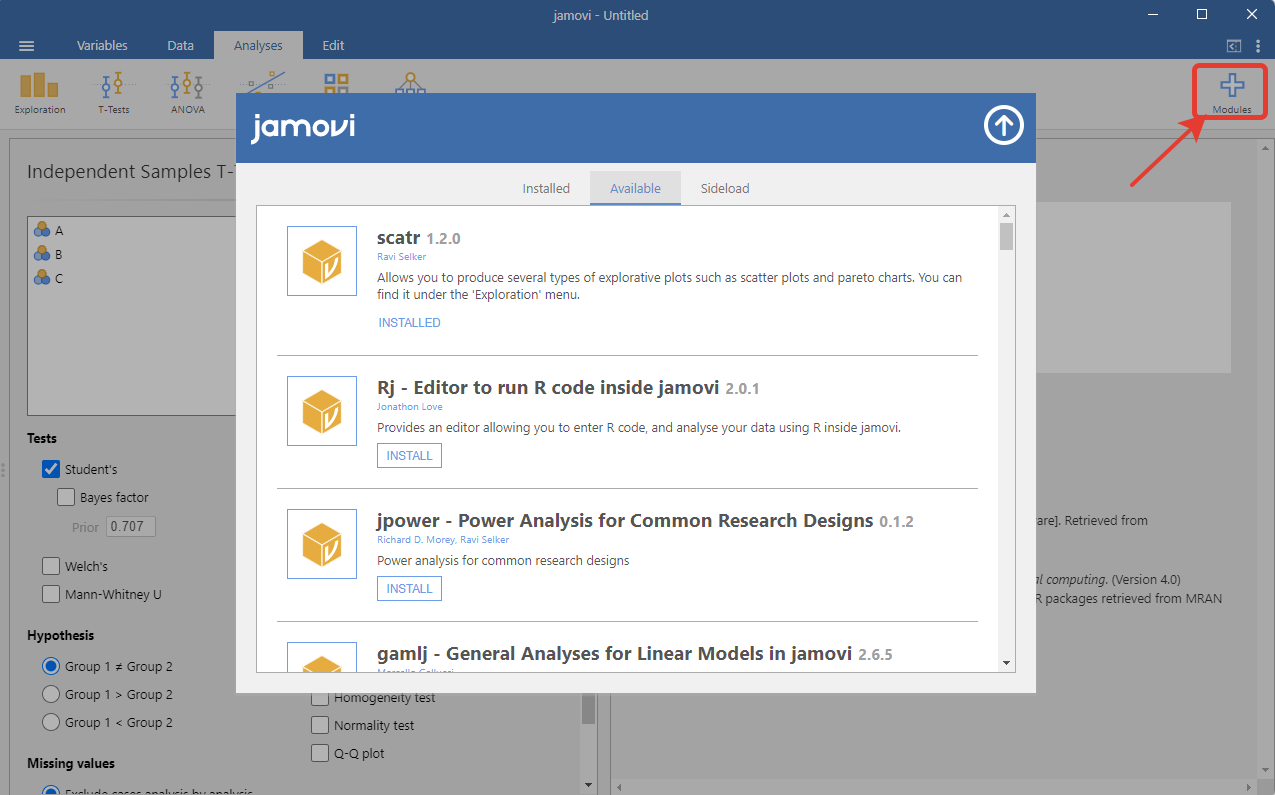
Дописав до этого места, я полон осознания, что далеко не все мои читатели так хорошо знакомы со статистикой и всё, что я перечислял до этого было понятно. Я, думаю, что это задел на будущее, пока верьте мне на слово, возможно, я освещу критерии и виды анализа со временем подробнее. В частности, сегодня мы применим один из статистических критериев, но без глубоких пояснений о нём, так цель поста - осветить ПО.
Практика
Для практики я взял этот набор данных в формате csv с Kaggle [6]. Открываем данные в Jamovi, что делается достаточно просто, как в любом Windows приложении таком как Word или Excel.
