EVM для задротов 6

Сегодня мы продолжим углубляться в EVM и пытаться в нем разобраться!
По своей сути данная статья является переводом и выжимкой вот этого парня ТЫК
Так же хочу предупредить, новичкам в программировании скорее всего будет сложно понять происходящее, поэтому если вы действительно хотите все впитать, то читайте неспешно и вместе с гуглом
А перед прочтением обязательно ознакомьтесь с:
- первой частью тут - ТЫК
- второй частью тут - ТЫК
- третьей статьей тут - ТЫК
- четвертой статьей тут - ТЫК
- пятой статьей тут - ТЫК
Начнем!
Понимание on-chain данных — важный навык для любого, кто хочет работать в пространстве Web3. Понимание структур данных, из которых состоит блокчейн, может помочь вам придумать новые и творческие способы анализа этих данных
Сегодня мы углубимся в ключевую структуру данных в EVM, transaction receipts и связанные с ними event logs. Если вы программировали на Solidity ранее, то, вероятно, сами уже создавали event logs, они составляют огромную часть данных, доступных нам в сети
В этой статье мы пройдем путь от заголовка блока до внутренностей event logs, и это даст нам полное представление о том, какие данные в блокчейне нам доступны и как они были созданы
Зачем использовать логи
Прежде чем мы начнем, я хочу кратко рассказать о том, почему мы используем event logs во время разработки на Solidity
- Как более дешевая альтернатива data storage, если в будущем контракту не требуется доступ к этим данным
- Как метод запуска приложений web3, которые слушают определенные event logs
Ноды EVM не обязаны хранить логи вечно и могут удалять старые логи для экономии места. Контракты не могут получить доступ к хранилищу логов, поэтому они не требуются нодами для выполнения контракта. С другой стороны, для выполнения требуется storage контракта, поэтому его нельзя удалить
Ethereum Block Merkle Roots
В "EVM для задротов 4" мы погружались в архитектуру Ethereum, в частности, в state Merkle root (корень состояний Меркла). State Merkle root был одним из 3 корней Merkle, содержащихся в хэдерсе блока. Двумя другими были transaction Merkle root и transaction receipt Merkle root
Для нашего дипдайва мы собираемся сослаться на блок 15001871 в цепочке Ethereum, который содержит 5 транзакций, связанные с ними receipts и event logs, которые были созданы. Это поможет нам связать любые концепции, которые мы изучаем, с реальным примером
Block Header
Начнем с хэдерс блока. Нас интересуют 3 компонента: «Transaction Root», «Receipt Root» и «Logs Bloom»
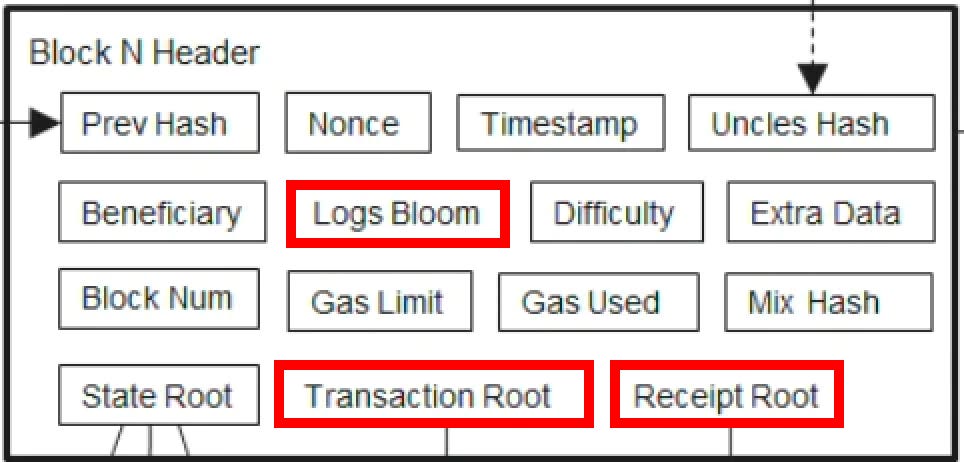
В клиенте Ethereum под «Transaction» и «Receipt» roots находятся Merkle Patricia Tries, содержащие данные транзакций и данные receipt для всех транзакций и receipts в этом блоке
