Как точно оценить цену отдельных NFT? — Часть 2

Перевод
Это вольный перевод: medium.com/nftbank-ai/how-to-accurately-estimate-the-price-of-individual-nfts-part-2-ac73e88aa3ad.
Первая часть: teletype.in/@menaskop/nft-nftbank-01.
Обзор первой части и превью второй
Многие полагаются на последнюю цену сделки или минимальную цену (Floor Price) коллекции для оценки стоимости NFT.
Однако эти показатели не всегда точно отражают ценность предмета, поскольку в пределах одной коллекции NFT могут быть значительные различия, а данные о торговле NFT часто разрознены. (Это можно сравнить с трудностями при покупке недвижимости, особенно если доступно мало данных о прошлых сделках).
Несмотря на эти сложности, данная проблема очень важна.
Точная оценка стоимости NFT — прогнозирование цен, близких к реальным сделкам, — предоставляет ценную информацию коллекционерам NFT, независимо от того, управляют ли они своим портфелем или оценивают возможности покупки или продажи NFT.
В нашей предыдущей статье мы кратко рассказали о том, как NFTBank решает эту проблему. Мы обсудили некоторые сложности, возникающие при создании модели оценки или традиционной временной модели для проектов NFT с низким объёмом сделок, что приводит к разрозненности данных о торговле и резким изменениям цен.
Мы также рассмотрели нюансы оценки стоимости NFT при пакетных продажах, которые происходят довольно часто, и как значения категориальных признаков могут быть преобразованы в значимые числовые данные, а не просто сопоставлены с константой…
Мы разработали нашу базовую модель, которая обеспечивает высокоточную оценку цен для сотен различных проектов NFT, учитывая эти сложности и нюансы.
Именно эта модель позволила нам обслуживать множество пользователей и партнёров.
С момента описания модели в первой части мы протестировали и применили различные передовые модели машинного обучения для улучшения производительности модели. Это позволило нам значительно повысить точность прогнозирования.
В этой статье мы поделимся достигнутыми улучшениями, дополнительными проблемами, которые нужно было решить, и тем, как мы их преодолели, чтобы достичь текущих результатов.
Как выглядит эффективная оценка цены NFT?
Давайте сначала ответим на самый важный вопрос: насколько эффективна оценка цены от NFTBank?
Взгляните на прогнозируемые значения и фактические цены продаж коллекции BAYC за период с 1 февраля 2022 года по 6 апреля 2022 года; синие ящики (box plots) показывают наши прогнозируемые значения, в то время как красные ящики указывают на фактические цены продаж.
Вы можете увидеть, что наши прогнозируемые цены находятся в близком диапазоне к фактическим ценам сделок, даже когда определённые признаки, такие как «золотой мех», значительно отклоняются от среднего:

Как мы пришли к этому?
Проблема низкого объёма, а также высокая волатильность цен продалжают оставаться вызовами при применении прогнозирования на основе машинного обучения (ML) к активам (навроде) NFT.
(В частности) проблема низкого объёма приводила к переоценке или недооценке NFT с редкими характеристиками.
Это связано с тем, что несколько необычных сделок могут существенно исказить модель. Это оказалось самой серьёзной проблемой, о которой мы подробнее расскажем ниже.
Высокая волатильность цен приводила к неправильным оценкам из-за природы модели машинного обучения.
ML обучается на основе прошлых данных, и если происходит внезапное изменение цены, модели требуется время, чтобы это учесть и адаптироваться, что приводит к запаздывающим оценкам.
Решение проблемы низкого объёма позволило нам лучше прогнозировать стоимость более редких NFT, что может существенно повлиять на эффективность активов сверхредких NFT, в то время как решение проблемы высокой волатильности позволило нашей модели более точно отслеживать фактические изменения цен.
В этой статье мы сосредоточимся на проблеме низкого объёма, а проблему высокой волатильности рассмотрим в следующей статье.
Решение проблемы низкого объёма в прогнозировании NFT на основе машинного обучения с использованием восстановления характеристик
Мы обнаружили, что ключом к решению проблемы низкого объёма сделок является отслеживание и обработка информации о ценах на «похожие» предметы. Иными словами, необходимо отслеживать цены на сопоставимые NFT, которые были проданы, определить степень их схожести и найти соответствующие цены.
Это важно, поскольку если можно определить сходство между предметами, то информация из разрозненных данных может быть аппроксимирована с учетом данных по аналогичным предметам.
Для определения схожести между NFT мы использовали самый интуитивно понятный, ключевой принцип, согласно которому наиболее критическим фактором в определении цены NFT является его «характеристика» (trait).
Вот упрощённая версия того, что мы делаем:
- разложение характеристик NFT-предметов;
- группировка NFT по характеристикам;
- вычисление статистики цен для каждой группы;
- восстановление стоимости NFT-предмета с использованием статистики.
