Сбор логов Docker-контейнеров с помощью OpenTelemetry

Перевод оригинальной статьи Collecting Docker Container Logs with OpenTelemetry.
Три недели в окопах: охота за утечкой 4 ГБ нативной памяти, которую .NET не мог увидеть

Перевод оригинальной статьи Three Weeks in the Trenches: Hunting a 4GB Native Memory Leak That .NET Couldn’t See.
OpenTelemetry Filelog Receiver: руководство по приему лог-файлов

Перевод оригинальной статьи OpenTelemetry Filelog Receiver: A Guide to Ingesting Log Files.
От вендоров к авангарду: ценный опыт Airbnb в области обеспечения наблюдаемости
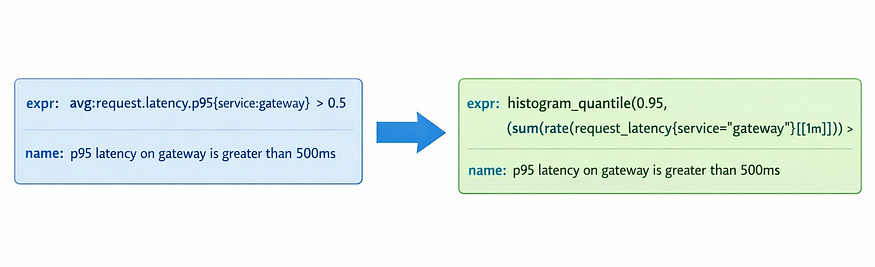
Это перевод оригинальной статьи From vendors to vanguard: Airbnb’s hard-won lessons in observability ownership.
Вы не готовы к мониторингу Kubernetes, пока не поймете эти концепции
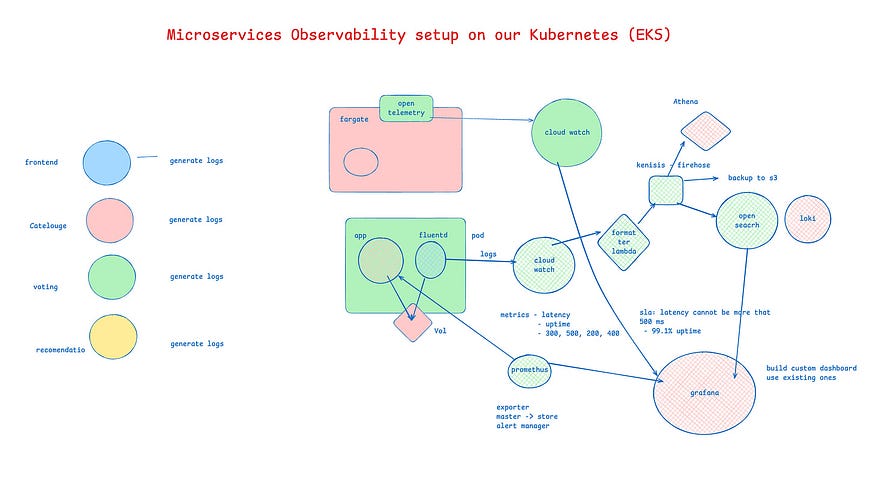
Это перевод оригинальной статьи You’re Not Ready for Kubernetes Observability Until You Understand These Concepts.
Пошаговое руководство по настройке безопасности конвейеров наблюдаемости с помощью Vector от Datadog