Данные загружены и выглядят похоже на привычный Excel формат. Jamovi очень хорошо сам понимает формат переменных, так он сам увидел числа и тексты. Интересно, что бинарные переменные и переменные с несколькими числами, он сразу воспринял как факторы, чем сэкономил пользователю время.
В этом наборе данных следующие переменные:
- satisfaction_level – уровень удовлетворенности.
- last_evaluation – последняя оценка.
- number_project – кол-во проектов.
- average_montly_hours – среднее кол-во часов в месяц.
- time_spend_company – время в компании.
- Work_accident – несчастные случаи .
- Left – увольнение (0 или 1).
- promotion_last_5years – повышение за последние 5 лет.
- sales – в данном случае, имеется ввиду подразделение.
- salary – заработная плата.
Пока мы с вами ничего не знаем об этих переменных, кроме их названий и нам бы хотелось начать с разведывательного анализа (Exploration).
Получить описательные статистики можно очень просто и быстро, перекидываем все наши переменные в окно Variables и в тот же момент получаем отчёт. Мне кажется, что так быстро я не получал этого результата прежде нигде.
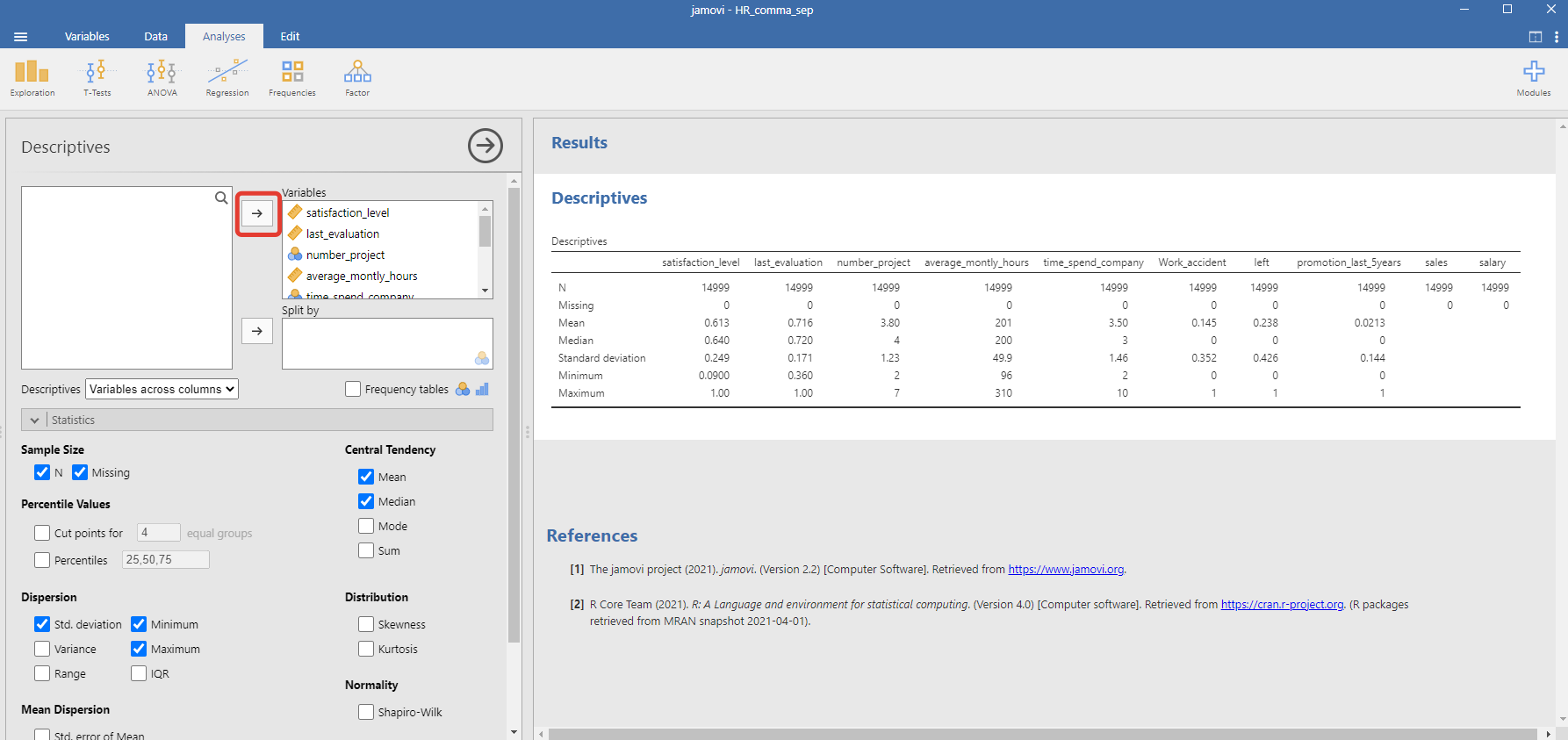
Видим, что в нашем наборе данных почти 15 тысяч наблюдений, нет пропусков в данных, для числовых переменных получили среднее, медиану, стандартное отклонение, минимум и максимум. Но это не предел, мы можем с помощью галок слева включить дополнительные расчёты, в том числе тест Шапиро-Уилка на нормальность распределения переменных.
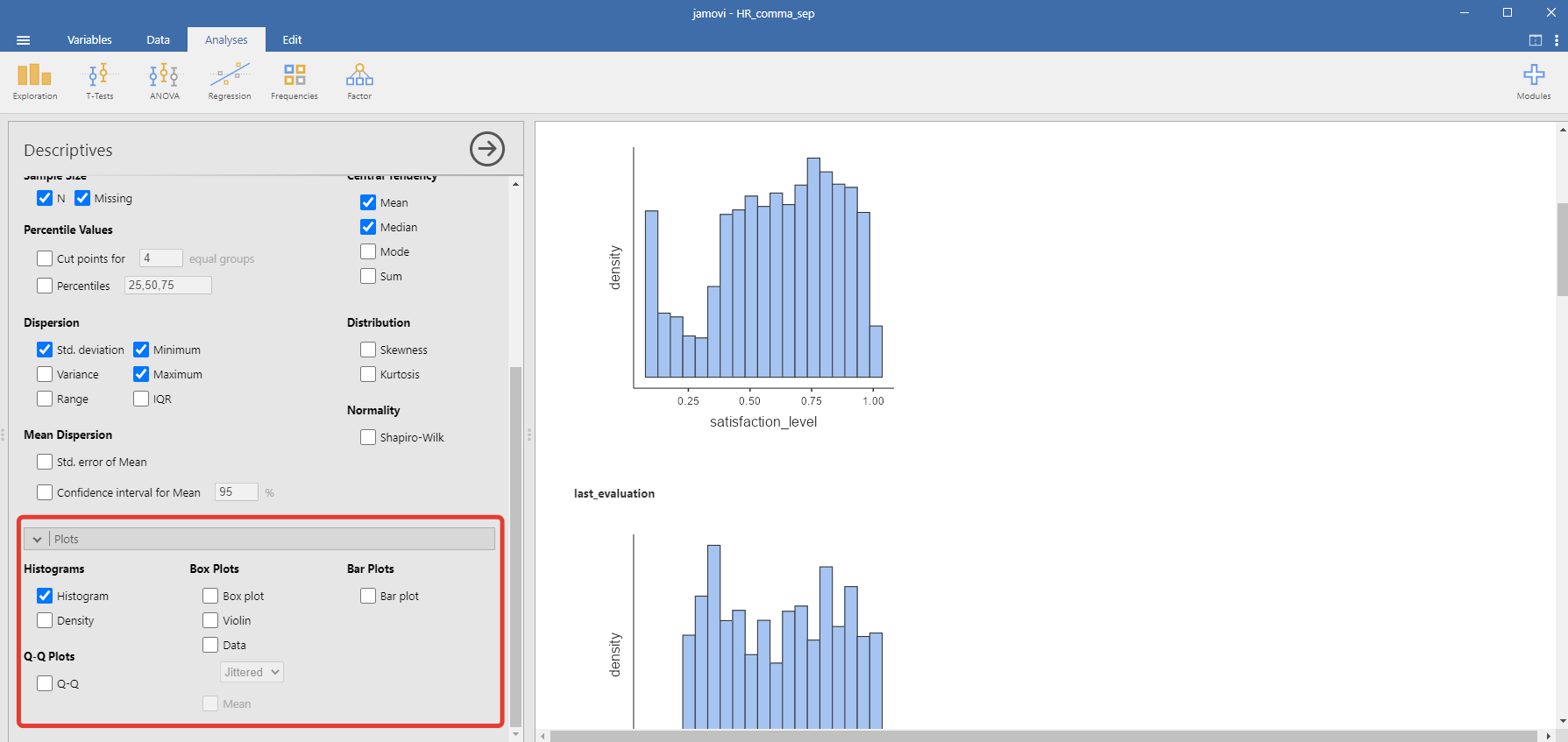
Что ещё важнее, мы можем сразу построить графики, а какой может быть анализ данных без графиков? В этот момент вновь можно оценить экономию времени, поставив галку «Гистограмма» мы тут же получаем графики для всех наших переменных.
Пора заняться HR аналитикой, представим, что мы хотим узнать, какие факторы влияют на принятие решения об увольнении. Возьмем в качестве подозреваемого фактора, крайне популярную в HR - удовлетворенность (satisfaction_level в наших данных).
- Наша нулевая гипотеза (H0): уровень удовлетворенности для уволенных и продолжающих работать не имеет отличий.
- Альтернативная гипотеза (H1): уровень удовлетворенности у уволенных ниже, чем у продолжающих работать.
И вновь дана разгадка названия моего канала - H0 и H1 это традиционное обозначение двух конкурирующих гипотез в статистике.
Как видите альтернативная гипотеза (H1) у нас односторонняя, нам, как HR аналитикам, интересно найти ответ на вопрос связана ли удовлетворенность и увольнения, тем образом, что чем она меньше, тем больше увольнений.
По гистограмме уровня удовлетворенности мы предполагаем, что данные далеки от нормального распределения (как это бывает зачастую в практике) и мы будем применять непараметрические критерии, а именно критерий Манна-Уитни.
Для этого выбираем T-тест для независимых выборок (Independent Samples T-Test) в Jamovi (это, конечно, контринтуитивно).
