Создание платформы наблюдаемости с помощью SigNoz, ClickHouse и OpenTelemetry — Часть 1
Перевод оригинальной статьи Building a Production-Grade Observability Platform with SigNoz, ClickHouse, and OpenTelemetry — Part 1
Перевод сделан специально для телеграм-канала Мониторим ИТ. Подписывайтесь! Там еще больше полезных постов о мониторинге.
Уроки, полученные в ходе нашей внутренней настройки наблюдения, и то, что мы узнали помимо документации и долгих ночей настройки кластера.
1. Обзор
Мы поставили перед собой задачу создать собственную платформу на базе SigNoz, ClickHouse и OpenTelemetry (OTEL), способную обрабатывать метрики и трассировки в различных средах в производственных масштабах. Мы постоянно запускаем тысячи экземпляров EC2 и хранилищ данных, генерирующих миллионы метрик и событий трассировки. Кроме того, это помогает нам экономить миллионы долларов на счетах других коммерческих решений, которые мы использовали раньше. 💸
О чем этот блог (и серия)
В этой публикации мы рассмотрим архитектуру и ключевые системные выводы, сделанные в ходе масштабного запуска — от проектирования до наблюдения за стеком наблюдения!
Мы выйдем за рамки обучающих материалов и рассмотрим операционные реалии высокопроизводительных систем наблюдения.
В следующих частях мы подробно рассмотрим:
Единый двоичный пользовательский интерфейс SigNoz и схемы *MergeTree
- Различные компонент пользовательского интерфейса Signoz и их практические последствия при настройке продакшна.
- *Схемы MergeTree для хранения метрик и трассировок в ClickHouse и то, как они используют “fingerprints” для оптимизации хранения.
Внутреннее устройство ClickHouse для телеметрических нагрузок
- Как ведут себя репликация, очереди слияний и компрессия в масштабах петабайт.
- Почему решения по ключам сортировки могут как ускорить, так и полностью разрушить латентность запросов.
- Как несоответствие форм вставки тихо убивает пропускную способность.
- Реальное влияние пакетной обработки, ограничений памяти и асинхронных вставок через коллектора.
Высокоуровневая архитектура
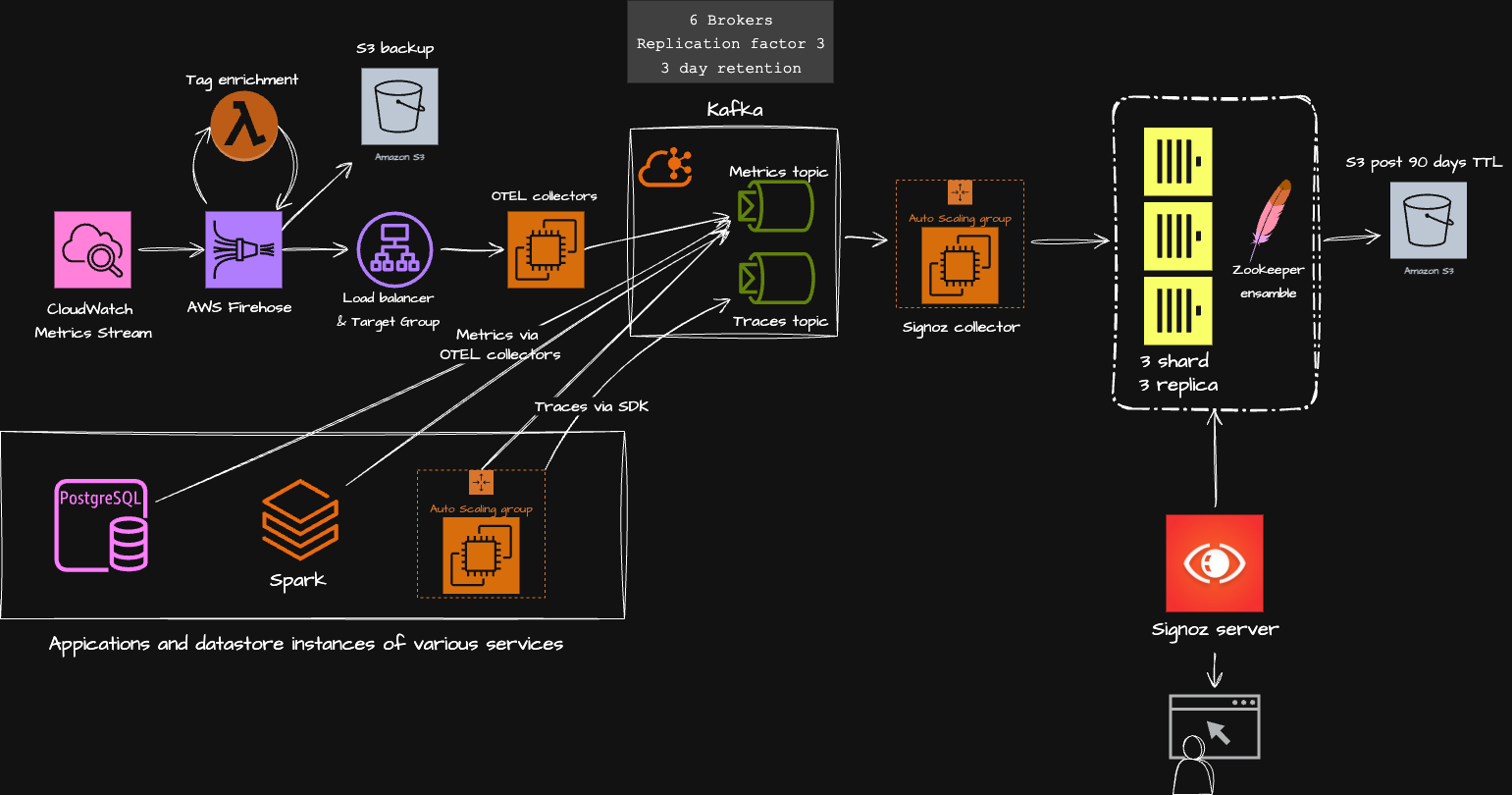
Проектирование высокого уровня (HLD)
Вот высокоуровневая архитектура конвейера наблюдаемости, который мы настроили с использованием OpenTelemetry (OTEL), Kafka и SigNoz. Цель была проста: создать масштабируемый, независимый от вендора конвейер телеметрии, который мог бы обрабатывать метрики и трассировки десятков сервисов, не ограничиваясь одним проприетарным решением.