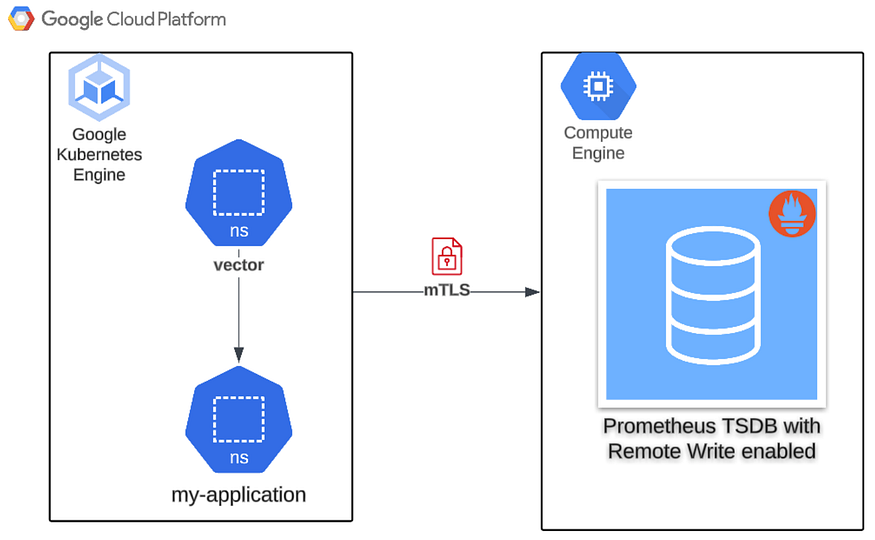
Перевод оригинальной статьи A Step-by-Step Guide to Securing Observability Pipelines Using Vector by Datadog.
Прекратите запускать по 5 агентов на каждом сервере — используйте Grafana Alloy
Это перевод оригинальной статьи Stop Running 5 Agents Per Server — Use Grafana Alloy Instead.
Создание платформы наблюдаемости с помощью SigNoz, ClickHouse и OpenTelemetry — Часть 1
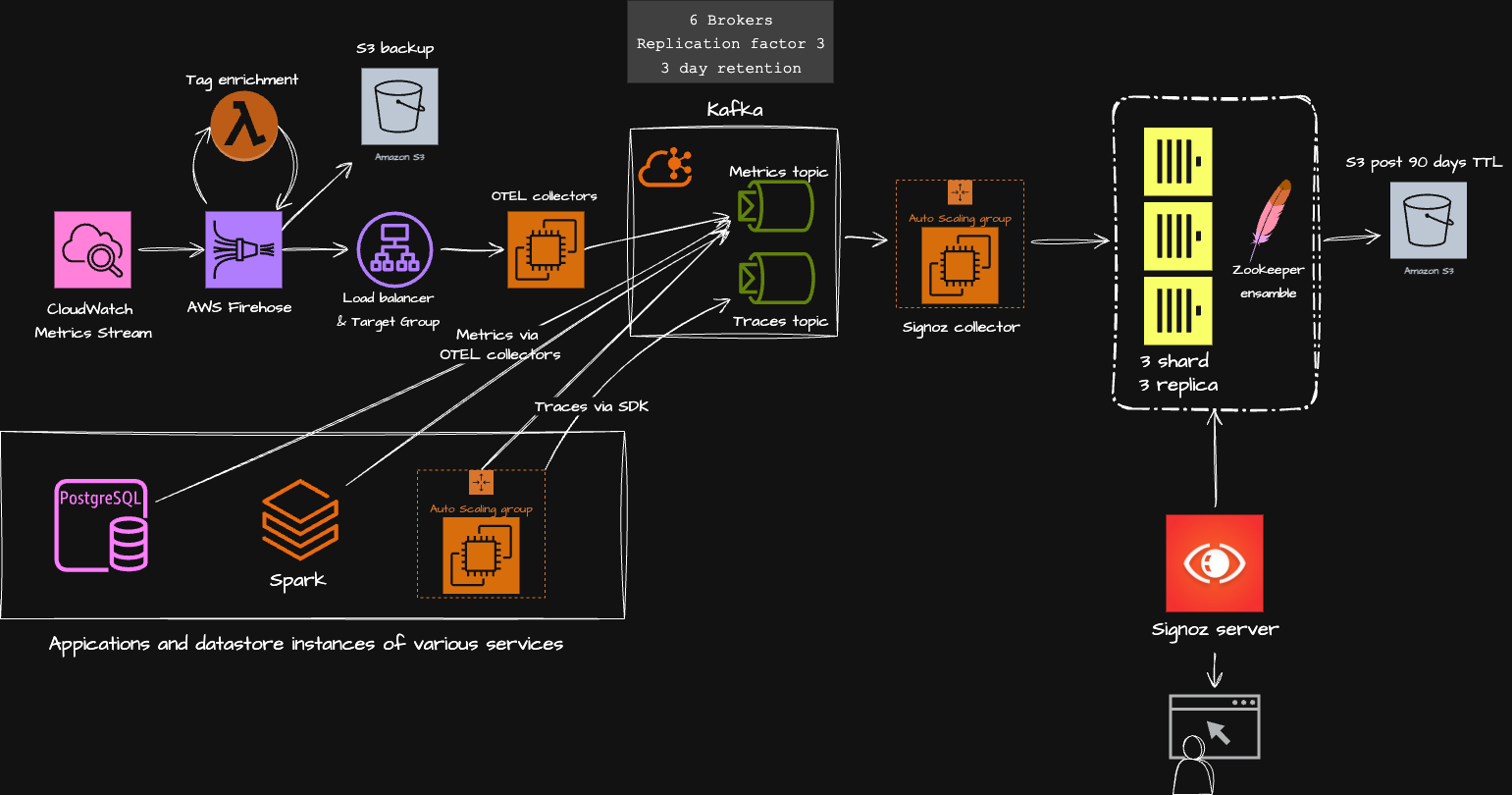
Перевод оригинальной статьи Building a Production-Grade Observability Platform with SigNoz, ClickHouse, and OpenTelemetry — Part 1
Масштабирование метрик Prometheus с помощью Grafana Mimir: пошаговая настройка
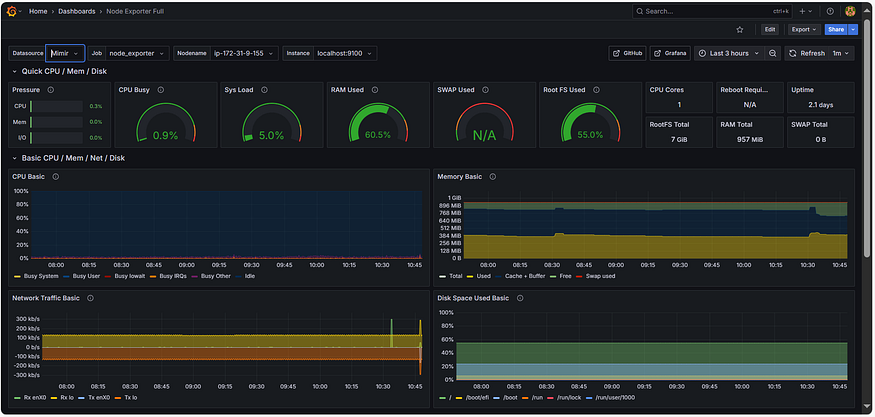
Это перевод оригинальной статьи Scaling Prometheus Metrics with Grafana Mimir: Step-by-Step Setup and Demo.
О чём логи Kubernetes не расскажут вам во время инцидента
Это перевод оригинальной статьи What Kubernetes Logs Won’t Tell You During an Incident.