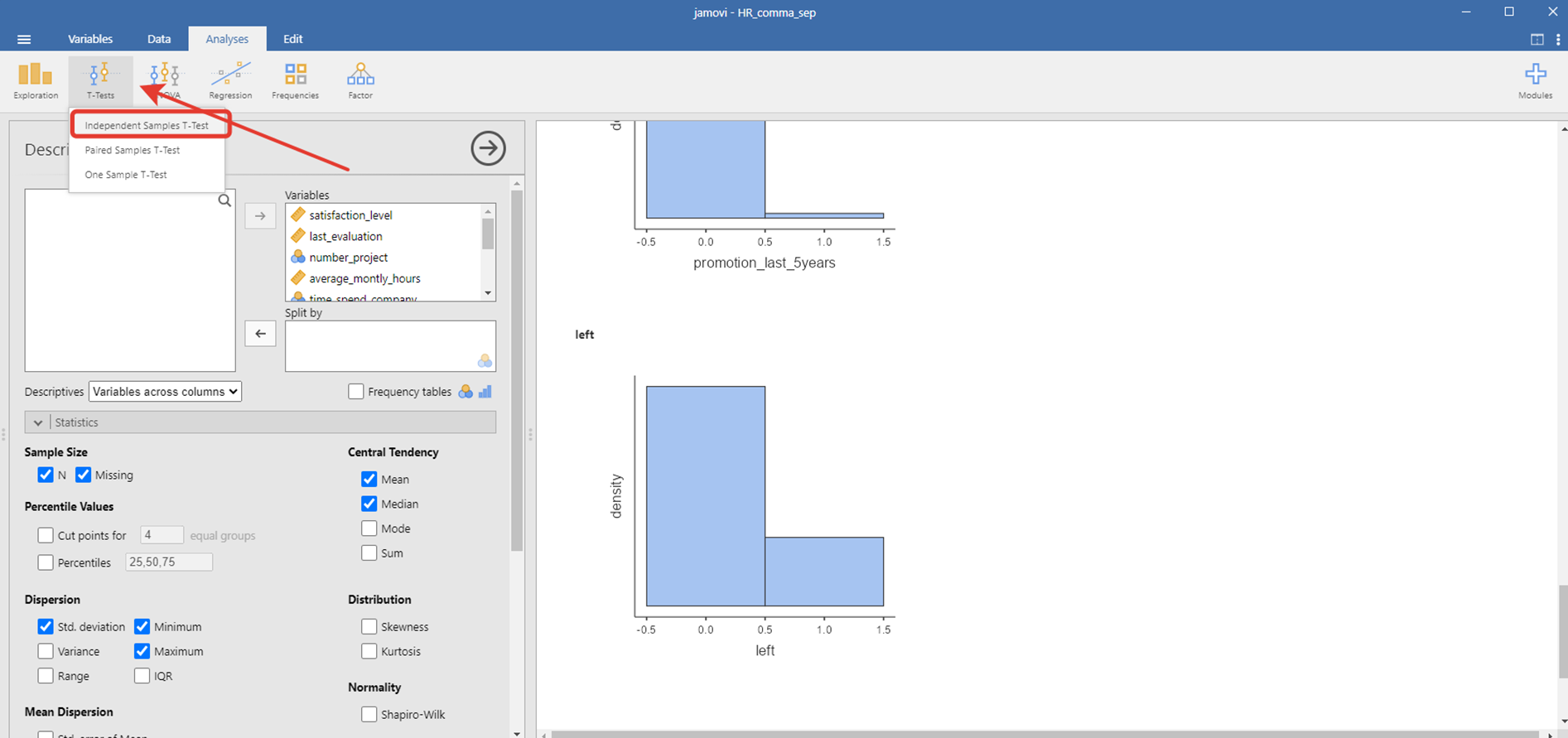
В открывшемся окне переносим уровень удовлетворенности (satisfaction_level) в поле зависимой переменной (Dependent Variables), увольнения (left) передаём в поле группирующей переменной (Grouping variable). Ниже ставим галки, что мы хотим применить U-тест Манна-Уитни (Manna-Whitney U), что наша гипотеза односторонняя (в данном случае первая группа 0 – это работающие, а вторая 1 – это уволенные, следовательно Group 1 > Group 2) и даже можем сразу поставить галку для расчёта размера эффекта (Effect size)!