Это может показаться простым и довольно лёгким для реализации, но заставить модель распознать и усвоить этот принцип может быть не так просто.
Например, простое добавление характеристики в модель часто приводит к проблеме недооценки, так как большинство сделок совершается вблизи минимальной цены (что приводит к тому, что ML-модель оценивает минимальные значения; потому что это эффективный способ минимизировать целевую функцию).
На рынке NFT шаги 1–3, упомянутые выше, могут быть легко выполнены, если считать характеристики свойствами.
Мы можем просто рассчитать статистику для каждой характеристики, разделив её на подгруппы. Однако сложность заключается в правильном сборе статистики для отдельных характеристик и её преобразовании в данные, которые могут представлять предмет.
Иными словами, необходимо определить, какие характеристики существенно влияют на цену, а затем правильно реконструировать информацию о характеристиках в предметы.
Просто потому что несколько NFT с оранжевым фоном были проданы по высокой цене, это не гарантирует, что все другие NFT с таким фоном также будут проданы по высокой цене.
Рассмотрим реальный пример. В коллекции BAYC обезьяны с мехом цвета «Solid Gold» имеют более высокие ценовые диапазоны по сравнению с обезьянами с мехом цвета «Brown». Это подразумевает, что процесс разложения характеристик NFT-предметов (Шаг 1), группировки NFT по характеристикам (Шаг 2) и вычисления статистики цен для каждой группы (Шаг 3) может быть решён напрямую:
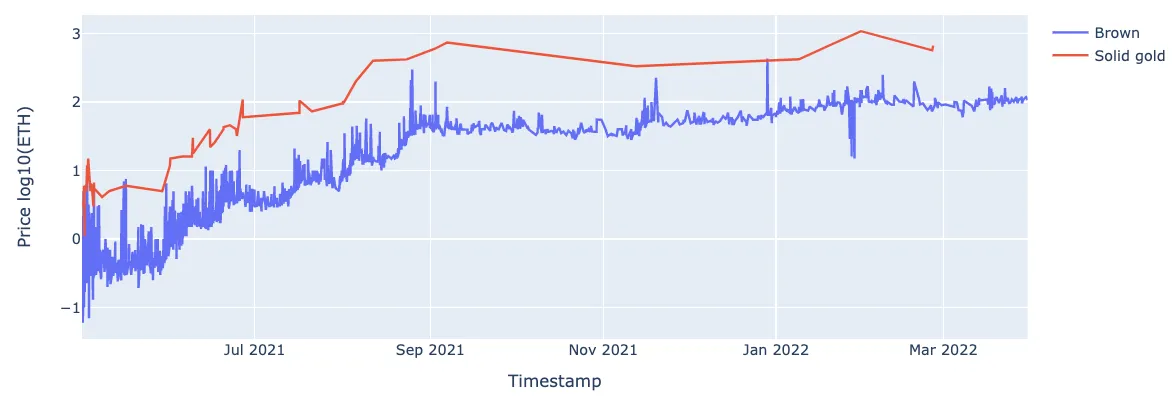
Временной последовательный ценовой тренд NFT-обезьян с двумя признаками; (красный) чистое золото, (синий) коричневый; ось x: временная метка, ось y: log(price)
Однако на этапе 4 возникает проблема: как восстановить значение элемента NFT, используя вычисленную статистику?
Например, рассмотрим обезьян со ртом «Скучная небритость» и «Скучная пицца», которыми обладают 3690 обезьян и 30 обезьян соответственно. Рассматривая динамику цен на NFT с каждым признаком, видим, что в большинстве случаев цена NFT с признаком «Скучная пицца» выше, но иногда NFT с признаком «Скучная небритость» продаётся по более высокой цене, чем другие:
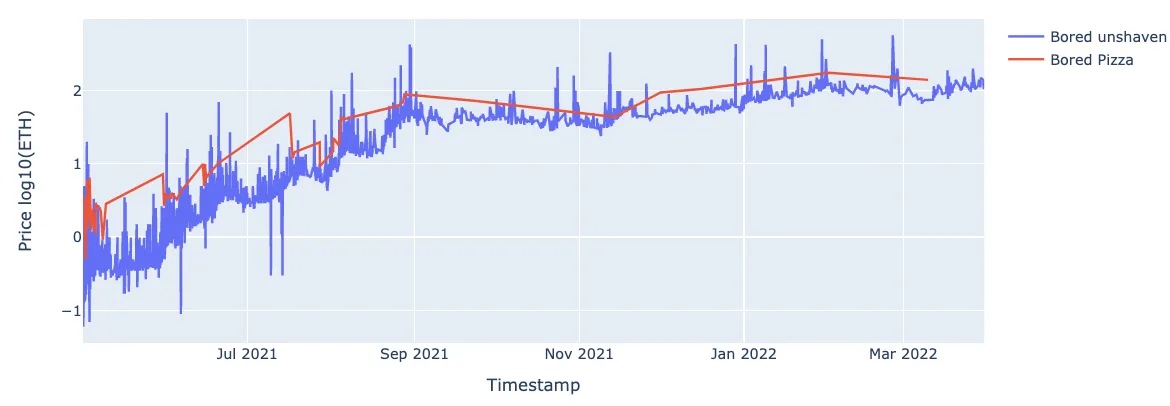
Временная последовательность изменения цен на обезьян со «Скучной небритостью» и «Скучным ртом пиццы»: ось x: временная метка, ось y: log(price)
Инверсии происходили и в тех случаях, когда эти NFT обладали другими ценными признаками, такими как «Solid Gold», «Trippy» или «Black suit» обезьяны. Этот пример указывает на трудности, связанные с выполнением шага 4, то есть с эффективным построением информации о предмете из набора информации о признаках.
