Вычленяем, классифицируем и конвертируем инфу из кодовой базы с помощью ChatGPT + LangChain
Когда у проекта уже есть какая-то большая кодовая база, а тебе при этом нужно вычленить из неё какую-то информацию, проходить по всем файлам вручную может быть дико геморрно
К счастью, у нас теперь есть нейросети. И сейчас покажу на одном из примеров, как их можно использовать в работе
Задача
Помните, я делал Perker - небольшую тулзу для хранения/изменения всяких статов итд в JSON-формате с возможностью редачить их через визуальный интерфейс?
Я как-то позабыл о ней, но тут-таки захотелось вынести все статы из кода в JSON
Но вот незадача - перков уже 150 штук. Вытаскивать всё это из каждого файла и конвертировать в JSON руками займёт несколько часов
Что есть LangChain
Не так давно после появления ChatGPT появилась библиотека LangChain - она позволяет выстраивать пайплайны запросов к языковым нейронкам для решения более сложных задач
Библиотека доступна на Python и JavaScript. Я с Python не особо знаком, поэтому использую JS-версию и тут буду писать о ней. Но принцип и API там одинаковое
LangChain из коробки имеет интеграции с разными языковыми моделями и источниками информации. Он умеет читать файлы локально с компа, со всяких баз данных, с википедии и даже Notion

Также LangChain умеет ходить в Google, делать вычисления через Wolfram, ходить в Jira... в общем-то, практически что угодно умеет
Но больше всего меня здесь заинтересовало то, что LangChain имеет готовые пайплайны для поиска информации, группировки и прочих штук. Это вот как раз то, что через обычный интерфейс чатика руками делать ультразапарно
Как накатить
Напишу инструкцию для JS. Тут всё на самом деле просто:
- Установить Node.JS
- Создать интересующую папку
- В ней прописать
npm install langchain zod dotenv - Создать
.env- файлик и прописать тамOPENAI_API_KEY=ваш API-ключ от OpenAI
Ключ лежит тут: https://platform.openai.com/account/api-keys
Вычленяем и формализуем информацию
У меня есть куча файлов на GDScript, где вся информация описана кодом
Мне нужно получить JSON с названиями, описаниями и статами
import { config } from 'dotenv';
import fs from 'fs';
import { ChatOpenAI } from "langchain/chat_models/openai";
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { createMetadataTaggerFromZod } from "langchain/document_transformers/openai_functions";
import { z } from "zod";
import { groupArrayByN } from './utils/group-array.js';
config()
const folder = 'PATH_TO_PERKS'
const zodSchema = z.object({
id: z.string().describe("Perk id stored in `id` variable`"),
title: z.string().describe("Perk name stored in `name` variable`"),
description: z.string().describe("The value of `description` variable"),
direction: z.string().describe("Perk direction stored in `requires` variable as `Unlock/direction_name`. If no direction is present, use `None`"),
stats: z.object({}).describe("Object with perk stats stored in `stats` variable"),
});
const metadataTagger = createMetadataTaggerFromZod(zodSchema, {
llm: new ChatOpenAI({ modelName: "gpt-3.5-turbo", temperature: 0.0 }),
});
const loader = new DirectoryLoader(
folder,
{
".gd": (path) => new TextLoader(path),
},
true
);
const docs = await loader.load()
const taggedDocuments = []
for (const grouppedDocs of groupArrayByN(docs, 10)) {
const currentTaggedDocuments = await metadataTagger.transformDocuments(grouppedDocs);
taggedDocuments.push(...currentTaggedDocuments)
}
const metadata = taggedDocuments.map(doc => doc.metadata)
fs.writeFileSync('classified_perks.json', JSON.stringify(metadata))Давайте по порядку расскажу, что он делает
Zod
С помощью Zod мы можем задать схему из полей, которые нужно сгенерировать
Это суперудобная штука, поскольку основная проблема ChatGPT как раз в том, что ответы обычно отдаются тупо текстом. Где, к тому же, будут примеси каких-нибудь инструкций и прочего ненужного говна
С Zod же мы задаём ригидную структуру из полей, и каждому полю даём описание того, что мы хотим туда сложить:
const zodSchema = z.object({
id: z.string().describe("Perk id stored in `id` variable`"),
title: z.string().describe("Perk name stored in `name` variable`"),
description: z.string().describe("The value of `description` variable"),
direction: z.string().describe("Perk direction stored in `requires` variable as `Unlock/direction_name`. If no direction is present, use `None`"),
stats: z.object({}).describe("Object with perk stats stored in `stats` variable"),
});Zod, на самом деле, очень распространённая нынче библиотека, которая не ограничивается только нейронками, её активно используют и во фронтенде/бэкэнде для валидации данных
Вы также можете создавать вложенные поля, массивы, разные типы данных (строки, числа, true/false итд). Всё это LangChain поддерживает. И, если вы хотите понастроить каких-нибудь графиков из уже давно написанной кодовой базы, это явно будет вам полезно
Доку по этой библиотеке можно почитать вот тут. Там всё очень просто
Meta tagger
const metadataTagger = createMetadataTaggerFromZod(zodSchema, {
llm: new ChatOpenAI({ modelName: "gpt-3.5-turbo", temperature: 0.0 }),
});В этом сегменте мы инициализируем готовый инструмент, который будет проходить по входным данным с помощью указанной нейросети, запрашивать у неё нужную информацию и сохранять её в формате, указанном Zod-схемой
Обратите внимание на параметр temperature. От него зависит, насколько ответ от нейронки будет "креативным". Если выставить в 0, то рандомизации не будет - ответы модели станут по сути детерминированными. Если вам нужно больше "фантазии" - значение можно увеличивать вплоть 1.