Мы не будем углубляться в то, как работает Merkle Patricia Trie. Для целей этой статьи нам нужно знать только то, что нода имеет доступ ко всем транзакциям и receipts
Давайте посмотрим на настоящий хэдерс блока 15001871, запросив его у ноды Ethereum

Обратите внимание поле logsBloom, это ключевая структура данных, к которой мы вернемся позже в этой статье
А пока давайте начнем с данных, лежащих в основе корня транзакции, Transaction Trie
Transaction Trie
«Transaction Trie» — это набор данных, который генерирует transactionsRoot и записывает векторы transaction request
Векторы transaction request — это фрагменты информации, необходимые для выполнения транзакции
Поля, включенные в транзакцию, можно увидеть ниже:
- Type = Тип транзакции (LegacyTxType, AccessListTxType, DynamicFeeTxType)
- ChainId = идентификатор цепочки EIP155 транзакции
- Data = входные данные транзакции
- AccessList = Список доступа транзакции
- Gas = gas limit транзакции
- GasPrice = цена газа транзакции
- GasTipCap = gasTipCap на каждую единицу газа транзакции
- GasFeeCap = Предельная комиссия на каждую единицу газа транзакции
- Value = сумма эфира передаваемого в транзакции
- Nonce = номер транзакции у отправителя
- To = адрес получателя транзакции. Для транзакций создания контракта "To" возвращает ноль
- RawSignatureValues = сигнатуры значений V, R, S транзакции
Давайте посмотрим на некоторые реальные данные из транзакции в блоке 15001871. Мы будем использовать первую транзакцию 0x311ba3a0affb00510ae3f0a36c5bcd0a48cdb23d803bbc16f128639ffb9e3e58
Давайте воспользуемся ethclient Geth для запроса в ноду. Обратите внимание, что ChainId и AccessList имеют значение «omitempty», что означает, что если поле пусто, то оно будет исключено из ответа
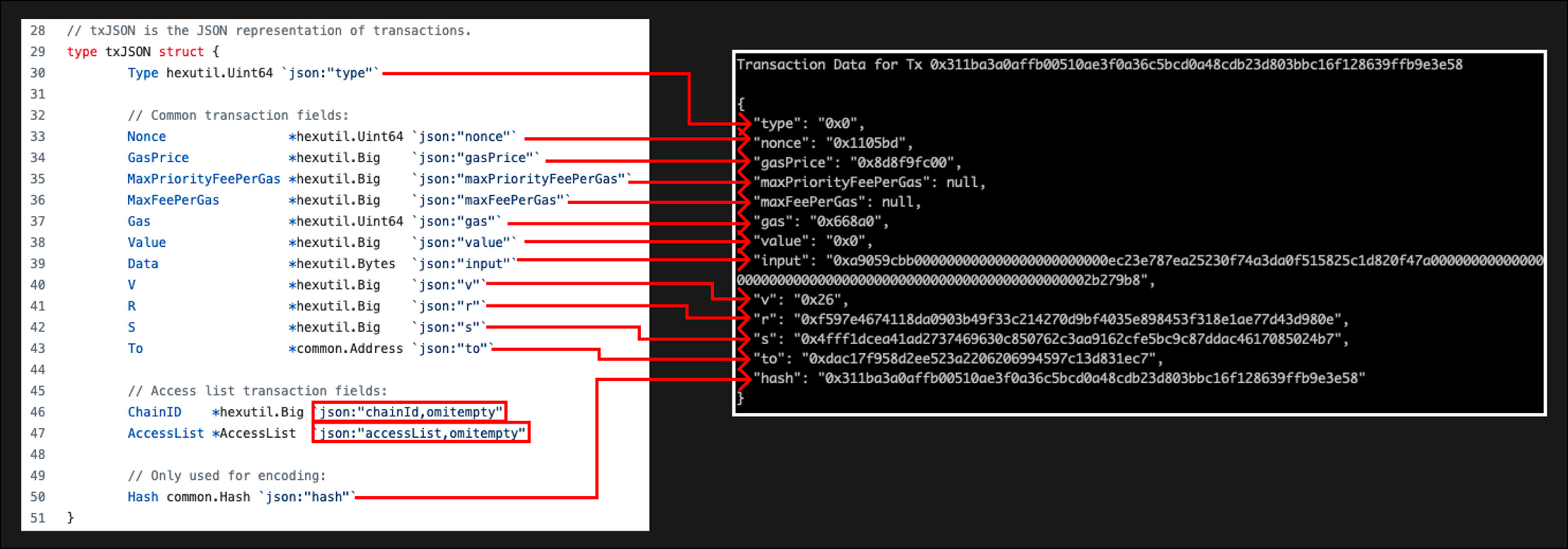
Эта транзакция представляет собой перевод USDT на этот адрес 0xec23e787ea25230f74a3da0f515825c1d820f47a
Адресом контракта ERC20 USDT является 0xdac17f958d2ee523a2206206994597c13d831ec7
Если мы посмотрим на входные данные, то увидим сигнатуру функции 0xa9059cbb, которая соответствует transfer(address,uint256), адрес для отправки USDT - 0xec23e787ea25230f74a3da0f515825c1d820f47a и сумму транзакции 0x2b279b8 = 45251000 в десятичном виде или 45,251 доллара
Что вы можете заметить в этой структуре данных транзакции, так это то, что она ничего не говорит нам о результате транзакции. Сделка прошла успешно? Сколько газа она израсходовала? Какие event logs были отправлены?
Здесь на помощь приходят transaction receipts и «Receipt Trie»
Receipts Trie
Торговый чек (shopping receipt) в обычной сделке (транзакции) фиксирует ее результат, так и объект в Receipt Trie делает то же самое для транзакции Ethereum вместе с некоторыми дополнительными деталями
На поставленные выше вопросы отвечает transaction receipt. Мы собираемся сосредоточиться на третьем вопросе. Какие event logs были отправлены?