Всё начинается с источника — наших приложений и систем данных, таких как PostgreSQL, Spark и различных микросервисов. Они генерируют телеметрию (метрики и трассировки), которые мы собираем с помощью OTEL-коллекторов и SDK. Коллекторы отвечают за пакетирование, сэмплинг и преобразование данных в единый формат OTEL перед их дальнейшей отправкой.
Для мониторинга метрик собственных сервисов AWS мы передаем метрики CloudWatch через Firehose. На пути потока находится лямбда-функция для обогащения тегами, добавляя полезные метаданные, такие как имена сервисов, окружения или кастомные теги, которые значительно упрощают поиск данных в будущем. Далее обогащенные данные резервируются в S3 и направляются на уровень коллектора OTEL через балансировщик нагрузки.
Совет 🚀В Firehose мы использовали размер буфера 0,2 МБ и интервал между буферами 60 секунд. Это даёт нам около 200 одновременных вызовов лямбда. Увеличение размера буфера может уменьшить количество лямбда вызовов. Однако необходимо учитывать размер сообщения после обогащения тега. Чем больше буфер, тем больше пакет после обогащения, и вы можете столкнуться с ошибками «Message size too large» в логах Firehose. Настройте значение для оптимизации затрат. Лямбда для обогащения метрик тегами: мы использовали модификацию этой лямбды для OTLPv1.0. Она использует ResourceGroupsTaggingAPI для обогащения метрик тегами в потоке. Используйте sending_queue и retry_on_failure в конфигурации OTEL collector. При экспорте в Kafka, в случае сбоя, коллектор будет хранить сообщения в памяти в зависимости от установленного лимита и пытаться отправить их повторно. Если очередь переполнена, начнется потеря сообщений. Слишком длинная очередь может привести к исчерпанию памяти экземпляра, вплоть до полной потери ответа. Поэтому лимит очереди критически важен.
Все эти телеметрические данные — как метрики, так и трассировки — поступают в Kafka, которая служит основой нашего конвейера наблюдения. У нас есть отдельные топики Kafka для метрик и трассировок, поддерживаемые шестью брокерами, с фактором репликации 3 и сроком хранения 3 дня. Это обеспечивает надёжный, отказоустойчивый буфер, способный справляться с пиковыми нагрузками без потери данных.