Загрузка файлов
Как уже говорил, LangChain из коробки умеет читать из разных источников, будь то база данных, странички из Notion или тупо файлы
В моём случае, это тупо файлы. Поэтому я использую DirectoryLoader
const loader = new DirectoryLoader(
folder,
{
".gd": (path) => new TextLoader(path),
},
true
);
const docs = await loader.load()На выходе получаю список "документов", в которых лежит исходный код и всякие мета-данные
Прогоняем документы через нейронку
const taggedDocuments = []
for (const grouppedDocs of groupArrayByN(docs, 10)) {
const currentTaggedDocuments = await metadataTagger.transformDocuments(grouppedDocs);
taggedDocuments.push(...currentTaggedDocuments)
}Дело в том, что контекстное окно у ChatGPT очень маленькое. И вам не дадут скормить сотню файлов разом
Поэтому я прогоняю не сразу всё, а разбил массив всех файлов на пачки по 10 штук
Вот код функции groupArrayByN, которая это разбивает
export function groupArrayByN(array, n) {
return array.reduce((result, item, index) => {
const chunkIndex = Math.floor(index / n); // calculate the chunk (group) index
if (!result[chunkIndex]) {
result[chunkIndex] = []; // create a new group if not exists
}
result[chunkIndex].push(item); // add the item to the corresponding group
return result;
}, []);
}Если у вас файлы большие, то можете уменьшить N вплоть до единицы. Тогда будет гонять файлы по одному
Но если же сами файлы состоят из большого количества кода, то тут будет гораздо сложнее
Тогда придётся использовать TextSplitter, который разбивает каждый документ на несколько поменьше
В LangChain есть разные готовые сплиттеры. Но при использовании их вытекает важная проблема - каждый кусок будет прогоняться через нейросеть по-отдельности
Соответственно, если вы захотите "список всех перков, которые прокачивают блид", то на один и тот же файл у вас может быть два ответа, один из которых - "да", а другой - "нет" (или "не знаю", если в куске нет информации)
Ещё один аргумент в пользу того, чтобы отходить от стрёмной практики хранить тысячи строк кода в одном файле
Пишем в файл
Тут всё просто. Используем fs, чтобы сохранить нужную инфу в файл:
const metadata = taggedDocuments.map(doc => doc.metadata)
fs.writeFileSync('classified_perks.json', JSON.stringify(metadata))На выходе я получил JSON в тысячу строк со всей информацией:

Представляете, сколько времени ушло бы на заполнение этой инфы вручную?
А сейчас весь этот труд заменился на 50 строк кода. В удивительное время живём!
И ведь что самое крутое - это можно использовать не только для рутинного "вытащить данные и переложить их в другой формат"
Вот список возможных юзкейсов:
- Создавать поля с вопросами, которые бы кратно упростили классификацию перков:
- Например, "does this perk require Poison?"
- Или, "perk rarity based on how unique does it sound. Possible values: Common, Rare, Legendary"
- Можно автоматизировать перевод на практически любой язык. Достаточно просто написать "Description translated to Russian".