Я снова запросил у ноды некоторые данные. Мы собираемся просмотреть transaction receipt для транзакции, которую мы рассмотрели выше 0x311ba3a0affb00510ae3f0a36c5bcd0a48cdb23d803bbc16f128639ffb9e3e58
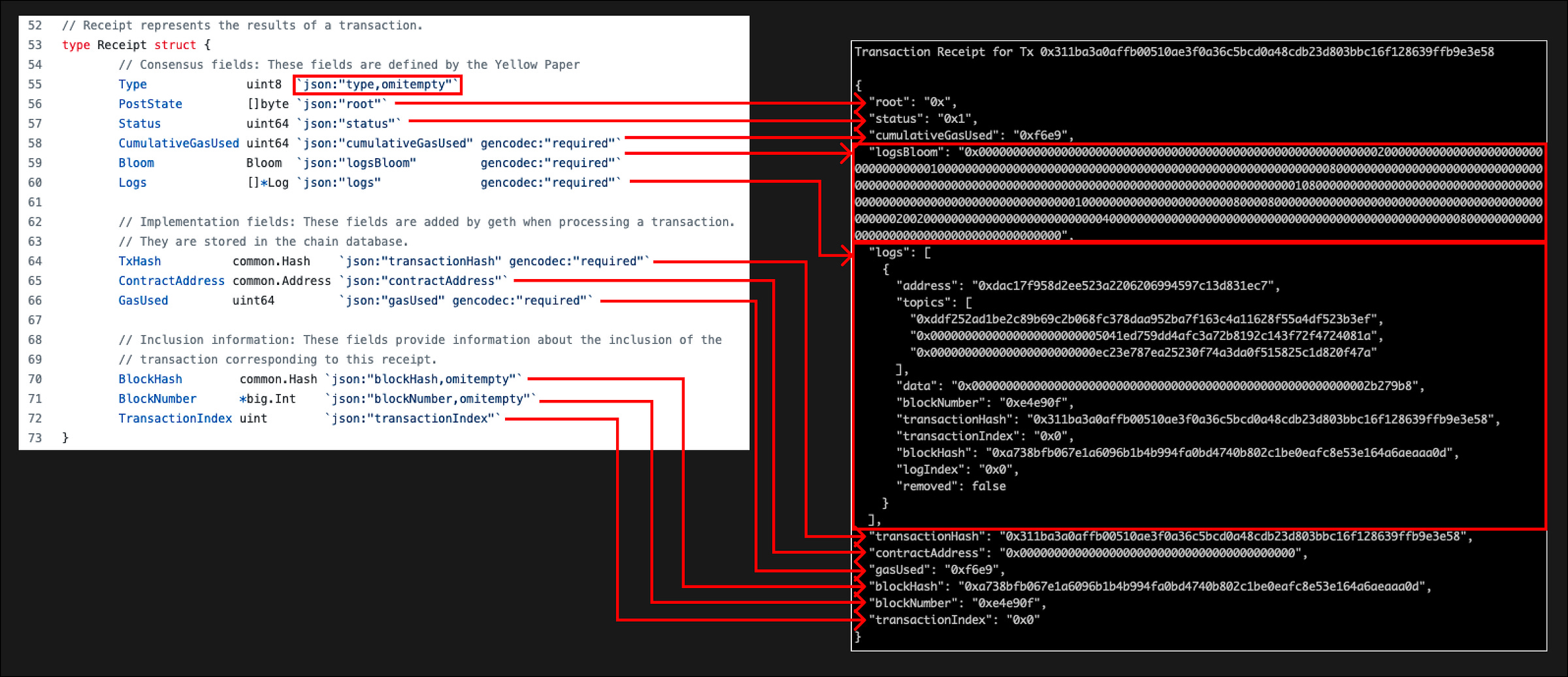
- Type = Тип транзакции (LegacyTxType, AccessListTxType, DynamicFeeTxType)
- PostState (root) = StateRoot после выполнения транзакции. Вы можете заметить, что в запросе выше это 0x, это, вероятно, связано с EIP-98
- CumulativeGasUsed = Сумма gasUsed этой транзакции и всех предыдущих транзакций в том же блоке
- Bloom (logsBloom) = Фильтр Блума для event logs (мы рассмотрим это в следующем разделе, помните, что мы также видели поле logsBloom в хэдерсе блока)
- Logs = массив объектов лога
- TxHash = хеш транзакции, с которой связан receipt
- ContractAddress = адрес развернутого контракта, если транзакция была созданием контракта. 0x000…0, если транзакция не является созданием контракта
- GasUsed = Газ, использованный этой транзакцией
- BlockHash = Хэш блока, в котором произошла эта транзакция
- BlockNumber = номер блока, в котором произошла эта транзакция
- TransactionIndex = индекс транзакций в блоке. Индекс определяет, какая транзакция выполняется первой. Эта транзакция находится в верхней части блока и поэтому имеет индекс 0
Теперь, когда мы знаем, из чего состоит transaction receipt, мы можем углубиться в logsBloom и массив логов в transaction receipt
Event Logs
В разделе с разбором транзакции мы отметили, что эта транзакция является переводом USDT. Я взял фрагмент кода из контракта USDT на Etherscan, чтобы мы могли его просмотреть
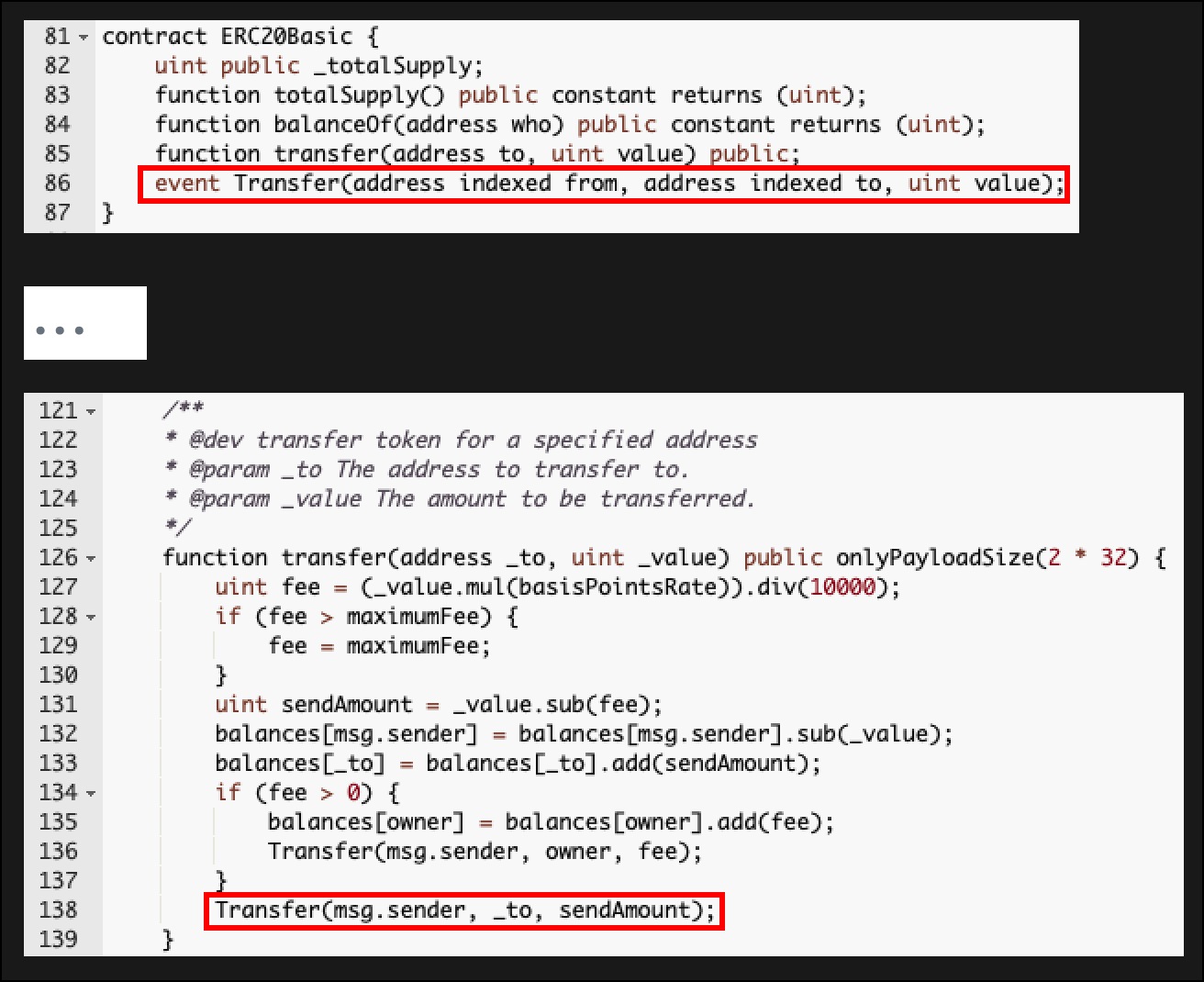
Мы видим, что event Transfer объявлено в строке 86 и что 2 входных параметра имеют ключевое слово «indexed»
Вам может быть интересно, что означает ключевое слово «indexed». Когда на вход event подаются «indexed» значения, то он позволяет нам быстро искать логи с этим инпутом
Например, с indexed «from», как показано выше, я могу задать вопрос: «Дайте мне все логи событий типа «Transfer» с адресом «To» 0x5041ed759dd4afc3a72b8192c143f72f4724081a между блоками X и Y». Как этот indexed работает внутри, будет рассмотрено в следующий раздел
Мы также можем видеть, что этот event log вызывается, когда функция Transfer доходит до строки 138. Обратите внимание, что этот контракт был создан в более ранней версией Solidity, поэтому ключевое слово emit отсутствует
Снова давайте взглянем на on-chain данные для этой транзакции
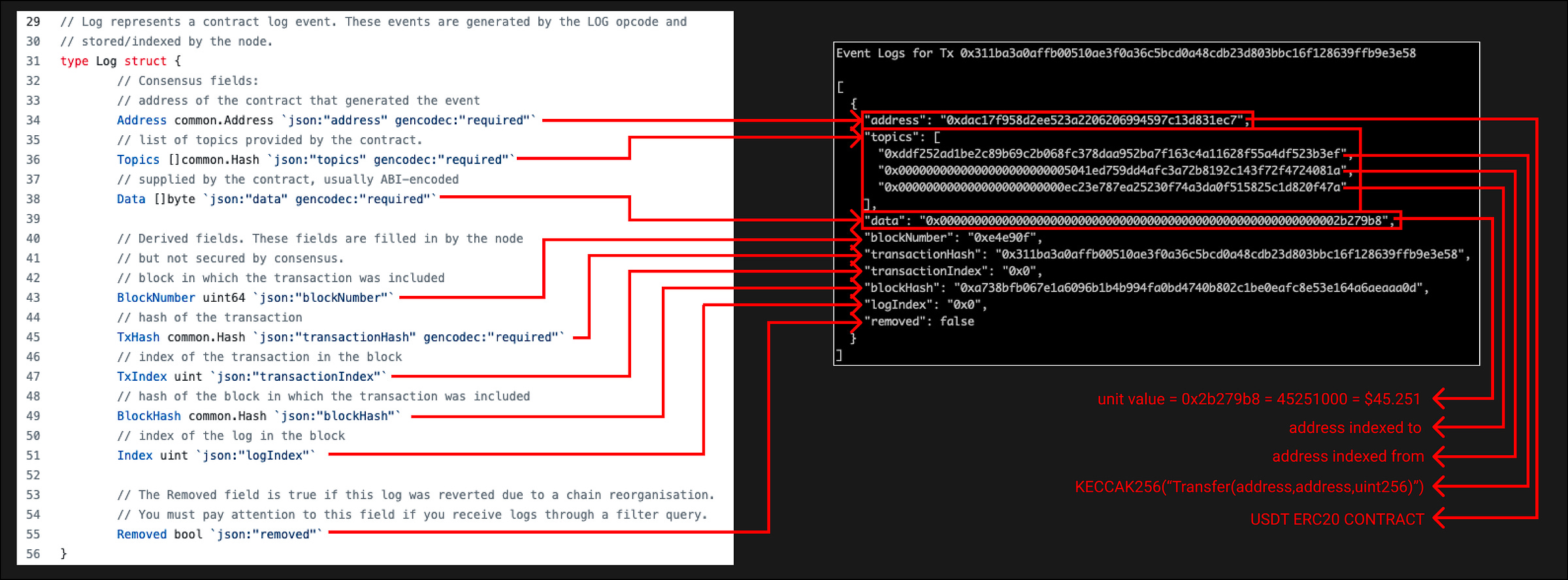
Если вы обратитесь к комментариям в структуре логов, то увидите описание для каждого поля. Поля, на которые мы хотим обратить внимание — это адрес, топики и дата
Topics