Из Kafka данные получают коллекторы SigNoz и записывают их в ClickHouse, нашу основную базу данных временных рядов. Кластер ClickHouse состоит из 3 шардов и 3 реплик, координируемых ZooKeeper для обеспечения согласованности и отказоустойчивости. Для управления расходами старые данные (более 90 дней) автоматически выгружаются в S3, что обеспечивает долгосрочное хранение без избыточных расходов на локальное хранилище.
Совет 🚀
- Убедитесь, что брокеры размещены в разных зонах доступности для высокой отказоустойчивости. У нас есть 6 брокеров с коэффициентом репликации 3 и сроком хранения 3 дня.
– Нам пришлось обновить max_message_bytes, поскольку батчи OTEL-коллектора превышали стандартный размер в 1 МБ. Настройте это значение в соответствии с вашей пропускной способностью.
- Конфигурация memory_limiter на коллекторе Signoz OTEL оказалась настоящим спасением! Она ограничивает потребление памяти заданным порогом и оказывает обратное давление на приемник Kafka при превышении лимитов памяти экземпляра, защищая экземпляр от выполнения OOM.
- Мы используем 8xlarge-инстанс для каждого узла ClickHouse с SSD-накопителем на 250 ГБ. Мы будем экспериментировать с уменьшением размера экземпляра после бенчмаркинга с использованием трёхмесячных метрик. В настоящее время загрузка ЦП составляет около 8%.
Наконец, все данные выводятся на сервер SigNoz, предоставляющий единую интерфейс-панель для запросов и визуализации как метрик, так и трассировок. Именно здесь команды непосредственно взаимодействуют с данными — устраняют скачки задержек, анализируют тенденции и находят узкие места в производительности.
Короче говоря, эта архитектура обеспечивает чёткое разделение приёма, обработки и хранения данных. Она устойчива к пиковым нагрузкам, достаточно модульна для развития со временем и даёт нам полный контроль над тем, как данные наблюдения проходят через наш стек, — без зависимости от непрозрачного ("чёрного ящика") SaaS-решения.
Масштаб и производительность
- Производственная инфраструктура, находящаяся под наблюдением, включает в себя более 10 тыс. экземпляров EC2 и хранилищ данных, работающих на пике производительности, генерирующих метрики и трассировки.
- Скорость приема данных: ~200 Мбит/с (Cloudwatch + метрики хоста + трассировки)
- ~100 млн уникальных метрик на пике
- ~1 млн строк/сек реплицируется на все 9 узлов ClickHouse
- Время вставки запросов в ClickHouse: 25 мкс.
- 357 ТБ загруженных спанов в месяц.
2. Почему OpenTelemetry (OTEL), а не Prometheus
Prometheus многие годы был стандартным выбором для наблюдаемости, но когда нам понадобилась телеметрия «сквозных сигналов» (метрики + трассировки + логи), его ограничения стали очевидными. Подробнее об этих различиях читайте в этой статье.

- Модель pull в Prometheus отлично подходит для простых кластеров, но плохо масштабируется для распределенных рабочих нагрузок с высокой мощностью.
- Конструкция OTEL на основе push-уведомлений и настраиваемые процессоры обеспечили нам более точный контроль и отказоустойчивость.
- Использование OTEL означало, что при необходимости мы могли экспортировать данные в несколько бэкэндов (например, ClickHouse + S3 + kafka).
Почему SigNoz
- Тесно интегрируется с OTEL и ClickHouse.
- По умолчанию он предоставляет UI для трассировки, дашборды для метрик и систему алёртинга.
- В отличие от SaaS-инструментов, он имеет открытый исходный код и является расширяемым — вы можете модифицировать экспортёр, менять схему ClickHouse и напрямую анализировать работу запросов.
- У него очень активная поддержка сообщества.
В последующих публикациях этой серии я поделюсь более подробной информацией о сервере SigNoz и архитектуре схемы, а также о том, как они себя покажут на платформе промышленного масштаба.

3. Наблюдение за стеком наблюдаемости
Наблюдаемость не будет полной, если вы не можете наблюдать за самим стеком наблюдаемости.