Смотри как круто, даже форматирование учёл и переменные оставил в исходном виде:

- Можно создавать промежуточные вычисления для дальнейшей балансировки. К слову, если вам нужны какие-то точные данные, а не сгенерированные нейросетью, LangChain умеет обращаться к кастомным функциям. Почитать можно тут
Более сложные цепочки
Помимо генерации "один ответ на один файл", нам также может понадобиться "пройтись по всем файлам и сформировать один ответ". Или "на основе информации из этих файлов, придумай что-нибудь по тому же принципу"
В LangChain есть разные готовые стратегии для таких сценариев
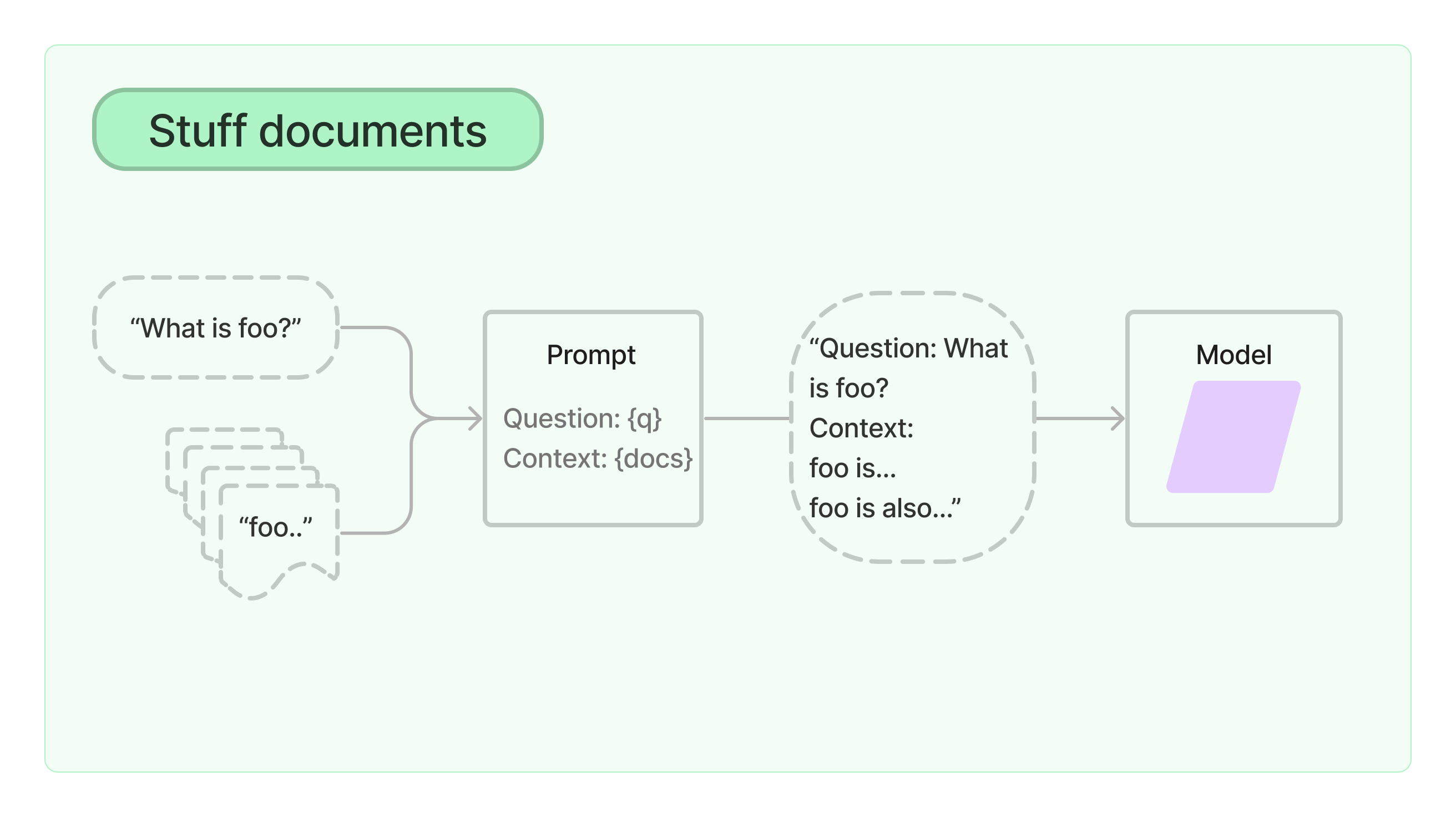
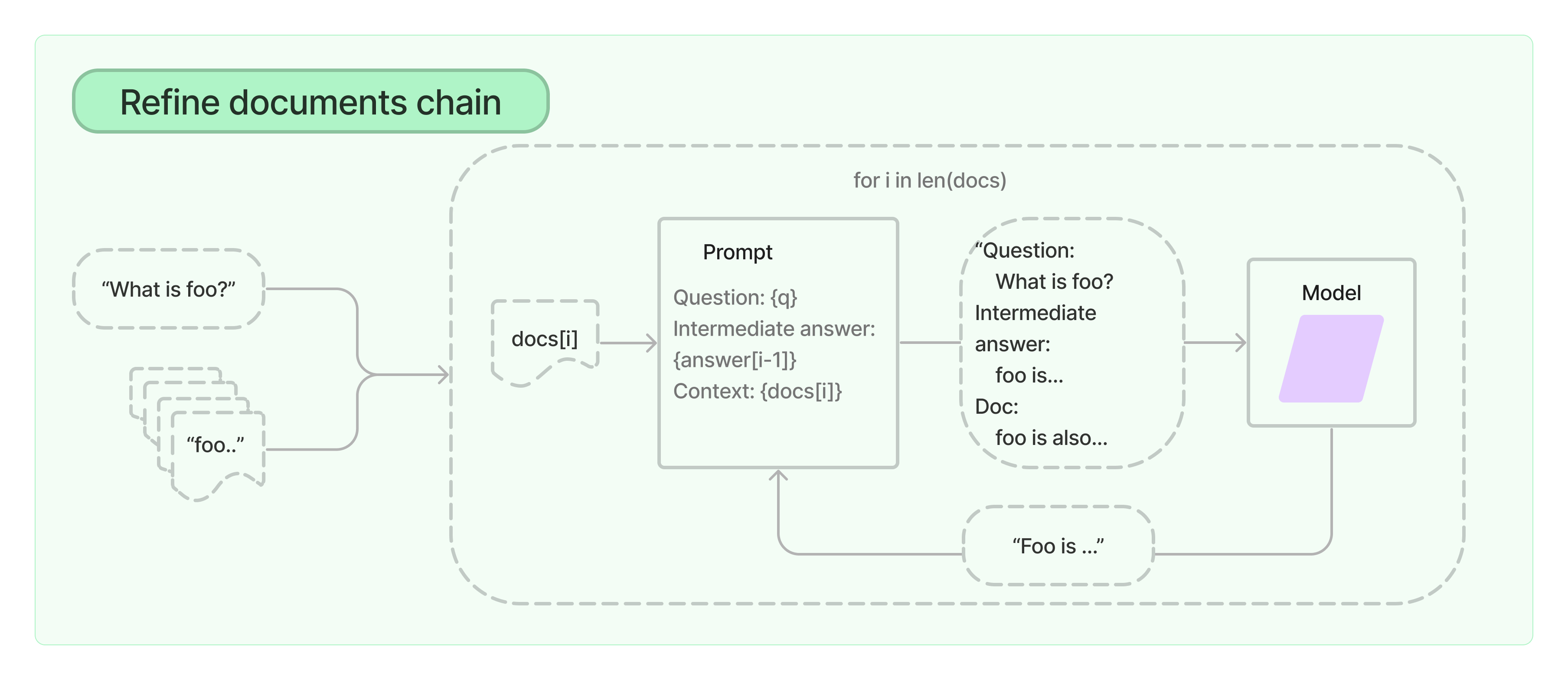

Честно говоря, использовать их со стандартным ChatGPT едва ли возможно, поскольку эти цепочки, хоть и прогоняют всё в несколько этапов, чтобы каждый запрос не упирался в лимит токенов, всё равно жрут сильно больше, чем пока позволяют лимиты
Чтобы это можно было использовать "втупую", нужна модель хотя бы с 32K-токенов (а через API доступ есть только у энтерпрайз-версии через Azure). А в идеале - дождаться, когда выйдет в публичный доступ Claude, у которой запас аж 100K
Мои попытки обхитрить систему успехом не увенчались, но если интересно поиграться на небольших данных - в документации есть примеры кода, которые позволяют "чатиться" с файлами. Например, вот тут
Лично я единственной потенциально рабочей стратегией пока вижу следующее:
- Сначала через Zod + Metadata Tagger вычленить со всех файлов ту необходимую информацию, которая может быть формализована
- Отфильтровать/конвертировать нужное обычным кодом на основе этой информации
- А затем уже использовать вышепоказанные цепочки. То есть не на исходных файлах, а на этом сгенерированном и отфильтрованном JSON
Итого
На самом деле, думаю, маленьким инди-разработчикам такие инструменты не особо будут интересны. Но вот людям, которые работают в каких-либо компаниях, где есть большие проекты, строятся экселевские таблички и прочая энтерпрайзная хрень - это прям охрененный тул для экономии времени
Завернуть бы это в какой-нибудь GUI на самом деле, и можно будет спокойно встраивать в пайплайны разработки даже не-программистам