Начнем с топиков. Топики являются indexed значениями. Вы заметите, что у нас есть 3 топика в нашем запросе, в то время как событие Transfer имеет только 2 indexed параметра (from и to). Это связано с тем, что первый топик всегда является хэшем сигнатуры event
В этом случае сигнатура event — Transfer(address,address,uint256). Мы хэшируем это значение через keccak256 и получаем ddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef. Попробуйте сами здесь (примечание: не забудьте указать тип ввода text)
Это имеет смысл, если мы посмотрим на вопрос, который мы задади выше, мы хотели ограничить event logs для конкретного типа Transfer. Может быть несколько events, у которых есть поле from, поэтому при помощи indexed сигнатуры event мы можем фильтровать по типу event
У нас может быть максимум 4 топика, и каждый топик имеет размер 32 байта. Мы можем объявить 3 indexed параметра, потому что первый принимается сигнатурой event
Есть один случай, когда первый топик не является хешированной сигнатурой event. Это когда мы объявляем анонимный event. Это открывает возможность иметь 4 indexed параметра, а не 3, но мы теряем возможность индексировать имя event. Еще одно преимущество анонимных event заключается в том, что их развертывание может быть дешевле, поскольку они не заставляют вас использовать 1 дополнительный топик
Другие топики — это indexed значения «from» и «to» из event Transfer
Если тип indexed параметра превышает 32 байта (т. е. string и bytes), то фактические данные не сохраняются, а сохраняется хэш keccak256 данных
Data
Топик дата содержит остальные (не indexed) параметры в event log. В нашем случае это просто «value» 0x000000000000000000000000000000000000000000000000000000000002b279b8, что равно 45251000 в десятичном виде или $45,251
Если бы у нас было больше, они были бы добавлены к дате. Давайте рассмотрим пример, где есть более 1 не indexed параметра

В этом примере мы добавляем дополнительное поле «tax (налог)» в event Transfer. Предположим, что tax равен 20%, поэтому наше значение tax должно быть 20% от 45251000. Это 9050200 в десятичном виде, что соответствует 0x8a1858 в шестнадцатеричном формате, тип uint = uint256, поэтому нам нужно дополнить шестнадцатеричное значение до 32 байт
Результирующий элемент даты будет 0x0000000000000000000000000000000000000000000000000000000002b279b800000000000000000000000000000000000000000000000000000000008a1858
Address
Поле адреса — это адрес контракта, вызвавшего event. Одно важное замечание по поводу этого поля заключается в том, что оно также будет indexed, несмотря на то, что оно не включено в раздел топиков
Опять же, это имеет смысл, event Transfer является частью стандарта ERC20, что означает, что когда мы фильтруем логи для event Transfer ERC20, то мы собираемся получить event Transfer из всех контрактов ERC20