Наш конвейер телеметрии оснащен Prometheus и коллекторами OTEL, но с одной особенностью: мы создали устойчивый уровень сбора метрик с буферизацией через Kafka, который устраняет необходимость в статических scrape-таргетов Prometheus и допускает простои сервера Prometheus.
PS: Мы решили не настраивать отдельный конвейер Signoz + CH для этого, поскольку настройка еще одного кластера CH + ансамбля Zookeeper потребовала бы слишком больших затрат на обслуживание ради наблюдаемости самого конвейера наблюдаемости, который работает на фиксированных инстансах.
3.1 Мотивация дизайна
По мере масштабирования наших кластеров OTEL и ClickHouse поддержка статических конфигураций сбора данных Prometheus для каждого коллектора, брокера или узла ClickHouse становилась неуправляемой.
- Динамическое автообнаружение — не требуется ручное изменение конфигурации при масштабировании экземпляров.
- Отказоустойчивость — метрические данные должны выдерживать кратковременные сбои Prometheus.
- Единый путь приема данных — объединение телеметрии на уровне инфраструктуры и приложения в один поток.
Поэтому вместо того, чтобы позволить Prometheus напрямую опрашивать каждый endpoint, мы перевернули архитектуру: Prometheus получает метрики всего из одного OTEL-коллектора, который читает метрики из Kafka, куда отправляют их все компоненты конвейера.
3.2 Примеры конфигураций коллектора
На каждом хосте (узлы Kafka, ClickHouse, OTEL Collector):
Экспортирует метрики Prometheus в Kafka.
receivers:
prometheus:
config:
global:
scrape_interval: 30s
scrape_configs:
- job_name: otel-collector-binary
static_configs:
- targets: ['localhost:8888'] # OTEL internal metrics
hostmetrics:
collection_interval: 30s
scrapers:
cpu: {}
load: {}
memory: {}
disk: {}
filesystem: {}
network: {}
processors:
resourcedetection/aws:
detectors: [ec2]
timeout: 2s
override: true
ec2:
tags:
- aws:autoscaling:groupName
- service_name
- environment_name
- cluster
- provisioned-by-user
- resource_type
exporters:
kafka:
brokers: ["observibility-kafka.prod.local:<port>"]
topic: "pipeline-metrics"Центральный коллектор (обращённый к Prometheus):
Использует данные из Kafka, повторно выставляет метрики для Prometheus.
receivers:
kafka:
brokers: ["kafka-1:9092", "kafka-2:9092"]
topic: "pipeline-metrics"
exporters:
prometheus:
endpoint: "0.0.0.0:9464"
service:
pipelines:
metrics:
receivers: [kafka]
exporters: [prometheus]Конфигурация Прометея
Prometheus требуется только один таргет:
scrape_configs:
- job_name: 'otel-metrics-aggregator'
static_configs:
- targets: ['otel-central-collector:9464']Это делает настройку полностью независимой от топологии — можно масштабировать Kafka, ClickHouse или OTEL-коллекторы вверх/вниз, не меняя YAML-конфигурацию Prometheus.
3.3 Что мы отслеживаем


4. Инструменты для отслеживания
Масштабное отслеживание требует тщательной координации между агентом OTEL и коллекторами, а также использования специальных инструментов для работы с устаревшим кодом. Вот обзор того, как мы справляемся с этим на нашей платформе.
Обзор агента + коллектора
- Агент OTEL: запускается вместе с приложениями (sidecar или in-process), перехватывая входящие и исходящие запросы для создания интервалов. Для HTTP, gRPC и поддерживаемых фреймворков агент автоматически инструментирует запросы.
- Сборщик OTEL: получает данные от агентов, выполняет батчинг, семплинг и обогащение, а также экспортирует их в Kafka для обеспечения устойчивости. Коллектор SigNoz из Kafka записывает данные в ClickHouse для хранения и визуализации.
Такое разделение гарантирует, что агенты остаются легкими, в то время как коллекторы выполняют тяжелую работу, такую как батчинг, backpressure и экспорт в больших масштабах.
Кастомное инструментирование для устаревших систем
Некоторые из наших сервисов используют старые версии фреймворков и библиотек, которые не инструментируются автоматически OTEL:
- Vert.x 3.9: Требуется специальный инструментарий для корректного захвата асинхронных циклов событий.