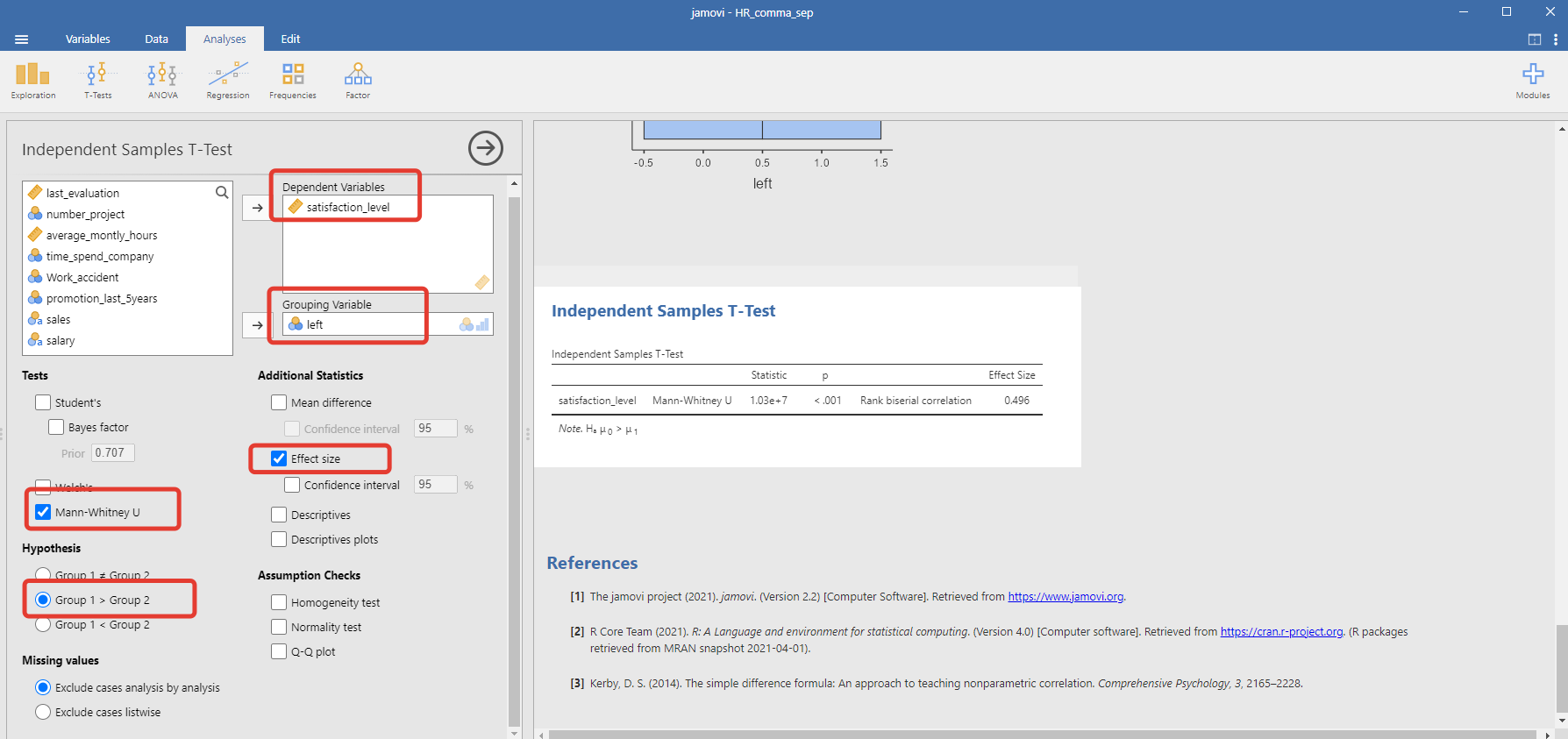
В окне справа сформировался отчёт, делаем вывод: на уровне статистической значимости (p < 0.001) мы можем отвергнуть нулевую гипотезу в пользу альтернативной.
Теперь тоже самое, но человеческим языком: мы можем говорить, что между уволенными и продолжающими работать есть статистическая разница в уровне удовлетворенности.
Следующий вопрос, насколько эта разница велика? Помогает нам на это ответить размер эффекта, для критерия Манна-Уитни это коэффициент рангово-бисериальной корреляции. В нашем примере он равен 0.496. Это много или мало? Этот коэффициент также лежит в интервале от [-1, 1] и такой результат принято считать умеренным эффектом, хотя мы помним условность таких категоризаций. Про корреляцию можно почитать мой пост.