Индексируя адрес контракта, мы можем сузить поиск до конкретного интересующего нас контракта/токена (USDT)
Opcodes
Наконец, давайте коснемся опкодов LOG, которых 5. Они идут от LOG0, когда топики не включены, до LOG4, когда включены 4 топика
LOG3 — это то, что было бы использовано в нашем примере. Он принимает:
- offset = смещение памяти, которое представляет собой начальное местоположение ввода поля данных
- length = длина данных
- topic1 = значение для topic1
- topic2 = значение для topic2
- topic3 = значение для topic3
Offset и length определяют, где в памяти находятся данные
Теперь, когда мы понимаем, как устроен лог, мы наконец-то можем ответить на вопрос, что происходит под капотом при индексации топика
Bloom Filters
Секрет того, как indexed элементы обеспечивают более быстрый поиск, заключается в фильтрах Блума
В Llimllib есть отличное определение этих структур данных
Фильтр Блума — это структура данных, предназначенная для быстрого и эффективного использования памяти, чтобы сообщить вам, присутствует ли элемент в наборе или нет
Плата за эту эффективность заключается в том, что фильтр Блума является вероятностной структурой данных: она говорит нам, что элемент либо определенно не входит в набор, либо может быть где-то в наборе
Базовая структура данных фильтра Блума представляет собой битовый вектор
Ниже приведен пример небольшого битового вектора. Белые ячейки представляют биты со значением 0, а зеленые ячейки представляют биты со значением 1

Эти биты были установлены в 1 путем ввода некоторых данных и их хеширования. Значение полученного хэша используется как битовый индекс, для которого бит должен быть обновлен
Приведенный выше битовый вектор является результатом использования двух разных хэш-функций для значения «ethereum» для получения двухбитных индексов
Хэши представляют собой шестнадцатеричные числа. Чтобы получить индекс, мы можем взять это число и преобразовать его в значение от 0 до 14. Существуют различные способы сделать это, например, используя остаток от деления на 14
Тут можно попробовать это сделать самому
Lookup
Итак, у нас есть фильтр Блума для транзакции, которую мы теперь понимаем как бит-вектор. Для Ethereum входными данными, которые хешируются для определения того, какие биты в битовом векторе следует обновить, являются топик адреса и топик event log
Вернемся к logBloom в receipt транзакции. Это фильтр Блума для конкретной транзакции. Помните, что транзакция может иметь несколько логов, так что это представляет адреса/топики всех этих логов
0x00000000000000000000000000000000000000000000000000000000002000000000000000000000000000000000010000000000000000000000000000000000000000000000000000000008000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000010800000000000000000000000000000000000000000000000000000000000000000100000000000000000000008000080000000000000000000000000000000000000000000002002000000000000000000000000004000000000000000000000000000000000000000000000000000800000000000000000000000000000000000000000
