Timsort

Timsort - это стабильный метод сортировки, о котором, по неясной причине, мало кто знает.
Timsort был разработан в 2002 году Тимом Петерсом для использования в python по причине того, что большинство алгоритмов сортировки просто не предназначены для практического применения на больших объемах данных. С тех пор алгоритм стал дефолтным методом сортировки сначала в python, а позднее в Java и Android JDK, а также в GNU Octave.
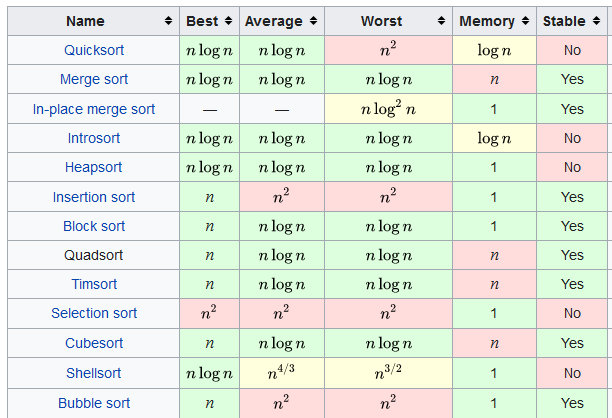
Timsort - это гибридный алгоритм, состоящий из шаблонов сортировок InsertionSort и MergeSort и использующий внутреннюю логику для манипулирования большими массивами данных.
Благодаря данной комбинации, при работе с частично отсортированными массивами алгоритм способен работать за Ω(n) сравнений, что значительно лучше, чем сортировки слиянием и быстрой сортировки. При работе же на случайных массивах Timsort, как и Merge, стабилен и работает за O (n log n).
Идея алгоритма
Давайте обратимся к общему виду алгоритма:
- Вычисляется размер частей
min_run; - Входной массив делится на подмассивы фиксированной длинны равной min_run;
- Каждый подмассив сортируется сортировкой вставками;
- Отсортированные подмассивы склеиваются сортировкой слиянием.
Тим Петерс разрабатывал Timsort для использования на массивах с уже упорядоченными подмассивами элементов, которые существуют в большинстве реальных наборов данных. Поэтому изначально массив делится на части. Он называл эти уже упорядоченные подмассивы «естественными пробегами».
Алгоритм
Рассмотрим более детально каждый шаг алгоритма.
1) Если массив, который мы пытаемся отсортировать, содержит менее 64 элементов, то Timsort выполнит просто сортировку вставками.
Идея алгоритма сортировки вставками:
Условно делим массив на две части: отсортиованную и неотсортированную(изначально весь массив). Проходим по неотсортированной части массива слева направо, переставляя каждый ее элемент на соответствующее место в отсортированной части. Таким образом, с каждым шагом отсортированная часть массива увеличивается на один элемент, а неотосортированная уменьшается.

Сортировка вставками наиболее эффективна на небольших массивах, на больших же списках данных данная сортировка терпит фиаско
2) Вычисление min_run и разбиние на подмассивы. (если входной массив состоит из более 64 элементов)
Тк сортировка вставками эффективна только на небольших массивах, то неплохо было бы выделить подмассивы определенной длины min_run.
Число min_run определяется на основе N, количества элементов исходного массива, исходя из следующих принципов:
- Оно не должно быть слишком большим, поскольку к подмассиву размера
min_runбудет в дальнейшем применена сортировка вставками. - Оно не должно быть слишком маленьким, поскольку чем меньше подмассив — тем больше итераций слияния подмассивов придётся выполнить на последнем шаге алгоритма. Оптимальным будет, если N/minrun будет степенью числа 2 (или близким к нему). Это требование обусловлено тем, что алгоритм слияния подмассивов наиболее эффективно работает на подмассивах примерно равного размера.
Тимом Петерсом было выбрано значение min_run ∈ [32;65).
Таким образом алгоритм вычисления min_run будет выглядит следующим образом:
берем старшие 6 бит числа N и добавляем единицу, если в оставшихся младших битах есть хотя бы один ненулевой.
def _minRunLength(n):
flag = 0
while (n >= 64):
flag = flag | (n & 1)
n = n >> 1
return n + flagПосле нахождения делим входные данные на подмассивы длинны min_run.
3) Сортировка подмассивов сортировкой вставками
4) Слияние уже отсортированных подмассивов
При слиянии начальные элементы подмассивов сравниваются между собой, и из них выбирается наименьший и перемещается в результирующий массив. Указатель в соответствующем подмассиве перемещается на следующий элемент. Процедура повторяется до тех пор, пока не достигнут конец одной из подпоследовательностей. Оставшиеся элементы другой подпоследовательности при этом передаются в результирующую последовательность в неизменном виде.

Вот вообщем-то и все, как уже было сказано Timsort стабилен и весьма производителен, поэтому стоит внимания.
Далее, если хотите можете посмотреть оффициальный код Timsort на C на гитхабе.
И привожу свою реализацию общего концепта данного алгоритма на Python.
def _insert_sort(data):
for i in range(1, len(data)):
j = i - 1
temp = data[i]
while data[j] > temp and j >= 0:
data[j + 1] = data[j]
j -= 1
data[j + 1] = temp
return data
def _merge_sort(left_arr, right_arr):
merge_arr = []
while len(left_arr) > 0 and len(right_arr) > 0:
if left_arr[0] < right_arr[0]:
merge_arr.append(left_arr[0])
left_arr = left_arr[1:]
else:
merge_arr.append(right_arr[0])
right_arr = right_arr[1:]
for i in range(len(left_arr)):
merge_arr.append(left_arr[i])
for j in range(len(right_arr)):
merge_arr.append(right_arr[j])
return merge_arr
def _minRunLength(n):
flag = 0
while (n >= 64):
flag |= n & 1
n = n >> 1
return n + flag
def Timsort(data):
if len(data) > 0:
min_run = _minRunLength(len(data))
for i in range(0, len(data), min_run):
data[i:i + min_run] = _insert_sort(data[i:i + min_run])
run = min_run
while run < len(data):
for i in range(0, len(data), run * 2):
data[i : i + 2 * run] = _merge_sort(data[i: i + run], data[i + run: i + (run * 2)])
run *= 2
return data