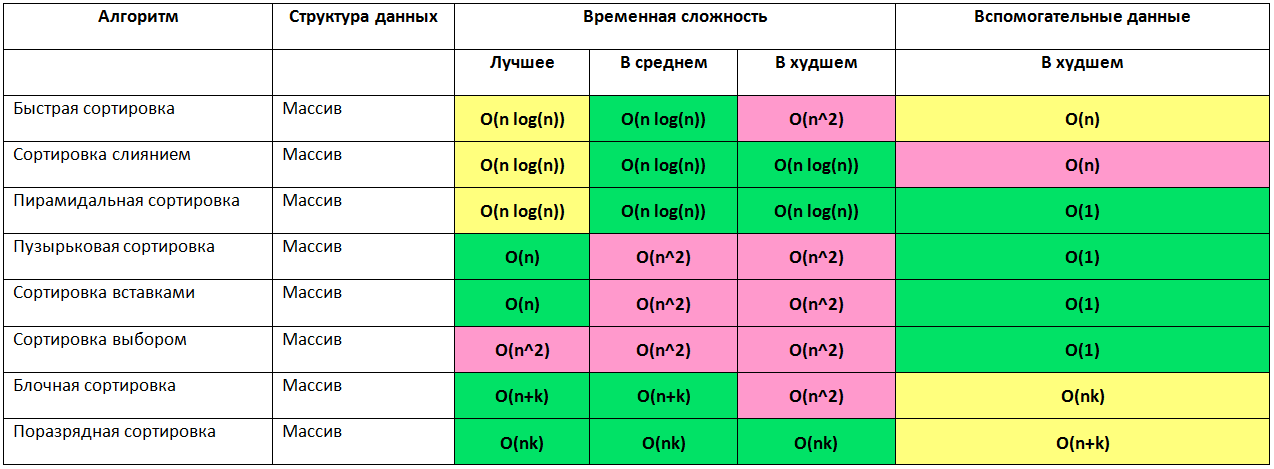
Быстрая сортировка
QuickSort - наиболее известная среди алгоритмов сортировки, разарботанная в 1960году математиком Чарльзом Харном. В лучшем случае оценка сложности Ω(n*log(n)), в худшем может деградировать до O(n^2).
Алгоритм построен на принципе "разделяй и влавствуй". Сама концепция алгоритма давольно простая и выглядит следующим образом:
- В начале выбирается "опорный" элемент. Это может быть любое элемент, но от выбора этого выбора сильно зависит эффективность алгоритма. Если нам известна медиана, то лучше выбирать элемент, который как можно ближе к медиане.
- Запускается цикл, в котором все элементы меньшие, либо равные, выбранному опорному элементу, перемещаются влево от него, а все большие вправо.
*В питоновской реалзацие, в предыдущем посте, я создал три листа для хранения соответствующих элементов, но сути это не меняет. - Для левого и правого массива, если в них больше одного элемента, действия повторяются рекурсивно. По итогу рекурсии получаем отсортированный массив.

Классическая реализация алгоритма выглядит следующим образом:
int partition(a: T[n], int l, int r)
T v = a[(l + r) / 2]
int i = l
int j = r
while (i ⩽ j)
while (a[i] < v)
i++
while (a[j] > v)
j--
if (i ⩾ j)
break
swap(a[i++], a[j--])
return jvoid quicksort(a: T[n], int l, int r)
if l < r
int q = partition(a, l, r)
quicksort(a, l, q)
quicksort(a, q + 1, r)Худшее время работы
Предположим, что мы разбиваем массив так, что одна часть содержит n − 1 элементов, а вторая 1. Поскольку процедура разбиения занимает время Θ(n), для времени работы T(n) получаем соотношение:
T(n) = T(n−1) + Θ(n) = Θ(n^2)
В частности, это происходит, если массив изначально отсортирован.
В своих алгоритмах быстрой сортировки я всегда в качестве опорного выбираю элемент, который стоит в середине рассматриваемого массива.
Рассмотрим массив, на котором быстрая сортировка с выбором среднего элемента в качестве опорного сделает Θ(n^2) сравнений. Очевидно, что это будет достигаться при худшем случае (когда при каждом разбиении в одном массиве будет оказываться 1, а в другом n−1 элемент).
Заполним сначала массив a длины n элементами от 1 до n, затем применим следующий алгоритм (нумерация с нуля):
void antiQsort(a: T[n])
for i = 0 to n - 1
swap(a[i], a[i / 2])
Тогда на каждом шаге в качестве среднего элемента будет ставиться самый крупный элемент.
При выполнении partition делается Θ(n) сравнений из-за того, что с помощью индексов i и j мы проходим в лучшем случае Ω(n) элементов (если функция прекращает свою работу, как только индексы встречаются), в худшем случае O(2n) элементов (если оба индекса полностью проходят массив). При каждом изменении индекса делается сравнение, значит, процедура partition делает Θ(n) сравнений с точностью до константы.
Рассмотрим, какой элемент будет выбираться опорным на каждом шаге. antiQsort на каждом шаге меняет местами последний и центральный элементы, поэтому в центре оказывается самый крупный элемент. А partition делает абсолютно симметричные этой процедуре операции, но в другую сторону: меняет местами центральный элемент с последним, так что самый крупный элемент становится последним, а затем выполняет на массиве длины на один меньшей ту же операцию. Получается, что опорным всегда будет выбираться самый крупный элемент, так как antiQsort на массиве любой длины будет выполнять операции, обратные partition. Фактически, partition — это antiQsort, запущенная в другую сторону. Также стоит отметить, что процедура разбиения будет делать на каждом шаге только одну смену элементов местами. Сначала i дойдет до середины массива, до опорного элемента, j останется равным индексу последнего элемента. Затем произойдет swap и i снова начнет увеличиваться, пока не дойдет до последнего элемента, j опять не изменит свою позицию. Потом произойдет выход из while.
Разбиение массива будет произведено Θ(n) раз, потому что разбиение производится на массивы длины 1 и n−1 из-за того, что на каждом шаге разбиения в качестве опорного будет выбираться самый крупный элемент (оценка на худшее время работы доказана выше). Следовательно, на массиве, который строится описанным выше способом, выполняется Θ(n)partition и Θ(n) сравнений для каждого выполнения partition. Тогда быстрая сортировка выполнит Θ(n^2) сравнений для массива, построенного таким способом.