Если мы вернемся к хэдерсу нашего блока, то у нас будет еще один файл logsBloom. Это фильтр Блума для всех транзакций внутри блока. Это все адреса/топики в каждом логе каждой транзакции
0x0100000000000004000000000000100000000000000000000000000000200000000000000000000000000000000001000000000000000000080008000000000040000000002000000000040800000000000000000000200000000000004800000040000002000000000000000000081000000000000040000000001080020000200001000000000000000000040000004000000000000000000000000010000000008000000000000800008000000800000000008000000200000800000000000000200a000000200000000000100002004000000000000000000000000020000000000080000020000000800000000000004000000000000000080000004000
Эти фильтры Блума представлены в шестнадцатеричном, а не в двоичном формате. Их длина составляет 256 байт, что представляет собой 2048-битный вектор
Обратимся к приведенному выше примеру в Llimllib, наш битовый вектор имел длину 15 с битовыми индексами 2 и 13. Если мы преобразуем это в шестнадцатеричный формат, то получим
001000000000010 = 0x1002
Поэтому, хотя шестнадцатеричный код может не выглядеть как битовый вектор, помните, что находится под капотом
Запросы
Если вы помните наш предыдущий запрос, в котором мы просили «получить нам все event logs типа Transfer с адресом «from» 0x5041ed759dd4afc3a72b8192c143f72f4724081a между блоками X и Y»
Мы можем взять топик Event сигнатуры, которая представляет тип Transfer вместе с топиком значения from (0x5041ed759dd4afc3a72b8192c143f72f4724081a), и определить, какие битовые индексы в фильтре Блума должны быть установлены в 1
Если мы используем logsBloom в хэдерсе блока, то мы можем проверить, не установлен ли какой-либо из этих битов в 1. Если это не так, то мы можем с уверенностью знать, что в блоке нет логов, соответствующих этому критерию
Если мы обнаружим, что биты установлены, мы знаем, что соответствующий лог может быть в блоке. Мы не знаем наверняка, потому что хэдерс блока logsBloom состоит из нескольких адресов и топиков. Возможно, другие логи event установили соответствующие биты. Вот почему фильтр Блума представляет собой вероятностную структуру данных
Чем больше битовый вектор, тем меньше вероятность пересечения битового индекса с другими логами
Когда у нас есть соответствующий фильтр Блума, мы можем запросить отдельные receipt logsBloom, используя ту же методологию. Когда мы получаем совпадение, мы можем просмотреть фактические записи логов, чтобы получить объект
Делая это от блока X до Y, мы можем быстро найти и получить все логи, которые соответствуют нашим критериям