Как NFTBank решил эту проблему?
TL'DR
Мы решили эту задачу, разработав модель, которая автоматически определяет ключевые признаки и объединяет информацию об отдельных признаках для формирования информации о конкретном товаре.
Мы внедрили логику в модель и подтвердили, что этот принцип помогает в работе, путём многочисленных экспериментов. Например, на графике ниже показана эффективность проведенной нами реконструкции признаков. Вы можете видеть, что прогнозируемая цена (красная линия) точно следует за трендом проданной цены, гораздо эффективнее, чем тренд цены пола в проекте:

Временная последовательность предсказания цены предмета на основе реконструкции признаков; ось x: временная метка, ось y: log(price); (синий): цена продажи, (красный): предсказание цены предмета на основе реконструкции признаков, (зеленый): минимальная цена проекта
Полная версия
В области машинного обучения зависимая переменная часто трансформируется с помощью логарифмической, степенной трансформации или трансформации Бокса-Кокса.
Эти преобразования имеют различные цели, но в целом направлены на то, чтобы данные соответствовали определённым статистическим допущениям.
Например, в моделировании цен можно скорректировать асимметрию распределения целевой переменной, используя логарифмическое преобразование.
Мы обнаружили, что цена NFT не только остаётся асимметричной, даже при логарифмическом преобразовании, но и в ряде случаев возникают несколько модальностей.
Поэтому мы разработали новый метод, вдохновлённый пошаговым отбором переменных и трансформацией Бокса-Кокса, для сбора статистики по каждой характеристике.
Пошаговый отбор переменных — это один из традиционных статистических методов выбора переменных.
Он начинается с модели, которая не содержит никаких переменных, в нашем случае — характеристик. Затем он добавляет наиболее значимые переменные одну за другой, пока не будет достигнуто заранее заданное условие остановки. В данном случае мы определили условие остановки как среднюю абсолютную ошибку (MAE), которая также используется в целевой функции модели.
Приблизительная цена предмета строится через взвешенное среднее информации по выбранным характеристикам (в этом случае вес применяется по-разному в зависимости от времени, и чем более свежие данные, тем больший вес они имеют).
Таким образом, приблизительная цена предмета, рассчитанная с помощью нашего преобразования, ведёт себя очень похоже на фактическую цену продажи.
Сила нашей системы машинного обучения заключается в способности исправлять разреженность данных, учитывая и анализируя все тенденции по каждой характеристике.
Иными словами, наша модель может оценить предмет, даже если по нему не было совершено ни одной сделки или если никогда не продавалась аналогичная комбинация характеристик.
Ограничения
Наш фундаментальный подход заключается в аппроксимации цены предмета через цену его характеристик. Естественно, невозможно оценить характеристику, которая никогда не торговалась (но кто знает? Возможно, мы ещё это исправим).
Это также означает, что наш метод уязвим к сценариям «wash-trading» (искусственно завышенных или заниженных цен на NFT путём многократных продаж между связанными сторонами).
Если один и тот же NFT был продан несколько раз по необоснованно высокой или низкой цене, информация о его характеристиках будет искажена, каким бы устойчивым ни был наш метод. Мы уже сталкивались с временным снижением производительности модели из-за wash-trading, как и предполагали.
Заключение
Производительность модели NFTBank постоянно улучшается благодаря многочисленным экспериментам и усилиям. Все члены команды работают день и ночь, чтобы сделать NFTBank самым эффективным инструментом для управления активами NFT. Большое спасибо нашим пользователям за поддержку и ценные отзывы. Это огромная мотивация для нас и имеет большое значение.
Если вы хотите использовать нашу оценку цен для своего продукта или сервиса, свяжитесь с нами. Мы будем рады сотрудничеству!