- Клиенты SQL (старые версии JDBC) и клиенты Redis: мы написали небольшие оболочки OTEL для захвата областей запросов/команд без изменения существующей бизнес-логики.
Эти специальные инструменты имели решающее значение для поддержания сквозной видимости трассировки для критически важных устаревших потоков.
Семплинг
Мы применяем вероятностный семплинг 1% для трейсов:
- Это означает, что только 1% всех запросов фиксируется как трейсы.
- Это снижает нагрузку на систему, при этом позволяя проводить статистически значимый анализ ошибок и скачков задержки.
- Даже при таком семплинге большинство ошибок фиксируются, так как спаны с ошибками чаще встречаются в запросах с высокой задержкой или сбоев.
Полезный совет: если уровень ошибок у вас крайне низок, рассмотрите tail-based sampling (сбор всех трейсов с ошибками) в сочетании с вероятностной выборкой, чтобы не пропустить критические события сбоя.
Метрики охвата
- Все метрики интервала (задержка, количество ошибок, длительность) хранятся в ClickHouse.
- Это позволяет строить дашборды без необходимости повторной обработки необработанных трассировок.
# Sample signoz config for span metrics
signozspanmetrics/delta:
aggregation_temporality: AGGREGATION_TEMPORALITY_DELTA
dimensions:
- default: default
name: service.namespace
- default: default
name: deployment.environment
- name: signoz.collector.id
dimensions_cache_size: 100000
latency_histogram_buckets:
- 100us
- 1ms
- 2ms
- 6ms
- 10ms
- 50ms
- 100ms
- 250ms
- 500ms
- 1000ms
- 1400ms
- 2000ms
- 5s
- 10s
- 20s
- 40s
- 60s
metrics_exporter: signozclickhousemetricsВспомогательные библиотеки OTEL
Для поддерживаемых библиотек OTEL предлагает богатый набор инструментов в opentelemetry-contrib. Он включает в себя автоматический инструментарий для баз данных, систем обмена сообщениями, веб-фреймворков и многого другого. Использование этих инструментов снижает потребность в специальных оболочках и обеспечивает совместимость с будущими версиями.
5. Итоги и что дальше
В этой части мы рассмотрели общие принципы проектирования и эксплуатации платформы наблюдения промышленного уровня с использованием SigNoz, ClickHouse и OpenTelemetry. Ключевые выводы:
- Масштабируемая архитектура: разделение приема, обработки и хранения позволяет системе обрабатывать миллионы показателей и трассировок в секунду, оставаясь при этом устойчивой к скачкам нагрузки.
- Практические уроки настройки: такие конфигурации, как ограничения памяти коллектора OTEL, пакетирование Kafka и размеры буфера Lambda, имеют решающее значение для надежности и оптимизации затрат.
- Самонаблюдаемость: Инструментирование самого конвейера наблюдаемости обеспечивает динамический мониторинг метрик Prometheus и обратного давления, без необходимости управлять сотнями статических конфигураций сбора данных.
- Трейс-инструментирование: правильная настройка агента и коллектора, а также специализированный инструментарий для устаревших библиотек обеспечивают полноту распределённых трейсов, в то время как вероятностная выборка позволяет контролировать затраты на хранение и прием данных.
Эта статья посвящена вопросам «почему» и «как» на архитектурном уровне. Мы надеемся, что она даст вам конкретные идеи и практические рекомендации по созданию и настройке собственного телеметрического стека.
Что дальше (часть 2):
В следующей публикации мы подробно рассмотрим сервер SigNoz, настройки коллектора и схемы ClickHouse. Вы получите подробную информацию о:
- Как коллекторы обрабатывают пакетирование, повторные попытки и обратное давление.
- Шаблоны проектирования схемы Signoz *MergeTree для метрик и диапазонов с высокой кардинальностью, а также то, как она использует отпечатки для оптимизации хранения.
- Однобинарный UI-сервер SigNoz с компонентами alert-manager и query-builder.
Оставайтесь с нами, если хотите узнать подробности, выходящие за рамки документации, — то, что делает платформу наблюдения за производством по-настоящему надежной и производительной. 👋
2 часть статьи на момент публикации перевода так и не вышлаю (примечание переводчика).
Подписывайтесь на телеграм-канал Мониторим ИТ, там еще больше полезной информации о мониторинге!