Концептуально так работает фильтр Блума. Давайте теперь посмотрим на фактическую реализацию, используемую в Ethereum
Geth Implementation - Bloom Filters
Мы понимаем, как работает фильтр Блума, но мы хотим знать точные шаги перехода от адреса/топика к логам Блума и увидеть, как это делается на примере реального блока
Хорошо, нет проблем, мы можем начать с определения в желтой бумаге. Не волнуйтесь, если вы что-то не поймете сейчас

Самый простой способ показать вам, что это значит — привести пример и сослаться на реализацию клиента Geth
Вот лог транзакции, которую мы рассмотрели выше (Etherscan)
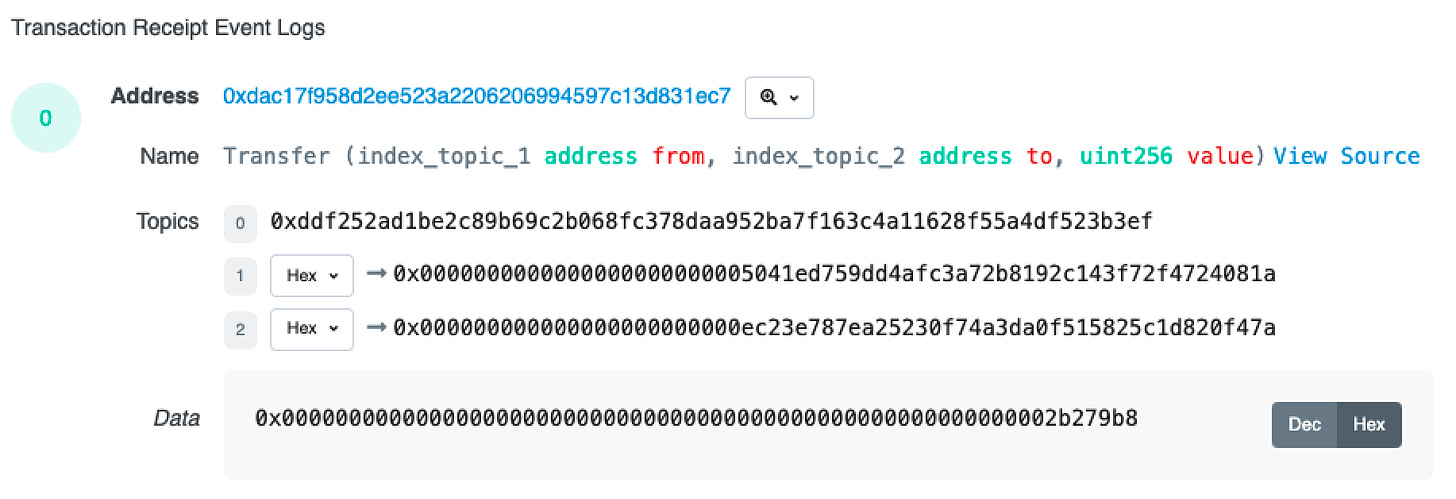
Мы рассмотрим первый топик, а именно сигнатуру event 0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef, и покажем, как это значение преобразуется в битовые индексы, которые следует обновить
Ниже представлена функция bloomValues из кодовой базы Geth. Эта функция принимает данные, такие как топик сигнатуры event 0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef и возвращает нам битовые индексы, которые необходимо обновить в фильтре Блума. Давайте пробежимся по нему
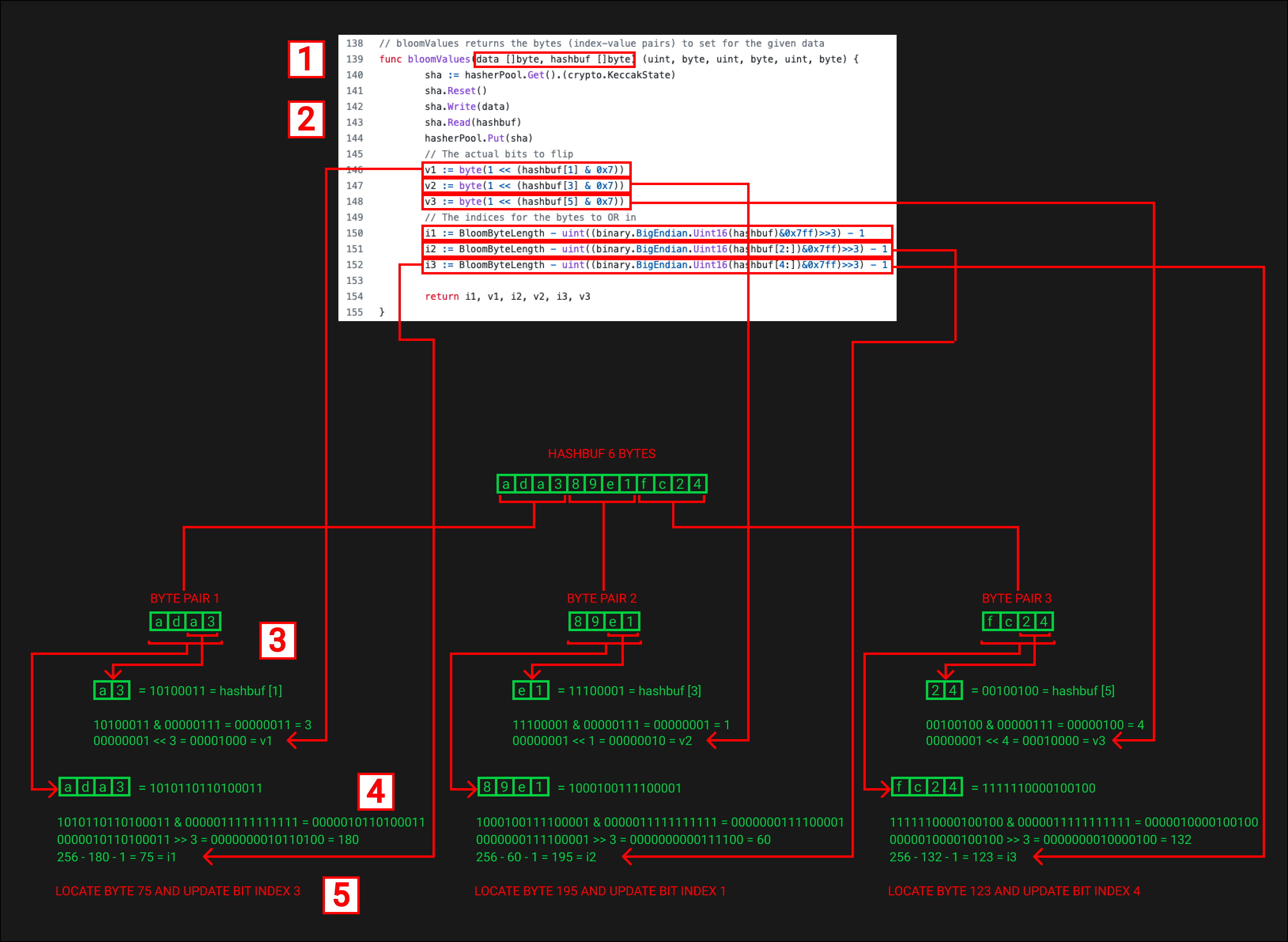
- Функция принимает данные, т.е. топик (в нашем случае топик сигнатуры event) и хэш-буфер, который представляет собой просто пустой массив байтов длиной 6
- Вернитесь к фрагменту желтой бумаги: «первые три пары байтов в хеше Keccak-256 последовательности байтов». Три пары байтов равны 6 байтам, поэтому наш hashbuf имеет длину 6
- Данные для нашего примера: 0xddf252ad1be2c89b69c2b068fc378daa952ba7f163c4a11628f55a4df523b3ef
- Функции sha между строками 140–144 хешируют входные данные и загружают выходные данные в хэш-буфер
- Выход sha, использующий keccak256, имеет вид ada389e1fc24a8587c776340efb91b36e675792ab631816100d55df0b5cf3cbc
- Вы можете проверить это, используя онлайн keccak 256 (убедитесь, что вы изменили тип ввода с текстового на шестнадцатеричный. При использовании keccak 256 для сигнатур функций ввод имеет текстовый тип, тогда как здесь он имеет шестнадцатеричный тип)
- Теперь hasbuf имеет содержимое [ad, a3, 89, e1, fc, 24] (в шестнадцатеричном формате). Помните, что каждый шестнадцатеричный символ представляет 4 бита, поэтому 2 символа представляют 8 бит
- v1 рассчитывается
- hashbuf[1] = 0xa3 = 10100011 используется с логическим & с 0x7. 0x7 = 00000111 в двоичном формате
- Байт состоит из 8 бит, если мы хотим получить битовый индекс, нам нужно убедиться, что полученное значение находится в диапазоне от 0 до 7 для массива с нулевым индексом. Использование логического & ограничивает hashbuf[1] значением от 0 до 7. В нашем случае это 3 = 00000011
- Это значение битового индекса используется с логическим оператором для изменения байта в правильном индексе, 0000100
- v1 — это целый байт, а не фактический битовый индекс, потому что это значение позже будет использоваться с логическим ИЛИ в фильтре Блума. ИЛИ гарантирует, что все соответствующие биты в фильтре Блума также будут изменены
- Теперь у нас есть значение байта, но нам все еще нужен индекс байта. Наш фильтр Блума имеет длину 256 байт (2048 бит), поэтому нам нужно знать, для какого байта выполнять логическое ИЛИ. Значение i1 представляет этот байтовый индекс
- Обратите внимание, что мы используем uint16 с нашим hashbuf, это ограничит его первыми 2 байтами массива. В нашем случае это 0xada3 = 1010110110100011
- Мы используем это значение с логическом И с 0x7ff = 0000011111111111. Если вы подсчитаете количество битов, установленных в 1 в 0x7ff, вы заметите, что их одиннадцать. Из желтой бумаги: «Он делает это, беря младшие 11 бит каждой из первых трех пар». Это дает нам значение 0000010110100011
- Затем это значение сдвигается вниз на 3 бита. Это превращает 11-битное число в 8-битное. Нам нужен байтовый индекс, и наш фильтр Блума имеет длину 256 байтов, поэтому нам нужно, чтобы значение нашего байтового индекса находилось в этом диапазоне. 8-битное число может быть любым значением от 0 до 255. В нашем случае это значение равно 180
- Мы вычисляем нашу шину байтового индекса, используя BloomByteLength, который, как мы знаем, равен 256 минус наше вычисленное значение 180, минус 1. Минус 1 означает сохранение результата от 0 до 255. Это дает нам наш байтовый индекс для обновления, в данном случае это байт 75
- Это говорит нам обновить битовый индекс 3 (4-й бит) в 75-м байте фильтра Блума. Это можно сделать, выполнив логическое ИЛИ v1 с 75-ым байтом в фильтре Блума
- Обратите внимание, что мы рассмотрели только первую «пару байтов» 0xada3. Это делается снова для следующих «пар байтов» 2 и 3. Каждый адрес/топик будет обновлять 3 бита в 2048-битном векторе. Из желтой бумаги: «специализированный фильтр Блума, который устанавливает три бита из 2048»
- «Пара байтов» 2 указывает индекс обновления бита 1 в байте 195.
- «Пара байтов» 3 состояния обновления индекса бита 4 в байте 123
- Если бит, который нужно изменить, уже был изменен другим топиком, то он останется прежним, в противном случае он будет изменен на 1
Итак, в заключение мы определили, что топик сигнатуры event изменит следующие биты в фильтре Блума
Взгляните на logBlooms в receipt транзакции, преобразуйте его в двоичный файл, и вы можете убедиться, что эти битовые индексы установлены
Я скомпилировал этот пример в репозиторий Github evm-by-example, чтобы вы могли поиграть с ним. Загляните в папку Bloom, она определенно поможет закрепить то, что вы узнали из статьи
Для тех, кто хочет немного углубиться, взгляните на BloomBits Trie